Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo mostra como usar cargas de trabalho de GPU NVIDIA com o Red Hat OpenShift do Azure.
Pré-requisitos
- OpenShift CLI
- jq, moreutils e pacote gettext
- Red Hat OpenShift 4.10 no Azure
Se você precisar instalar um cluster, consulte Tutorial: Criar um cluster do Red Hat OpenShift 4 do Azure. os clusters devem ser versão 4.10.x ou superior.
Observação
A partir da 4.10, não é mais necessário configurar direitos para usar o Operador NVIDIA. Isso simplificou muito a configuração do cluster para cargas de trabalho de GPU.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Solicitar cota de GPU
Todas as cotas de GPU no Azure são 0 por padrão. Você precisará entrar no portal do Azure e solicitar a cota de GPU. Devido à concorrência para os trabalhadores de GPU, talvez seja necessário provisionar um cluster em uma região em que você possa realmente reservar GPU.
dá suporte aos seguintes processadores GPU:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
As seguintes instâncias também são suportadas em MachineSets adicionais:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Observação
Ao solicitar cota, lembre que o Azure é por núcleo. Para solicitar um único nó NC4as T4 v3, você precisará solicitar cota em grupos de 4. Se você quiser solicitar um NC16as T4 v3, precisará solicitar cota de 16.
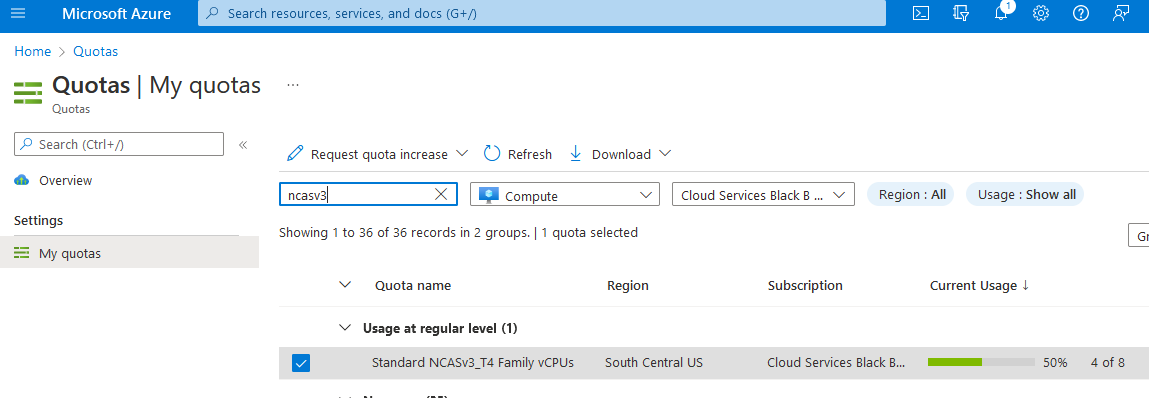
Entre no portal do Azure.
Insira cotas na caixa de pesquisa e selecione Computação.
Na caixa de pesquisa, insira NCAsv3_T4, marque a caixa da região em que seu cluster está e selecione Solicitar aumento de cota.
Configure a cota.
Entre no seu cluster
Entre no OpenShift com uma conta de usuário com privilégios de administrador de cluster. O exemplo a seguir usa uma conta chamada kubadmin:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Segredo de pull (condicional)
Atualize o seu segredo de pull para garantir que você possa instalar operadores e conectar-se ao cloud.redhat.com.
Observação
Ignore esta etapa se você já tiver recriado um segredo de pull completo com cloud.redhat.com habilitado.
Faça logon em cloud.redhat.com.
Navegue até https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Selecione Baixar segredo de pull e salve o segredo de pull como
pull-secret.txt.Importante
As etapas restantes nesta seção devem ser executadas no mesmo diretório de trabalho que
pull-secret.txt.Exporte o segredo de pull existente.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonMescle o segredo de pull baixado com o segredo de pull do sistema a ser adicionado
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonCarregue o novo arquivo de segredo.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonTalvez seja necessário esperar cerca de 1 hora para que tudo seja sincronizado com cloud.redhat.com.
Excluir segredos.
rm pull-secret.txt export-pull.json new-pull-secret.json
Conjunto de computadores de GPU
usa o MachineSet do Kubernetes para criar conjuntos de máquinas. O procedimento a seguir explica como exportar o primeiro conjunto de computadores em um cluster e usá-lo como um modelo para criar um único computador de GPU.
Exibir conjuntos de computadores existentes.
Para facilitar a instalação, este exemplo usa o primeiro conjunto de computadores como o único a ser clonado para criar um novo conjunto de computadores de GPU.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Salve uma cópia do conjunto de computadores de exemplo.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonAltere o campo
.metadata.namepara um novo nome exclusivo.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonVerifique se
spec.replicascorresponde à contagem de réplicas desejada para o conjunto de computadores.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonAltere o campo
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetpara corresponder ao campo.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonAltere
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetpara corresponder ao campo.metadata.name.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonAltere
spec.template.spec.providerSpec.value.vmSizepara corresponder ao tipo de instância de GPU desejado do Azure.O computador usado neste exemplo é Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonAltere
spec.template.spec.providerSpec.value.zonepara corresponder à zona desejada do Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonExclua a seção
.statusdo arquivo yaml.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonVerifique os outros dados no arquivo yaml.
Verifique se o SKU correto está definido
Dependendo da imagem usada para o conjunto de computadores, ambos os valores de image.sku e image.version ser definidos adequadamente. Isso serve para garantir que será utilizada uma máquina virtual da geração 1 ou 2 para o Hyper-V. Veja aqui para obter mais informações.
Exemplo:
Se estiver usando Standard_NC4as_T4_v3, há suporte para ambas as versões. Conforme mencionado no Suporte a recursos. Nesse caso, não é necessária nenhuma alteração.
Se estiver usando Standard_NC24ads_A100_v4, somente a VM de geração 2 terá suporte.
Nesse caso, o valor image.sku deve seguir a versão v2 equivalente da imagem que corresponde ao image.sku original do cluster. Para este exemplo, o valor será v410-v2.
Isso pode ser encontrado usando o seguinte comando:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Se o cluster tiver sido criado com a imagem de SKU aro_410 e o mesmo valor for mantido no conjunto de computadores, ele falhará com o seguinte erro:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Criar conjunto de computadores de GPU
Use as etapas a seguir para criar o novo computador de GPU. Pode levar de 10 a 15 minutos para provisionar um novo computador de GPU. Se essa etapa falhar, entre no portal do Azure e verifique se não há problemas de disponibilidade. Para fazer isso, acesse Máquinas Virtuais e pesquise o nome do trabalho que você criou anteriormente para ver o status das VMs.
Crie o conjunto de computadores de GPU.
oc create -f gpu_machineset.jsonEsse comando vai demorar um pouco para ser concluído.
Verifique o conjunto de computadores de GPU.
Os computadores devem estar sendo implantados. Você pode exibir o status do conjunto de computadores com os seguintes comandos:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiDepois que os computadores forem provisionados (o que pode levar de 5 a 15 minutos), serão exibidos como nós na lista de nós:
oc get nodesVocê deve ver um nó com o nome
nvidia-worker-southcentralus1que foi criado anteriormente.
Instalar o Operador de GPU NVIDIA
Esta seção explica como criar o namespace nvidia-gpu-operator, configurar o grupo de operadores e instalar o operador de GPU NVIDIA.
Crie o namespace NVIDIA.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFCrie o grupo de operadores.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFObtenha o canal de NVIDIA mais recente usando o seguinte comando:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Observação
Se o seu cluster foi criado sem fornecer o segredo de pull, o cluster não incluirá amostras ou operadores da Red Hat ou de parceiros certificados. Isso resultará na seguinte mensagem de erro:
Erro do servidor (NotFound): packagemanifests.packages.operators.coreos.com "gpu-operator-certified" não encontrado.
Para adicionar seu segredo de pull do Red Hat em um cluster Red Hat OpenShift no Azure, siga essa orientação.
Obtenha o pacote NVIDIA mais recente usando o seguinte comando:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Crie a Assinatura.
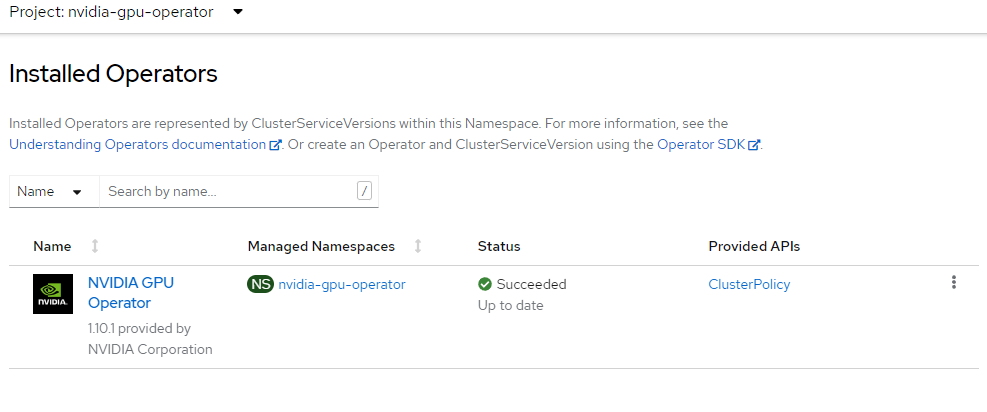
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFAguarde até que o Operador conclua a instalação.
Não prossiga até verificar se o operador terminou a instalação. Além disso, verifique se o trabalho da GPU está online.
Instalar o operador de descoberta de recursos do nó
O operador de descoberta de recursos do nó descobrirá a GPU nos seus nós e rotulará adequadamente os nós para que você possa direcioná-los para cargas de trabalho.
Este exemplo instala o operador NFD no namespace openshift-ndf e cria a "assinatura" que é a configuração do NFD.
Documentação oficial para instalar o Operador de Descoberta de Recursos do Nó.
Configure
Namespace.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFCrie
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFCrie
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFAguarde a conclusão da instalação da descoberta de recursos do nó.
Você pode fazer logon no console do OpenShift para exibir os operadores ou simplesmente aguardar alguns minutos. Não aguardar a instalação do operador resultará em um erro na próxima etapa.
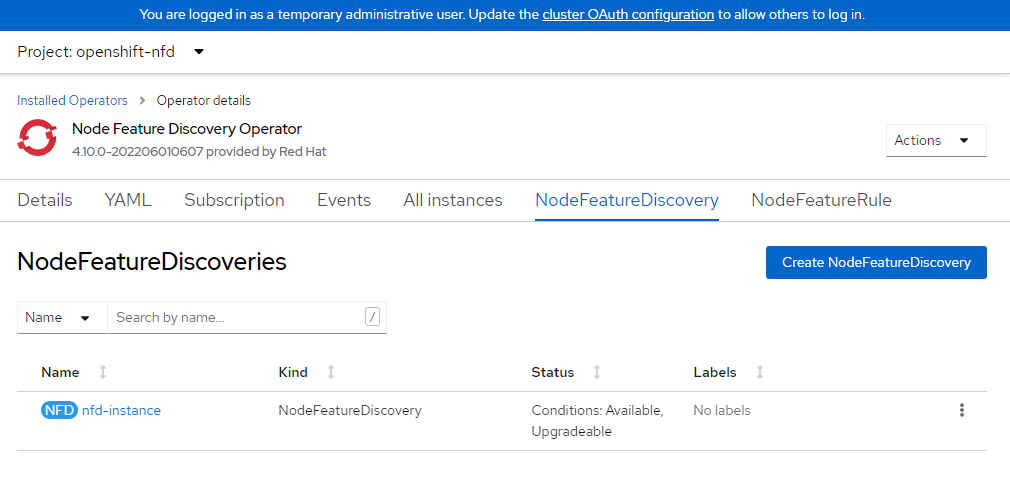
Crie a instância NFD.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFVerifique se o NFD está pronto.
O status desse operador deve ser exibido como Disponível.
Aplicar Configuração do Cluster NVIDIA
Esta seção explica como aplicar a configuração do cluster NVIDIA. Leia a documentação da NVIDIA sobre como personalizar isso se você tiver os seus próprios repositórios privados ou configurações específicas. Esse processo pode levar vários minutos para ser concluído.
Aplique a configuração do cluster.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFVerifique a política do cluster.
Faça logon no console do OpenShift e navegue até os operadores. Verifique se você está no namespace
nvidia-gpu-operator. Esse valor deveria serState: Ready once everything is complete.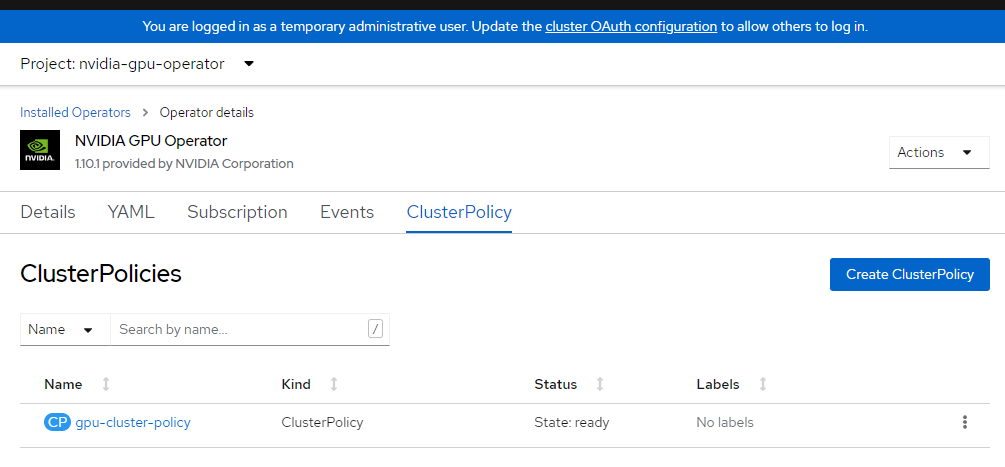
Validar GPU
Pode levar algum tempo para que o Operador NVIDIA e o NFD instalem e autoidentifiquem completamente os computadores. Execute os seguintes comandos para validar se tudo está em execução conforme o esperado:
Verifique se o NFD pode ver as suas GPUs.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterA saída deve ter aparência similar à exibida a seguir:
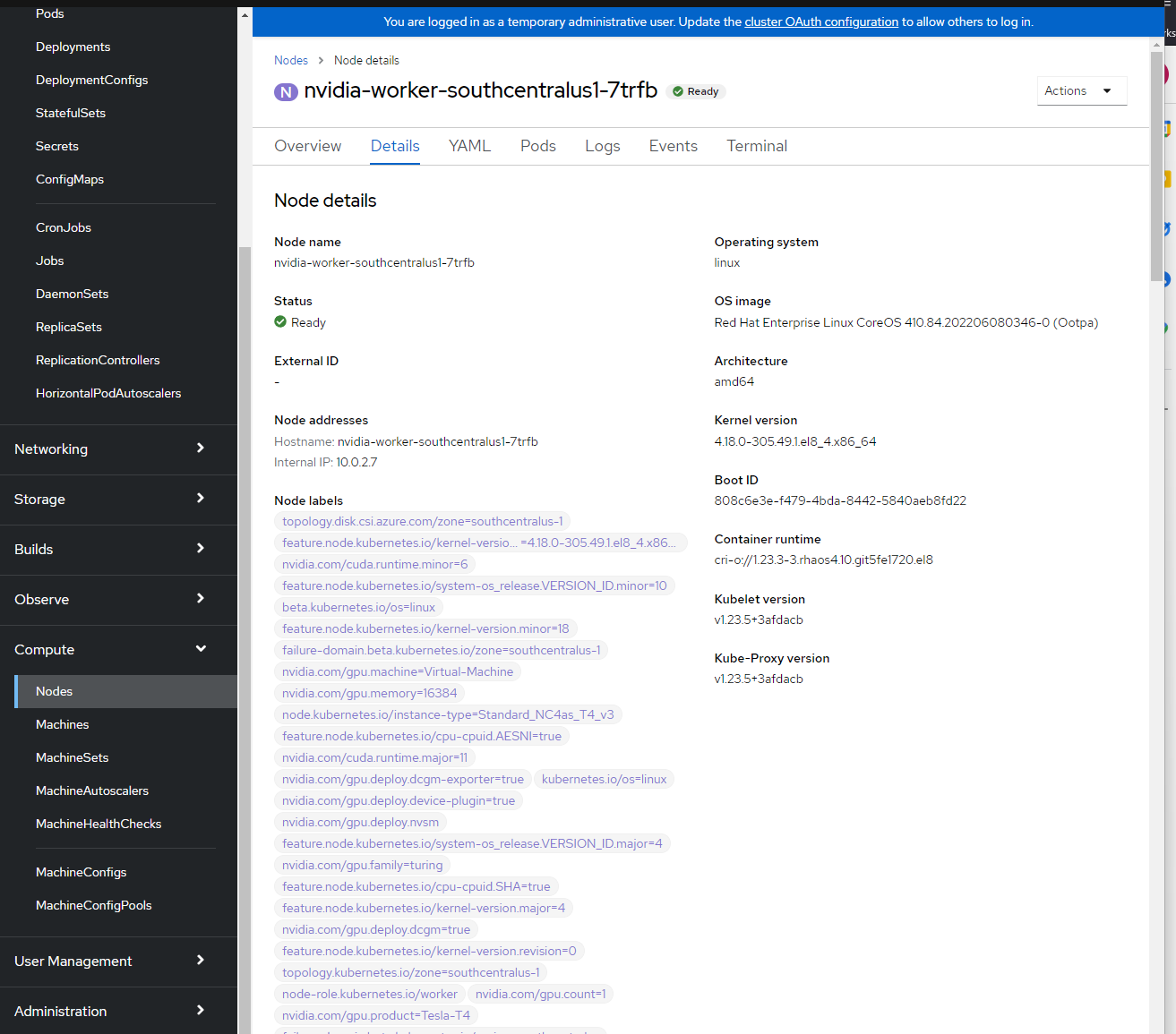
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueVerifique os rótulos do nó.
Você pode ver os rótulos do nó fazendo logon no console do OpenShift –> Computação –> Nós –> nvidia-worker-southcentralus1-. Você deve ver vários rótulos de GPU NVIDIA e o dispositivo pci-10de acima.
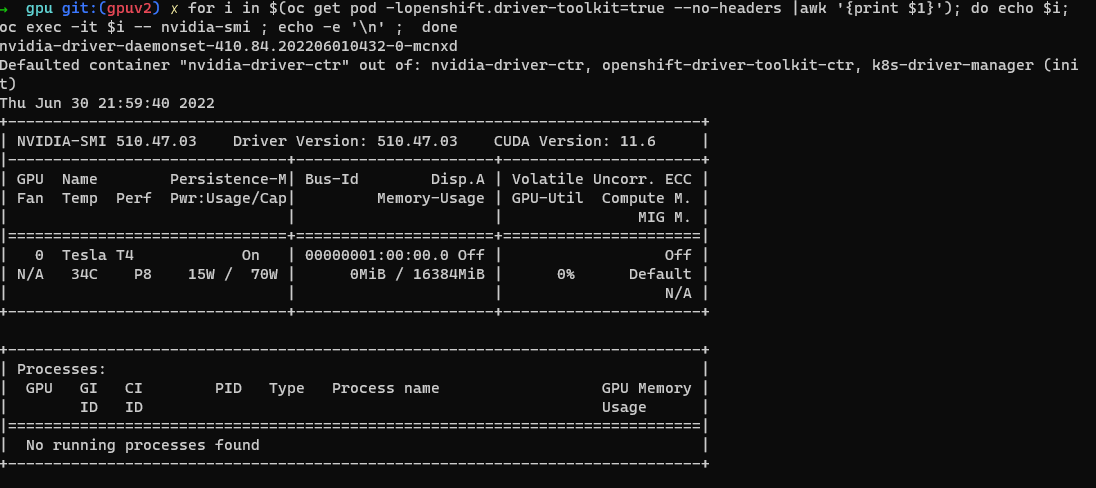
Verificação da ferramenta NVIDIA SMI.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneVocê deverá ver a saída que mostra as GPUs disponíveis no host, como esta captura de tela de exemplo. (Varia dependendo do tipo de trabalho da GPU)
Criar Pod para executar uma carga de trabalho de GPU
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFExiba os logs.
oc logs cuda-vector-add --tail=-1
Observação
Se você receber um erro Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, tente executar oc delete pod cuda-vector-add e execute novamente a instrução create acima.
A saída deve ser semelhante ao exemplo a seguir (dependendo da GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Se tiver êxito, o pod poderá ser excluído:
oc delete pod cuda-vector-add