Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
No Azure Machine Learning, você pode usar um contêiner personalizado para implantar um modelo em um ponto de extremidade online. Implantações de contêiner personalizadas podem usar servidores Web diferentes do servidor Python Flask padrão que o Azure Machine Learning usa.
Ao usar uma implantação personalizada, você pode:
- Use várias ferramentas e tecnologias, como o TensorFlow Serving (Serviço TF), TorchServe, Triton Inference Server, o pacote Plumber R e a imagem mínima de inferência do Azure Machine Learning.
- Ainda aproveite o monitoramento interno, o dimensionamento, o alerta e a autenticação oferecidos pelo Azure Machine Learning.
Este artigo mostra como usar uma imagem de TF Serving para servir um modelo do TensorFlow.
Prerequisites
Um Workspace do Azure Machine Learning. Para obter instruções sobre como criar um workspace, consulte Criar o workspace.
A CLI do Azure e a extensão
mlou o SDK do Python do Azure Machine Learning v2:Para instalar a CLI do Azure e a
mlextensão, consulte Instalar e configurar a CLI (v2).Os exemplos neste artigo pressupõem que você use um shell do tipo Bash ou um shell compatível. Por exemplo, você pode usar um shell em um sistema Linux ou no Subsistema do Windows para Linux.
Um grupo de recursos do Azure que contém seu workspace e que você ou sua entidade de serviço têm acesso de Colaborador. Se você usar as etapas em Criar o workspace para configurar seu workspace, atenderá a esse requisito.
Docker Engine, installed and running locally. This prerequisite is highly recommended. Você precisa dele para implantar um modelo localmente e isso é útil para depuração.
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Script da CLI do Azure | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Implanta vários modelos em uma única implantação estendendo a imagem mínima de inferência do Azure Machine Learning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Implanta um único modelo estendendo a imagem mínima de inferência do Azure Machine Learning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Implanta dois modelos do MLFlow com requisitos diferentes do Python em duas implantações separadas atrás de um único ponto de extremidade. Usa a imagem mínima de inferência do Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Implanta três modelos de regressão em um ponto de extremidade. Usa o pacote R do Encanador. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Implanta um modelo Half Plus Two usando um contêiner personalizado do TF Serving. Utiliza o processo padrão de registro de modelo. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Implanta um modelo chamado Half Plus Two utilizando um contêiner personalizado do TF Serving com o modelo integrado à imagem. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Implanta um único modelo usando um contêiner personalizado TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Implanta um modelo triton usando um contêiner personalizado. |
Este artigo mostra como usar o exemplo tfserving/half-plus-two.
Warning
As equipes de suporte da Microsoft podem não ser capazes de ajudar a solucionar problemas causados por uma imagem personalizada. Se você encontrar problemas, talvez você seja solicitado a usar a imagem padrão ou uma das imagens que a Microsoft fornece para ver se o problema é específico para sua imagem.
Baixar o código-fonte
The steps in this article use code samples from the azureml-examples repository. Use os seguintes comandos para clonar o repositório:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inicializar variáveis de ambiente
Para usar um modelo tensorFlow, você precisa de várias variáveis de ambiente. Execute os seguintes comandos para definir essas variáveis:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Implantar um modelo do TensorFlow
Baixe e descompacte um modelo que divide um valor de entrada por dois e adiciona dois ao resultado:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Testar uma imagem de serviço TF localmente
Use o Docker para executar sua imagem localmente para teste:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Enviar solicitações de ativação e pontuação para a imagem
Envie uma solicitação de dinâmica para verificar se o processo dentro do contêiner está em execução. Você deve obter um código de status de resposta de 200 OK.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Envie uma solicitação de pontuação para verificar se você pode obter previsões sobre dados não rotulados:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Parar a imagem
Ao concluir o teste localmente, interrompa a imagem:
docker stop tfserving-test
Implantar o ponto de extremidade online no Azure
Para implantar seu ponto de extremidade online no Azure, execute as etapas nas seções a seguir.
Criar arquivos YAML para seu endpoint e implantação
Você pode configurar sua implantação na nuvem usando YAML. Por exemplo, para configurar o endpoint, você pode criar um arquivo YAML chamado tfserving-endpoint.yml que contém as seguintes linhas:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
Para configurar sua implantação, você pode criar um arquivo YAML chamado tfserving-deployment.yml que contém as seguintes linhas:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
As seções a seguir discutem conceitos importantes sobre os parâmetros YAML e Python.
Base image
Na seção environment do YAML ou no construtor Environment em Python, especifique a imagem base como um parâmetro. Este exemplo usa docker.io/tensorflow/serving:latest como o image valor.
Se você inspecionar o contêiner, poderá ver que esse servidor usa comandos ENTRYPOINT para iniciar um script de ponto de entrada. Esse script usa variáveis de ambiente como MODEL_BASE_PATH e MODEL_NAMEexpõe portas como 8501. Todos esses detalhes pertencem a esse servidor e você pode usar essas informações para determinar como definir sua implantação. Por exemplo, se você definir as variáveis de ambiente MODEL_BASE_PATH e MODEL_NAME na definição de implantação, o TF Serving usará esses valores para iniciar o servidor. Da mesma forma, se você definir a porta para cada rota 8501 na definição de implantação, as solicitações do usuário para essas rotas serão roteadas corretamente para o servidor TF Serving.
Este exemplo é baseado no caso TF Serving. Mas você pode usar qualquer contêiner que permaneça ativo e responda a solicitações que vão para rotas de vida, preparação e pontuação. Para ver como formar um Dockerfile para criar um contêiner, você pode consultar outros exemplos. Alguns servidores usam CMD instruções em vez de ENTRYPOINT instruções.
O parâmetro inference_config
Na environment seção ou Environment na classe, inference_config é um parâmetro. Ele especifica a porta e o caminho para três tipos de rotas: atividade, preparação e rotas de pontuação. O inference_config parâmetro será necessário se você quiser executar seu próprio contêiner com um ponto de extremidade online gerenciado.
Rotas de preparação versus rotas de vida
Alguns servidores de API fornecem uma maneira de verificar o status do servidor. Há dois tipos de rotas que você pode especificar para verificar o status:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
No contexto de inferência de machine learning, um servidor pode responder com um código de status de 200 OK a uma solicitação de atividade antes de carregar um modelo. O servidor pode responder com um código de status de 200 OK a uma solicitação de preparação somente depois de carregar o modelo na memória.
Para obter mais informações sobre investigações de disponibilidade e preparação, consulte Configurar Liveness, Readiness e Startup Probes.
O servidor de API escolhido determina as rotas de disponibilidade e preparação. Você identifica esse servidor em uma etapa anterior ao testar o contêiner localmente. Neste artigo, a implantação de exemplo usa o mesmo caminho para as rotas de disponibilidade e preparação, pois o Serviço de TF define apenas uma rota de vida útil. Para obter outras maneiras de definir as rotas, consulte outros exemplos.
Scoring routes
O servidor de API que você usa fornece uma maneira de receber o conteúdo no qual trabalhar. No contexto da inferência de machine learning, um servidor recebe os dados de entrada por meio de uma rota específica. Identifique essa rota para o servidor de API ao testar o contêiner localmente em uma etapa anterior. Especifique essa rota como a rota de pontuação quando você definir a implantação a ser criada.
A criação bem-sucedida da implantação também atualiza o parâmetro do ponto de extremidade scoring_uri. Você pode verificar esse fato executando o seguinte comando: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Localizar o modelo montado
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. Quando o modelo é montado, você pode implantar novas versões do modelo sem precisar criar uma nova imagem do Docker. By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
Por exemplo, considere a seguinte configuração:
- Uma estrutura de diretório em seu computador local de /azureml-examples/cli/endpoints/online/custom-container
- Um nome de modelo de
half_plus_two
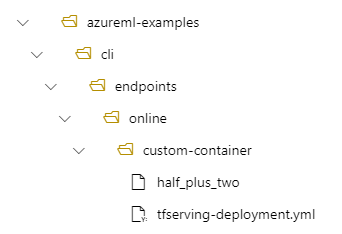
Suponha que seu arquivo tfserving-deployment.yml contenha as linhas a seguir em sua model seção. Nesta seção, o name valor refere-se ao nome que você usa para registrar o modelo no Azure Machine Learning.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Nesse caso, quando você cria uma implantação, seu modelo está localizado na seguinte pasta: /var/azureml-app/azureml-models/tfserving-mounted/1.
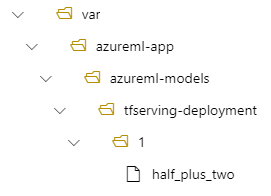
Opcionalmente, você pode configurar seu model_mount_path valor. Ajustando essa configuração, você pode alterar o caminho em que o modelo está montado.
Important
O model_mount_path valor deve ser um caminho absoluto válido no Linux (no sistema operacional convidado da imagem do contêiner).
Important
model_mount_path é utilizável somente no cenário BYOC (Traga seu próprio contêiner). No cenário BYOC, o ambiente usado pela implantação online deve ter inference_config o parâmetro configurado. Você pode usar a CLI do Azure ML ou o SDK do Python para especificar inference_config o parâmetro ao criar o ambiente. Atualmente, a interface do usuário do Studio não dá suporte à especificação desse parâmetro.
Quando você altera o valor de model_mount_path, você também precisa atualizar a variável de MODEL_BASE_PATH ambiente. Defina MODEL_BASE_PATH ao mesmo valor de model_mount_path para evitar uma implantação com falha por não encontrar o caminho base.
Por exemplo, você pode adicionar o model_mount_path parâmetro ao arquivo tfserving-deployment.yml. Você também pode atualizar o MODEL_BASE_PATH valor nesse arquivo:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
Em sua implantação, seu modelo está localizado em /var/tfserving-model-mount/tfserving-mounted/1. Ele não está mais em azureml-app/azureml-models, mas no caminho de montagem especificado:
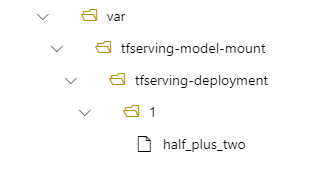
Criar seu ponto de extremidade e implantação
Depois de construir seu arquivo YAML, use o seguinte comando para criar seu ponto de extremidade:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Use o comando a seguir para criar sua implantação. Esta etapa pode durar alguns minutos.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Invocar o ponto de extremidade
Quando a implantação for concluída, faça uma solicitação de pontuação para o ponto de extremidade implantado.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Excluir o ponto de extremidade
Se você não precisar mais do ponto de extremidade, execute o seguinte comando para excluí-lo:
az ml online-endpoint delete --name tfserving-endpoint