Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste artigo, você aprenderá a criar clusters do Apache Hadoop no HDInsight usando o portal do Azure e, em seguida, executar trabalhos do Apache Hive no HDInsight. A maioria dos trabalhos de Hadoop consiste em trabalhos em lotes. Criar um cluster, executar alguns trabalhos e excluir o cluster. Neste artigo, você deve executar as três tarefas. Para obter explicações detalhadas sobre as configurações disponíveis, confira Configurar clusters no HDInsight. Para obter mais informações sobre o uso do portal para criar clusters, confira Criar clusters no portal.
Neste início rápido, você usa o Portal do Azure para criar um cluster Hadoop do HDInsight. Também é possível criar um cluster usando o modelo do Azure Resource Manager.
Atualmente, o HDInsight é fornecido com sete tipos diferentes de cluster. Cada tipo de cluster dá suporte a um conjunto diferente de componentes. Todos os tipos de cluster dão suporte ao Hive. Para obter uma lista de componentes com suporte no HDInsight, confira What's new in the Apache Hadoop cluster versions provided by HDInsight? (Novidades nas versões de cluster Apache Hadoop fornecidas pelo HDInsight?)
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Criar um cluster do Apache Hadoop
Nesta seção, você criará um cluster Hadoop no HDInsight usando o portal do Azure.
Entre no portal do Azure.
No menu superior, selecione + Criar um recurso.
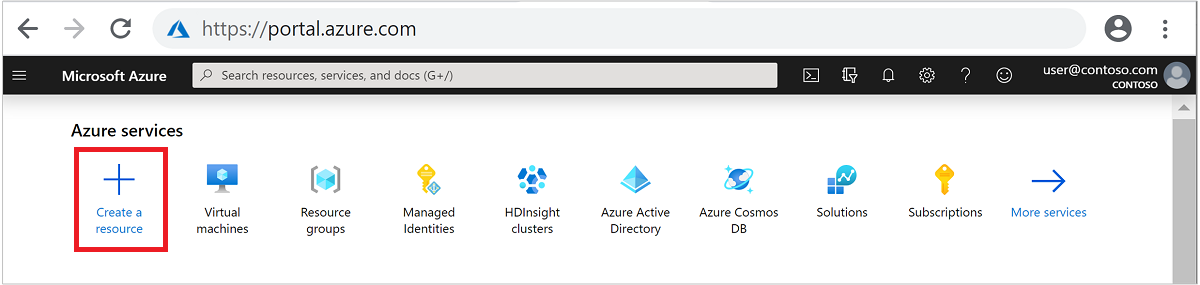
Selecione Análise>Azure HDInsight para acessar a página Criar cluster HDInsight.
Na guia Informações Básicas, forneça as seguintes informações:
Propriedade Descrição Subscription Na lista suspensa, selecione a assinatura do Azure usada para o cluster. Grupo de recursos Na lista suspensa, selecione o grupo de recursos existente ou selecione Criar. Nome do cluster Insira um nome global exclusivo. O nome pode ter até 59 caracteres incluindo letras, números e hifens. O primeiro e último caracteres do nome não podem ser hifens. Região Na lista suspensa, selecione uma região em que o cluster foi criado. Escolha um local mais próximo a você para obter melhor desempenho. Tipo de cluster Selecione Selecione o tipo de cluster. Em seguida, selecione Hadoop como o tipo de cluster. Versão Na lista suspensa, selecione uma versão. Use a versão padrão se não souber o que escolher. Nome de usuário e senha de entrada do cluster O nome de entrada padrão é admin. A senha precisa ter no mínimo dez caracteres e precisa conter pelo menos um dígito, uma letra maiúscula, uma minúscula e um caractere não alfanumérico (exceto pelos caracteres ' ` "). Não forneça senhas comuns, como "Pass@word1".Nome de usuário do Secure Shell (SSH) O nome de usuário padrão é sshuser. Você pode fornecer outro nome para o nome de usuário de SSH.Usar a senha de entrada do cluster para SSH Marque essa caixa de seleção para usar a mesma senha para o usuário SSH que aquela fornecida para o usuário de entrada do cluster. 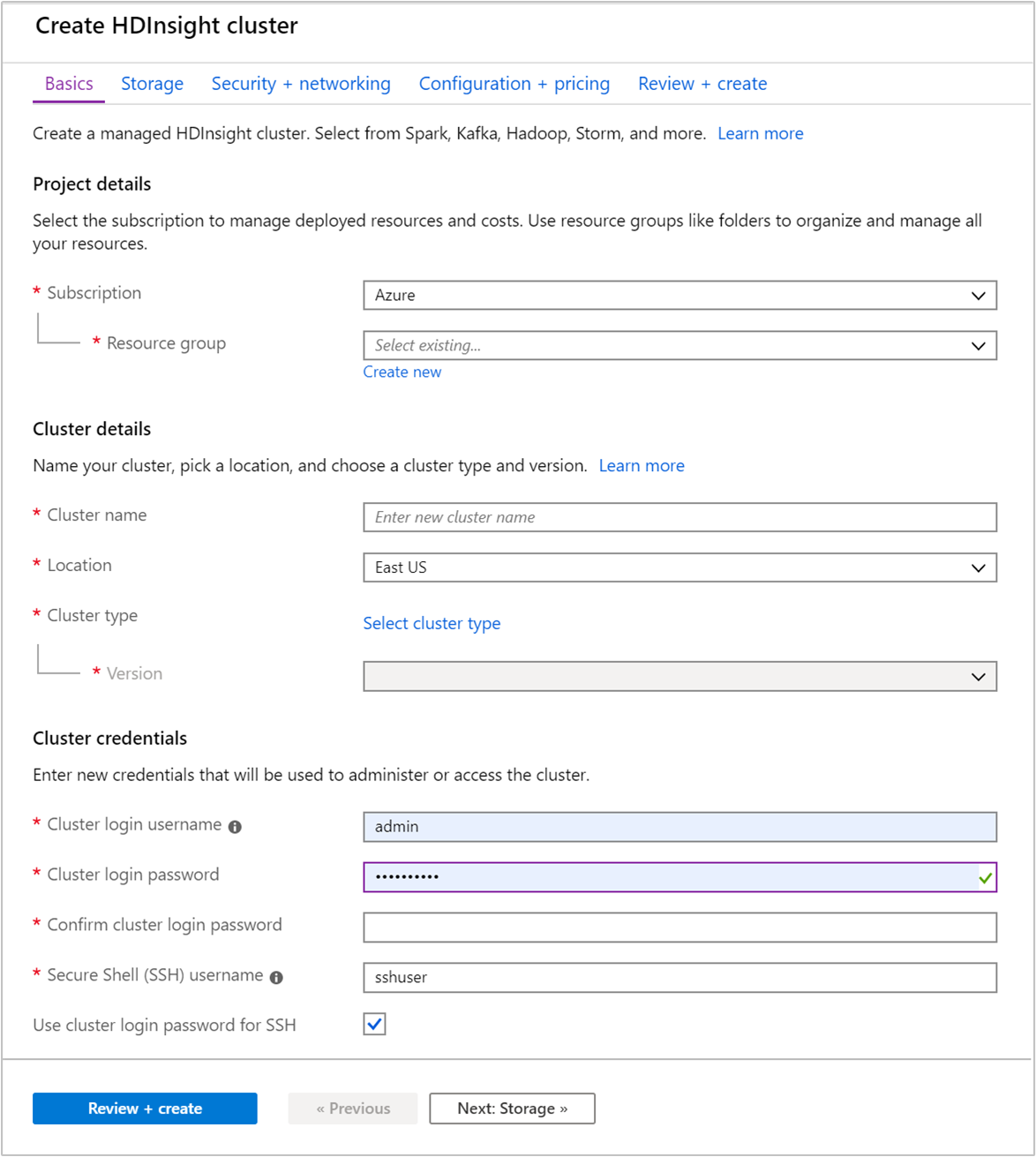
Selecione Próximo: Armazenamento >> para passar para as configurações de armazenamento.
Na guia Armazenamento, forneça os seguintes valores:
Propriedade Descrição Tipo de armazenamento primário Use o valor padrão Armazenamento do Azure. Método de seleção Use o valor padrão Selecione na lista. Conta de armazenamento primária Use a lista suspensa para selecionar uma conta de armazenamento existente ou selecione Criar. Se você criar uma conta, o nome deverá ter entre 3 e 24 caracteres e poderá incluir apenas números e letras minúsculas Contêiner Use o valor preenchido automaticamente. 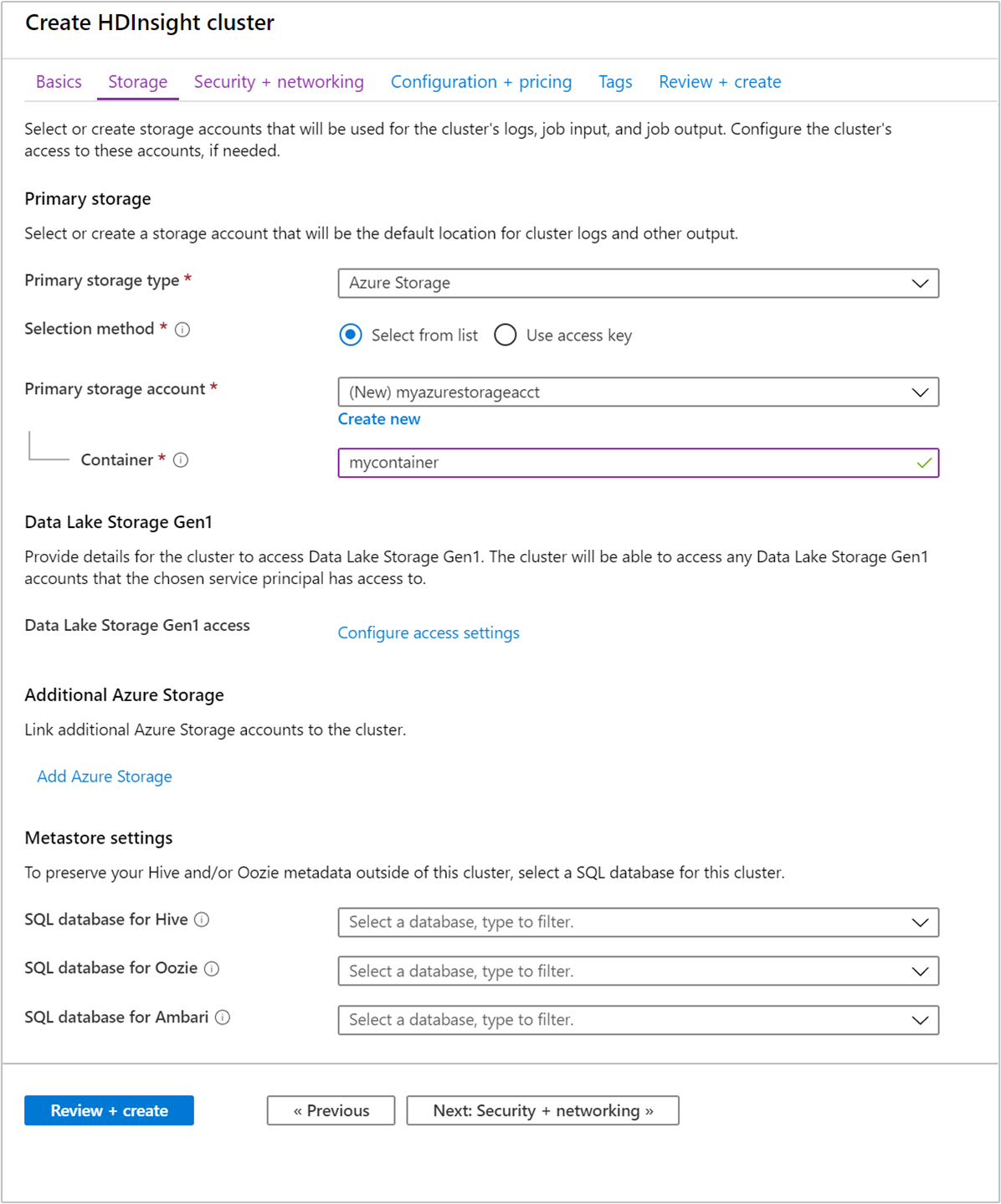
Cada cluster tem uma conta do Armazenamento do Microsoft Azure ou uma dependência de
Azure Data Lake Storage Gen2. Ela é conhecida como a conta de armazenamento padrão. O cluster HDInsight e sua conta de armazenamento padrão devem estar colocados na mesma região do Azure. A exclusão dos clusters não exclui a conta de armazenamento.Selecione a guia Examinar + criar.
Na guia Examinar + criar, verifique os valores selecionados nas etapas anteriores.
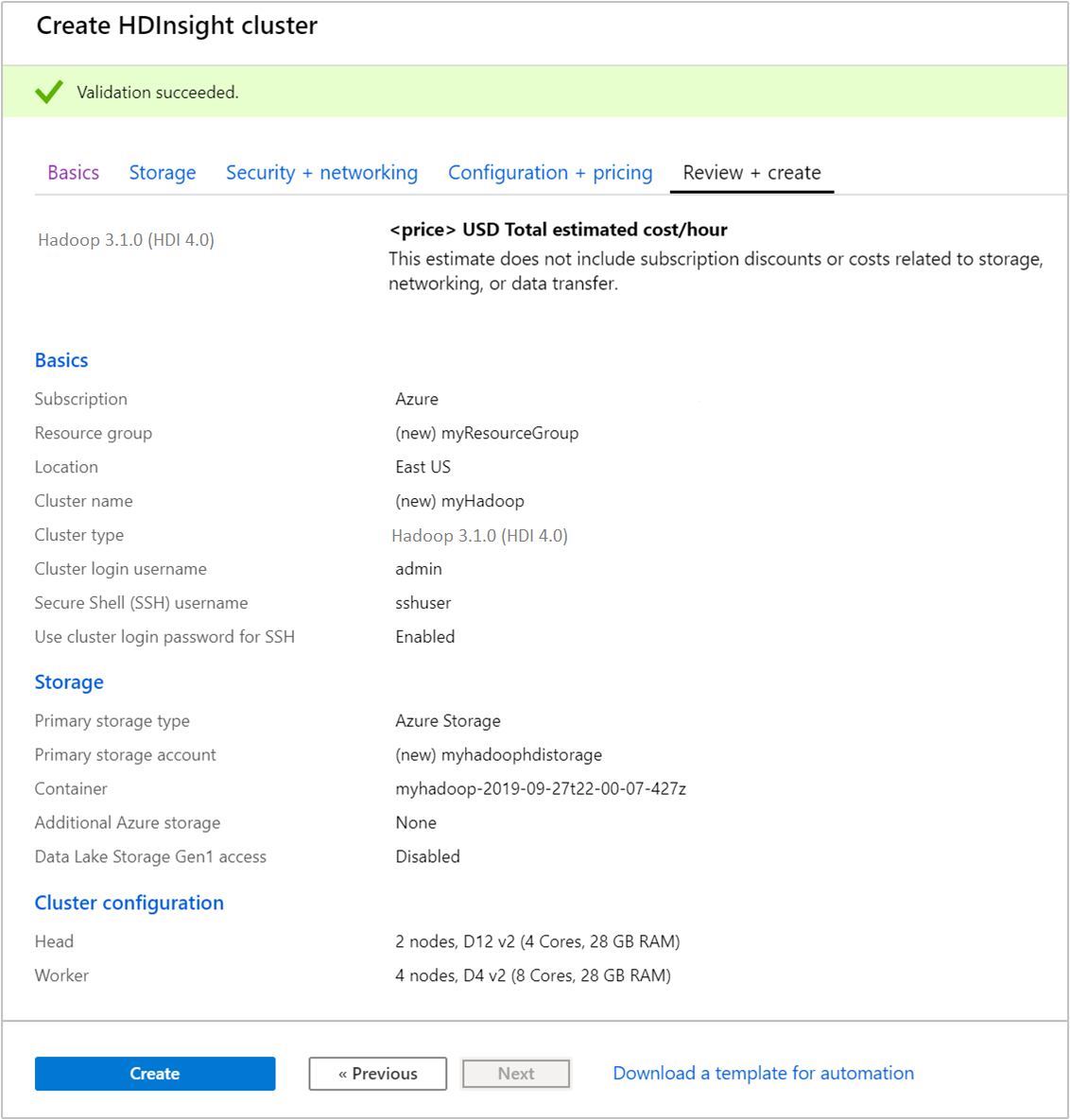
Selecione Criar. Demora cerca de 20 minutos para criar um cluster.
Após a criação do cluster, você verá a página de visão geral do cluster no Portal do Azure.
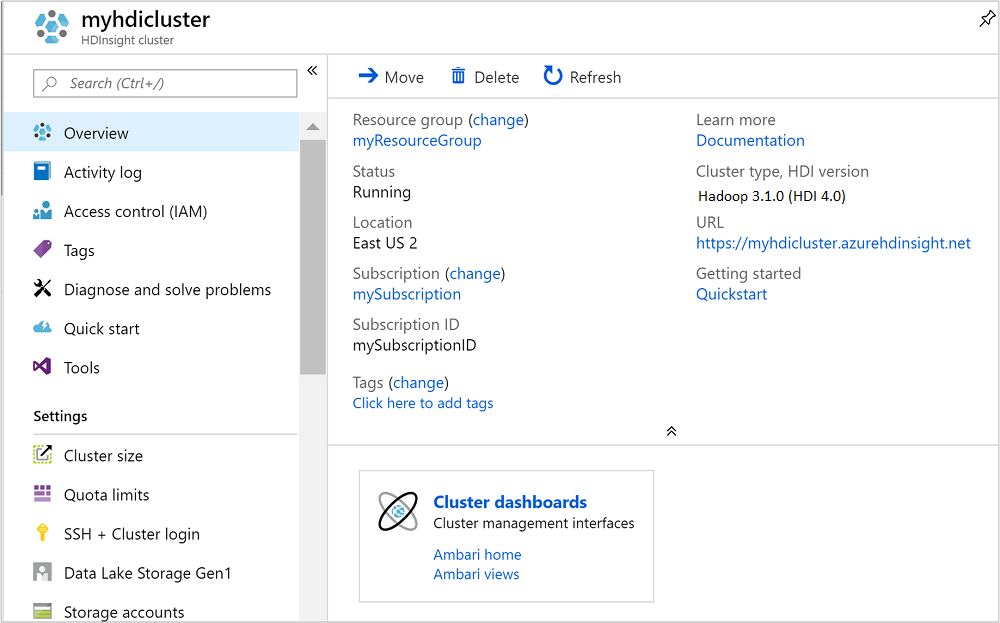
Executar consultas do Apache Hive
Apache Hive é o componente mais popular usado no HDInsight. Há várias maneiras de executar trabalhos do Hive no HDInsight. Neste início rápido, você usará o modo de exibição do Ambari Hive no portal. Para obter outros métodos para enviar trabalhos do Hive, confira Usar o Hive no HDInsight.
Observação
O Apache Hive View não está disponível no HDInsight 4.0.
Para abrir o Ambari, na captura de tela anterior, selecione Painel do Cluster. Navegue também até
https://ClusterName.azurehdinsight.netondeClusterNameestá o cluster que você criou na seção anterior.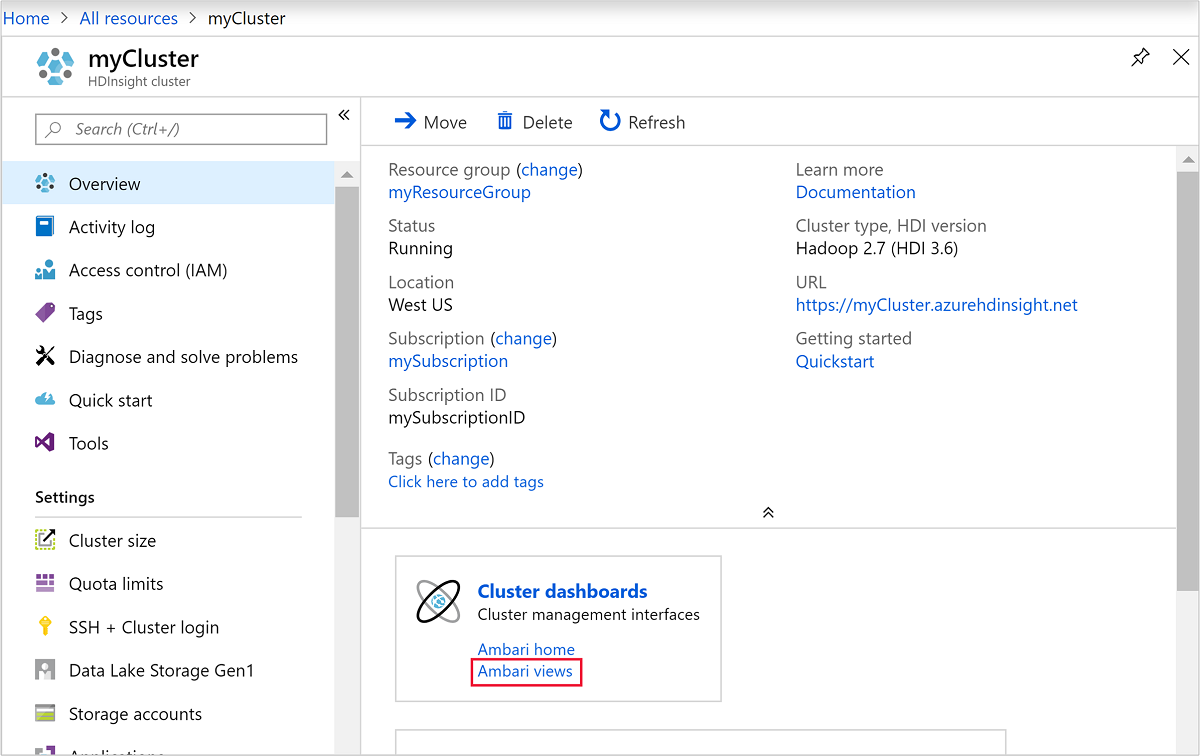
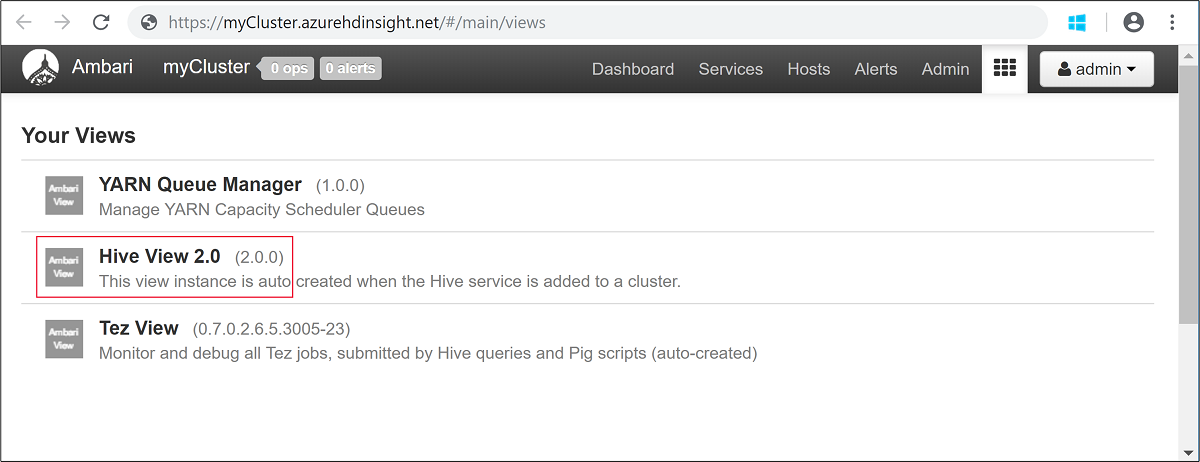
Insira o nome de usuário e a senha do Hadoop que você especificou durante a criação do cluster. O nome de usuário padrão é
admin.Abra a Exibição do Hive , conforme mostrado na seguinte captura de tela:
Na guia CONSULTA, cole as seguintes instruções HiveQL na planilha:
SHOW TABLES;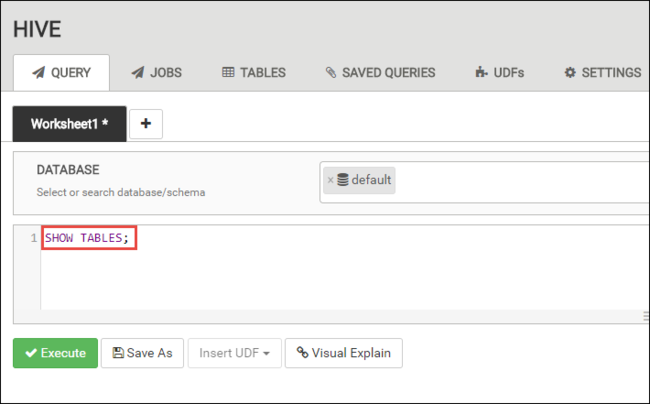
Selecione Executar. Uma guia RESULTADOS aparece abaixo da guia CONSULTA e exibe informações sobre o trabalho.
Após a conclusão da consulta, a guia CONSULTA exibirá os resultados da operação. Você deverá ver uma tabela chamada hivesampletable. Essa tabela do Hive de exemplo é fornecida com todos os clusters HDInsight.
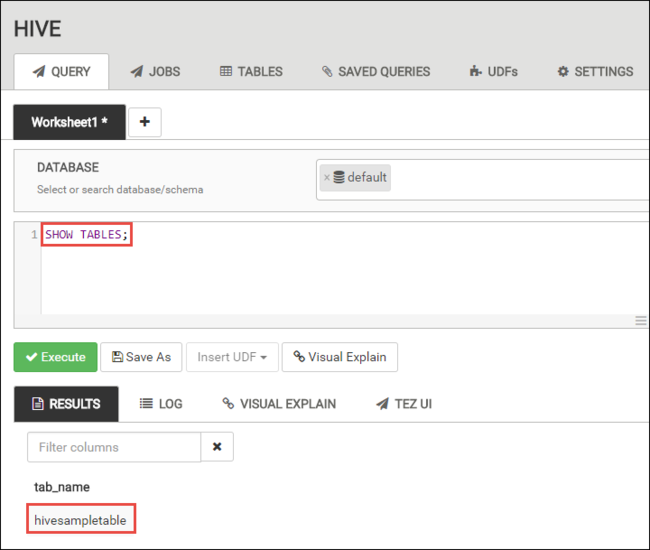
Repita as etapas 4 e 5 para executar a seguinte consulta:
SELECT * FROM hivesampletable;Você também pode salvar os resultados da consulta. Selecione o botão de menu à direita e especifique se deseja baixar os resultados como um arquivo CSV ou armazená-los na conta de armazenamento associada ao cluster.
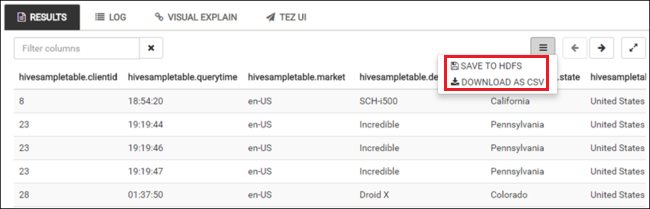
Depois de concluir um trabalho do Hive, você poderá exportar os resultados para o Banco de Dados SQL do Azure ou o banco de dados do SQL Server e visualizar os resultados usando o Excel. Para obter mais informações sobre como usar o Hive no HDInsight, confira Usar o Apache Hive e o HiveQL com o Apache Hadoop no HDInsight para analisar um arquivo log4j do Apache de exemplo.
Limpar os recursos
Após concluir o início rápido, poderá ser conveniente excluir o cluster. Com o HDInsight, seus dados são armazenados no Armazenamento do Azure, assim você poderá excluir, com segurança, um cluster quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como os encargos para o cluster são muitas vezes maiores do que os encargos para armazenamento, faz sentido, do ponto de vista econômico, excluir os clusters quando não estiverem em uso.
Observação
Se você for prosseguir imediatamente para o próximo artigo a fim de saber como executar operações de ETL usando Hadoop no HDInsight, convém manter o cluster em execução. Isso porque, no tutorial, você precisará criar um cluster Hadoop novamente. No entanto, se você não for conferir o próximo artigo imediatamente, exclua o cluster agora.
Para excluir o cluster e/ou a conta de armazenamento padrão
Volte para a guia do navegador onde você tem o portal do Azure. Você deve estar na página de visão geral do cluster. Se você quiser apenas excluir o cluster, mas manter a conta de armazenamento padrão, selecione Excluir.
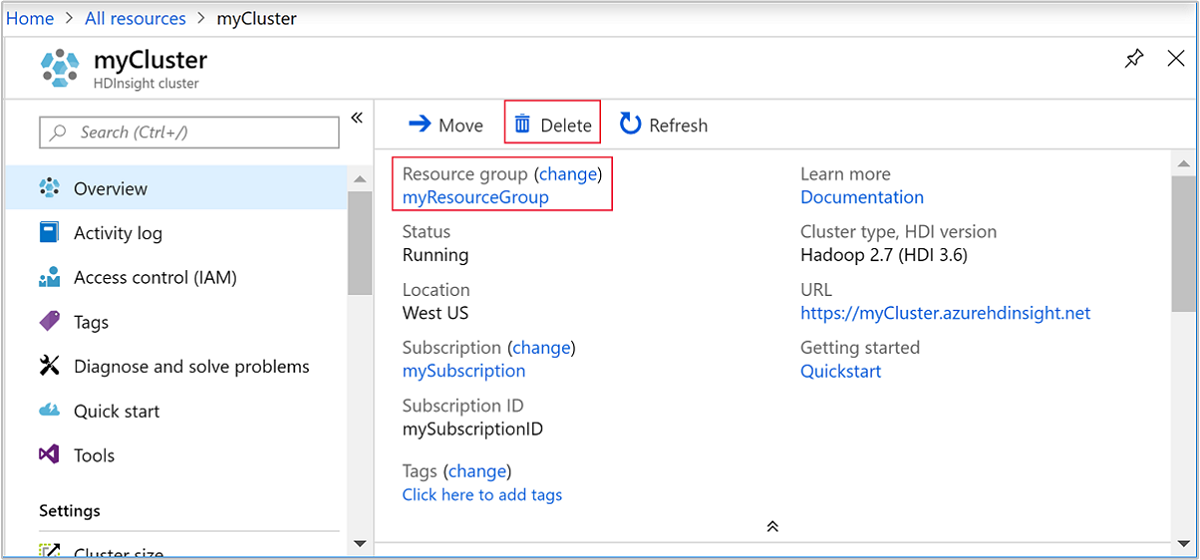
Se você quiser excluir o cluster, bem como a conta de armazenamento padrão, selecione o nome do grupo de recursos (realçado na captura de tela anterior) para abrir a página do grupo de recursos.
Selecione Excluir grupo de recursos para excluir o grupo de recursos, que contém o cluster e a conta de armazenamento padrão. Observe que a exclusão do grupo de recursos exclui a conta de armazenamento. Para manter a conta de armazenamento, exclua apenas o cluster.
Próximas etapas
Neste início rápido, você aprendeu a criar um cluster HDInsight baseado em Linux usando um modelo do Resource Manager e a executar consultas básicas do Hive. No próximo artigo, saiba como executar uma operação de ETL (extração, transformação e carregamento) usando o Hadoop no HDInsight.