Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo fornece uma visão geral da Pesquisa de Vetores de IA do Mosaico, incluindo o que ela é e como ela funciona.
O que é o Mosaic AI Vector Search?
O Mosaic AI Vector Search é uma solução de pesquisa de vetor que é integrada à Plataforma de Inteligência de Dados do Databricks e integrada às ferramentas de governança e produtividade. A pesquisa de vetor é um tipo de pesquisa otimizada para recuperar inserções. Incorporações são representações matemáticas do conteúdo semântico de dados, de modo geral dados de texto ou de imagens. As inserções são geradas por um modelo de linguagem grande e são um componente fundamental de muitos aplicativos de IA generativos que dependem da localização de documentos ou imagens semelhantes entre si. Alguns exemplos são os sistemas RAG, sistemas de recomendação e reconhecimentos de imagem e vídeo.
Com o Mosaic AI Vector Search, você cria um índice de busca em vetores a partir de uma tabela Delta. O índice inclui dados incorporados com metadados. Em seguida, você pode consultar o índice usando uma API REST para identificar os vetores mais semelhantes e retornar os documentos associados. Você pode estruturar o índice para sincronizar automaticamente sempre que a tabela Delta subjacente for atualizada.
O Mosaic AI Vector Search suporta o seguinte:
- Pesquisa híbrida de similaridade de palavras-chave.
- Pesquisa de palavra-chave de texto completo (Beta) em qualquer ponto de extremidade ou índices de texto completo dedicados (Beta) em pontos de extremidade otimizados para armazenamento.
- Filtragem.
- Reclassificado.
- Listas de controle de acesso (ACLs) para gerenciar endpoints de pesquisa de vetores.
- Sincronize apenas as colunas selecionadas.
- Salve e sincronize as incorporações geradas.
Como funciona o Mosaic AI Vector Search?
A Pesquisa de Vetores AI do Mosaic usa o algoritmo Hierarchical Navigable Small World (HNSW) para suas pesquisas aproximadas do vizinho mais próximo (ANN) e a métrica de distância L2 para medir a similaridade do vetor de incorporação. Se quiser usar a similaridade por cosseno, você precisará normalizar suas incorporações de ponto de dados antes de usá-las para alimentar a busca em vetores. Quando os pontos de dados são normalizados, a classificação produzida pela distância euclidiana é a mesma que a classificação produzida pela similaridade por cosseno.
O Mosaic AI Vector Search também dá suporte à pesquisa híbrida por similaridade de palavras-chave, que combina a pesquisa de inserção baseada em vetores com técnicas tradicionais de pesquisa baseada em palavras-chave. Essa abordagem corresponde a palavras exatas na consulta e, ao mesmo tempo, usa uma pesquisa de similaridade baseada em vetores para capturar as relações semânticas e o contexto da consulta.
Ao integrar essas duas técnicas, a pesquisa híbrida por similaridade de palavras-chave recupera documentos que contêm não apenas as palavras-chave exatas, mas também aquelas que são conceitualmente semelhantes, fornecendo resultados de pesquisa mais abrangentes e relevantes. Esse método é particularmente útil em aplicativos de RAG em que os dados de origem têm palavras-chave exclusivas, como SKUs ou identificadores, que não são adequados para a simples pesquisa por similaridade.
Para obter detalhes sobre a API, consulte a referência Python SDK e Query um índice de pesquisa de vetor.
Cálculo de pesquisa de similaridade
O cálculo de pesquisa de similaridade usa a seguinte fórmula:
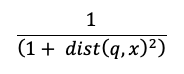
em que dist é a distância euclidiana entre a consulta q e a entrada de índice x:
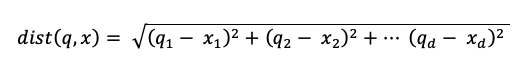
Algoritmo de pesquisa por palavra-chave
As pontuações de relevância são calculadas usando o Okapi BM25. Todas as colunas de texto ou cadeia de caracteres são pesquisadas, incluindo as colunas de inserção do texto de origem e de metadados em formato de texto ou cadeia de caracteres. A função de geração de tokens divide os limites das palavras, remove a pontuação e converte todo o texto em letras minúsculas.
Como as pesquisas por similaridade e por palavra-chave são combinadas
Os resultados das pesquisas por similaridade e por palavra-chave são combinados usando a função RRF (Reciprocal Rank Fusion).
O RRF pontua primeiro cada documento de cada método usando as pontuações:
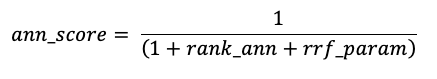
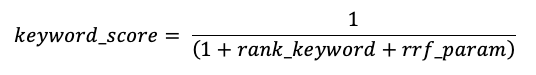
O rrf_param controla a importância relativa dos documentos de classificação superior e inferior. Com base na documentação, rrf_param está definido como 60.
As pontuações são normalizadas para que a pontuação mais alta possível seja 1 usando o seguinte fator de normalização:
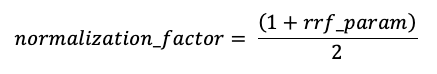
A pontuação final de cada documento é calculada da seguinte maneira:
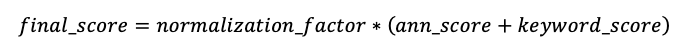
Os documentos com as pontuações finais mais altas são retornados.
Opções para fornecer inserções de vetores
Para criar um índice de pesquisa de vetor no Databricks, primeiro você deve decidir como fornecer inserções de vetor. O Databricks dá suporte a três opções.
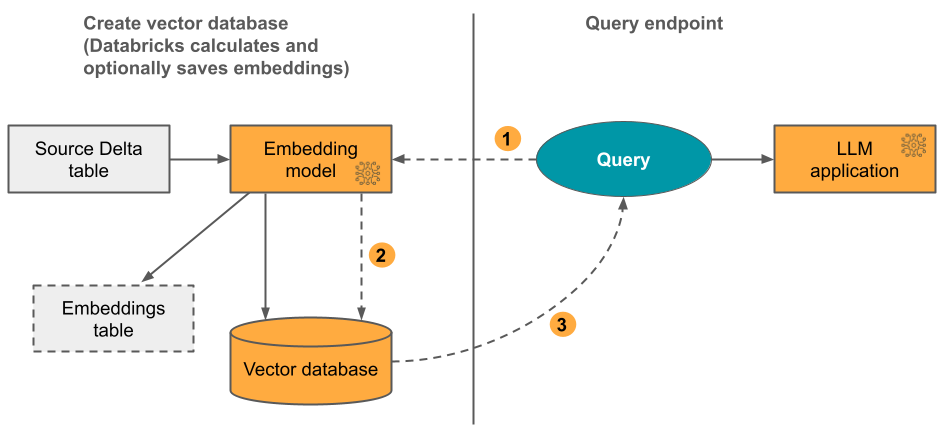
Opção 1: Índice de Sincronização Delta com incorporações computadas pelo Databricks
Com essa opção, você fornece uma tabela Delta de origem que contém dados no formato de texto. O Databricks calcula as inserções usando um modelo especificado e, opcionalmente, salva as inserções em uma tabela no Catálogo do Unity. À medida que a tabela Delta é atualizada, o índice permanece sincronizado com a tabela Delta.
O diagrama a seguir ilustra o processo:
- Calcular inserções de consulta. A consulta pode incluir filtros de metadados.
- Realize pesquisas por similaridade para identificar os documentos mais relevantes.
- Retorne os documentos mais relevantes e anexe-os à consulta.
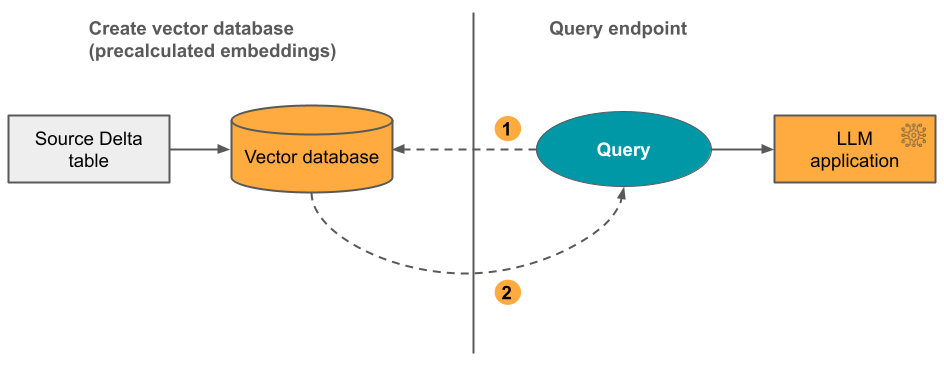
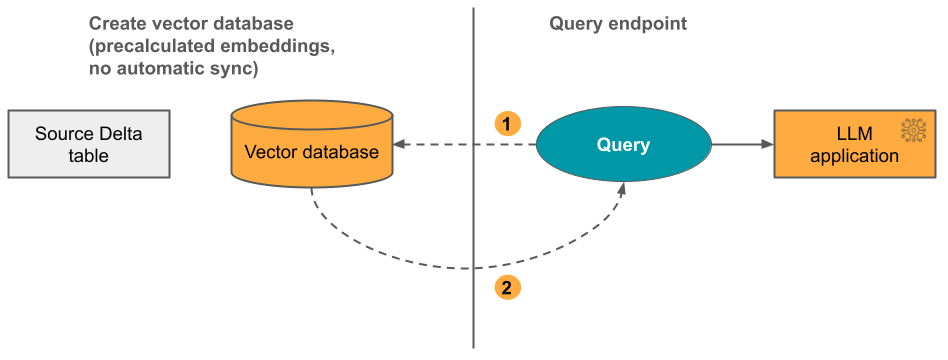
Opção 2: Índice de Sincronização Delta com inserções autogerenciadas
Com essa opção, você fornece uma tabela Delta de origem que contém inserções pré-calculadas. À medida que a tabela Delta é atualizada, o índice permanece sincronizado com a tabela Delta.
Observação
Não é possível converter um índice de inserção autogerenciado em um índice gerenciado pelo Databricks. Se você decidir usar inserções gerenciadas posteriormente, deverá criar um novo índice e recompute inserções.
O diagrama a seguir ilustra o processo:
- A consulta consiste em incorporações e pode incluir filtros de metadados.
- Realize pesquisas por similaridade para identificar os documentos mais relevantes. Retorne os documentos mais relevantes e anexe-os à consulta.
Opção 3: Índice de Acesso Direto ao Vetor
Com essa opção, você deve atualizar manualmente o índice usando a API REST quando a tabela de inserções for alterada.
O diagrama a seguir ilustra o processo:
Opção 4: índice de pesquisa de texto completo em pontos de extremidade com otimização de armazenamento (Beta)
Com essa opção, você cria um Delta Sync Index em um endpoint otimizado para armazenamento sem nenhuma coluna de incorporação. O índice dá suporte à pesquisa de texto completo baseada em palavra-chave usando a pontuação BM25, sem a necessidade de inserções de vetor. Isso é útil para pesquisar termos exatos, identificadores ou palavras-chave em dados de texto.
Observação
Você também pode usar query_type="FULL_TEXT" para executar pesquisas de palavra-chave em índices de pesquisa de vetor existentes em pontos de extremidade padrão e otimizados para armazenamento. Essa opção é para criar um índice dedicado que não contém nenhuma inserção.
Índices de pesquisa de texto completo dedicados só estão disponíveis em pontos de extremidade otimizados para armazenamento e exigem o modo de sincronização disparado. Consulte Criar um índice de pesquisa de texto completo (Beta) para obter instruções.
Opções de ponto de extremidade
A Pesquisa de Vetor de IA do Mosaico fornece as seguintes opções para que você possa selecionar a configuração de ponto de extremidade que atenda às necessidades do aplicativo.
Observação
Os pontos de extremidade otimizados para armazenamento estão na Visualização Pública. O QPS alto está em beta e está disponível apenas para endpoints padrão.
- Os pontos de extremidade padrão têm uma capacidade de 320 milhões de vetores na dimensão 768.
- Com pontos de extremidade padrão, você pode usar QPS alto para dar suporte à alta taxa de transferência sustentada. Consulte a taxa de transferência do ponto de extremidade de escala com QPS alto (Beta).
- Pontos de extremidade otimizados para armazenamento têm uma capacidade maior (mais de um bilhão de vetores na dimensão 768) e proporcionam uma indexação 10 a 20 vezes mais rápida. As consultas em pontos de extremidade otimizados para armazenamento têm uma latência ligeiramente maior de cerca de 250 milissegundos. O preço dessa opção é otimizado para o maior número de vetores. Para obter detalhes de preços, consulte a página de preços da busca vetorial. Para obter informações sobre como gerenciar custos de pesquisa de vetor, consulte o guia de gerenciamento de custos de pesquisa de vetor.
Especifique o tipo de ponto de extremidade ao criar o ponto de extremidade.
Consulte também Limitações de pontos de extremidade otimizados para armazenamento.
Como configurar o Mosaic AI Vector Search
Para usar o Mosaic AI Vector Search, crie o seguinte:
Um ponto de extremidade de busca em vetores. Este endpoint atende ao índice de busca de vetores. Você pode consultar e atualizar o endpoint usando a API REST ou o SDK. Confira Criar um ponto de extremidade de busca em vetores para obter instruções.
Os pontos de extremidade são escalados verticalmente de maneira automática para dar suporte ao tamanho do índice ou ao número de solicitações simultâneas. Os pontos de extremidade são reduzidos automaticamente quando um índice é excluído.
Um índice de busca em vetores. O índice de pesquisa de vetor é criado a partir de uma tabela Delta e é otimizado para fornecer pesquisas de vizinha mais próxima aproximada (ANN) em tempo real. O objetivo da pesquisa é identificar os documentos que sejam semelhantes à consulta. Os índices de busca em vetores aparecem no Catálogo do Unity e são regidos por ele. Confira Criar um índice de busca em vetores para obter instruções.
Além disso, se você optar por ter o Databricks computando as inserções, poderá usar um ponto de extremidade de API do Modelo de Fundação pré-configurado ou criar um ponto de extremidade de serviço de modelo para atender ao modelo de inserção de sua escolha. Consulte APIs de Modelo de Base de pagamento por token ou Criar modelo de base que atende os pontos de extremidade para obter instruções.
Para consultar o ponto de extremidade de serviço do modelo, use a API REST ou o SDK do Python. Sua consulta pode definir os filtros com base em qualquer coluna na tabela Delta. Para obter detalhes, consulte Use filtros em consultas, a referência API ou a referência do SDK Python.
Requirements
- Workspace habilitado para Catálogo do Unity.
- Computação sem servidor habilitada. Para obter instruções, consulte Conectar-se à computação sem servidor.
- Para pontos de extremidade padrão, a tabela de origem deve ter o Feed de Dados de Alterações habilitado. Consulte Use o feed de dados de alterações do Delta Lake no Azure Databricks.
- Para criar um índice de pesquisa de vetor, você deve ter CREATE TABLE privilégios no esquema de catálogo em que o índice será criado.
A permissão para criar e gerenciar terminais de busca vetorial é configurada usando listas de controle de acesso. Consulte ACLs do endpoint de pesquisa vetorial.
Proteção e autenticação de dados
O Databricks implementa os seguintes controles de segurança para proteger seus dados:
- Cada solicitação do cliente ao Mosaic AI Vector Search é logicamente isolada, autenticada e autorizada.
- Mosaic AI Vector Search criptografa todos os dados em repouso (AES-256) e em trânsito (TLS 1.2+).
O Mosaic AI Vector Search dá suporte a dois modos de autenticação, entidades de serviço e PATs (tokens de acesso pessoal). Para aplicativos de produção, o Databricks recomenda que você use entidades de serviço, que podem ter um desempenho por consulta até 100 msec mais rápido em relação aos tokens de acesso pessoal.
Token da entidade de serviço. Um administrador pode gerar um token de entidade de serviço e passá-lo para o SDK ou a API. Consulte usar entidades de serviço. Para casos de uso de produção, o Databricks recomenda usar um token de entidade de serviço.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Token de acesso pessoal. Você pode usar um token de acesso pessoal para autenticar com o Mosaic AI Vector Search. Consulte token de autenticação de acesso pessoal. Se você usar o SDK em um ambiente de notebook, o SDK gerará automaticamente um token PAT para autenticação.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
As Chaves gerenciadas pelo cliente (CMK) têm suporte em pontos de extremidade criados em 8 de maio de 2024 ou após 8 de maio de 2024.
Monitorar o uso e os custos
Para obter informações sobre como monitorar o uso e os custos associados a índices e pontos de extremidade de pesquisa de vetores, consulte o Guia de Gerenciamento de Custos de Pesquisa de Vetores.
Você também pode consultar o uso por política de orçamento. Consulte as políticas de orçamento de pesquisa do Vector.
Limites de tamanho de dados e recursos
A tabela a seguir resume os limites de tamanho de dados e recursos para pontos de extremidade e índices de busca em vetores:
| Resource | Granularidade | Limit |
|---|---|---|
| Pontos de extremidade de busca em vetores | Por área de trabalho | 100 |
| Inserções (índice de Sincronização Delta) | Por ponto de extremidade padrão | ~ 320,000,000 na dimensão de inserção 768 ~ 160,000,000 na dimensão de inserção 1536 ~ 80,000,000 na dimensão de inserção 3072 (escalona aproximadamente de forma linear) |
| Inserções (índice direct vector access) | Por ponto de extremidade padrão | ~ 2,000,000 na dimensão de inserção 768 |
| Incorporações (endpoint com otimização de armazenamento) | Por ponto de extremidade otimizado para armazenamento | ~ 1,000,000,000 na dimensão de inserção 768 |
| Dimensão de inserção | Por índice | 4096 |
| Indexes | Por ponto de extremidade | 50 |
| Columns | Por índice | 50 |
| Columns | Tipos com suporte: Bytes, short, integer, long, float, double, boolean, string, timestamp, date, array | |
| Campos de metadados | Por índice | 50 |
| Nome do índice | Por índice | 128 caracteres |
Os limites a seguir se aplicam à criação e atualização de índices de busca em vetores:
| Resource | Granularidade | Limit |
|---|---|---|
| Tamanho da linha do Índice de Sincronização Delta | Por índice | 100 KB |
| Tamanho da coluna de inserção de origem do Índice de Sincronização Delta | Por índice | 32764 bytes |
| Limite de tamanho da solicitação de upsert em massa do Índice de Vetor Direto | Por índice | 10MB |
| Limite de tamanho da solicitação de exclusão em massa do Índice de Vetor Direto | Por índice | 10MB |
Os limites a seguir se aplicam à API de consulta.
| Resource | Granularidade | Limit |
|---|---|---|
| Tamanho do texto de consulta | Por consulta | 32764 caracteres |
| Tokens ao usar a pesquisa híbrida | Por consulta | 1024 palavras ou caracteres de 2 bytes |
| Condições de filtro | Por cláusula de filtro | 1024 elementos |
| Número máximo de resultados retornados (pesquisa aproximada do vizinho mais próximo) | Por consulta | 10,000 |
| Número máximo de resultados retornados (pesquisa de similaridade de palavra-chave híbrida) | Por consulta | 200 |
| Número máximo de resultados retornados (pesquisa de texto completo) | Por consulta | 200 |
| Tamanho da resposta | Por consulta | 10MB |
Limitações
- O nome
_idda coluna é reservado. Se a tabela de origem tiver uma coluna nomeada_id, renomeie-a antes de criar um índice de pesquisa de vetor. - Não há suporte para permissões no nível de linha e de coluna. No entanto, você pode implementar suas próprias ACLs de nível de aplicação usando a API de filtro.
- Você não pode clonar um índice em um workspace diferente. Você pode fazer solicitações entre workspaces usando o SDK do Databricks ou a API REST.
- A capacidade do índice é provisionada com base no tamanho da tabela de origem no momento da criação do índice. Começar com uma tabela de origem pequena limita o quanto o índice pode crescer, resultando em erros de capacidade esgotada. Portanto, dimensione a tabela de origem para corresponder ao volume de dados esperado antes de criar o índice.
Limitações de pontos de extremidade otimizados para armazenamento.
As limitações nesta seção se aplicam somente a pontos de extremidade otimizados para armazenamento. Os pontos de extremidade otimizados para armazenamento estão na Visualização Pública.
- Não há suporte para o modo de sincronização contínua.
- Não há suporte para colunas a serem sincronizadas.
- A dimensão de inserção deve ser divisível por 16.
- A atualização incremental tem suporte parcial. Cada sincronização deve recompilar partes do índice de pesquisa vetorial.
- Para índices gerenciados, todas as inserções computadas anteriormente serão reutilizados se a linha de origem não tiver sido alterada.
- Você deve prever uma redução significativa de ponta a ponta no tempo necessário para uma sincronização em comparação com os pontos de extremidade padrão. Conjuntos de dados com 1 bilhão de inserções devem concluir uma sincronização em menos de 8 horas. Conjuntos de dados menores levarão menos tempo para serem sincronizados.
- Não há suporte para workspaces compatíveis com FedRAMP.
- Não há suporte para CMK (chaves gerenciadas pelo cliente).
- Para usar um modelo de inserção personalizado para um índice de Sincronização Delta gerenciado, a consulta de IA para modelos personalizados e modelos externos deve ser habilitada. Consulte Manage Azure Databricks pré-visualizações para saber como habilitar pré-visualizações.
- Os pontos de extremidade otimizados para armazenamento dão suporte a até 1 bilhão de incorporações de vetores de 768 dimensões. Se você tiver um caso de uso de escala maior, entre em contato com sua equipe de conta.