Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A Instância Gerenciada do Azure para Apache Cassandra fornece operações automatizadas de implantação e dimensionamento para datacenters do Apache Cassandra de software livre gerenciados. Esse recurso acelera cenários híbridos e ajuda a reduzir a manutenção contínua.
Este guia rápido demonstra como usar o portal do Azure para criar um cluster Apache Spark totalmente gerenciado dentro da rede virtual do Azure do seu Azure Managed Instance for Apache Cassandra cluster. Você cria o cluster do Spark no Azure Databricks. Posteriormente, você pode criar ou anexar notebooks ao cluster, ler dados de diferentes fontes de dados e analisar insights.
Você também pode saber mais com instruções detalhadas sobre como implantar o Azure Databricks em sua rede virtual do Azure (injeção de rede virtual).
Pré-requisitos
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Criar um cluster do Azure Databricks
Siga estas etapas para criar um cluster do Azure Databricks em uma rede virtual que tenha a Instância Gerenciada do Azure para Apache Cassandra:
Entre no portal do Azure.
No painel esquerdo, localize grupos de recursos. Vá para o grupo de recursos que contém a rede virtual em que sua instância gerenciada é implantada.
Abra o recurso de rede virtual e anote o espaço de endereço.
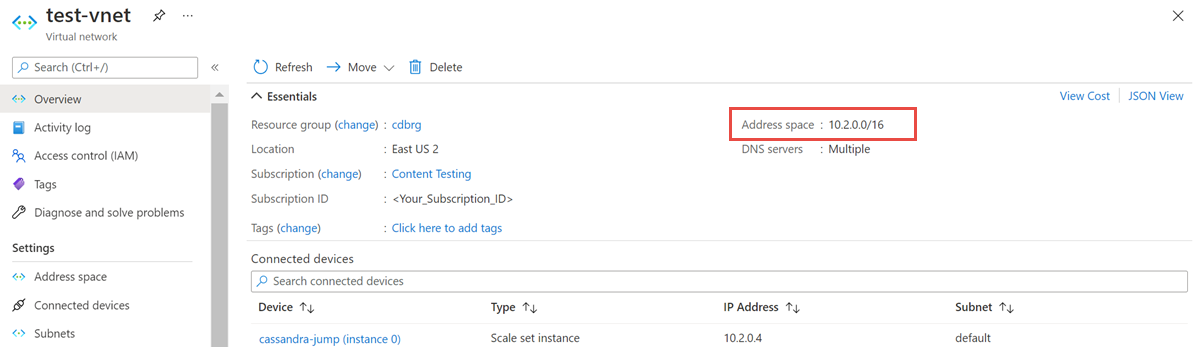
No grupo de recursos, selecione Adicionar e pesquisar o Azure Databricks no campo de pesquisa.
Selecione Criar para criar uma conta do Azure Databricks.
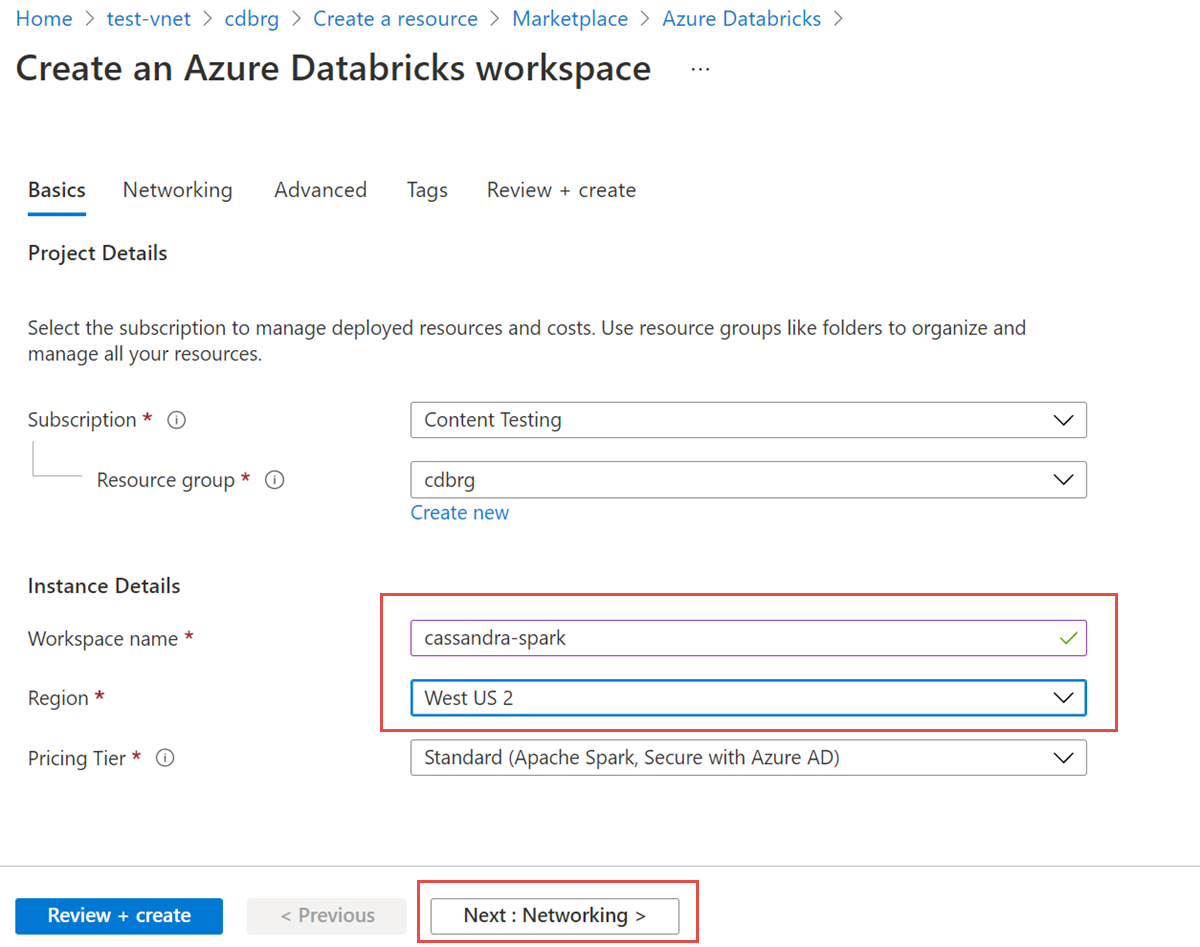
Insira os valores a seguir:
- Nome do workspace: forneça um nome para o workspace do Azure Databricks.
- Região: selecione a mesma região que sua rede virtual.
- Tipo de preço: selecione Standard, Premium ou Avaliação. Para obter mais informações sobre essas camadas, consulte a página de preços do Azure Databricks.
Selecione a guia Rede e insira os seguintes detalhes:
- Implantar o workspace do Azure Databricks em sua VNet (Rede Virtual): selecione Sim.
- Rede Virtual: na lista suspensa, escolha a rede virtual onde sua instância gerenciada está localizada.
- Nome da sub-rede pública: insira um nome para a sub-rede pública.
- Intervalo CIDR de sub-rede pública: insira um intervalo de IP para a sub-rede pública.
- Nome da sub-rede privada: insira um nome para a sub-rede privada.
- Intervalo CIDR de sub-rede privada: insira um intervalo de IP para a sub-rede privada.
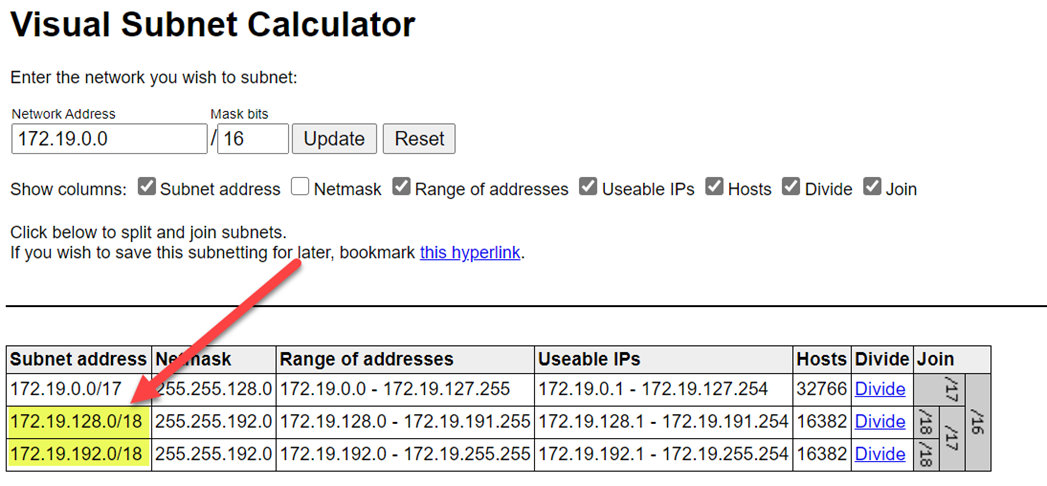
Para evitar colisões de intervalos, selecione intervalos mais altos. Se necessário, use uma calculadora de sub-rede visual para dividir os intervalos.
A captura de tela a seguir mostra detalhes de exemplo no painel de rede.
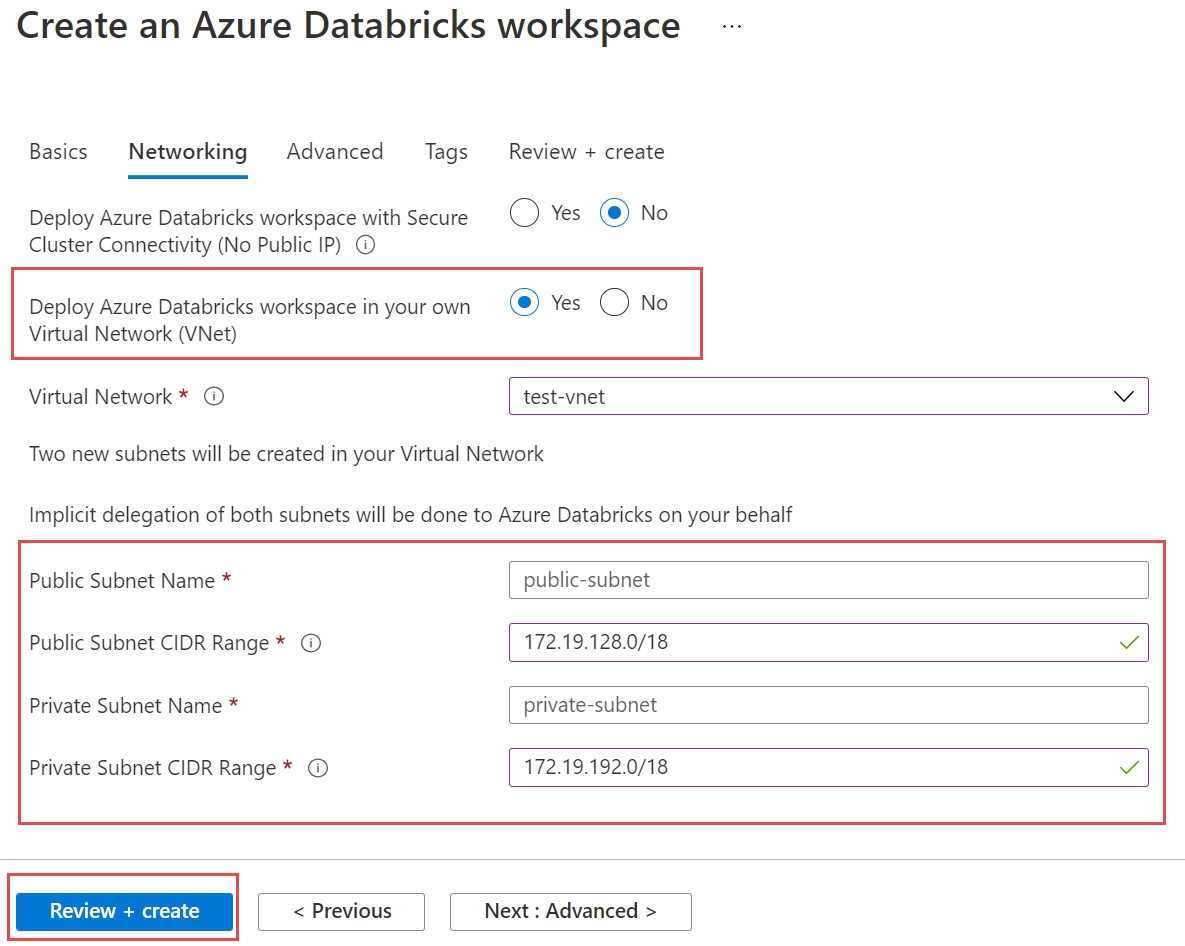
Selecione Examinar + criar e, em seguida, selecione Criar para implantar o workspace.
Abra a área de trabalho depois de ela ser criada.
Você será redirecionado ao portal do Azure Databricks. No portal, selecione Novo Cluster.
No painel Novo cluster , aceite valores padrão para todos os campos diferentes dos seguintes campos:
- Nome do cluster: insira um nome para o cluster.
- Versão do Databricks Runtime: recomendamos que você selecione o runtime do Azure Databricks versão 7.5 ou posterior para o suporte do Spark 3.x.

Expanda Opções Avançadas e adicione a configuração a seguir. Substitua os IPs e as credenciais do nó.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAdicione a biblioteca do Conector do Apache Spark Cassandra ao cluster para se conectar aos pontos de extremidade nativos e do Cassandra do Azure Cosmos DB. Em seu cluster, selecione Bibliotecas>Instalar Novo>Maven e, em seguida, adicione
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0o campo Coordenadas do Maven.
Selecione Instalar.
Limpar os recursos
Se você não quiser continuar a usar esse cluster de instância gerenciada, siga estas etapas para excluí-lo:
- No menu esquerdo do portal do Azure, selecione Grupos de recursos.
- Na lista, selecione o grupo de recursos que você criou para este início rápido.
- Na página Visão geral do grupo de recursos, selecione Excluir grupo de recursos.
- No próximo painel, insira o nome do grupo de recursos a ser excluído e selecione Excluir.
Próxima etapa
Neste início rápido, você aprendeu a criar um cluster Apache Spark totalmente gerenciado dentro da rede virtual do cluster da Instância Gerenciada do Azure para Apache Cassandra. Em seguida, saiba como gerenciar os recursos do cluster e do datacenter.