Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os pipelines podem conter muitos conjuntos de dados com muitos fluxos para mantê-los atualizados. Os pipelines gerenciam automaticamente atualizações e clusters para serem atualizados com eficiência. No entanto, há alguma sobrecarga com o gerenciamento de um grande número de fluxos e, às vezes, isso pode levar a uma inicialização maior do que o esperado ou até mesmo à sobrecarga de gerenciamento durante o processamento.
Se você estiver enfrentando atrasos ao aguardar a inicialização de pipelines acionados, como tempos de inicialização superiores a cinco minutos, considere dividir o processamento em vários pipelines, mesmo quando os conjuntos de dados usam a mesma fonte de dados.
Observação
Os pipelines acionados realizam as etapas de inicialização cada vez que são iniciados. Os pipelines contínuos só executam as etapas de inicialização quando são interrompidos e reiniciados. Esta seção é mais útil para otimizar a inicialização de pipeline disparada.
Quando considerar a divisão de um pipeline
Há vários casos em que a divisão de um pipeline pode ser vantajosa por motivos de desempenho.
- As fases
INITIALIZINGeSETTING_UP_TABLESlevam mais tempo do que o desejado, afetando o tempo geral do pipeline. Se isso levar mais de 5 minutos, muitas vezes é útil dividir o seu pipeline. - O driver que gerencia o cluster pode se tornar um gargalo ao executar muitas tabelas de streaming (mais de 30-40) em um único pipeline. Se o driver não responder, as durações das consultas de streaming aumentarão, afetando o tempo total da atualização.
- Um pipeline disparado com vários fluxos de tabelas de streaming pode não ser capaz de executar todas as atualizações de fluxo que podem ser realizadas em paralelo.
Detalhes sobre problemas de desempenho
Esta seção descreve alguns dos problemas de desempenho que podem surgir de ter muitas tabelas e fluxos em um único pipeline.
Gargalos nas fases INICIALIZAÇÃO e CONFIGURAÇÃO_DAS_TABELAS
As fases iniciais da execução podem ser um gargalo de desempenho, dependendo da complexidade do pipeline.
Fase de inicialização
Durante essa fase, são criados planos lógicos, incluindo planos para criar o grafo de dependência e determinar a ordem das atualizações da tabela.
fase CONFIGURAÇÃO_DAS_TABELAS
Durante essa fase, os seguintes processos são executados, com base nos planos criados na fase anterior:
- Validação e resolução de esquema para todas as tabelas definidas no pipeline.
- Crie o grafo de dependência e determine a ordem de execução da tabela.
- Verifique se cada conjunto de dados está ativo no pipeline ou se é novo desde qualquer atualização anterior.
- Crie tabelas de streaming na primeira atualização e, para exibições materializadas, crie exibições temporárias ou tabelas de backup necessárias durante cada atualização de pipeline.
Por que INICIALIZAR e CONFIGURAR_TABELAS podem levar mais tempo
Pipelines grandes com muitos fluxos para muitos conjuntos de dados podem levar mais tempo por vários motivos:
- Para pipelines com muitos fluxos e dependências complexas, essas fases podem levar mais tempo devido ao volume de trabalho a ser feito.
- Transformações complexas, incluindo
Auto CDCtransformações, podem causar um gargalo de desempenho devido às operações necessárias para materializar as tabelas com base nas transformações definidas. - Há também cenários em que um número significativo de fluxos pode causar lentidão, mesmo que esses fluxos não façam parte de uma atualização. Por exemplo, considere um pipeline com mais de 700 fluxos, dos quais menos de 50 são atualizados para cada gatilho, com base em uma configuração. Neste exemplo, cada execução deve percorrer algumas das etapas para todas as 700 tabelas, obter os dataframes e selecionar as que serão executadas.
Gargalos do driver
O driver gerencia as atualizações dentro da execução. Ele deve executar alguma lógica para cada tabela, para decidir quais instâncias em um cluster devem lidar com cada fluxo. Ao executar várias tabelas de streaming (mais de 30-40) em um único pipeline, o driver pode se tornar um gargalo para recursos de CPU à medida que lida com o trabalho em todo o cluster.
O driver também pode encontrar problemas de memória. Isso pode acontecer com mais frequência quando o número de fluxos paralelos é 30 ou mais. Não há um número específico de fluxos ou conjuntos de dados que possa causar problemas de memória do driver, mas depende da complexidade das tarefas que estão em execução em paralelo.
Os fluxos de streaming podem ser executados em paralelo, mas isso requer que o driver use memória e CPU para todos os fluxos simultaneamente. Em um pipeline disparado, o driver pode processar um subconjunto de fluxos em paralelo de cada vez, para evitar restrições de memória e CPU.
Em todos esses casos, a divisão de pipelines para que haja um conjunto ideal de fluxos em cada um pode acelerar o tempo de inicialização e processamento.
Compensações com a divisão de pipelines
Quando todos os seus fluxos estão dentro de um único pipeline, o "Lakeflow Spark Declarative Pipelines" gerencia as dependências para você. Quando há múltiplos pipelines, você deve gerenciar as dependências entre os pipelines.
Dependências Você pode ter um pipeline downstream que depende de vários pipelines upstream (em vez de um). Por exemplo, se você tiver três pipelines,
pipeline_A,pipeline_B, epipeline_C, epipeline_Cdepender de ambospipeline_Aepipeline_B, você deseja quepipeline_Catualize somente depois que tantopipeline_Aquantopipeline_Btiverem concluído suas respectivas atualizações. Uma maneira de resolver isso é orquestrar as dependências, tornando cada pipeline uma tarefa em um job com as dependências modeladas corretamente, de modo quepipeline_Csó seja atualizado após a conclusão depipeline_Aepipeline_B.Simultaneidade Você pode ter fluxos diferentes em um pipeline que levam tempos muito diferentes para serem concluídos, por exemplo, se
flow_Aforem atualizados em 15 segundos eflow_Blevarem vários minutos. Pode ser útil examinar os tempos de consulta antes de dividir seus pipelines e agrupar consultas mais curtas.
Planejar a divisão dos seus pipelines
Você pode visualizar a divisão do pipeline antes de começar. Aqui está um gráfico de um pipeline de origem que processa 25 tabelas. Uma única fonte de dados raiz é dividida em 8 segmentos, cada um com dois modos de exibição.
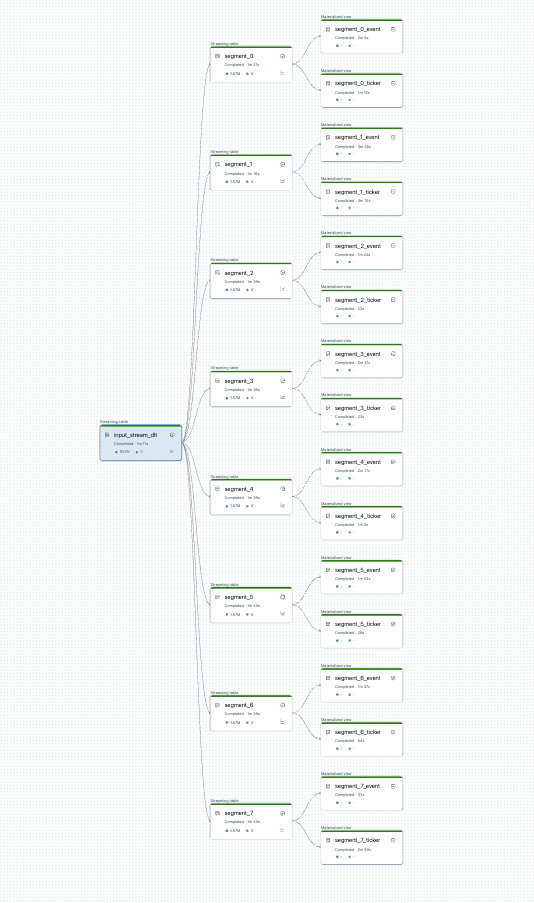
Após dividir o pipeline, existem dois pipelines. Processa-se a fonte de dados raiz única, 4 segmentos e as exibições associadas. O segundo pipeline processa os outros 4 segmentos e suas exibições associadas. O segundo pipeline depende do primeiro para atualizar a fonte de dados raiz.
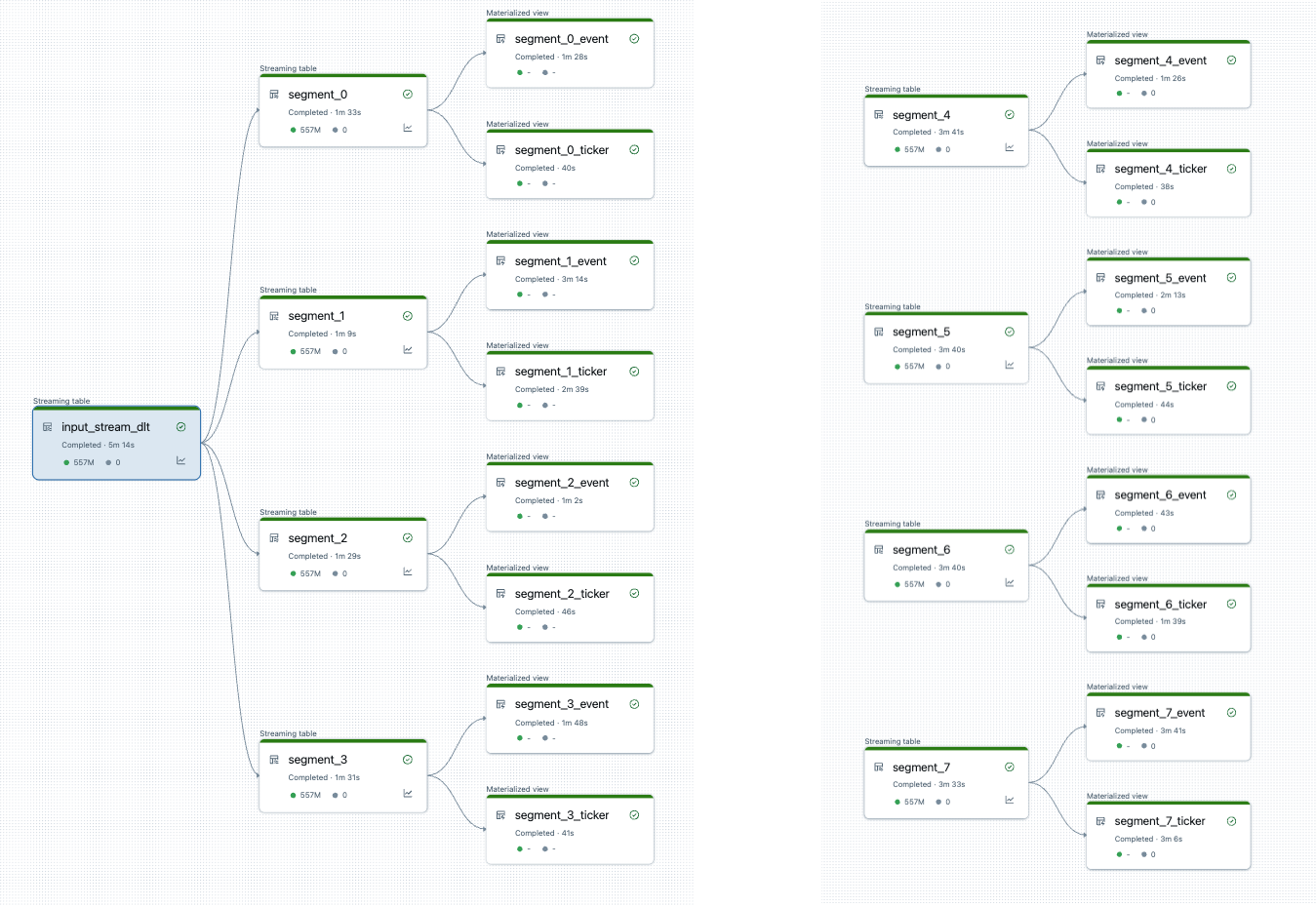
Dividir o pipeline sem uma atualização completa
Depois de planejar a divisão do pipeline, crie os novos pipelines necessários e mova tabelas entre os pipelines para realizar o balanceamento de carga. Você pode mover tabelas sem causar uma atualização completa.
Para ter detalhes, consulte Mover tabelas entre pipelines.
Há algumas limitações com essa abordagem:
- Os pipelines devem estar no Catálogo do Unity.
- Os pipelines de origem e de destino devem estar dentro do mesmo workspace. Não há suporte para movimentos entre espaços de trabalho.
- O pipeline de destino deve ser criado e executado uma vez (mesmo que tenha falhas) antes da transferência.
- Você não pode mover uma tabela de um pipeline que usa o modo de publicação padrão para um que usa o modo de publicação herdado. Para obter mais detalhes, consulte o esquema LIVE (herdado).