Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este tutorial guia você pela criação de um agente de IA que usa a recuperação e as ferramentas em conjunto.
Este é um tutorial de nível intermediário que pressupõe alguma familiaridade com os conceitos básicos da criação de um agente no Databricks. Se você for novo na criação de agentes, consulte Introdução aos agentes de IA.
O notebook de exemplo inclui todo o código usado no tutorial.
Este tutorial aborda alguns dos principais desafios da criação de aplicativos de IA generativos:
- Simplificando a experiência de desenvolvimento para tarefas comuns, como criar ferramentas e depurar a execução do agente.
- Desafios operacionais como:
- Configuração do agente de acompanhamento
- Definindo entradas e saídas de maneira previsível
- Gerenciando versões de dependências
- Controle de versão e implantação
- Medindo e melhorando a qualidade e a confiabilidade de um agente.
Para simplificar, este tutorial usa uma abordagem em memória para habilitar a busca por palavras-chave em um conjunto de dados que contém a documentação do Databricks segmentada.
Notebook de exemplo
Este bloco de anotações autônomo foi projetado para fazer você trabalhar rapidamente com agentes de IA do Mosaico usando um corpus de documento de exemplo. Ele está pronto para ser executado sem nenhuma configuração ou dados necessários.
Demonstração do agente de IA do Mosaico
Criar um agente e ferramentas
O Mosaic AI Agent Framework dá suporte a várias estruturas de criação diferentes. Este exemplo usa o LangGraph para ilustrar conceitos, mas este não é um tutorial do LangGraph.
Para obter exemplos de outras estruturas com suporte, consulte Criar um agente de IA e implantá-lo nos Aplicativos do Databricks.
A primeira etapa é criar um agente. Você deve especificar um cliente LLM e uma lista de ferramentas. O pacote Python databricks-langchain inclui clientes compatíveis com LangChain e LangGraph para LLMs do Databricks e ferramentas registradas no Catálogo do Unity.
O ponto de extremidade deve ser uma API de Modelo de Fundação com chamada de função ou Modelo Externo usando o Gateway de IA. Confira Modelos com suporte.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
O código a seguir define uma função que cria um agente a partir do modelo e de algumas ferramentas. Discutir os detalhes internos desse código do agente está fora do escopo desta página. Para obter mais informações sobre como criar um agente do LangGraph, consulte a documentação do LangGraph.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Definir ferramentas do agente
As ferramentas são um conceito fundamental para a criação de agentes. Eles fornecem a capacidade de integrar LLMs com código definido por humanos. Quando fornecido com uma solicitação e uma lista de ferramentas, um LLM com chamada de ferramenta gera os argumentos para invocar a ferramenta. Para obter mais informações sobre ferramentas e usá-las com agentes de IA do Mosaico, consulte as ferramentas do agente de IA.
A primeira etapa é criar uma ferramenta de extração de palavra-chave com base no TF-IDF. Este exemplo usa o scikit-learn e uma ferramenta do Catálogo do Unity.
O databricks-langchain pacote fornece uma maneira conveniente de trabalhar com as ferramentas do Catálogo do Unity. O código a seguir ilustra como implementar e registrar uma ferramenta de extrator de palavra-chave.
Observação
O workspace do Databricks tem uma ferramenta interna, system.ai.python_exec, que você pode usar para estender agentes com a capacidade de executar scripts em Python em um ambiente isolado. Outras ferramentas internas úteis incluem conexões externas e funções de IA.
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Aqui está uma explicação do código acima:
- Cria um cliente que usa o Catálogo do Unity no workspace do Databricks como um "registro" para criar e descobrir ferramentas.
- Define uma função Python que realiza a extração de palavras-chave TF-IDF.
- Registra a função Python como uma função de Catálogo do Unity.
Esse fluxo de trabalho resolve vários problemas comuns. Agora você tem um registro central para ferramentas que, como outros objetos no Catálogo do Unity, podem ser controladas. Por exemplo, se uma empresa tiver uma maneira padrão de calcular a taxa de retorno interna, você poderá defini-la como uma função no Catálogo do Unity e conceder acesso a todos os usuários ou agentes com a FinancialAnalyst função.
Para tornar essa ferramenta utilizável por um agente LangChain, use o UCFunctionToolkit que cria uma coleção de ferramentas para o LLM selecionar:
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
O código a seguir mostra como testar a ferramenta:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
O código a seguir cria um agente que usa a ferramenta de extração de palavra-chave.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
No rastreamento resultante, você pode ver que o LLM selecionou a ferramenta.
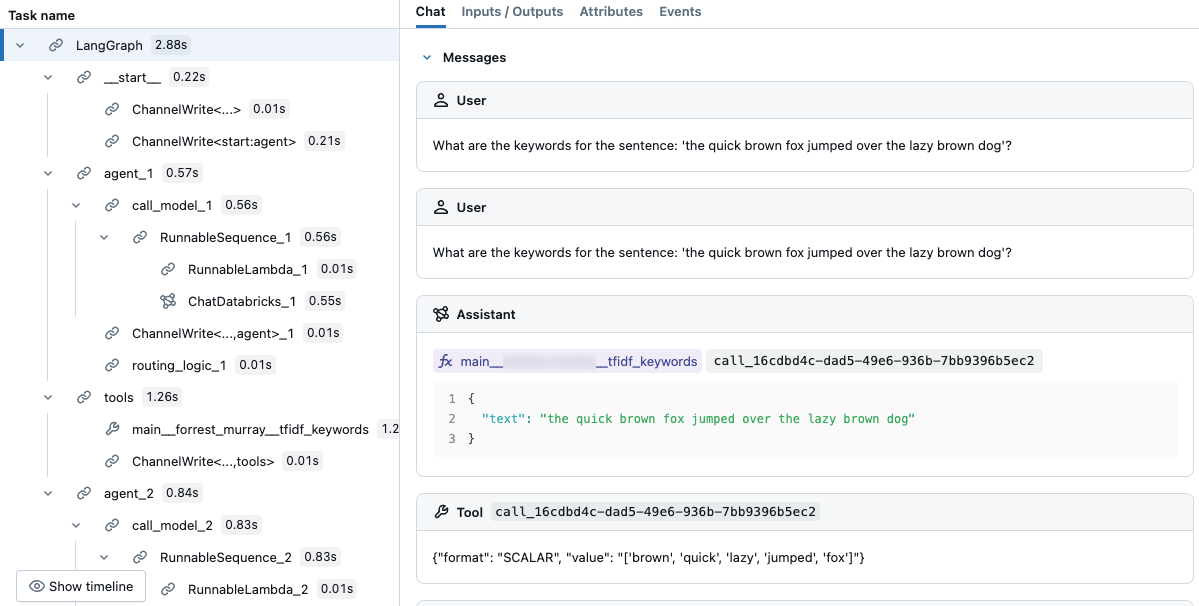
Utilize registros de log para depurar agentes
O MLflow Tracing é uma ferramenta poderosa para depurar e observar aplicativos de IA generativos, incluindo agentes. Ele captura informações detalhadas da operação por meio de intervalos, que encapsulam segmentos de código específicos e registram entradas, saídas e dados de tempo.
Para bibliotecas populares como LangChain, habilite o rastreamento automático com mlflow.langchain.autolog(). Você também pode usar mlflow.start_span() para personalizar um rastreamento. Por exemplo, você pode adicionar campos de valor de dados personalizados ou rotulagem para observabilidade. O código que é executado no contexto desse intervalo é associado aos campos que você define. Neste exemplo de TF-IDF na memória, dê um nome e um tipo de intervalo.
Para saber mais sobre o tracing, consulte MLflow Tracing - observabilidade do GenAI.
O exemplo a seguir cria uma ferramenta de recuperação usando um índice de TF-IDF simples na memória. Ele demonstra o registro automático para execuções de ferramentas e o rastreamento de intervalo personalizado para maior observabilidade:
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
Esse código usa um tipo de intervalo especial, RETRIEVER, que é reservado para ferramentas de recuperação de dados. Outros recursos de agente de IA do Mosaic (como o Playground de IA, a interface de usuário de revisão e a avaliação) usam o tipo de intervalo RETRIEVER para exibir os resultados da recuperação.
As ferramentas do Retriever exigem que você especifique seu esquema para garantir a compatibilidade com recursos downstream do Databricks. Para obter mais informações sobre mlflow.models.set_retriever_schema, consulte esquemas de recuperação personalizados.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
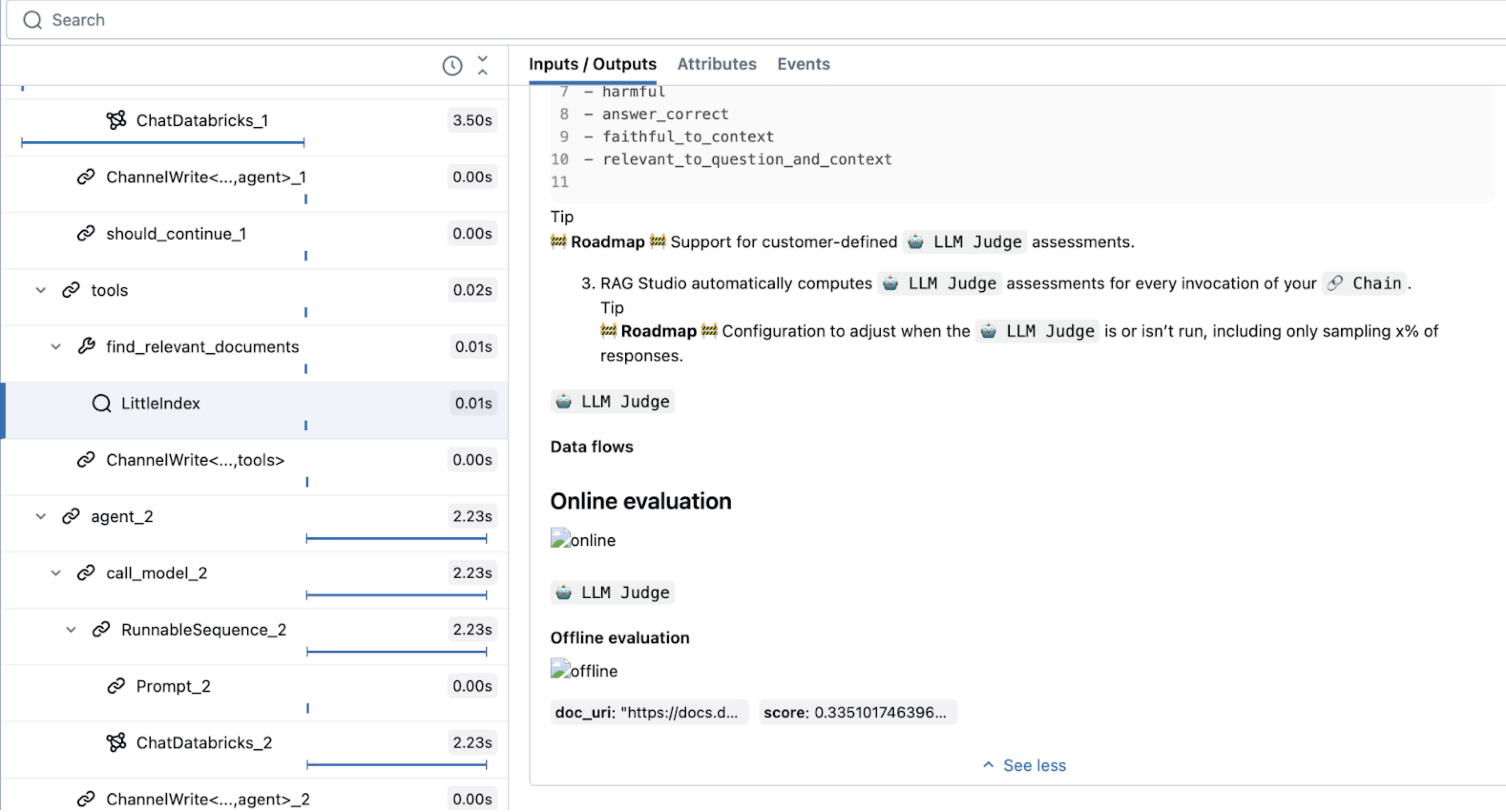
Definir o agente
A próxima etapa é avaliar o agente e prepará-lo para a implantação. Em um alto nível, isso envolve o seguinte:
- Defina uma API previsível para o agente usando uma assinatura.
- Adicione a configuração do modelo, o que facilita a configuração de parâmetros.
- Registre o modelo com dependências que forneçam um ambiente reproduzível e permitam configurar sua autenticação para outros serviços.
A interface MLflow ChatAgent simplifica a definição de entradas e saídas do agente. Para usá-lo, defina seu agente como uma subclasse de ChatAgent, implementando a inferência sem streaming com a função predict e a inferência de streaming com a função predict_stream.
ChatAgent é independente da sua escolha de framework de criação de agentes, permitindo que você teste e utilize facilmente diferentes frameworks e implementações de agentes - o único requisito é implementar as interfaces predict e predict_stream.
A criação do agente usando ChatAgent oferece vários benefícios, incluindo:
- Suporte à saída de streaming
- Histórico abrangente de mensagens com chamada de ferramenta: Retorne várias mensagens, incluindo mensagens intermediárias com chamada de ferramenta, para melhorar a qualidade e o gerenciamento de conversas.
- Suporte ao sistema multiagente
- Integração de recursos do Databricks: Compatibilidade pronta para uso com o Playground de IA, Avaliação de Agentes e Monitoramento de Agentes.
- Interfaces de criação tipadas: escrever código do agente usando classes Python tipadas, beneficiando-se do preenchimento automático do IDE e do notebook.
Para obter mais informações sobre como criar um ChatAgent, consulte esquema de agente de entrada e saída herdado (Model Serving).
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
O código a seguir mostra como usar o ChatAgent.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
Configurar agentes com parâmetros
A Estrutura do Agente permite controlar a execução do agente com parâmetros. Isso significa que você pode testar rapidamente diferentes configurações de agentes, como alternar endpoints de LLM ou experimentar ferramentas diferentes sem alterar o código base.
O código a seguir cria um dicionário de configuração que define parâmetros de agente ao inicializar o modelo.
Para obter mais detalhes sobre a parametrização de agentes, consulte Parametrize code for deployment across environments.
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Registrar o agente
Depois de definir o agente, ele estará pronto para ser registrado. No MLflow, registrar em log um agente significa salvar a configuração do agente (incluindo dependências) para que ele possa ser usado para avaliação e implantação.
Observação
Ao desenvolver agentes em um notebook, o MLflow infere as dependências do agente do ambiente do notebook.
Para registrar um agente em um notebook, você pode escrever todo o código que define o modelo em uma única célula e, em seguida, usar o %%writefile comando magic para salvar a definição do agente em um arquivo:
%%writefile agent.py
...
<Code that defines the agent>
Se o agente exigir acesso a recursos externos, como o Catálogo do Unity para executar a ferramenta de extração de palavra-chave, você deverá configurar a autenticação para o agente para que ele possa acessar os recursos quando ele for implantado.
Para simplificar a autenticação para recursos do Databricks, habilite a passagem de autenticação automática:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
Para saber mais sobre agentes de log, consulte log baseado em código.
Avaliar o agente
A próxima etapa é avaliar o agente para ver como ele se sai. A Avaliação do Agente é desafiadora e levanta muitas questões, como a seguinte:
- Quais são as métricas certas para avaliar a qualidade? Como posso confiar nas saídas dessas métricas?
- Preciso avaliar muitas ideias, como faço...
- executar a avaliação rapidamente para que a maior parte do meu tempo não seja gasto esperando?
- comparar rapidamente essas diferentes versões do meu agente em qualidade, custo e latência?
- Como identificar rapidamente a causa raiz de problemas de qualidade?
Como cientista de dados ou desenvolvedor, talvez você não seja o verdadeiro especialista no assunto. O restante desta seção descreve as ferramentas de avaliação do agente que podem ajudá-lo a definir um bom resultado.
Criar um conjunto de avaliação
Para definir o que a qualidade significa para um agente, use métricas para medir o desempenho do agente em um conjunto de avaliação. Consulte Definir "qualidade": conjuntos de avaliação.
Com a Avaliação do Agente, você pode criar conjuntos de avaliação sintética e medir a qualidade executando avaliações. A ideia é começar com base nos fatos, como um conjunto de documentos, e "trabalhar para trás" usando esses fatos para gerar um conjunto de perguntas. Você pode condicionar as perguntas que são geradas ao fornecer algumas diretrizes:
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
As avaliações geradas incluem o seguinte:
Um campo de solicitação semelhante ao
ChatAgentRequestmencionado anteriormente:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}Uma lista de "conteúdo recuperado esperado". O esquema do retriever foi definido com os campos
contentedoc_uri.[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]Uma lista de fatos esperados. Quando você compara duas respostas, pode ser difícil encontrar pequenas diferenças entre elas. Os fatos esperados destilam o que separa uma resposta correta de uma resposta parcialmente correta de uma resposta incorreta e melhoram tanto a qualidade dos juízes de IA quanto a experiência das pessoas que trabalham no agente:
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]Um campo source_id que aqui é
SYNTHETIC_FROM_DOC. À medida que você cria conjuntos de avaliação mais completos, os exemplos virão de várias fontes diferentes, de modo que este campo os distingue.
Para saber mais sobre como criar conjuntos de avaliação, consulte Sintetizar conjuntos de avaliação.
Usar juízes LLM para avaliar o agente
Avaliar manualmente o desempenho de um agente em tantos exemplos gerados não se adapta bem a grandes escalas. Em escala, usar LLMs como juízes é uma solução muito mais razoável. Para usar os juízes internos que estão disponíveis ao usar a Avaliação do Agente, use o seguinte código:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
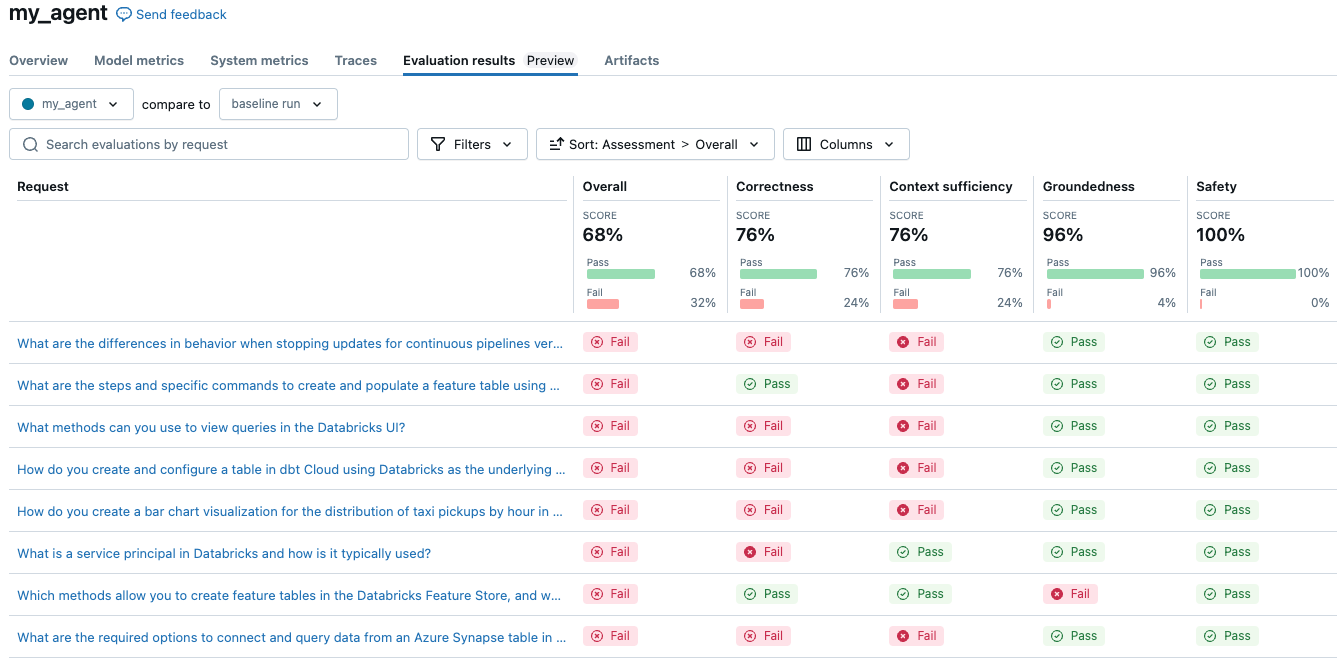
O agente simples obteve 68% no total. Seus resultados podem ser diferentes aqui, dependendo da configuração que você usa. Executar um experimento para comparar três LLMs diferentes para custo e qualidade é tão simples quanto alterar a configuração e reavaliar.
Considere alterar a configuração do modelo para usar uma llm, prompt do sistema ou configuração de temperatura diferente.
Esses juízes podem ser personalizados para seguir as mesmas diretrizes que os especialistas humanos usariam para avaliar uma resposta. Para obter mais informações sobre juízes LLM, consulte Juízes de IA embutidos (MLflow 2).
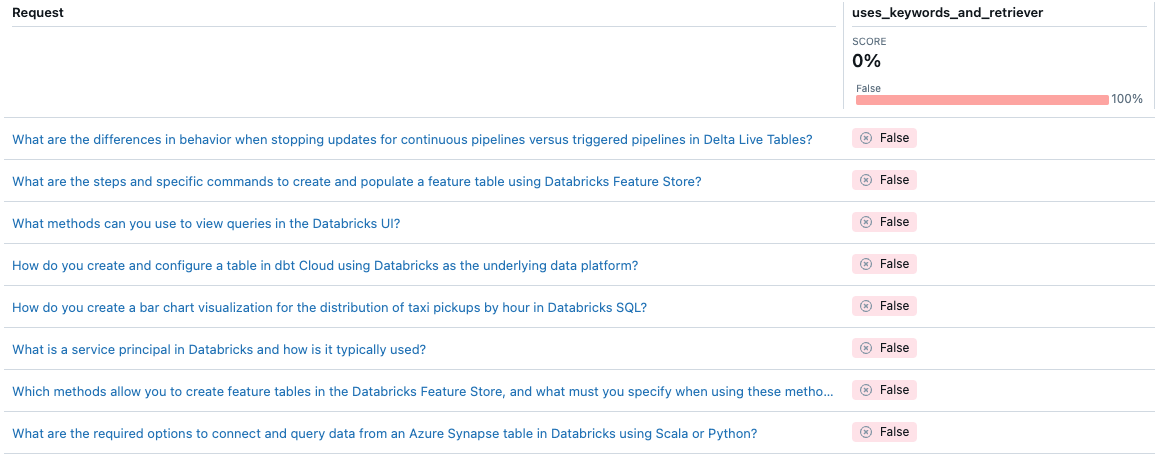
Com a Avaliação do Agente, você pode personalizar a maneira como mede a qualidade de um agente específico usando métricas personalizadas. Você pode pensar na avaliação como um teste de integração e métricas individuais como testes de unidade. O exemplo a seguir usa uma métrica booliana para verificar se o agente usou a extração da palavra-chave e o recuperador para uma determinada solicitação:
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Observe que o agente nunca usa a extração de palavra-chave. Como você pode corrigir esse problema?
Implantar e monitorar o agente
Quando você estiver pronto para começar a testar seu agente com usuários reais, o Agent Framework fornece uma solução pronta para produção para atender o agente no Mosaic AI Model Serving.
A implantação de agentes no Model Serving oferece os seguintes benefícios:
- O Model Serving gerencia o dimensionamento automático, o registro em log, o controle de versão e o controle de acesso, permitindo que você se concentre no desenvolvimento de agentes de qualidade.
- Os especialistas no assunto podem usar o Aplicativo de Revisão para interagir com o agente e fornecer comentários que podem ser incorporados ao seu monitoramento e avaliações.
- Você pode monitorar o agente executando avaliações no tráfego ao vivo. Embora o tráfego do usuário não inclua a verdade básica, os juízes LLM (e a métrica personalizada que você criou) realizam uma avaliação não supervisionada.
O código a seguir implanta os agentes em um endpoint de serviço. Para obter mais informações, consulte Implantar um agente para aplicativos de IA generativos (Model Serving).
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)