Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
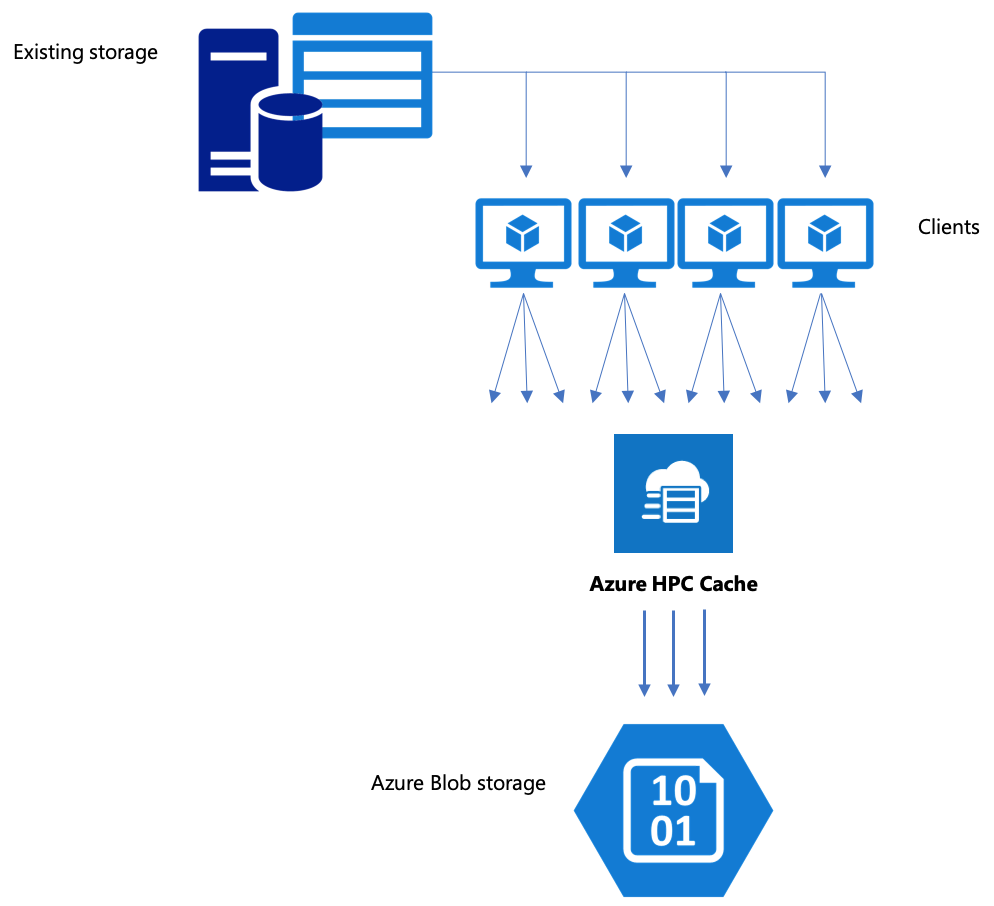
Se o fluxo de trabalho incluir a movimentação de dados para o Armazenamento de Blobs do Azure, verifique se você está usando uma estratégia eficiente. Você deve criar o cache, adicionar o contêiner de blob como um destino de armazenamento e copiar seus dados usando o Azure HPC Cache.
Este artigo explica as melhores maneiras de mover dados para o armazenamento de blobs para uso com o Azure HPC Cache.
Dica
Este artigo não se aplica ao armazenamento de blobs montados em NFS (alvos de armazenamento ADLS-NFS). Você pode usar qualquer método baseado em NFS para preencher um contêiner de blobs ADLS-NFS antes ou depois de adicioná-lo ao HPC Cache. Leia sobre pré-carregamento de dados com o protocolo NFS para saber mais.
Tenha estes fatos em mente:
O HPC Cache do Azure usa um formato de armazenamento especializado para organizar dados no armazenamento de blobs. É por isso que um destino de armazenamento de blobs deve ser um contêiner novo e vazio ou um contêiner de blob usado anteriormente para dados do Azure HPC Cache.
Copiar dados por meio do HPC Cache do Azure para um destino de armazenamento de back-end é mais eficiente quando você usa vários clientes e operações paralelas. Um comando de cópia simples de um cliente moverá os dados lentamente.
As estratégias descritas neste artigo funcionam para preencher um contêiner de blob vazio ou para adicionar arquivos a um destino de armazenamento usado anteriormente.
Copiar dados por meio do HPC Cache do Azure
O HPC Cache do Azure foi projetado para atender a vários clientes simultaneamente, portanto, para copiar dados por meio do cache, você deve usar gravações paralelas de vários clientes.
Os comandos cp ou copy que você normalmente usa para transferir dados de um sistema de armazenamento para outro são processos monothread que copiam apenas um arquivo de cada vez. Isso significa que o servidor de arquivos está ingerindo apenas um arquivo por vez , o que é um desperdício de recursos do cache.
Esta seção explica estratégias para criar um sistema de cópia de arquivos multicliente e multithreaded para transferir dados para o Blob Storage com o Azure HPC Cache. Ele explica os conceitos de transferência de arquivo e os pontos de decisão que podem ser usados para copiar dados eficientes usando vários clientes e comandos de cópia simples.
Ele também explica alguns utilitários que podem ajudar. O msrsync utilitário pode ser usado para automatizar parcialmente o processo de divisão de um conjunto de dados em buckets e uso de comandos rsync. O parallelcp script é outro utilitário que lê o diretório de origem e emite comandos de cópia automaticamente.
Planejamento estratégico
Ao criar uma estratégia para copiar dados em paralelo, você deve entender as compensações no tamanho do arquivo, na contagem de arquivos e na profundidade do diretório.
- Quando os arquivos são pequenos, a métrica de interesse é arquivos por segundo.
- Quando os arquivos são grandes (10MiBi ou superior), a métrica de interesse é bytes por segundo.
Cada processo de cópia tem uma taxa de transferência e uma taxa de transferência de arquivos, que podem ser medidas pelo tempo do comando de cópia e considerando o tamanho e a quantidade de arquivos. Explicar como medir as taxas está fora do escopo deste documento, mas é imperativo entender se você lidará com arquivos pequenos ou grandes.
As estratégias de ingestão de dados paralelas com o HPC Cache do Azure incluem:
Cópia manual – você pode criar manualmente uma cópia com vários threads em um cliente executando mais de um comando de cópia ao mesmo tempo em segundo plano em conjuntos predefinidos de arquivos ou caminhos. Ler "Ingestão de dados do Azure HPC Cache – método de cópia manual" para obter detalhes.
A cópia parcialmente automatizada com
msrsync-msrsyncé um utilitário wrapper que executa vários processos paralelosrsync. Para obter detalhes, leia a ingestão de dados do Azure HPC Cache – método msrsync.Copiação com script com
parallelcp– Saiba como criar e executar um script de cópia paralelo na ingestão de dados do Cache HPC do Azure – método de script de cópia paralela.
Próximas Etapas
Depois de configurar o armazenamento, saiba como os clientes podem montar o cache.