Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
O Azure HDInsight no AKS se aposentou em 31 de janeiro de 2025. Saiba mais com este comunicado.
Você precisa migrar suas cargas de trabalho para microsoft fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esse recurso está atualmente em versão prévia. Os termos de uso complementares para o Microsoft Azure Previews incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, consulte Informações sobre a visualização do Azure HDInsight no AKS. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para mais atualizações sobre a Comunidade do Azure HDInsight .
Depois que o cluster é criado, o usuário pode usar variadas interfaces para enviar e gerenciar trabalhos por meio de diferentes métodos.
- usando o Jupyter
- usando Zeppelin
- usando o ssh (comando spark-submit)
Usando o Jupyter
Pré-requisitos
Um cluster do Apache Spark™ em HDInsight em AKS. Para obter mais informações, consulte Criar um cluster do Apache Spark.
O Jupyter Notebook é um ambiente de notebook interativo que dá suporte a várias linguagens de programação.
Criar um Jupyter Notebook
Navegue até a página do cluster do Apache Spark™ e abra a guia Visão Geral. Clique em Jupyter, ele solicita que você se autentique e abra a página da Web do Jupyter.

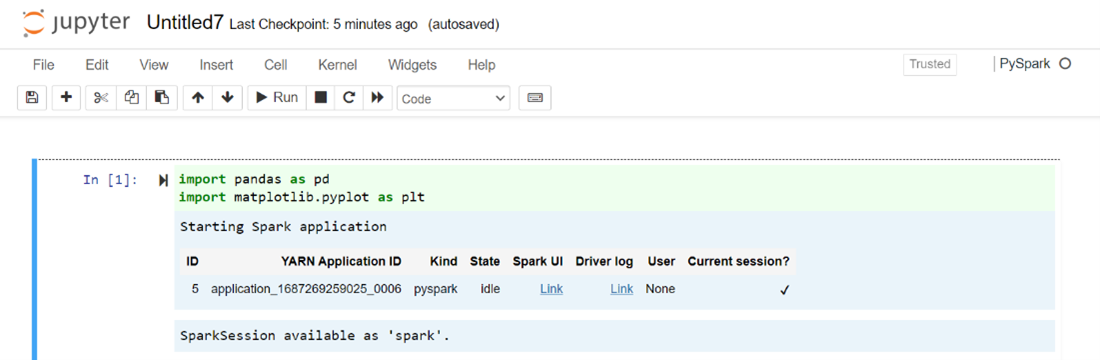
Na página da Web do Jupyter, selecione Novo > PySpark para criar um bloco de anotações.

Um novo notebook criado e aberto com o nome
Untitled(Untitled.ipynb).Nota
Usando o PySpark ou o kernel do Python 3 para criar um notebook, a sessão do Spark é criada automaticamente para você quando você executa a primeira célula de código. Você não precisa criar explicitamente a sessão.
Cole o código a seguir em uma célula vazia do Jupyter Notebook e pressione SHIFT + ENTER para executar o código. Veja aqui para obter mais controles no Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Plotar um grafo com Salário e idade como eixos X e Y
No mesmo bloco de anotações, cole o código a seguir em uma célula vazia do Jupyter Notebook e pressione SHIFT + ENTER para executar o código.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()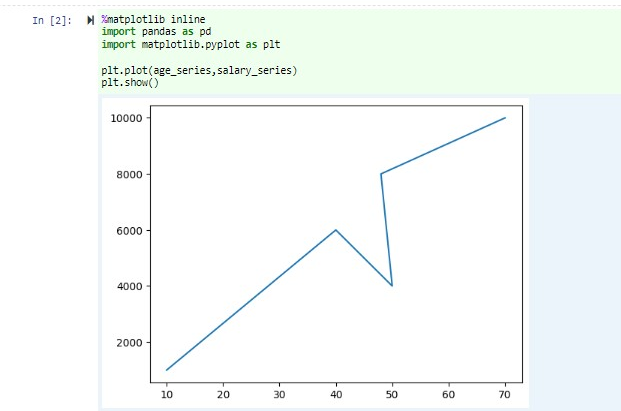




Salvar o Bloco de Anotações
Na barra de menus do notebook, navegue até Arquivo > Salvar e Ponto de Verificação.
Desligue o notebook para liberar os recursos do cluster: na barra de menus do notebook, navegue até Arquivo > Fechar e Parar. Você também pode executar qualquer um dos blocos de anotações na pasta de exemplos.


Usando cadernos do Apache Zeppelin
Os clusters do Apache Spark do HDInsight no AKS incluem notebooks Apache Zeppelin. Use os notebooks para executar trabalhos do Apache Spark. Neste artigo, você aprenderá a usar o notebook Zeppelin em um cluster AKS com HDInsight.
Pré-requisitos
Um cluster do Apache Spark no HDInsight em AKS. Para obter instruções, consulte Criar um cluster do Apache Spark.
Iniciar um bloco de anotações do Apache Zeppelin
Navegue até a página Visão geral do cluster do Apache Spark e selecione o notebook Zeppelin nos painéis do Cluster. Isso solicita a autenticação e a abertura da página do Zeppelin.
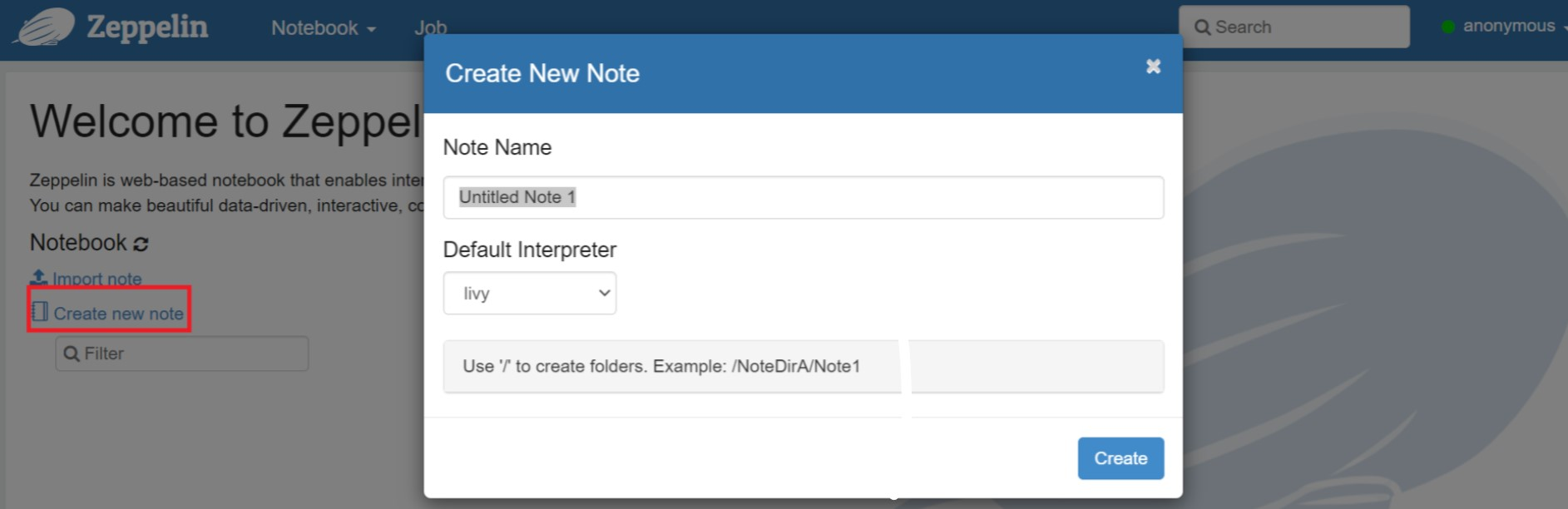
Crie um novo bloco de anotações. No painel de cabeçalho, navegue até Notebook > Criar nova anotação. Verifique se o cabeçalho do bloco de anotações mostra um status de conexão. Ele indica um ponto verde no canto superior direito.
Execute o seguinte código no Zeppelin Notebook:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Selecione o botão Reproduzir para executar o snippet no parágrafo. O status no canto direito do parágrafo deve progredir de PRONTO, PENDENTE, EXECUTANDO para FINALIZADO. A saída aparece na parte inferior do mesmo parágrafo. A captura de tela se parece com a seguinte imagem:
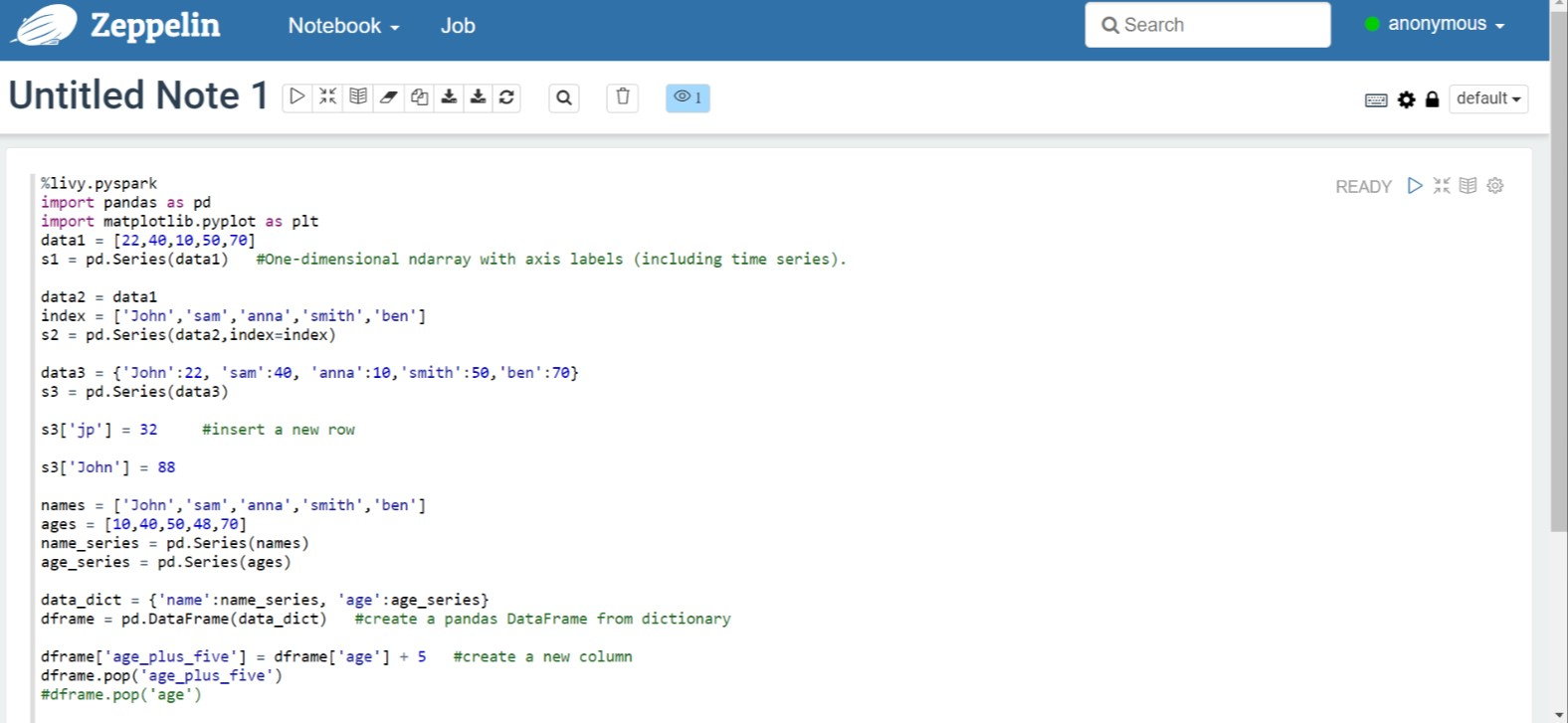
Saída:





Usando submissão de trabalhos do Spark
Criar um arquivo usando o seguinte comando '#vim samplefile.py'
Este comando abre o arquivo vim
Cole o código a seguir no arquivo vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Salve o arquivo com o método a seguir.
- Pressione o botão Escape
- Insira o comando
:wq
Execute o comando a seguir para executar o trabalho.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Monitorar consultas em um cluster Apache Spark no HDInsight em AKS
Interface de histórico do Spark
Clique na interface do Servidor de Histórico do Spark na aba visão geral.

Selecione a execução recente na UI usando o mesmo ID do app.
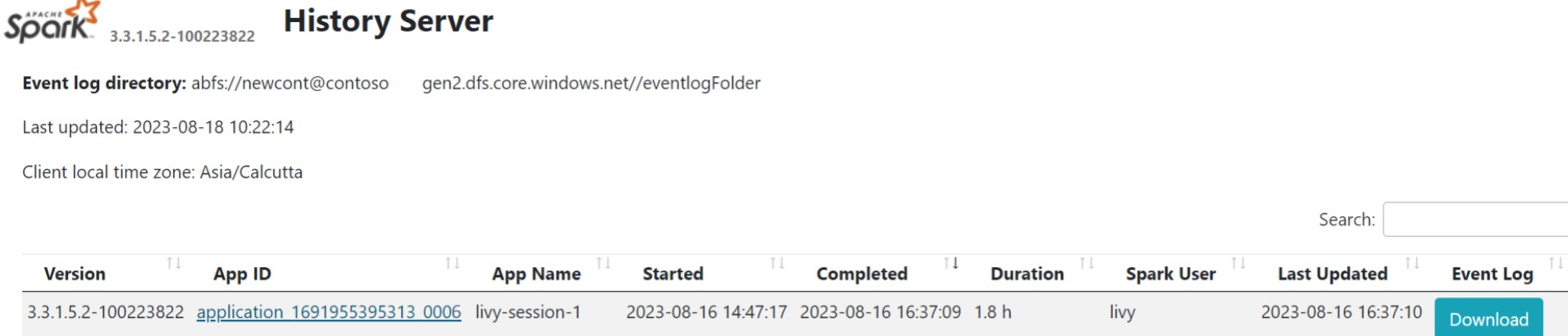
Exiba os ciclos do Grafo Acíclico Direcionado e os estágios do trabalho na interface do servidor de histórico do Spark.
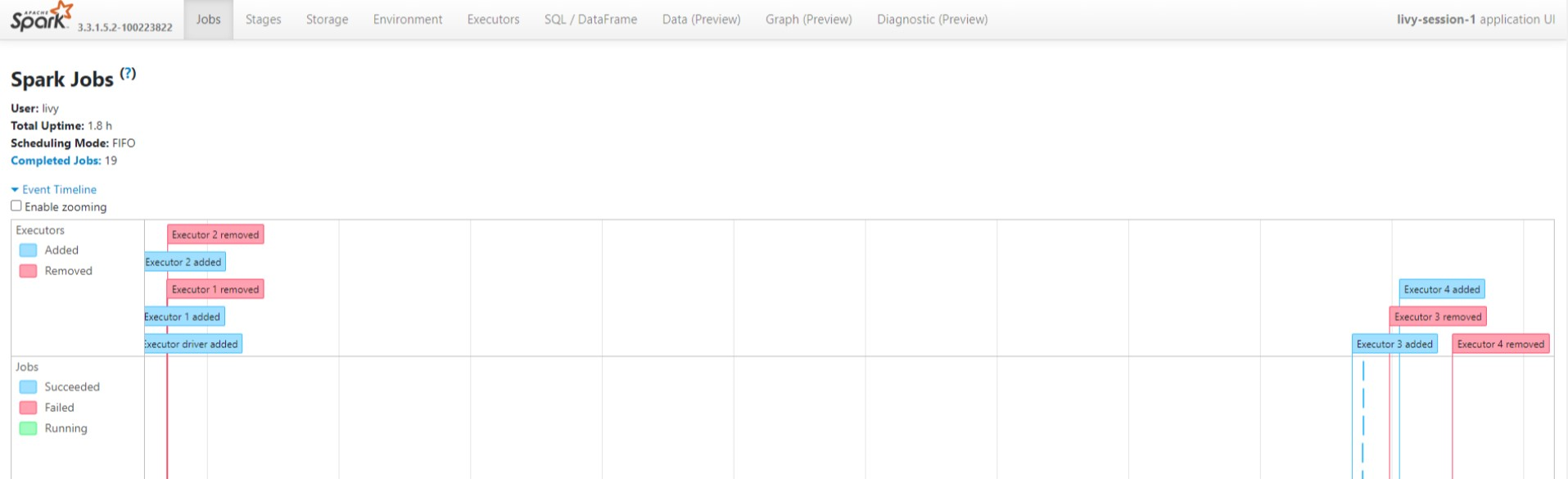



Interface do Usuário da Sessão Livy
Para abrir a interface do usuário da sessão do Livy, digite o seguinte comando no navegador
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui
Visualize os registros do driver clicando na opção do driver em registros.

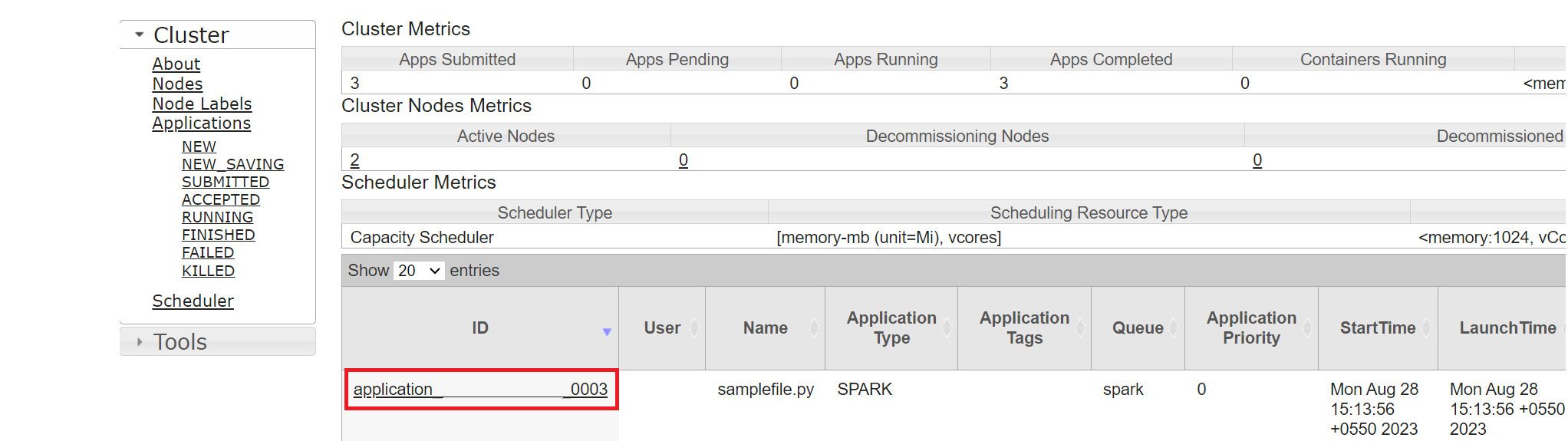
Yarn UI
Na aba Visão Geral, clique em Yarn e abra a interface do usuário do Yarn.
Você pode acompanhar o trabalho executado recentemente pela mesma ID do aplicativo.
Clique na ID do Aplicativo no Yarn para exibir logs detalhados do trabalho.


Referência
- Apache, Apache Spark, Spark e nomes de projeto de software livre associados são marcas do ASF (Apache Software Foundation).