Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Crie um agente de IA inteligente usando o TypeScript e o Azure DocumentDB. Este início rápido demonstra uma arquitetura de dois agentes que executa uma pesquisa semântica de hotéis e gera recomendações personalizadas.
Importante
Este exemplo usa o LangChain, uma estrutura popular para a criação de aplicativos de IA. O LangChain fornece abstrações para agentes, ferramentas e prompts que simplificam o desenvolvimento de agentes.
Pré-requisitos
Você pode usar a CLI do Desenvolvedor do Azure para criar os recursos necessários do Azure executando os azd comandos no repositório de exemplo. Para obter mais informações, consulte Implantar Infraestrutura com a CLI do Desenvolvedor do Azure.
Recursos do Azure
Recurso do Azure OpenAI no Microsoft Foundry Models (clássico) com as seguintes implantações de modelo no Microsoft Azure AI Foundry:
- Implantação de
gpt-4o(Agente Sintetizador) – Recomendado: capacidade de 50.000 tokens por minuto (TPM) - Implantação de
gpt-4o-mini(Agente Planejador) – Recomendado: capacidade de 30.000 tokens por minuto (TPM) - Implantação de
text-embedding-3-small(Inserções) – Recomendado: capacidade de 10.000 tokens por minuto (TPM) -
Cotas de token: configurar TPM suficiente para cada implantação a fim de evitar a limitação de taxa
- Consulte Gerenciar cotas do Azure OpenAI para gerenciamento de cotas
- Se você encontrar 429 erros, aumente a cota do TPM ou reduza a frequência da solicitação
- Implantação de
Cluster do Azure DocumentDB (com compatibilidade do MongoDB) com suporte à pesquisa de vetor:
-
Requisitos de camada de cluster com base no algoritmo de índice de vetor preferencial:
- FIV (Índice de Arquivo Invertido): M10 ou superior (algoritmo padrão)
- HNSW (Mundo Pequeno Navegável Hierárquico): M30 ou superior (baseado em grafo)
- DiskANN: M40 ou superior (otimizado para grande escala)
-
Configuração do firewall: OBRIGATÓRIO. Sem a configuração de firewall adequada, as tentativas de conexão falham.
- Adicione o endereço IP do cliente às regras de firewall do cluster. Para obter mais informações, consulte Conceder acesso a partir do seu endereço IP.
- Para autenticação sem senha, verifique se o RBAC (controle de acesso baseado em função) está habilitado.
-
Requisitos de camada de cluster com base no algoritmo de índice de vetor preferencial:
Ferramentas de desenvolvimento
- CLI do Desenvolvedor do Azure para provisionamento de recursos
- Node.js LTS
- TypeScript 5.0 ou posterior
- CLI do Azure para autenticação
- Visual Studio Code com a extensão do DocumentDB para gerenciamento de banco de dados (opcional)
Arquitetura de aplicativos para Node.js com funcionalidade autônoma RAG
O exemplo usa uma arquitetura de dois agentes em que cada agente tem uma função específica.

Este exemplo usa a estrutura de agente do LangChain com o SDK do OpenAI. Ele aproveita as abstrações de chamada de função do LangChain para integração de ferramentas e segue um fluxo de trabalho linear entre os agentes e a ferramenta de pesquisa. A execução é sem estado e sem histórico de conversa, o que a torna adequada para os cenários de consulta e resposta de turno único.
Obter o código de exemplo Node.js
Baixe ou clone o repositório Azure DocumentDB Samples para o seu computador local para seguir o tutorial de início rápido.
Navegue até o diretório do projeto:
cd ai/vector-search-agent-typescript
Implantar recursos do Azure com a CLI do Desenvolvedor do Azure
Use a CLI do Desenvolvedor do Azure (azd) para provisionar os recursos necessários do Azure OpenAI e do DocumentDB.
Entre no Azure:
azd auth loginProvisione e implante a infraestrutura:
azd upQuando solicitado, selecione sua assinatura e um local (por exemplo,
swedencentraloueastus2).Após a conclusão da implantação,
azdgera as variáveis de ambiente necessárias. Copie-os em seu.envarquivo (consulte Configurar variáveis de ambiente).
Dica
Execute azd env get-values a qualquer momento para exibir os valores atuais do ambiente.
Configurar variáveis de ambiente
Se você criou seus recursos do Azure manualmente ou deseja usar seus próprios recursos existentes, precisará configurar variáveis de ambiente para que o aplicativo se conecte ao Azure OpenAI e ao Azure DocumentDB. Se você usou azd up, pode ignorar essa etapa, pois as variáveis de ambiente necessárias são definidas automaticamente no azd ambiente e podem ser acessadas com azd env get-values.
Crie um .env arquivo na raiz do projeto para configurar variáveis de ambiente. Você pode criar uma cópia do .env.sample arquivo do repositório.
Edite o arquivo .env e substitua estes valores marcadores temporários:
Esse início rápido usa uma arquitetura de dois agentes (planejador + sintetizador) com três implantações de modelo (dois modelos de chat + inserções). As variáveis de ambiente são configuradas para cada implantação de modelo.
-
AZURE_OPENAI_PLANNER_MODEL: seu nome de modelo gpt-4o-mini -
AZURE_OPENAI_SYNTH_MODEL: nome do seu modelo gpt-4o -
AZURE_OPENAI_EMBEDDING_MODEL: o nome do modelo de inserção de texto 3-small
Você pode escolher entre dois métodos de autenticação: autenticação sem senha usando a Identidade do Azure (recomendado) ou a cadeia de conexão tradicional e a chave de API.
Opção 1: autenticação sem senha
Use a autenticação sem senha com o Azure OpenAI e o Azure DocumentDB. Definir USE_PASSWORDLESS=true, AZURE_OPENAI_ENDPOINTe AZURE_DOCUMENTDB_CLUSTER.
# Enable passwordless authentication
USE_PASSWORDLESS=true
# Azure OpenAI Configuration (passwordless)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (passwordless)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Pré-requisitos para autenticação sem senha:
Verifique se você está conectado ao Azure:
az loginConceda à sua identidade as seguintes funções:
-
Cognitive Services OpenAI Userno recurso Azure OpenAI -
DocumentDB Account ContributoreCosmos DB Account Reader Roleno recurso do Azure DocumentDB
Para obter mais informações sobre como atribuir funções, consulte Atribuir funções do Azure usando o portal do Azure.
-
Como funciona a autenticação sem senha
Quando USE_PASSWORDLESS=true, o aplicativo usa DefaultAzureCredential do SDK de Identidade do Azure para obter um token OAuth. Para conexões do Azure DocumentDB, ele usa um callback de token OIDC que passa diretamente o token de acesso ao driver do MongoDB. Isso significa que nenhuma senha ou cadeia de conexão é armazenada em arquivos de configuração.
O fluxo de autenticação:
-
DefaultAzureCredentialverifica se há credenciais disponíveis (CLI do Azure, identidade gerenciada, variáveis de ambiente) em ordem. - Para o Azure OpenAI, o token é passado automaticamente para os clientes LangChain
AzureChatOpenAIeAzureOpenAIEmbeddings. - Para o Azure DocumentDB, uma função de callback de token recupera um token de acesso e fornece-o ao cliente MongoDB por meio do
MONGODB-OIDCmecanismo de autenticação.
import { AzureOpenAIEmbeddings, AzureChatOpenAI } from "@langchain/openai";
import { MongoClient, OIDCCallbackParams } from 'mongodb';
import { AccessToken, DefaultAzureCredential, TokenCredential, getBearerTokenProvider } from '@azure/identity';
/*
This file contains utility functions to create Azure OpenAI clients for embeddings, planning, and synthesis.
It supports two modes of authentication:
1. API Key based authentication using AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINTenvironment variables.
2. Passwordless authentication using DefaultAzureCredential from Azure Identity library.
*/
// Azure Identity configuration
const OPENAI_SCOPE = 'https://cognitiveservices.azure.com/.default';
const DOCUMENT_DB_SCOPE = 'https://ossrdbms-aad.database.windows.net/.default';
// Azure identity credential (used for passwordless auth)
const CREDENTIAL = new DefaultAzureCredential();
function requireEnvVars(names: string[]) {
const missing = names.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missing.length > 0) {
throw new Error(`Missing required environment variables: ${missing.join(', ')}`);
}
}
// Token callback for MongoDB OIDC authentication
async function azureIdentityTokenCallback(
params: OIDCCallbackParams,
credential: TokenCredential
): Promise<{ accessToken: string; expiresInSeconds: number }> {
const tokenResponse: AccessToken | null = await credential.getToken([DOCUMENT_DB_SCOPE]);
return {
accessToken: tokenResponse?.token || '',
expiresInSeconds: (tokenResponse?.expiresOnTimestamp || 0) - Math.floor(Date.now() / 1000)
};
Opção 2: cadeia de conexão e autenticação de chave de API
Use autenticação baseada em chave, definindo USE_PASSWORDLESS=false (ou omitindo-o) e fornecendo os valores AZURE_OPENAI_API_KEY e AZURE_DOCUMENTDB_CONNECTION_STRING em seu arquivo .env.
# Disable passwordless authentication
USE_PASSWORDLESS=false
# Azure OpenAI Configuration (API key)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_API_KEY=your-azure-openai-api-key
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (connection string)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_CONNECTION_STRING=mongodb+srv://username:password@cluster.mongocluster.cosmos.azure.com/
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
Estrutura do projeto
O projeto segue um layout de projeto Node.js/TypeScript padrão. Sua estrutura de diretório deve se parecer com a seguinte estrutura:
vector-search-agent-typescript/
├── src/
│ ├── agent.ts # Main agent application
│ ├── upload-documents.ts # Data upload utility
│ ├── cleanup.ts # Database cleanup utility
│ ├── vector-store.ts # Vector store and tool implementation
│ ├── utils/
│ │ ├── clients.ts # Azure OpenAI and DocumentDB client setup
│ │ ├── prompts.ts # System prompts and tool definitions
│ │ ├── types.ts # TypeScript type definitions
│ │ └── mongo.ts # MongoDB utility functions
│ └── scripts/ # Additional utility scripts
├── .env # Environment variable configuration
├── package.json # npm dependencies and scripts
└── tsconfig.json # TypeScript configuration
Explorar o código Node.js para a aplicação agente RAG
Esta seção percorre os principais componentes do fluxo de trabalho do agente de IA. Ele destaca como os agentes processam solicitações, como as ferramentas conectam a IA ao banco de dados e como os prompts orientam o comportamento da IA.
Aplicativo RAG Node.js por meio de agentes
O src/agent.ts arquivo orquestra um sistema de recomendação de hotel alimentado por IA.
O aplicativo usa dois serviços do Azure:
- Azure OpenAI que usa modelos de IA que entendem consultas e geram recomendações
- Azure DocumentDB que armazena dados de hotéis e executa pesquisas de similaridade de vetor
Node.js Agente e componentes de ferramentas
Os três componentes trabalham juntos para processar a solicitação de pesquisa do hotel:
- Agente do Planner – interpreta a solicitação e decide como pesquisar
- Ferramenta de pesquisa de vetor – localiza hotéis semelhantes ao que o agente do planejador descreve
- Agente de sintetizador – grava uma recomendação útil com base nos resultados da pesquisa
Fluxo de Trabalho do Aplicativo Agentic RAG
O aplicativo processa uma solicitação de pesquisa de hotel em duas etapas:
- Planejamento: O fluxo de trabalho chama o agente do planejador, que analisa a consulta do usuário (como "hotéis próximos a trilhas para corrida") e pesquisa o banco de dados para encontrar hotéis correspondentes.
- Sintetizar: O fluxo de trabalho chama o agente sintetizador, que analisa os resultados da pesquisa e grava uma recomendação personalizada explicando quais hotéis correspondem melhor à solicitação.
// Authentication
const clients = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1' ? createClientsPasswordless() : createClients();
const { embeddingClient, plannerClient, synthClient, dbConfig } = clients;
console.log(`DEBUG mode is ${process.env.DEBUG === 'true' ? 'ON' : 'OFF'}`);
console.log(`DEBUG_CALLBACKS length: ${DEBUG_CALLBACKS.length}`);
// Get vector store (get docs, create embeddings, insert docs)
const store = await getExistingStore(
embeddingClient,
dbConfig);
const query = process.env.QUERY || "quintessential lodging near running trails, eateries, retail";
const nearestNeighbors = parseInt(process.env.NEAREST_NEIGHBORS || '5', 10);
//Run planner agent
const hotelContext = await runPlannerAgent(plannerClient, embeddingClient, query, store, nearestNeighbors);
if (process.env.DEBUG === 'true') console.log(hotelContext);
//Run synth agent
const finalAnswer = await runSynthesizerAgent(synthClient, query, hotelContext);
// Get final recommendation (data + AI)
console.log('\n--- FINAL ANSWER ---');
console.log(finalAnswer);
Node.js Agents para planejamento e síntese
O arquivo de origem src/agent.ts implementa os agentes planejadores e sintetizadores que trabalham juntos a fim de processar as solicitações de pesquisa de hotéis.
Agente do Planner
O agente do planner é o tomador de decisão que determina como procurar hotéis.
O agente do planner recebe a consulta de linguagem natural do usuário e a envia para um modelo de IA usando a estrutura de agente do LangChain, juntamente com as ferramentas disponíveis que ele pode usar. A IA decide chamar a ferramenta de pesquisa de vetor e fornece parâmetros de pesquisa. LangChain manipula a execução da ferramenta automaticamente e retorna os hotéis correspondentes. Em vez de codificar logicamente a pesquisa, a IA interpreta o que o usuário deseja e escolhe de que forma pesquisar, tornando o sistema flexível a diferentes tipos de consultas.
async function runPlannerAgent(
plannerClient: any,
embeddingClient: any,
userQuery: string,
store: AzureDocumentDBVectorStore,
nearestNeighbors = 5
): Promise<string> {
console.log('\n--- PLANNER ---');
const userMessage = `Use the "${TOOL_NAME}" tool with nearestNeighbors=${nearestNeighbors} and query="${userQuery}". Do not answer directly; call the tool.`;
const contextSchema = z.object({
store: z.any(),
embeddingClient: z.any()
});
const agent = createAgent({
model: plannerClient,
systemPrompt: PLANNER_SYSTEM_PROMPT,
tools: [getHotelsToMatchSearchQuery],
contextSchema,
});
const agentResult = await agent.invoke(
{ messages: [{ role: 'user', content: userMessage }] },
// @ts-ignore
{ context: { store, embeddingClient }, callbacks: DEBUG_CALLBACKS }
);
const plannerMessages = agentResult.messages || [];
const searchResultsAsText = extractPlannerToolOutput(plannerMessages);
return searchResultsAsText;
}
Sintetizador agente
O agente sintetizador é o escritor que cria recomendações úteis.
O agente sintetizador recebe a consulta original do usuário junto com os resultados da pesquisa de hotéis. Ele envia tudo para um modelo de IA com instruções para escrever recomendações. Ele retorna uma resposta de linguagem natural que compara hotéis e explica as melhores opções. Essa abordagem é importante porque os resultados brutos da pesquisa não são amigáveis. O sintetizador transforma registros de banco de dados em uma recomendação de conversa que explica por que determinados hotéis correspondem às necessidades do usuário.
async function runSynthesizerAgent(synthClient: any, userQuery: string, hotelContext: string): Promise<string> {
console.log('\n--- SYNTHESIZER ---');
let conciseContext = hotelContext;
console.log(`Context size is ${conciseContext.length} characters`);
const agent = createAgent({
model: synthClient,
systemPrompt: SYNTHESIZER_SYSTEM_PROMPT,
});
const agentResult = await agent.invoke({
messages: [{
role: 'user',
content: createSynthesizerUserPrompt(userQuery, conciseContext)
}]
});
const synthMessages = agentResult.messages;
const finalAnswer = synthMessages[synthMessages.length - 1].content;
console.log(`Output: ${finalAnswer.length} characters of final recommendation`);
return finalAnswer as string;
}
Ferramentas do agente para busca de repositório em vetores
O src/vector-store.ts arquivo de origem define a ferramenta de pesquisa de vetor que o agente planejador usa.
O arquivo de ferramentas define uma ferramenta de pesquisa que o agente de IA pode usar para localizar hotéis. Essa ferramenta é como o agente se conecta ao banco de dados. A IA não pesquisa o banco de dados diretamente. Solicita o uso da ferramenta de pesquisa, e a ferramenta executa a pesquisa propriamente dita.
Node.js Função como definição de ferramenta
A função langChain tool cria uma ferramenta a partir de uma função TypeScript regular. A definição da ferramenta inclui o nome, a descrição e o esquema (usando o Zod para validação). Essa definição permite que a IA saiba que a ferramenta existe e como usá-la corretamente.
export const getHotelsToMatchSearchQuery = tool(
async ({ query, nearestNeighbors }, config): Promise<string> => {
try {
const store = config.context.store as AzureDocumentDBVectorStore;
const embeddingClient = config.context.embeddingClient as AzureOpenAIEmbeddings;
// Create query embedding and perform search
const queryVector = await embeddingClient.embedQuery(query);
const results = await store.similaritySearchVectorWithScore(queryVector, nearestNeighbors);
console.log(`Found ${results.length} documents from vector store`);
// Format results for synthesizer
const formatted = results.map(([doc, score]) => {
const md = doc.metadata as Partial<HotelForVectorStore>;
console.log(`Hotel: ${md.HotelName ?? 'N/A'}, Score: ${score}`);
return formatHotelForSynthesizer(md, score);
}).join('\n\n');
return formatted;
} catch (error) {
console.error('Error in getHotelsToMatchSearchQuery tool:', error);
return 'Error occurred while searching for hotels.';
}
},
{
name: TOOL_NAME,
description: TOOL_DESCRIPTION,
schema: z.object({
query: z.string(),
nearestNeighbors: z.number().optional().default(5),
}),
}
);
Execução da ferramenta Node.js com a pesquisa de vetor do Azure DocumentDB
Quando a IA chama a ferramenta, o corpo da função é executado. Ele gera uma inserção convertendo a consulta de texto em um vetor numérico usando o modelo de inserção do Azure OpenAI. Em seguida, ele pesquisa o banco de dados enviando o vetor para o Azure DocumentDB, que localiza hotéis com vetores semelhantes que significam descrições semelhantes. Por fim, ele formata os resultados convertendo os registros de banco de dados em texto legível que o agente sintetizador pode entender.
A implementação aproveita o LangChain's AzureDocumentDBVectorStore para uma integração perfeita com o Azure DocumentDB.
Por que usar esse padrão?
Separar a ferramenta do agente fornece flexibilidade. A IA decide quando pesquisar e o que pesquisar, enquanto a ferramenta manipula como pesquisar. Você pode adicionar mais ferramentas sem alterar a lógica do agente.
Solicitações do agente para orientar o comportamento da IA
O arquivo de origem src/utils/prompts.ts contém prompts do sistema e definições de ferramenta para os agentes.
O arquivo de prompts define as instruções e o contexto fornecidos aos modelos de IA para os agentes planejador e sintetizador. Esses prompts orientam o comportamento da IA e garantem que ela entenda sua função no fluxo de trabalho.
A qualidade das respostas de IA depende muito de instruções claras. Esses prompts definem limites, definem o formato de saída e concentram a IA na meta do usuário de tomar uma decisão. Você pode personalizar esses prompts para alterar como os agentes se comportam sem modificar nenhum código.
export const PLANNER_SYSTEM_PROMPT = `You are a hotel search planner. Transform the user's request into a clear, detailed search query for a vector database.
CRITICAL REQUIREMENT: You MUST ALWAYS call the "${TOOL_NAME}" tool. This is MANDATORY for every request.
Use a tool call with:
- query (string)
- nearestNeighbors (number 1-20)
QUERY REFINEMENT RULES:
- If vague (e.g., "nice hotel"), add specific attributes: "hotel with high ratings and good amenities"
- If minimal (e.g., "cheap"), expand: "budget hotel with good value"
- Preserve specific details from user (location, amenities, business/leisure)
- Keep natural language - this is for semantic search
- Don't just echo the input - improve it for better search results
- nearestNeighbors: Use 3-5 for specific requests, 10-15 for broader requests, max 20
EXAMPLES:
User: "cheap hotel" → {"tool": "${TOOL_NAME}", "args": {"query": "budget-friendly hotel with good value and affordable rates", "nearestNeighbors": 10}}
User: "hotel near downtown with parking" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel near downtown with good parking and wifi", "nearestNeighbors": 5}}
User: "nice place to stay" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel with high ratings, good reviews, and quality amenities", "nearestNeighbors": 10}}
Do not answer the user directly. Always call the tool.`;
// ============================================================================
// Synthesizer Prompts
// ============================================================================
export const SYNTHESIZER_SYSTEM_PROMPT = `You are an expert hotel recommendation assistant using vector search results.
Only use the TOP 3 results provided. Do not request additional searches or call other tools.
GOAL: Provide a concise comparative recommendation to help the user choose between the top 3 options.
REQUIREMENTS:
- Compare only the top 3 results across the most important attributes: rating, score, location, price-level (if available), and key tags (parking, wifi, pool).
- Identify the main tradeoffs in one short sentence per tradeoff.
- Give a single clear recommendation with one short justification sentence.
- Provide up to two alternative picks (one sentence each) explaining when they are preferable.
FORMAT CONSTRAINTS:
- Plain text only (no markdown).
- Keep the entire response under 220 words.
- Use simple bullets (•) or numbered lists and short sentences (preferably <25 words per sentence).
- Preserve hotel names exactly as provided in the tool summary.
Do not add extra commentary, marketing language, or follow-up questions. If information is missing and necessary to choose, state it in one sentence and still provide the best recommendation based on available data.`;
Preparar e carregar dados no Azure DocumentDB com Node.js
O exemplo usa dados de hotel de um arquivo JSON. O repositório inclui duas versões:
-
Hotels.json- Dados de hotel sem inserções de vetor (usados por este exemplo) -
Hotels_Vector.json- Dados de hotel com inserções pré-computadas (usadas por outros exemplos)
Como funciona o upload
O upload-documents.ts script executa três etapas:
-
Carregar dados — Lê os registros de hotel do arquivo
Hotels.json. -
Gerar inserções — Para cada hotel, o script envia o
Descriptioncampo para o modelo do Azure OpenAItext-embedding-3-smallpara gerar uma inserção de vetor de 1536 dimensões. Isso converte a descrição do texto em uma representação numérica que captura seu significado semântico. - Inserir e indexar — O script insere documentos (com suas inserções) na coleção do Azure DocumentDB e cria um índice de vetor usando o algoritmo configurado (FIV, HNSW ou DiskANN).
import { createClientsPasswordless, createClients } from './utils/clients.js';
import { getStore } from './vector-store.js';
/**
* Upload documents to Azure DocumentDB MongoDB Vector Store
*/
async function uploadDocuments() {
try {
console.log('Starting document upload...\n');
// Get clients based on authentication mode
const usePasswordless = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1';
console.log(`Authentication mode: ${usePasswordless ? 'Passwordless (Azure AD)' : 'API Key'}`);
console.log('\nEnvironment variables check:');
console.log(` DATA_FILE_WITHOUT_VECTORS: ${process.env.DATA_FILE_WITHOUT_VECTORS}`);
console.log(` AZURE_DOCUMENTDB_DATABASENAME: ${process.env.AZURE_DOCUMENTDB_DATABASENAME}`);
console.log(` AZURE_DOCUMENTDB_COLLECTION: ${process.env.AZURE_DOCUMENTDB_COLLECTION}`);
console.log(` AZURE_DOCUMENTDB_CLUSTER: ${process.env.AZURE_DOCUMENTDB_CLUSTER}`);
console.log(` AZURE_OPENAI_EMBEDDING_MODEL: ${process.env.AZURE_OPENAI_EMBEDDING_MODEL}`);
const requiredEnvVars = [
'DATA_FILE_WITHOUT_VECTORS',
'AZURE_DOCUMENTDB_DATABASENAME',
'AZURE_DOCUMENTDB_COLLECTION',
'AZURE_DOCUMENTDB_CLUSTER',
'AZURE_OPENAI_EMBEDDING_MODEL',
];
const missingEnvVars = requiredEnvVars.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missingEnvVars.length > 0) {
throw new Error(`Missing required environment variables: ${missingEnvVars.join(', ')}`);
}
const clients = usePasswordless ? createClientsPasswordless() : createClients();
const { embeddingClient, dbConfig } = clients;
console.log('\ndbConfig properties:');
console.log(` instance: ${dbConfig.instance}`);
console.log(` databaseName: ${dbConfig.databaseName}`);
console.log(` collectionName: ${dbConfig.collectionName}`);
// Check for data file path
const dataFilePath = process.env.DATA_FILE_WITHOUT_VECTORS!;
console.log(`\nReading data from: ${dataFilePath}`);
console.log(`Database: ${dbConfig.databaseName}`);
console.log(`Collection: ${dbConfig.collectionName}`);
console.log(`Vector algorithm: ${process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf'}\n`);
// Upload documents using existing getStore function
const startTime = Date.now();
const store = await getStore(dataFilePath, embeddingClient, dbConfig);
const duration = ((Date.now() - startTime) / 1000).toFixed(2);
console.log(`\n✓ Upload completed in ${duration} seconds`);
// Close connection
await store.close();
console.log('✓ Connection closed');
// Force exit to ensure process terminates (Azure credential timers may still be active)
process.exit(0);
} catch (error: any) {
console.error('\n✗ Upload failed:', error?.message || error);
console.error('\nFull error:', error);
process.exit(1);
}
}
// Run the upload
uploadDocuments();
Criação de índice vetor
O índice de vetor é o que permite a pesquisa de similaridade rápida. Quando o índice é criado, o Azure DocumentDB organiza os vetores de inserção para que consultas como "localizar hotéis semelhantes a esta descrição" possam ser respondidas com eficiência sem verificar todos os documentos.
O tipo de índice escolhido afeta o desempenho:
| Algoritmo | Nível do cluster | Mais adequado para |
|---|---|---|
| FIV | M10+ | Conjuntos de dados pequenos a médios, menor custo |
| HNSW | M30+ | Recolhimento alto, consultas rápidas |
| DiskANN | M40+ | Conjuntos de dados em grande escala, bilhões de vetores |
import {
AzureDocumentDBVectorStore,
AzureDocumentDBSimilarityType,
AzureDocumentDBConfig
} from "@langchain/azure-cosmosdb";
import type { AzureOpenAIEmbeddings } from "@langchain/openai";
import { readFileSync } from 'fs';
import { Document } from '@langchain/core/documents';
import { HotelsData, Hotel } from './utils/types.js';
import { TOOL_NAME, TOOL_DESCRIPTION } from './utils/prompts.js';
import { z } from 'zod';
import { tool } from "langchain";
import { MongoClient } from 'mongodb';
import { BaseMessage } from "@langchain/core/messages";
type HotelForVectorStore = Omit<Hotel, 'Description_fr' | 'Location' | 'Rooms'>;
// Helper function for similarity type
function getSimilarityType(similarity: string) {
switch (similarity.toUpperCase()) {
case 'COS': return AzureDocumentDBSimilarityType.COS;
case 'L2': return AzureDocumentDBSimilarityType.L2;
case 'IP': return AzureDocumentDBSimilarityType.IP;
default: return AzureDocumentDBSimilarityType.COS;
}
}
// Consolidated vector index configuration
function getVectorIndexOptions() {
const algorithm = process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf';
const dimensions = parseInt(process.env.EMBEDDING_DIMENSIONS || '1536');
const similarity = getSimilarityType(process.env.VECTOR_SIMILARITY || 'COS');
const baseOptions = { dimensions, similarity };
switch (algorithm) {
case 'vector-hnsw':
return {
kind: 'vector-hnsw' as const,
m: parseInt(process.env.HNSW_M || '16'),
efConstruction: parseInt(process.env.HNSW_EF_CONSTRUCTION || '64'),
...baseOptions
};
case 'vector-diskann':
return {
kind: 'vector-diskann' as const,
...baseOptions
};
case 'vector-ivf':
default:
Execute o aplicativo RAG por meio de agentes com Node.js
Instale as dependências:
npm installAntes de executar o agente, carregue os dados sobre os hotéis com as inserções. O
upload-documents.tscomando carrega hotéis do arquivo JSON, gera inserções para cada hotel usandotext-embedding-3-small, insere documentos no Azure DocumentDB e cria um índice de vetor.npm run uploadExecute o agente de recomendação do hotel usando o
agent.tscomando. O agente chama o agente planejador, a busca em vetores e o agente sintetizador. A saída inclui pontuações de similaridade e a análise comparativa do agente sintetizador, juntamente com recomendações.npm startDEBUG mode is OFF DEBUG_CALLBACKS length: 0 Connected to existing vector store: Hotels.hotel_data --- PLANNER --- Found 5 documents from vector store Hotel: Nordick's Valley Motel, Score: 0.49866509437561035 Hotel: White Mountain Lodge & Suites, Score: 0.48731985688209534 Hotel: Trails End Motel, Score: 0.47985398769378662 Hotel: Country Comfort Inn, Score: 0.47431993484497070 Hotel: Lakefront Captain Inn, Score: 0.45787304639816284 --- SYNTHESIZER --- Context size is 3233 characters Output: 812 characters of final recommendation --- FINAL ANSWER --- 1. COMPARISON SUMMARY: • Nordick's Valley Motel has the highest rating (4.5) and offers free parking, air conditioning, and continental breakfast. It is located in Washington D.C., near historic attractions and trails. • White Mountain Lodge & Suites is a resort with unique amenities like a pool, restaurant, and meditation gardens, but has the lowest rating (2.4). It is located in Denver, surrounded by forest trails. • Trails End Motel is budget-friendly with a moderate rating (3.2), free parking, free wifi, and a restaurant. It is close to downtown Scottsdale and eateries. Key tradeoffs: - Nordick's Valley Motel excels in rating and proximity to historic attractions but lacks a pool or free wifi. - White Mountain Lodge & Suites offers resort-style amenities and forest trails but has the lowest rating. - Trails End Motel balances affordability and essential amenities but has fewer unique features compared to the others. 2. BEST OVERALL: Nordick's Valley Motel is the best choice for its high rating, proximity to trails and attractions, and free parking. 3. ALTERNATIVE PICKS: • Choose White Mountain Lodge & Suites if you prioritize resort amenities and forest trails over rating. • Choose Trails End Motel if affordability and proximity to downtown Scottsdale are your main concerns.
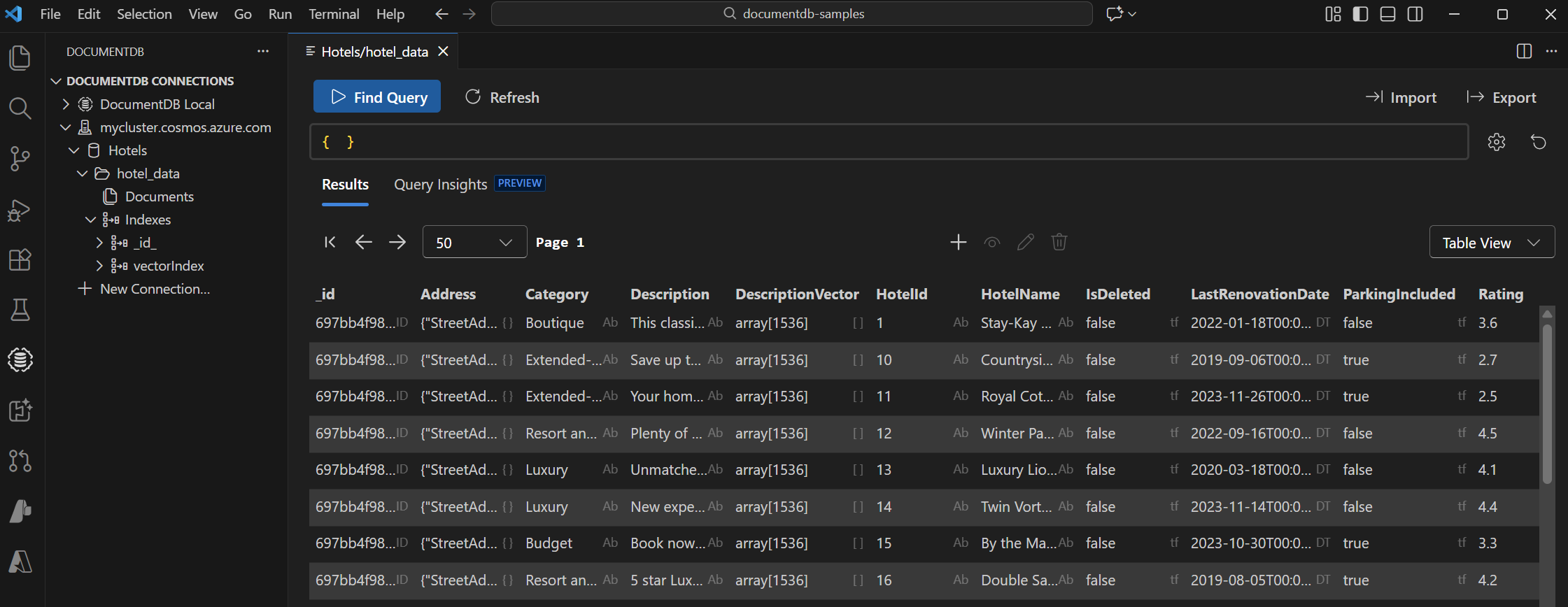
Exibir e gerenciar dados no Visual Studio Code
Selecione a extensão do DocumentDB no Visual Studio Code para se conectar à sua conta do Azure DocumentDB.
Exiba os dados e índices no banco de dados Hotéis.
Limpar os recursos
Se você usou azd up para provisionar recursos, poderá remover todos os recursos do Azure com:
azd down
Se você criou manualmente os recursos e deseja remover todos os recursos, exclua o grupo de recursos para evitar custos extras.
Se você quiser reutilizar os recursos, use o comando de limpeza para excluir o banco de dados de teste quando terminar. Execute o comando a seguir:
npm run cleanup