Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
Extensão de ML da CLI do Azurev2 (atual)
Neste artigo, você aprenderá a criar e executar pipelines de machine learning usando a CLI do Azure e componentes. Você pode criar pipelines sem usar componentes, mas os componentes fornecem flexibilidade e habilitam a reutilização. Os pipelines do Azure Machine Learning podem ser definidos em YAML e executados na CLI, criados em Python ou compostos no designer do estúdio do Azure Machine Learning por meio de uma interface de arrastar e soltar. Este artigo se concentra na CLI.
Pré-requisitos
Uma assinatura do Azure. Se não tiver uma, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
A extensão da CLI do Azure para Machine Learning, instalada e configurada.
Um clone do repositório de exemplos. Você pode usar esses comandos para clonar o repositório:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Leitura prévia sugerida
Crie seu primeiro pipeline com componentes
Primeiro, você criará um pipeline com componentes usando um exemplo. Isso lhe dá uma impressão inicial de como é um pipeline e um componente no Azure Machine Learning.
No diretório cli/jobs/pipelines-with-components/basics do repositório azureml-examples, vá para o subdiretório 3b_pipeline_with_data. Há três tipos de arquivos nesse diretório. Esses são os arquivos que você precisa criar ao criar seu próprio pipeline.
pipeline.yml. Esse arquivo YAML define o pipeline de machine learning. Ele descreve como dividir uma tarefa de aprendizado de máquina completa em um fluxo de trabalho de várias etapas. Por exemplo, considere a tarefa simples de machine learning de usar dados históricos para treinar um modelo de previsão de vendas. Talvez você queira criar um fluxo de trabalho sequencial que contenha etapas de processamento de dados, treinamento de modelo e avaliação de modelo. Cada etapa é um componente que tem uma interface bem definida e pode ser desenvolvido, testado e otimizado de forma independente. O YAML do pipeline também define como as etapas secundárias se conectam a outras etapas no pipeline. Por exemplo, a etapa de treinamento do modelo gera um arquivo de modelo e o arquivo de modelo é passado para uma etapa de avaliação de modelo.
component.yml. Esses arquivos YAML definem os componentes. Elas contêm as seguintes informações:
- Metadados: Nome, nome de exibição, versão, descrição, tipo e assim por diante. Os metadados ajudam a descrever e gerenciar o componente.
- Interface: entradas e saídas. Por exemplo, um componente de treinamento de modelo usa dados de treinamento e número de épocas como entrada e gera um arquivo de modelo treinado como saída. Depois que a interface for definida, diferentes equipes poderão desenvolver e testar o componente de forma independente.
- Comando, código e ambiente: o comando, o código e o ambiente para executar o componente. O comando é o comando shell para executar o componente. O código geralmente se refere a um diretório de código-fonte. O ambiente pode ser um ambiente do Azure Machine Learning (curado ou criado pelo cliente), uma imagem Docker ou um ambiente conda.
component_src. Estes são os diretórios de código-fonte para componentes específicos. Eles contêm o código-fonte executado no componente. Você pode usar seu idioma preferido, incluindo Python, R e outros. O código deve ser executado por um comando de shell. O código-fonte pode usar algumas entradas da linha de comando do shell para controlar como essa etapa é executada. Por exemplo, uma etapa de treinamento pode usar dados de treinamento, taxa de aprendizado e o número de épocas para gerenciar o processo de treinamento. O argumento de um comando de shell é usado para passar entradas e saídas para o código.
Agora você criará um pipeline usando o 3b_pipeline_with_data exemplo. Cada arquivo é explicado mais adiante nas seções a seguir.
Primeiro, liste os recursos de computação disponíveis usando o seguinte comando:
az ml compute list
Se você não o tiver, crie um cluster chamado cpu-cluster executando este comando:
Observação
Ignore esta etapa para usar a computação sem servidor.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Agora, crie um trabalho de pipeline definido no arquivo pipeline.yml executando o comando a seguir. O destino de computação é referenciado no arquivo pipeline.yml como azureml:cpu-cluster. Se o destino de computação usar um nome diferente, lembre-se de atualizá-lo no arquivo pipeline.yml.
az ml job create --file pipeline.yml
Você deverá receber um dicionário JSON com informações sobre o trabalho do pipeline, incluindo:
| Chave | Descrição |
|---|---|
name |
O nome baseado em GUID do trabalho. |
experiment_name |
O nome sob o qual os trabalhos serão organizados no Estúdio. |
services.Studio.endpoint |
Uma URL para monitorar e revisar o trabalho do pipeline. |
status |
O status do trabalho. Provavelmente será Preparing neste momento. |
Vá para a URL services.Studio.endpoint para ver uma visualização do pipeline.
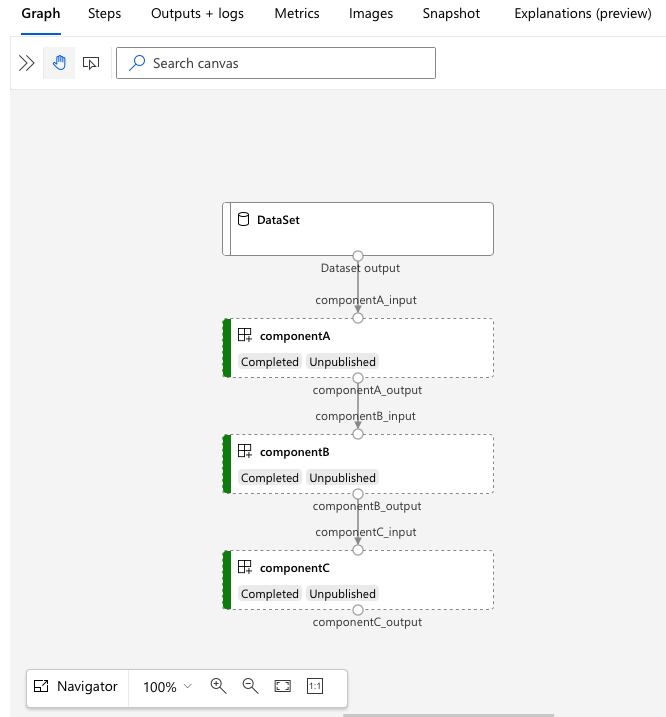
Entender a definição de pipeline YAML
Agora você examinará a definição de pipeline no arquivo 3b_pipeline_with_data/pipeline.yml .
Observação
Para usar a computação sem servidor, substitua default_compute: azureml:cpu-cluster por default_compute: azureml:serverless neste arquivo.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
A tabela a seguir descreve os campos mais usados do esquema YAML do pipeline. Para saber mais, confira o esquema YAML de pipeline completo.
| Chave | Descrição |
|---|---|
type |
Obrigatório. O tipo de trabalho. Deve ser pipeline para trabalhos de pipeline. |
display_name |
Nome de exibição do trabalho de pipeline na interface do estúdio. Editável na interface do estúdio. Não precisa ser exclusivo em todos os trabalhos do espaço de trabalho. |
jobs |
Obrigatório. Um dicionário do conjunto de trabalhos individuais a serem executados como etapas no pipeline. Esses trabalhos são considerados trabalhos filho do trabalho do pipeline pai. Na versão atual, os tipos de trabalho com suporte no pipeline são command e sweep. |
inputs |
Um dicionário de entradas para o trabalho de pipeline. A chave é um nome para a entrada dentro do contexto do trabalho e o valor é o valor de entrada. Você pode referenciar essas entradas de pipeline pelas entradas de um trabalho de etapa individual no pipeline usando a expressão ${{ parent.inputs.<input_name> }}. |
outputs |
Um dicionário de configurações de saída do trabalho de pipeline. A chave é um nome para a saída no contexto do trabalho e o valor é a configuração de saída. Você pode referenciar essas saídas de pipeline pelas saídas de um trabalho de etapa individual no pipeline usando a expressão ${{ parents.outputs.<output_name> }}. |
O exemplo de 3b_pipeline_with_data contém um pipeline de três etapas.
- As três etapas são definidas em
jobs. Todas as três etapas são do tipocommand. A definição de cada etapa está em um arquivo correspondentecomponent*.yml. Você pode ver os arquivos YAML do componente no diretório 3b_pipeline_with_data .componentA.ymlé descrito na próxima seção. - Esse pipeline tem dependência de dados, o que é comum em pipelines reais. O componente A obtém a entrada de dados de uma pasta local em
./data(linhas 18-21) e passa sua saída para o componente B (linha 29). A saída do componente A pode ser referenciada como${{parent.jobs.component_a.outputs.component_a_output}}. -
default_computedefine a computação padrão para o pipeline. Se um componente emjobsdefinir uma computação diferente, as configurações específicas do componente serão respeitadas.

Ler e gravar dados em um pipeline
Um cenário comum é ler e gravar dados em um pipeline. No Azure Machine Learning, você usa o mesmo esquema para ler e gravar dados para todos os tipos de trabalhos (trabalhos de pipeline, trabalhos de comando e trabalhos de varredura). A seguir estão exemplos de uso de dados em pipelines para cenários comuns:
- Dados locais
- Arquivo Web com uma URL pública
- Um armazenamento de dados e um caminho do Azure Machine Learning
- Ativos de dados do Azure Machine Learning
Entender o YAML de definição do componente
Este é o arquivo componentA.yml , um exemplo de YAML que define um componente:
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Esta tabela define os campos mais usados do componente YAML. Para saber mais, consulte o esquema YAML de componente completo.
| Chave | Descrição |
|---|---|
name |
Obrigatório. O nome do componente. Ele deve ser exclusivo no espaço de trabalho do Azure Machine Learning. Ele deve começar com uma letra minúscula. Letras minúsculas, números e sublinhados (_) são permitidos. O comprimento máximo é de 255 caracteres. |
display_name |
Nome de exibição do componente na interface do usuário do estúdio. Ele não precisa ser exclusivo dentro do ambiente de trabalho. |
command |
Obrigatório. O comando a ser executado. |
code |
O caminho local para o diretório do código-fonte a ser carregado e usado para o componente. |
environment |
Obrigatório. O ambiente usado para executar o componente. |
inputs |
Um dicionário de entradas de componentes. A chave é um nome para a entrada dentro do contexto do componente e o valor é a definição de entrada do componente. Você pode referenciar entradas no comando usando a ${{ inputs.<input_name> }} expressão. |
outputs |
Um dicionário de saídas de componentes. A chave é um nome para a saída dentro do contexto do componente e o valor é a definição de saída do componente. Você pode referenciar saídas no comando usando a ${{ outputs.<output_name> }} expressão. |
is_deterministic |
Se será necessário reutilizar o resultado do trabalho anterior se as entradas do componente não forem alteradas. O valor padrão é true. Essa configuração também é conhecida como reutilização por padrão. O cenário comum quando definido false é forçar o recarregamento de dados do armazenamento em nuvem ou de uma URL. |
No exemplo em 3b_pipeline_with_data/componentA.yml, o componente A tem uma entrada de dados e uma saída de dados, que podem ser conectadas a outras etapas no pipeline pai. Todos os arquivos na seção code do componente YAML serão carregados no Azure Machine Learning quando o trabalho de pipeline for enviado. Neste exemplo, os arquivos ./componentA_src abaixo serão carregados. (Linha 16 em componentA.yml.) Você pode ver o código-fonte carregado na interface do usuário do estúdio: clique duas vezes na etapa componentA no grafo e vá para a guia Código , conforme mostrado na captura de tela a seguir. Você pode ver que é um script hello-world que faz uma impressão simples e grava a data e hora atuais no caminho componentA_output. O componente usa entrada e fornece saída por meio da linha de comando. É tratado em hello.py via argparse.

Entrada e saída
A entrada e a saída definem a interface de um componente. A entrada e a saída podem ser valores literais (do tipo string, numberou integer) ou booleanum objeto que contém um esquema de entrada.
A entrada Objeto (do tipo uri_file, uri_folder, mltable, mlflow_model ou custom_model) pode se conectar a outras etapas no trabalho de pipeline pai para passar dados/modelos para outras etapas. No gráfico do pipeline, a entrada do tipo objeto é exibida como um ponto de conexão.
Entradas de valor literal (string, number, , integer) booleansão os parâmetros que você pode passar para o componente em runtime. Você pode adicionar um valor padrão de entradas literais no default campo. Para os tipos number e integer, você também pode adicionar valores mínimos e máximos usando os campos min e max. Se o valor de entrada for menor que o mínimo ou mais do que o máximo, o pipeline falhará na validação. A validação ocorre antes de enviar um trabalho de pipeline, o que pode economizar tempo. A validação funciona para a CLI, o SDK do Python e a interface do usuário do Designer. A captura de tela a seguir mostra um exemplo de validação na interface do usuário do Designer. Da mesma forma, você pode definir valores permitidos em enum campos.

Se você quiser adicionar uma entrada a um componente, precisará fazer edições em três locais:
- O campo
inputsno YAML do componente. - O campo
commandno YAML do componente. - No código-fonte do componente que processa a entrada de linha de comando.
Esses locais são marcados com caixas verdes na captura de tela anterior.
Para saber mais sobre entradas e saídas, consulte Gerenciar entradas e saídas para componentes e pipelines.
Ambientes
O ambiente é o ambiente no qual o componente é executado. Pode ser um ambiente do Azure Machine Learning (pré-configurado ou personalizado), uma imagem do Docker ou um ambiente conda. Veja os seguintes exemplos:
-
Ativo registrado do ambiente Azure Machine Learning. O ambiente é referenciado no componente com a sintaxe
azureml:<environment-name>:<environment-version>. - Imagem pública do Docker.
- Arquivo Conda. O arquivo conda precisa ser usado junto com uma imagem base.
Registrar um componente para reutilização e compartilhamento
Embora alguns componentes sejam específicos para um pipeline específico, o benefício real dos componentes vem da reutilização e do compartilhamento. Você pode registrar um componente no workspace do Machine Learning para disponibilizá-lo para reutilização. Os componentes registrados dão suporte ao controle de versão automático para que você possa atualizar o componente, mas verifique se os pipelines que exigem uma versão mais antiga continuarão funcionando.
No repositório azureml-examples, vá para o cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components diretório.
Para registrar um componente, use o comando az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Depois que esses comandos são executados, você pode ver os componentes no estúdio, em Assets>Componentes:

Selecione um componente. Você verá informações detalhadas de cada versão do componente.
A guia Detalhes mostra informações básicas como o nome do componente, quem o criou e a versão. Há campos editáveis para Marcas e Descrição. Você pode usar tags para adicionar palavras-chave para busca. O campo de descrição dá suporte à formatação markdown. Você deve usá-lo para descrever a funcionalidade do componente e o uso básico.
Na guia Trabalhos , você verá o histórico de todos os trabalhos que usam o componente.
Use componentes registrados em um arquivo YAML do trabalho do pipeline
Agora você usará 1b_e2e_registered_components como exemplo de como usar o componente registrado no YAML do pipeline. Vá para o 1b_e2e_registered_components diretório e abra o pipeline.yml arquivo. As chaves e os valores nos campos inputs e outputs são semelhantes aos já discutidos. A única diferença significativa é o valor dos campos component nas entradas jobs.<job_name>.component. O valor component está na forma azureml:<component_name>:<component_version>. A train-job definição, por exemplo, especifica que a versão mais recente do componente my_train registrado deve ser usada:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Gerenciar componentes
Você pode verificar os detalhes do componente e gerenciar componentes usando a CLI v2. Use az ml component -h para obter instruções detalhadas sobre comandos de componente. A seguinte tabela lista todas os comandos disponíveis. Veja mais exemplos na referência da CLI do Azure.
| Comando | Descrição |
|---|---|
az ml component create |
Criar um componente. |
az ml component list |
Liste os componentes em uma área de trabalho. |
az ml component show |
Mostrar os detalhes de um componente. |
az ml component update |
Atualizar um componente. Apenas alguns campos (descrição, display_name) dão suporte à atualização. |
az ml component archive |
Arquive um contêiner de componentes. |
az ml component restore |
Restaurar um componente arquivado. |
Próxima etapa
- Experimente o exemplo de componente da CLI v2