Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Esse recurso está em Visualização Pública.
Esta página apresenta o Genie Code para desenvolvimento de pipeline, um agente de dados de IA disponível selecionando o modo agente no Genie Code. Projetado especificamente para o Lakeflow Spark Declarative Pipelines (SDP) e o Lakeflow Pipelines Editor, ele explora dados, gera e executa código de pipeline e corrige erros, tudo a partir de um único prompt.
O que é o Genie Code para desenvolvimento de pipeline?
O Genie Code no modo Agent é um parceiro autônomo que pode automatizar fluxos de trabalho de engenharia de dados de várias etapas inteiros no SDP e no Editor de Pipelines do Lakeflow.
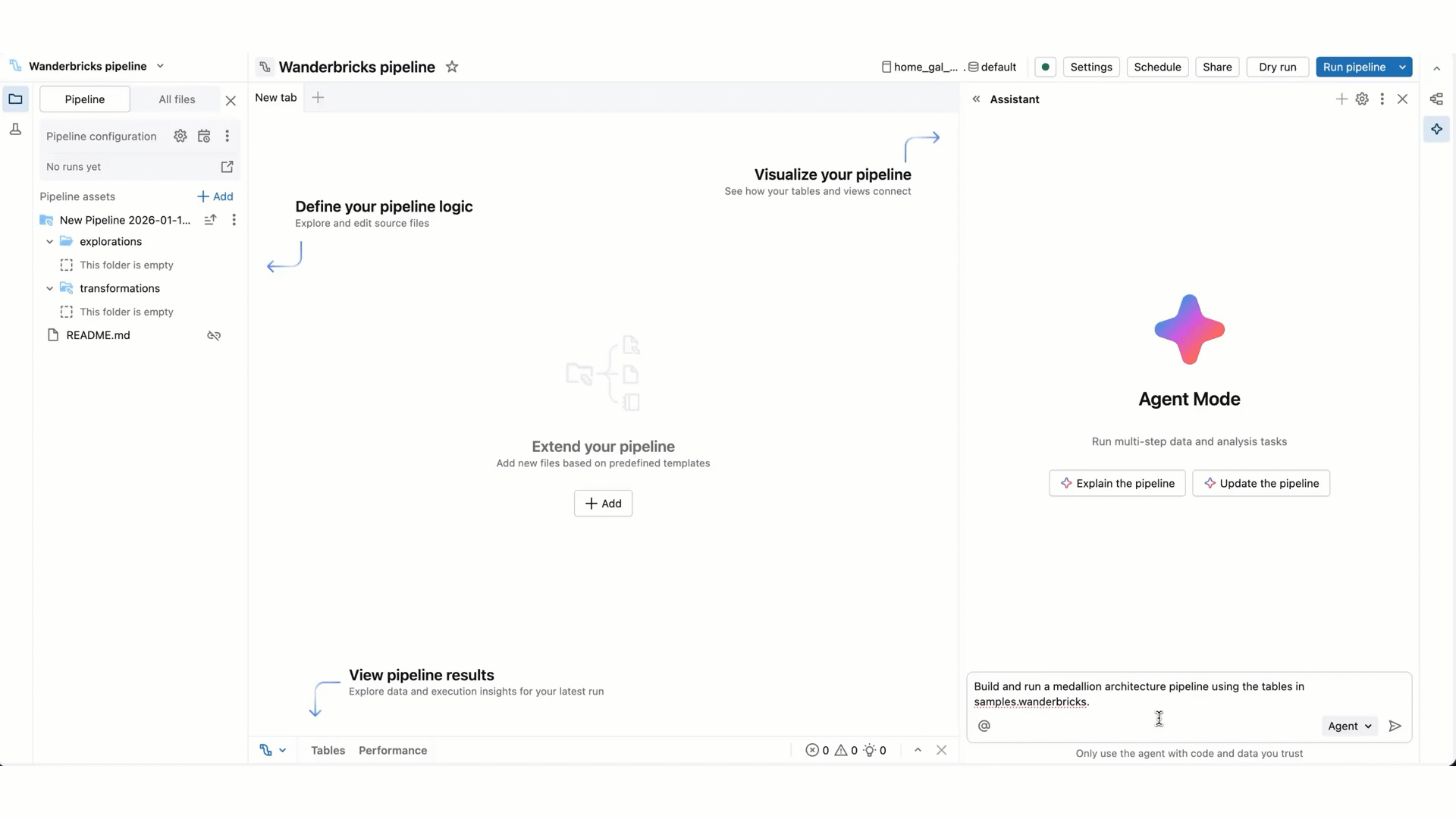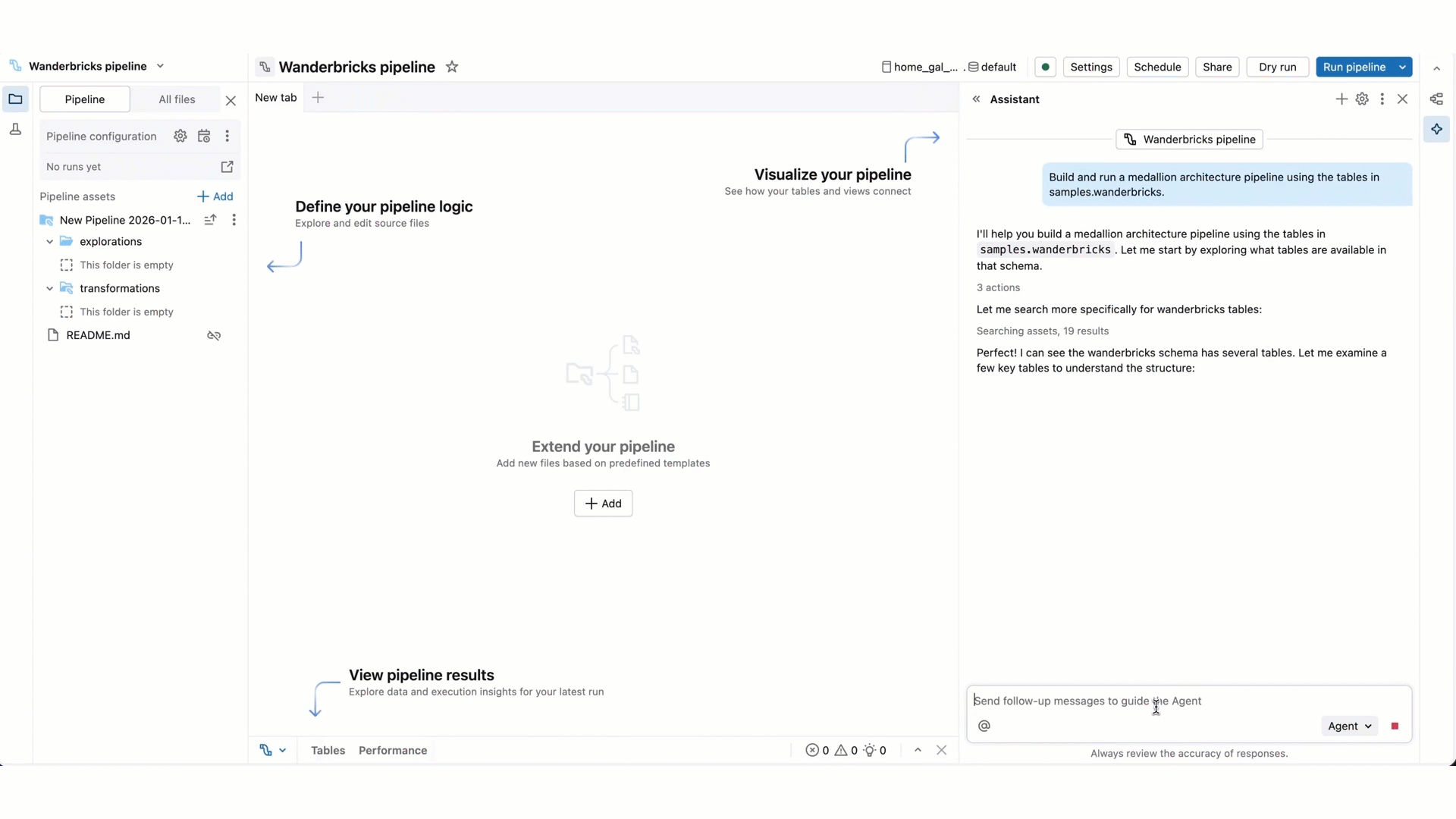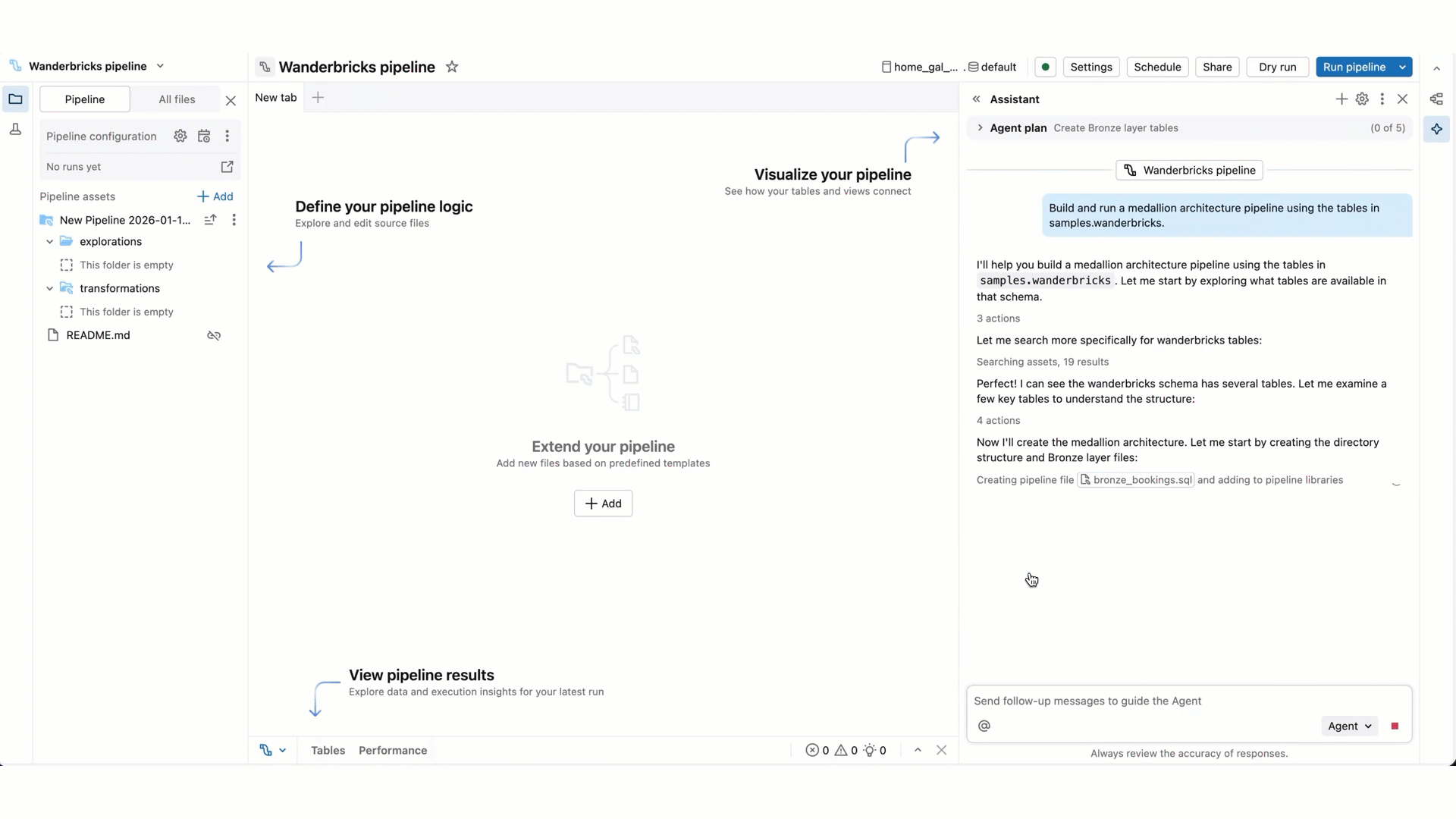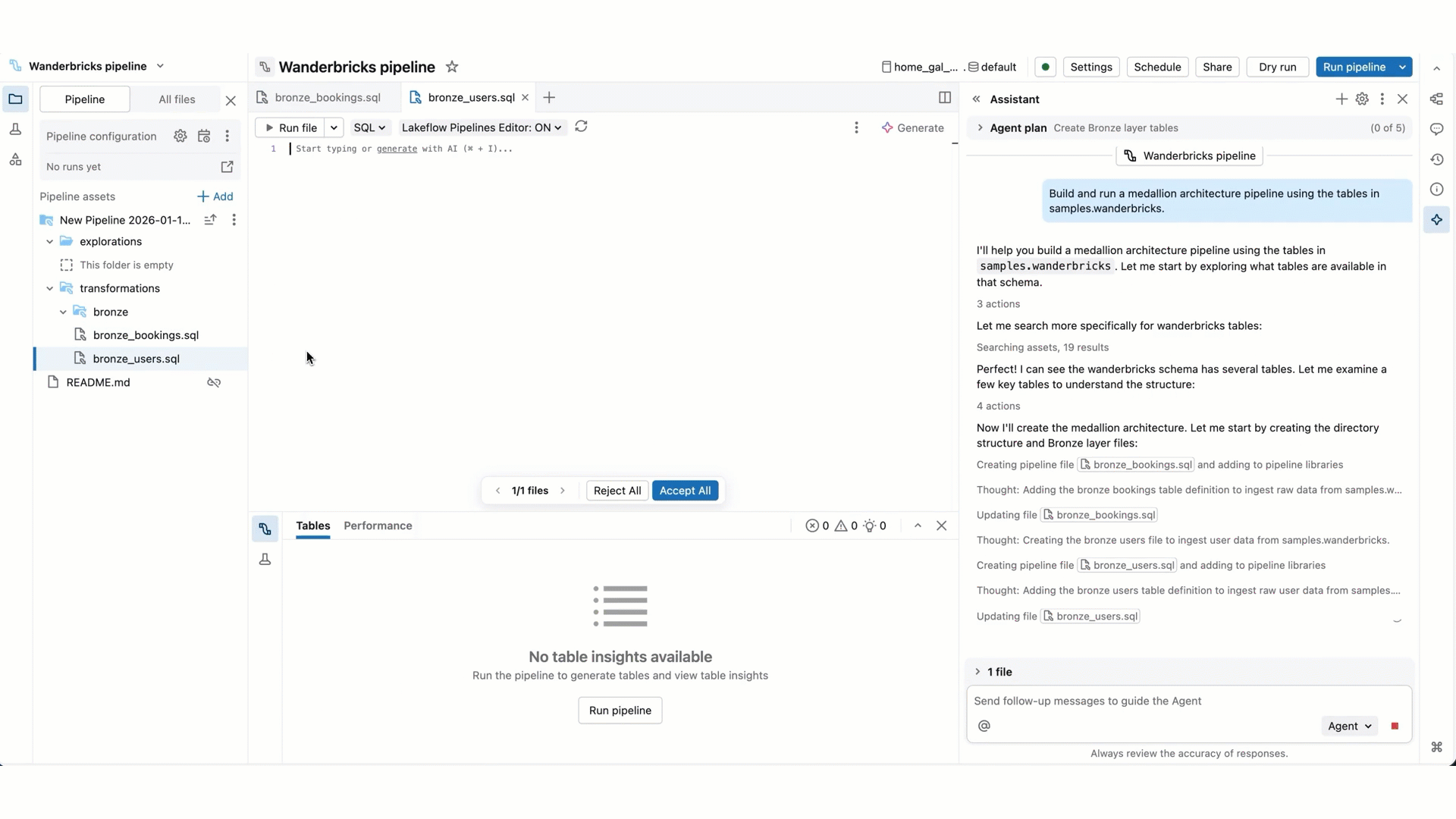
Em comparação com o modo de chat do Genie Code, o modo agente expandiu os recursos: planejamento de uma solução, recuperação de ativos relevantes, execução de código, uso de saídas de pipeline para melhorar os resultados, corrigir erros automaticamente e muito mais.
O Genie Code no modo Agent pode planejar e gerar pipelines inteiros de ponta a ponta do zero ou acelerar o trabalho em um pipeline existente. O agente trabalha com você para aprovar seus planos e confirmar suas próximas etapas antes de prosseguir. Com sua aprovação, o Genie Code pode usar ferramentas para executar tarefas como pesquisar tabelas, editar um SQL ou Python arquivo de origem, executar atualizações de pipeline e ler conjuntos de dados de pipeline.
O acesso e as ações do Genie Code são regidos pelas permissões do usuário. Ele só pode acessar dados aos quais você tem acesso e executar operações para as quais você tem permissões.
Observação
Quando você ativa o modo Agente no Genie Code, o Genie Code adapta suas funcionalidades com base nos recursos que você está usando atualmente no Databricks. Por exemplo, no Editor do Lakeflow Pipelines, o Genie Code se concentra em tarefas de edição de pipeline e engenharia de dados. Em notebooks e no Editor de SQL, o Genie Code dá suporte à exploração e análise de dados. Consulte Usar Genie Code para ciência de dados para mais informações.
Requirements
Para usar o Genie Code para engenharia de dados, seu workspace precisa do seguinte:
- Recursos de IA impulsionados por parceiros habilitados tanto para a conta quanto para o espaço de trabalho. Consulte recursos de IA impulsionados por parceiros.
- Seu workspace deve estar em uma região com suporte. O Genie Code é um serviço designado que usa o Geos para gerenciar a residência de dados. Consulte a disponibilidade geográfica dos recursos do Genie Code.
Usar Genie Code para desenvolvimento de pipelines
Para usar as capacidades agenticas do Genie Code para o desenvolvimento de pipeline:
No Editor do Lakeflow Pipelines, abra o painel lateral do Genie Code clicando no
 Genie Code no canto superior direito do seu workspace.
Genie Code no canto superior direito do seu workspace.No canto inferior direito, selecione Agente. Isso alterna para o modo Agente do Genie Code, permitindo que você utilize os recursos de engenharia de dados direcionada do Genie Code.
Insira um prompt para o Genie Code. Por exemplo, você pode fazer perguntas sobre seu pipeline, como "descreva este pipeline". Você também pode solicitar que adicione novos conjuntos de dados, por exemplo: "criar silver_sales_data em um novo arquivo que lê de bronze_sales_data, limpa os dados e inclui expectativas de qualidade úteis".
Observação
O Genie Code respeita as permissões do Catálogo do Unity do usuário, portanto, ele só pode acessar a fonte de dados e pipeline à qual você tem acesso.
À medida que o Genie Code gera sua resposta, ele geralmente faz uma pausa para obter sua entrada:
Para tarefas mais complexas, o Genie Code pode criar um plano passo a passo e fazer perguntas esclarecedoras. Responda às suas perguntas esclarecedoras para ajudá-lo a aprimorar seu plano.
Quando o Genie Code precisa executar o código ou atualizar um pipeline, ele solicita sua aprovação antes de continuar. Permitir ou recusar sua solicitação. Você também pode selecionar Permitir neste thread (referindo-se ao thread de conversa do Genie Code) ou Sempre permitir.
Importante
O Genie Code no modo Agent pode gerar e executar código em seu pipeline. Embora tenha guardrails para evitar ações perigosas, ainda há risco. Você só deve usá-lo com dados confiáveis e deve examinar o código antes de executá-lo.
À medida que o Genie Code continua seu trabalho, você pode ser solicitado a selecionar Continuar ou Rejeitar. Examine seu trabalho existente e, em seguida, selecione Continuar para permitir que ele continue para suas próximas etapas ou rejeite dizer-lhe para tentar outra coisa.
Para interromper o Genie Code enquanto ele estiver funcionando, clique no
 .
.
O Genie Code pode criar novos arquivos, gerar texto, consultas e código, executar os arquivos ou pipelines e acessar os conjuntos de dados de saída para interpretar os resultados.
Observação
Para que o Genie Code continue seu trabalho e execute as próximas etapas, você precisa permanecer na guia atual em que ele está funcionando.
Dica
Você pode adicionar instruções para o Genie Code usar na maioria das respostas. Por exemplo, se você tiver convenções de código que deseja usar ou bibliotecas preferenciais a serem usadas, poderá adicionar essas diretrizes às instruções do Genie Code. Você também pode criar habilidades para estender o Genie Code com funcionalidades especializadas para suas tarefas específicas de domínio. Para obter mais detalhes e outras dicas, consulte Dicas para melhorar as respostas do Genie Code.
Capabilities
No modo agente, o Genie Code pode ajudar na maioria das tarefas de desenvolvimento de pipeline. As principais funcionalidades incluem:
- Descoberta de dados: o Genie Code pode pesquisar tabelas no workspace para ajudá-lo a encontrar os dados necessários para uma tarefa.
- Edições de código de Pipeline: Genie Code pode criar e editar vários arquivos de cada vez. Ele mantém você informado sobre quais arquivos ele está mudando e mostra a diferença de código em cada arquivo, para que você possa examinar as alterações individualmente ou todas juntas no final.
- Execução de Pipeline: o Genie Code pode executar arquivos individuais, realizar uma execução simulada/real do pipeline ou realizar uma atualização completa. Quando o Genie Code deseja continuar, ele solicita sua confirmação antes de fazer isso.
- Entendendo e melhorando o comportamento do pipeline: o Genie Code pode inspecionar conjuntos de dados e saídas de pipeline para ajudá-lo a entender o que um pipeline está fazendo de ponta a ponta e por quê. Por exemplo, ele pode resumir transformações, rastrear como os dados fluem para tabelas downstream e realçar alterações inesperadas em contagens de linhas ou esquemas. Quando ele apresenta possíveis problemas de qualidade de dados, o Genie Code pode ajudá-lo a raciocinar sobre sua causa e sugerir onde e como resolvê-los no pipeline.
Esses recursos dão suporte a casos de uso comuns, como:
- Criando um novo pipeline: o Genie Code pode ajudar com todas as etapas de criação de um pipeline de arquitetura de medalhão, desde a ingestão de dados até a padronização e limpeza dos dados, até a transformação e a análise dos dados.
- Explicar um pipeline: o Genie Code pode analisar e explicar um pipeline existente para ajudá-lo a aumentar rapidamente.
- Corrigir problemas: quando você tem erros, o Genie Code pode ajudar a diagnosticar e corrigir os problemas, iterando por vários arquivos até que o problema seja resolvido.
Exemplos
Experimente os seguintes prompts para começar:
- "Crie e execute um pipeline de arquitetura de medalhão para detecção de fraude usando as transações de tabela e os clientes em my_catalog.my_schema.".
- "Explique cada etapa deste fluxo de dados."
- Corrija a falha neste processo.
Próximas etapas
- Saiba mais sobre os recursos assistenciais de IA do Databricks
- Obtenha dicas para melhorar as respostas do Genie Code
- Usar o Genie Code para ciência de dados, para descoberta e exploração de dados
- Usar o Genie Code para criação de dashboard
- Explorar o Editor de Pipelines do Lakeflow