Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Dica
Um bom complemento para as explicações neste guia é o guia Modelo de Dados de Rastreamento, que mostrará como o Rastreamento do MLflow representa os conceitos discutidos aqui.
O que é rastreamento?
O rastreamento no contexto do ML (machine learning) refere-se ao acompanhamento e ao registro detalhados do fluxo de dados e das etapas de processamento durante a execução de um modelo de ML. Ele fornece transparência e insights sobre cada estágio da operação do modelo, desde a entrada de dados até a saída da previsão. Esse acompanhamento detalhado é crucial para depurar, otimizar e entender o desempenho de modelos de ML.
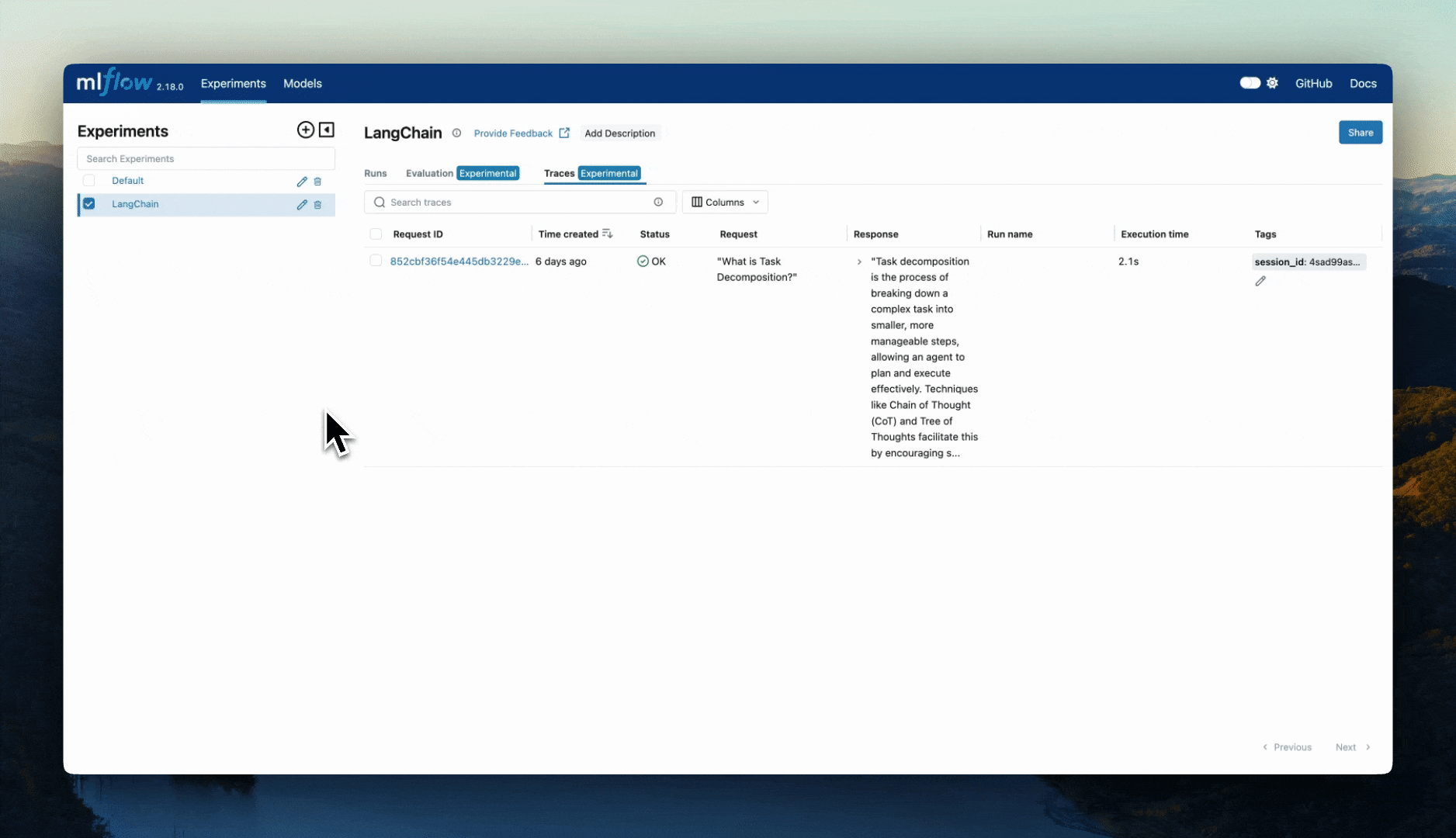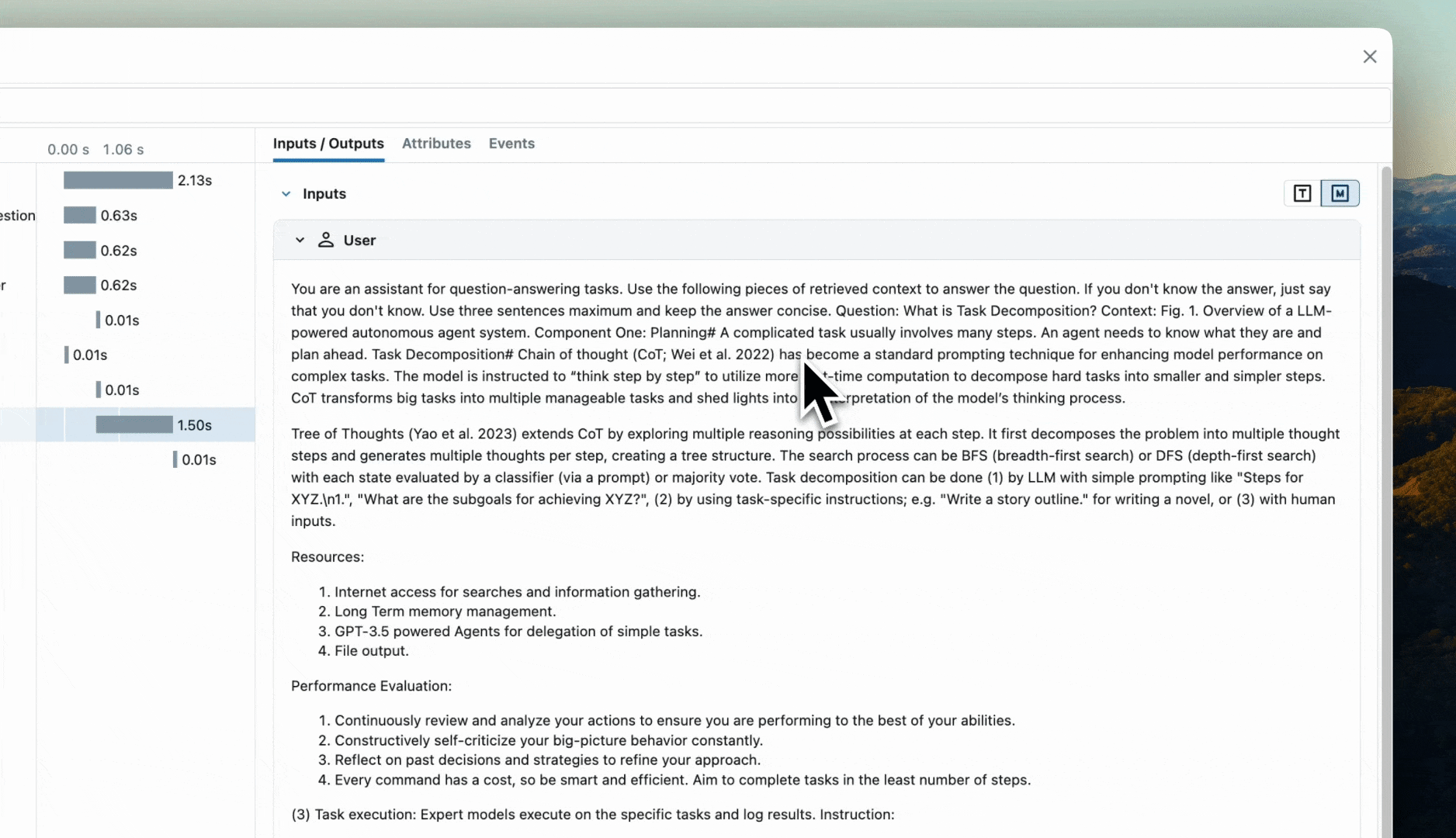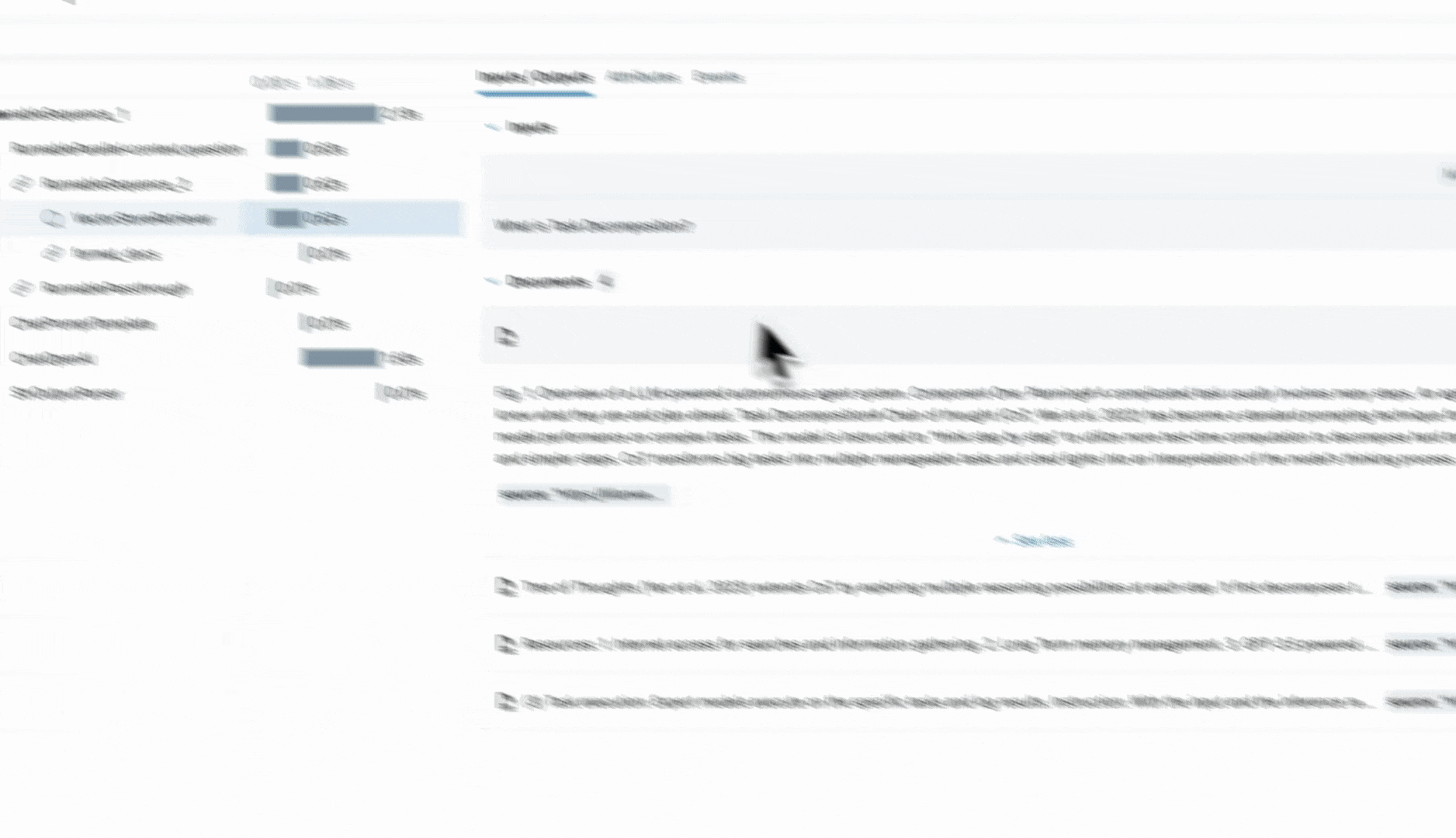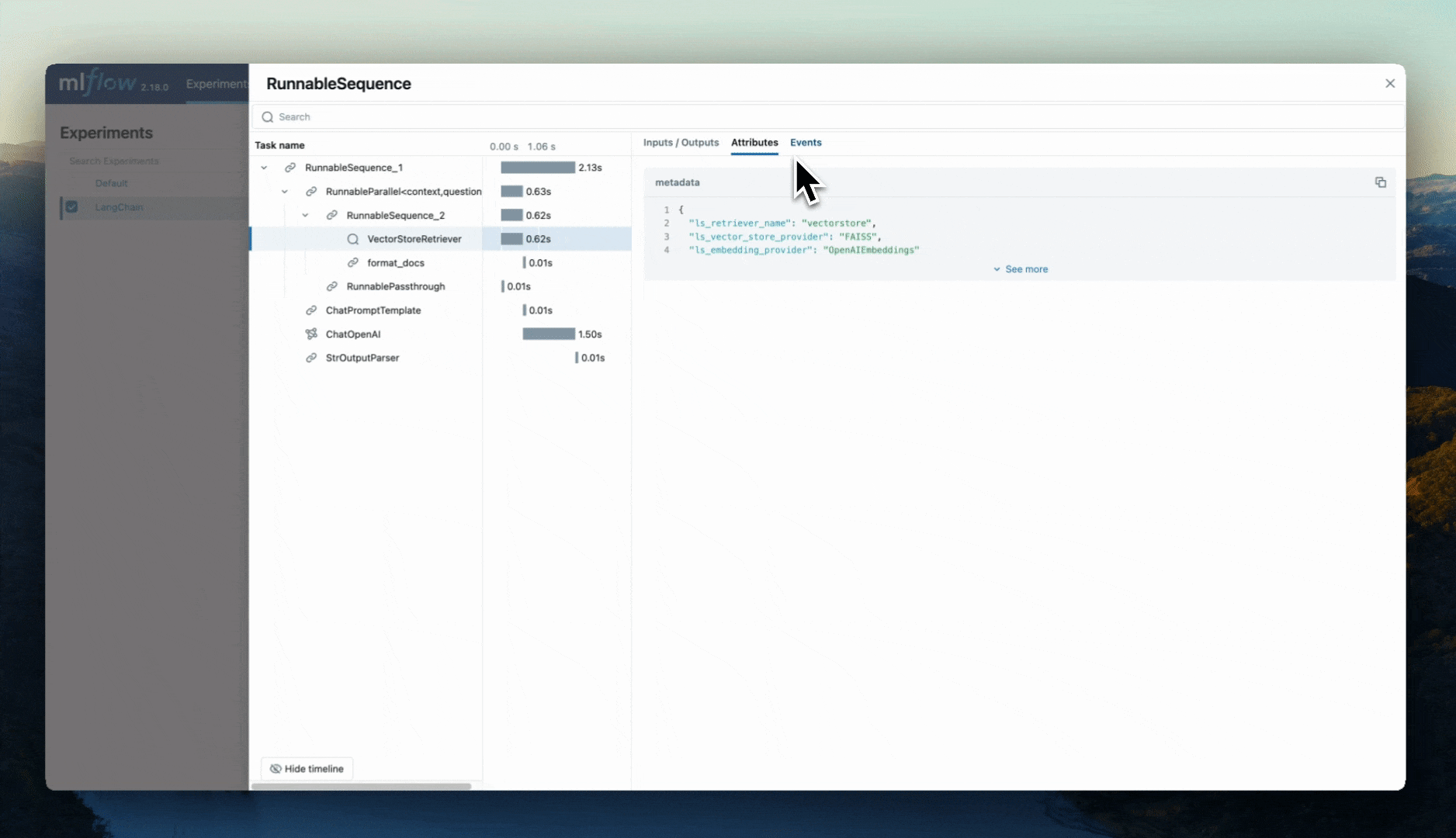
Conceito de um intervalo
No contexto do rastreamento, um intervalo representa uma única operação dentro do sistema. Ele captura metadados como a hora de início, a hora de término e outras informações contextuais sobre a operação. Junto com os metadados, as entradas fornecidas para uma unidade de trabalho (como uma chamada para um modelo genai, uma consulta de recuperação de um repositório de vetores ou uma chamada de função), bem como a saída da operação, são registradas.
O diagrama a seguir ilustra uma chamada para um modelo GenAI e a coleta de informações relevantes em um intervalo. O intervalo inclui metadados como a hora de início, a hora de término e os argumentos de solicitação, bem como a entrada e a saída da chamada de invocação.
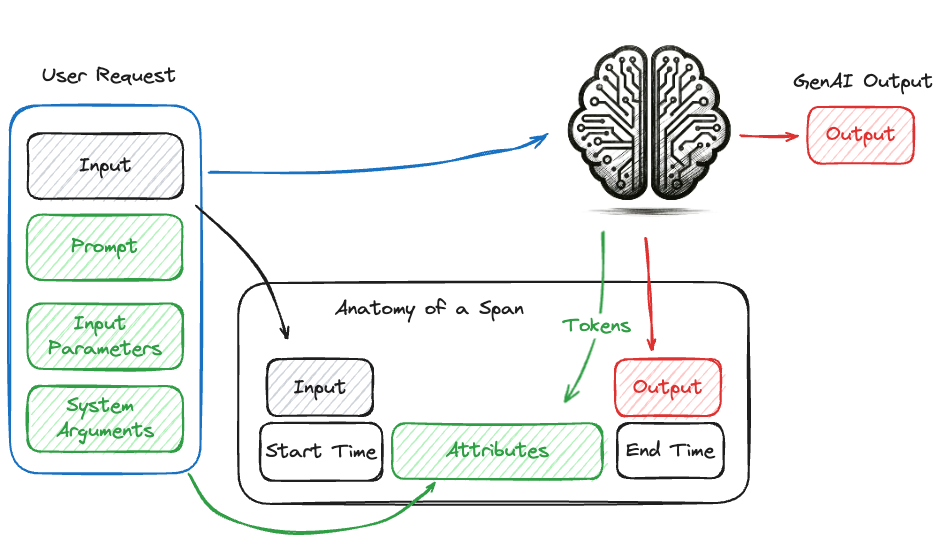
Conceito de um traço
Um rastreamento no contexto do GenAI é uma coleção de eventos de intervalo semelhantes a grafos direcionados acíclicos (DAG) que são chamados e registrados assincronamente em um processador. Cada intervalo representa uma única operação dentro do sistema e inclui metadados como hora de início, hora de término e outras informações contextuais. Esses intervalos são vinculados para formar um rastreamento, o que fornece uma visão abrangente do processo de ponta a ponta.
- Estrutura semelhante a DAG: a estrutura DAG garante que não haja ciclos na sequência de operações, facilitando a compreensão do fluxo de execução.
- Informações sobre o Span: cada span captura uma unidade de trabalho discreta, como uma chamada de função, uma consulta de banco de dados ou uma requisição de API. Os intervalos incluem metadados que fornecem contexto sobre a operação.
- Associação Hierárquica: os intervalos espelham a estrutura de seus aplicativos, permitindo que você veja como diferentes componentes interagem e dependem uns dos outros.
Ao coletar e analisar esses intervalos, é possível rastrear o caminho de execução, identificar gargalos e entender as dependências e interações entre diferentes componentes do sistema. Esse nível de visibilidade é crucial para diagnosticar problemas, otimizar o desempenho e garantir a robustez dos aplicativos GenAI.
Para ilustrar o que um rastreamento inteiro pode capturar em um aplicativo RAG, consulte a ilustração abaixo.
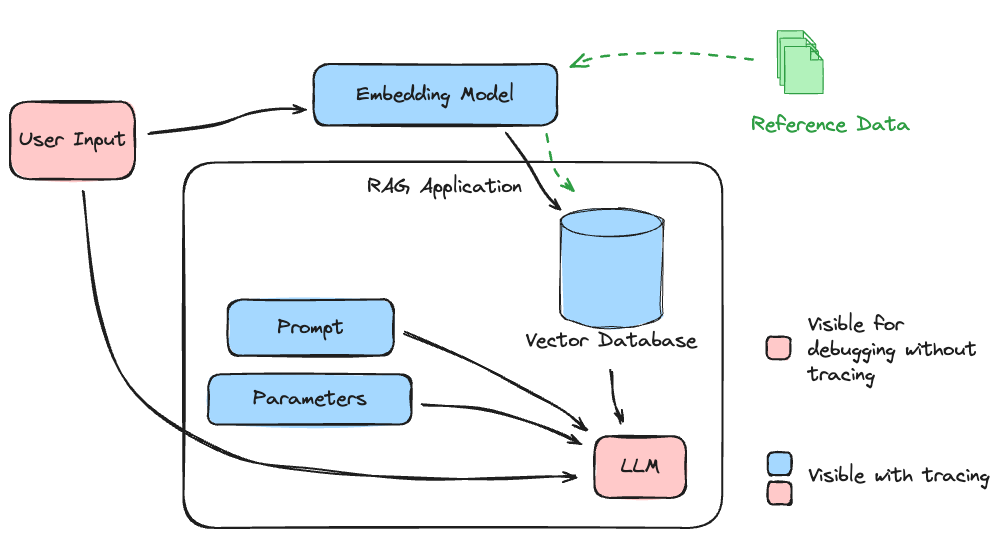
Os subsistemas envolvidos neste aplicativo são essenciais para a qualidade e a relevância do sistema. Não ter visibilidade dos caminhos que os dados seguirão ao interagir com o LLM de estágio final cria um aplicativo cuja qualidade só poderia ser obtida por um alto grau de validação manual monótona, entediante e cara de cada parte de forma isolada.
Caso de uso de ChatCompletions do GenAI
Em aplicativos GenAI (Generative AI), como conclusões de chat, o rastreamento torna-se muito mais importante para os desenvolvedores de modelos e aplicativos alimentados por GenAI. Esses casos de uso envolvem a geração de texto semelhante ao humano com base em prompts de entrada. Embora não seja tão complexo quanto aplicativos GenAI que envolvem agentes ou recuperação informativa para aumentar um modelo de GenAI, uma interface de chat pode se beneficiar do rastreamento. Habilitar o rastreamento em interfaces por interação com um modelo GenAI por meio de uma sessão de chat permite avaliar todo o histórico contextual, prompt, entrada e parâmetros de configuração, juntamente com a saída, encapsulando o contexto completo do payload da solicitação que foi enviado para o modelo GenAI.
Como exemplo, a ilustração abaixo mostra a natureza de uma interface ChatCompletions usada para conectar um modelo, hospedado em um servidor de implantação, a um serviço de GenAI externo.

Metadados adicionais relacionados ao processo de inferência são úteis por vários motivos, incluindo cobrança, avaliação de desempenho, relevância, avaliação de alucinações e depuração em geral. Os metadados de chave incluem:
- Contagens de tokens: o número de tokens processados, que afeta a cobrança.
- Nome do modelo: o modelo específico usado para inferência.
- Tipo de provedor: o serviço ou a plataforma que fornece o modelo.
- Parâmetros de consulta: configurações como temperatura e top-k que influenciam o processo de geração.
- Entrada de consulta: a entrada da solicitação (pergunta do usuário).
- Resposta de consulta: a resposta gerada pelo sistema para a consulta de entrada, utilizando os parâmetros de consulta para ajustar a geração.
Esses metadados ajudam a entender como diferentes configurações afetam a qualidade e o desempenho das respostas geradas, auxiliando no ajuste fino e na otimização.
Aplicativos RAG (geração avançada aumentada de recuperação)
Em aplicativos mais complexos, como o RAG (geração de Retrieval-Augmented), o rastreamento é essencial para depuração e otimização eficazes. RAG envolve vários estágios, incluindo recuperação de documentos e interação com modelos GenAI. Quando apenas a entrada e a saída estão visíveis, torna-se desafiador identificar a origem de problemas ou oportunidades de melhoria.
Por exemplo, se um sistema GenAI gerar uma resposta insatisfatória, o problema poderá estar em:
- Otimização de Armazenamento de Vetores: a eficiência e a precisão do processo de recuperação de documentos.
- Modelo de inserção: a qualidade do modelo usado para codificar e pesquisar documentos relevantes.
- Material de Referência: o conteúdo e a qualidade dos documentos que estão sendo consultados.
O rastreamento permite que cada etapa dentro do pipeline RAG seja investigada e avaliada quanto à qualidade. Ao fornecer visibilidade em cada estágio, o rastreamento ajuda a identificar onde os ajustes são necessários, seja no processo de recuperação, no modelo de inserção ou no conteúdo do material de referência.
Por exemplo, o diagrama a seguir ilustra as interações complexas que formam uma aplicação RAG simples, em que o modelo GenAI é chamado repetidamente com dados adicionais obtidos que orientam a geração da resposta final de saída.
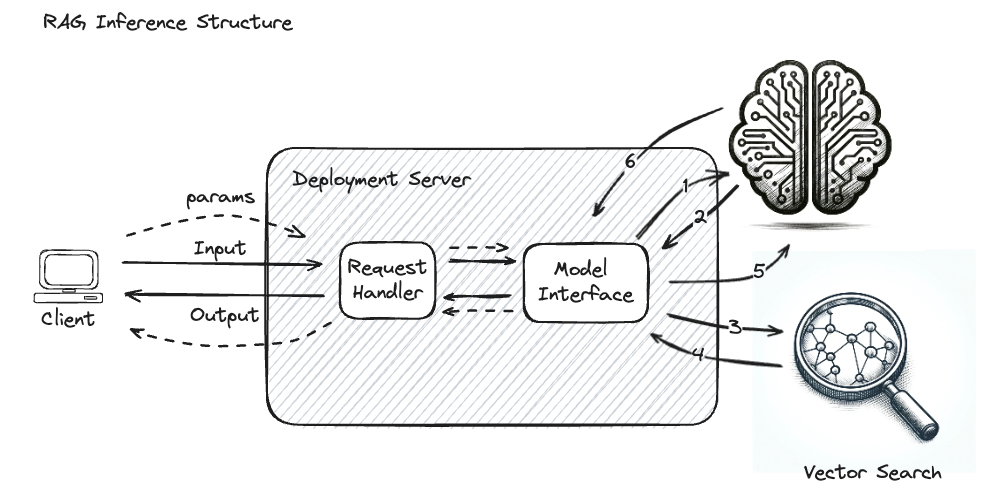
Sem o rastreamento habilitado em um sistema tão complexo, é desafiador identificar a causa raiz de problemas ou gargalos. As seguintes etapas seriam efetivamente uma "caixa preta":
- Inserção da consulta de entrada
- O retorno do vetor de consulta codificado
- A entrada de pesquisa de vetor
- Os fragmentos do documento recuperados do Banco de Dados Vetor
- A entrada final para o modelo GenAI
Diagnosticar problemas de correção com respostas nesse sistema sem que essas 5 etapas críticas tenham a instrumentação configurada para capturar as entradas, as saídas e os metadados associados a cada solicitação cria um cenário desafiador para depurar, melhorar ou refinar esse aplicativo. Ao considerar o ajuste de desempenho para capacidade de resposta ou custo, não ter a visibilidade de latências para cada uma dessas etapas apresenta um desafio totalmente diferente que exigiria a configuração e a instrumentação manual de cada um desses serviços.
Introdução ao rastreamento no MLflow
Para saber como utilizar o rastreamento no MLflow, consulte o Guia de Rastreamento do MLflow.
Além do GenAI: Rastreamento do Machine Learning Tradicional
Observação
Embora essa documentação se concentre em aplicativos GenAI em que o rastreamento fornece mais valor, o Rastreamento de MLflow também pode ser aplicado a fluxos de trabalho ML tradicionais. A seção a seguir descreve brevemente esse caso de uso para um entendimento completo.
No ML tradicional, o processo de inferência é relativamente simples. Quando uma solicitação é feita, os dados de entrada são alimentados no modelo, que processa os dados e gera uma previsão.
O diagrama a seguir ilustra a relação entre os dados de entrada, a interface de serviço do modelo e o próprio modelo.
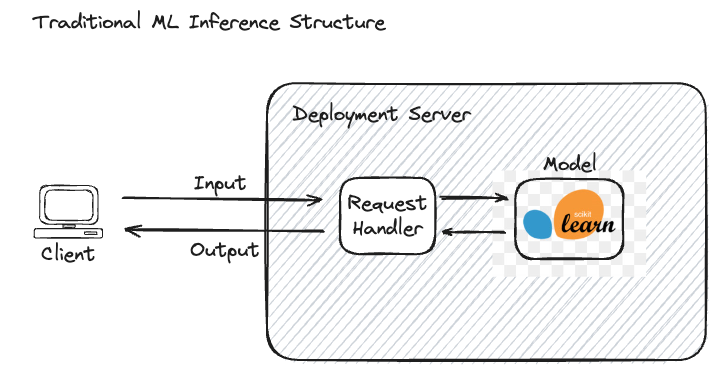
Esse processo é totalmente visível, o que significa que a entrada e a saída são claramente definidas e compreensíveis para o usuário final. Por exemplo, em um modelo de detecção de spam, a entrada é um email e a saída é um rótulo binário que indica se o email é spam ou não. Todo o processo de inferência é transparente, facilitando a determinação de quais dados foram enviados e qual previsão foi retornada, renderizando o rastreamento completo de um processo em grande parte irrelevante no contexto do desempenho do modelo qualitativo.
No entanto, o rastreamento pode ser incluído como parte de uma configuração de implantação para fornecer insights adicionais sobre a natureza do processamento das solicitações feitas ao servidor, a latência da previsão do modelo e para registrar em log o acesso à API ao sistema. Para essa forma clássica de registro de rastreamento em log, na qual os metadados associados às solicitações de inferência são monitorados e registrados sob a perspectiva de latência e desempenho, esses logs normalmente não são usados por desenvolvedores de modelos ou cientistas de dados para entender a operação do modelo.
Próximas etapas
Continue seu percurso com essas ações e tutoriais recomendados.
- Instrumentar seu aplicativo com rastreamento – saiba como adicionar rastreamento ao seu aplicativo GenAI
- Depurar e observar seu aplicativo – Use rastreamentos para analisar o comportamento do aplicativo
- Usar rastreamentos para melhorar a qualidade – Aproveitar os rastreamentos para aprimoramentos sistemáticos
Guias de referência
Explore a documentação detalhada sobre os conceitos relacionados.
- Modelo de dados de rastreamento – Entender como o MLflow representa rastreamentos e intervalos
- Consultar rastreamentos por meio do SDK – Aprender análise de rastreamento programático
- Avaliações de log – Entender como anexar comentários a rastreamentos