Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve como implantar um sistema de SAP HANA altamente disponível em uma configuração de expansão. Especificamente, a configuração usa o HSR (replicação de sistema) do HANA e o Pacemaker em VMs (máquinas virtuais) do Red Hat Enterprise Linux no Azure. Os sistemas de arquivos compartilhados na arquitetura apresentada são montados com NFS e fornecidos pelo Azure NetApp Files ou pelo compartilhamento de NFS nos Arquivos do Azure.
Nos comandos de configurações e instalação de exemplo a instância do HANA é 03 e a ID do sistema HANA é HN1.
Pré-requisitos
Alguns leitores se beneficiarão da consultoria de uma variedade de observações e recursos do SAP antes de prosseguir com os tópicos deste artigo:
- A observação do SAP 1928533 inclui:
- Um lista de tamanhos de VM do Azure compatíveis com a implantação do software SAP.
- Informações importantes sobre capacidade para tamanhos de VM do Azure.
- Software SAP e combinações de sistema operacional e banco de dados compatíveis.
- A versão do kernel do SAP necessária para Windows e Linux no Microsoft Azure.
- Observação do SAP 2015553: lista os pré-requisitos para implantações do software SAP com suporte para SAP no Azure.
- Observação do SAP [2002167]: têm as configurações recomendadas do sistema operacional para o RHEL.
- Observação do SAP 2009879: têm as diretrizes do SAP HANA para o RHEL.
- A Observação do SAP 3108302 contém as Diretrizes SAP HANA para o Red Hat Enterprise Linux 9.x.
- Observação do SAP 2178632: contém informações detalhadas sobre todas as métricas de monitoramento relatadas para o SAP no Azure.
- Observação do SAP 2191498: contém a versão necessária do agente de host do SAP para Linux no Azure.
- Observação do SAP 2243692: contém informações sobre o licenciamento do SAP para o Linux no Azure.
- Observação do SAP 1999351: contém informações adicionais sobre a solução de problemas para a extensão de monitoramento avançado do Azure para SAP.
- Observação do SAP 1900823: contém informações sobre os requisitos de armazenamento do SAP HANA.
- Wiki da comunidade do SAP: contém todas as observações do SAP necessárias para Linux.
- Planejamento e implementação de Máquinas Virtuais do Azure para SAP no Linux.
- Implantação de Máquinas Virtuais do Azure para SAP no Linux.
- Implantação de Máquinas Virtuais do Azure do DBMS para SAP no Linux.
- Requisitos de rede do SAP HANA.
- Documentação geral do RHEL:
- Visão geral do complemento de alta disponibilidade.
- Administração do complemento de alta disponibilidade.
- Referência do complemento de alta disponibilidade.
- Guia de rede do Red Hat Enterprise Linux.
- Como fazer para configurar a replicação do sistema de expansão do SAP HANA em um cluster Pacemaker com os sistemas de arquivos do HANA em compartilhamentos NFS.
- Ativo/Ativo (habilitado para leitura): solução de HA RHEL para replicação do sistema e expansão do SAP HANA.
- Documentação do RHEL específica do Azure:
- Documentação do Azure NetApp Files.
- Volumes NFS v4.1 no Azure NetApp Files para SAP HANA.
- Documentação dos Arquivos do Azure
Visão geral
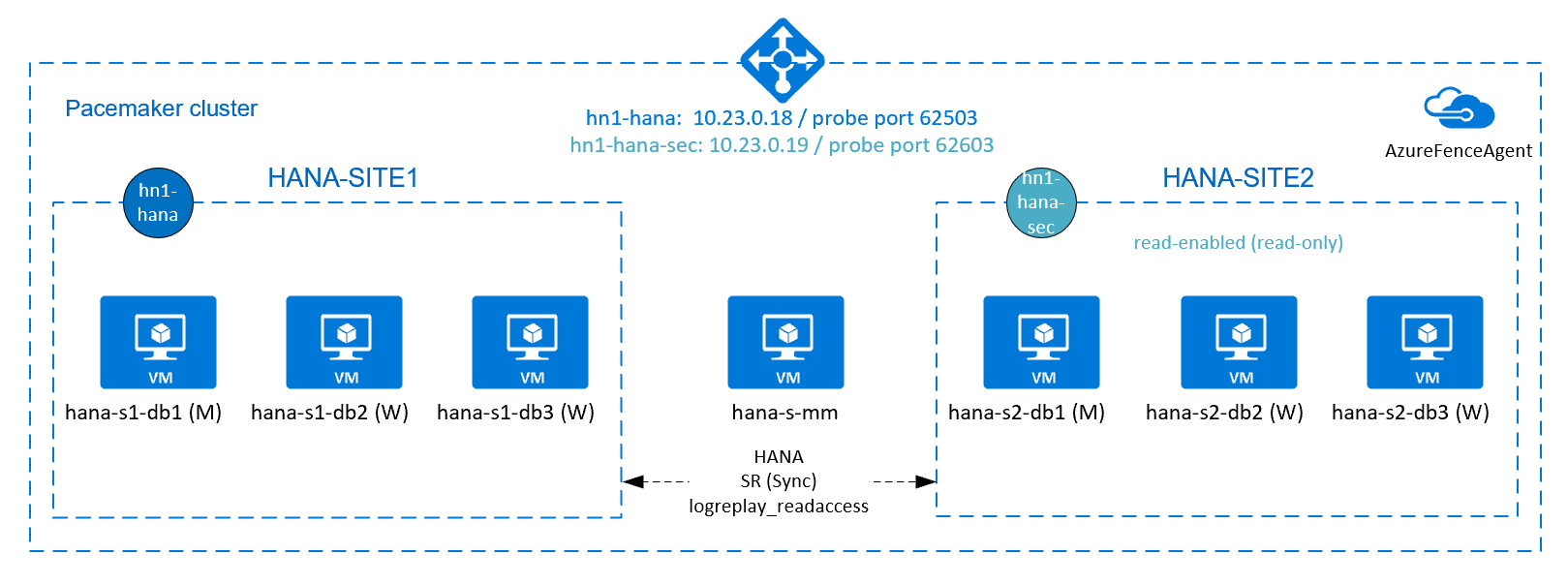
A fim de obter alta disponibilidade do HANA para instalações de expansão do HANA é possível configurar a replicação do sistema HANA e proteger a solução com um cluster Pacemaker para permitir o failover automático. Quando um nó ativo falha, o cluster executa o failover dos recursos do HANA para o outro site.
No diagrama a seguir, há três nós do HANA em cada site e um nó de fabricante principal para evitar um cenário de "dupla personalidade". As instruções podem ser adaptadas para incluir mais VMs como nós de BD do HANA.
O sistema de arquivos compartilhados HANA /hana/shared na arquitetura apresentada pode ser fornecido pelo Azure NetApp Files ou pelo compartilhamento NFS nos Arquivos do Azure. O sistema de arquivos compartilhados do HANA é montado com NFS em cada nó do HANA no mesmo local de replicação do sistema HANA. Os sistemas de arquivos /hana/data e /hana/log são sistemas de arquivos locais e não são compartilhados entre os nós do banco de dados HANA. O SAP HANA será instalado no modo não compartilhado.
Para as configurações de armazenamento SAP HANA recomendadas, consulte Configurações de armazenamento de VMs do Azure no SAP HANA.
Importante
Se estiver implantando todos os sistemas de arquivos do HANA no Azure NetApp Files, para sistemas de produção, onde o desempenho é crucial, recomendamos avaliar e considerar o uso do grupo de volumes de aplicativos do Azure NetApp Files para o SAP HANA.

O diagrama anterior mostra três sub-redes representadas em uma rede virtual do Azure, seguindo as recomendações de rede do SAP HANA:
- Na comunicação com o cliente -
client10.23.0.0/24 - Na comunicação interna entre nós do HANA:
inter10.23.1.128/26 - Na replicação de sistema do HANA:
hsr10.23.1.192/26
Devido a /hana/data e /hana/log serem implantados em discos locais, não é necessário implantar uma sub-rede separada e separar as placas de rede virtual para comunicação com o armazenamento.
Se você estiver usando o Azure NetApp Files, os volumes NFS para /hana/shared serão implantados em uma sub-rede separada, delegada ao Azure NetApp Files: anf 10.23.1.0/26.
Configurar a infraestrutura
Nas instruções a seguir, presumimos que você já criou o grupo de recursos, a rede virtual do Azure com três sub-redes da rede do Azure: clientinter e hsr.
Implantar máquinas virtuais do Linux por meio do portal do Azure
Implantar as VMs do Azure. Nessa configuração, implante sete máquinas virtuais:
- Três máquinas virtuais para servir como nós de BD do HANA para o site 1 da replicação do HANA: hana-s1-db1, hana-s1-db2 e hana-s1-db3.
- Três máquinas virtuais para servir como nós de BD do HANA para o site 2 da replicação do HANA: hana-s2-db1, hana-s2-db2 e hana-s2-db3.
- Uma máquina virtual pequena para servir como fabricante principal: hana-s-mm.
As VMs implantadas como nós do SAP BD HANA, devem ser certificadas pelo SAP para HANA, conforme publicado no Diretório de hardware SAP HANA. Quando implantar os nós de BD do HANA, não deixe de selecionar a rede acelerada.
Para o nó do fabricante principal, você pode implantar uma VM pequena, porque essa VM não executa nenhum dos recursos do SAP HANA. A VM do fabricante principal é usada na configuração do cluster para obter um número ímpar de nós de cluster em um cenário de dupla personalidade. A VM do fabricante principal precisa apenas de uma interface de rede virtual na sub-rede
clientneste exemplo.Implantar discos gerenciados locais para o
/hana/datae o/hana/log. A configuração mínima de armazenamento recomendada para o/hana/datae o/hana/logé descrita em Configurações de armazenamento de VMs SAP HANA do Azure.Implante a interface de rede primária para cada VM na sub-rede da rede virtual
client. Quando a VM é implantada via portal do Azure, o nome da interface de rede é gerado automaticamente. Neste artigo, vamos nos referir às interfaces de rede primária geradas automaticamente como hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-cliente assim por diante. Essas interfaces de rede são anexadas à sub-rede da rede virtual do Azureclient.Importante
Confira se o sistema operacional selecionado conta com a certificação SAP para o SAP HANA para os tipos de VM específicas que você está usando. Para obter uma lista de tipos de VM certificadas do SAP HANA e das versões de sistemas operacionais para esses tipos, confira Plataformas de IaaS certificadas do SAP HANA. Aprofundar-se nos detalhes do tipo de VM listado para obter a lista completa de versões do sistema operacional com suporte do SAP HANA para esse tipo.
Crie seis interfaces de rede, uma para cada máquina virtual do HANA DB, na sub-rede da rede virtual
inter(neste exemplo, hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-intere hana-s2-db3-inter).Crie seis interfaces de rede, uma para cada máquina virtual do HANA DB, na sub-rede da rede virtual
hsr(neste exemplo, hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsre hana-s2-db3-hsr).Anexe as interfaces da rede virtual recém-criadas às máquinas virtuais correspondentes:
- Acesse a máquina virtual no portal do Azure.
- No painel à esquerda, escolha Máquinas Virtuais. Filtre o nome da máquina virtual (por exemplo, hana-s1-db1) e, em seguida, escolha a máquina virtual.
- No painel Visão geral, escolha Parar para desalocar a máquina virtual.
- Escolha Rede e, em seguida, anexe a interface de rede. Na lista suspensa Anexar interface de rede, selecione as interfaces de rede já criadas para as sub-redes
interehsr. - Selecione Salvar.
- Repita as etapas de b até e para as máquinas virtuais restantes (em nosso exemplo, hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 e hana-s2-db3)
- Deixe as máquinas virtuais no estado parado por enquanto.
Habilite a rede acelerada para as interfaces de rede adicionais das sub-redes
interehsrfazendo o seguinte:Abra o Azure Cloud Shell no portal do Azure.
Execute os comandos a seguir para habilitar a rede acelerada para as interfaces de rede adicionais, que estão anexadas às sub-redes
interehsr.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking trueObservação
Você não precisa instalar o pacote da CLI do Azure em seus nós do HANA para executar
azo comando. Você pode executá-lo em qualquer computador que tenha a CLI instalada ou usar o Azure Cloud Shell.
Iniciar as máquinas virtuais do BD HANA.
Configurar o Azure Load Balancer
Durante a configuração da VM, você tem a opção de criar ou selecionar o balanceador de carga existente na seção de rede. Siga as etapas abaixo para configurar o balanceador de carga padrão para a configuração de alta disponibilidade do banco de dados HANA.
Observação
- Para escalar horizontalmente o HANA, selecione a NIC para a sub-rede
clientao adicionar as máquinas virtuais no pool de back-end. - O conjunto completo de comandos na CLI do Azure e no PowerShell adiciona as VMs com NIC primária no pool de back-end.
Siga as etapas em Criar balanceador de carga para configurar um balanceador de carga padrão para um sistema SAP de alta disponibilidade usando o portal do Azure. Durante a configuração do balanceador de carga, considere os seguintes pontos:
- Configuração de IP front-end: Crie um IP front-end. Selecione a mesma rede virtual e nome de sub-rede das máquinas virtuais de banco de dados.
- Pool de back-end: Crie um pool de back-end e adicione VMs de banco de dados.
-
Regras de entrada: Crie uma regra de balanceamento de carga. Siga as mesmas etapas para ambas as regras de balanceamento de carga.
- Endereço IP de front-end: Selecione um IP de front-end.
- Pool de back-end: selecione um pool de back-end.
- Portas de alta disponibilidade: selecione essa opção.
- Protocolo: selecione TCP.
-
Sonda de integridade: crie uma sonda de integridade com os seguintes detalhes:
- Protocolo: selecione TCP.
- Porta: Por exemplo, 625<instância-não.>.
- Intervalo: Inserir 5.
- Limite de investigação: insira 2.
- Tempo limite de inatividade (minutos): Inserir 30.
- Habilitar IP Flutuante: Selecione essa opção.
Observação
A propriedade de configuração da investigação de integridade numberOfProbes, também conhecida como Limite não íntegro no portal, não é respeitada. Para controlar o número de análises consecutivas bem-sucedidas ou com falha, configure a propriedade probeThreshold para 2. No momento, não é possível definir essa propriedade usando o portal do Azure, portanto, use o comando da CLI do Azure ou do PowerShell.
Observação
Você deve estar ciente da limitação a seguir ao usar o balanceador de carga padrão. Ao colocar VMs sem endereços IP públicos no pool de back-end de um balanceador de carga interno, não há conectividade com a Internet de saída. Para permitir o roteamento para pontos de extremidade públicos, você precisa executar configurações adicionais. Para obter mais informações, confira Conectividade de ponto de extremidade público para Máquinas Virtuais usando o Azure Standard Load Balancer em cenários de alta disponibilidade do SAP.
Importante
Não habilite carimbos de data/hora de TCP em VMs do Azure posicionadas de forma subjacente em relação ao Azure Load Balancer. Habilitar carimbos de data/hora de TCP faz as investigações de integridade falharem. Defina o parâmetro net.ipv4.tcp_timestampscomo 0. Para obter detalhes, confira Investigações de integridade do Load Balancer e observação do SAP 2382421.
Implantar o NFS
Há duas opções para implantar o NFS nativo do Azure para /hana/shared. Você pode implantar o volume do NFS no Azure NetApp Files ou no compartilhamento NFS nos Arquivos do Azure. Os arquivos do Azure dão suporte ao protocolo NFSv4.1, os arquivos NFS no Azure NetApp dão suporte ao NFSv4.1 e NFSv3.
As próximas seções descrevem as etapas para implantar o NFS – você precisará selecionar apenas uma das opções.
Dica
Você optou por implantar /hana/shared no compartilhamento NFS nos Arquivos do Azure ou no volume NFS no Azure NetApp Files.
Implantar a infraestrutura do Azure NetApp Files
Implante os volumes do Azure NetApp Files no sistema de arquivos /hana/shared. Você precisa de um volume /hana/shared separado para cada site de replicação do sistema HANA. Para obter mais informações, confira Configurar a infraestrutura do Azure NetApp Files.
Neste exemplo, você usa os seguintes volumes do Azure NetApp Files:
- volume HN1-shared-s1 (nfs://10.23.1.7/ HN1-shared-s1)
- volume HN1-shared-s2 (nfs://10.23.1.7/ HN1-shared-s2)
Implantar o NFS na infraestrutura dos Arquivos do Azure
Implante compartilhamentos NFS dos Arquivos do Azure para o sistema de arquivos /hana/shared. É necessário um compartilhamento NFS dos Arquivos do Azure /hana/shared separado para cada local de replicação do sistema HANA. Para obter mais informações, confira Como criar um compartilhamento NFS.
Neste exemplo, foram usados os seguintes compartilhamentos NFS dos Arquivos do Azure:
- compartilhar hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- compartilhar hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Configuração e preparação do sistema operacional
As instruções das próximas seções têm como prefixo uma das seguintes abreviações:
- [A] : Aplicável a todos os nós
- [AH]: aplicável a todos os nós de BD do HANA
- [M]: aplicável ao nó do fabricante principal
- [AH1]: aplicável a todos os nós de BD do HANA no SITE 1
- [AH2]: aplicável a todos os nós de BD do HANA no SITE 2
- [AH1]: aplicável somente ao nó de BD do HANA 1, SITE 1
- [AH2]: aplicável somente ao nó de BD do HANA 1, SITE 2
Configure e prepare seu sistema operacional fazendo o seguinte:
[A] Mantenha os arquivos do host nas máquinas virtuais. Inclua entradas para todas as sub-redes. As entradas a seguir são adicionadas a
/etc/hostspara este exemplo.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Crie o arquivo de configuração /etc/sysctl.d/ms-az.conf com a Microsoft para as definições de configuração do Azure.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Dica
Evite definir
net.ipv4.ip_local_port_rangeenet.ipv4.ip_local_reserved_portsexplicitamente nos arquivos de configuraçãosysctl, para permitir que o agente de host do SAP gerencie os intervalos de portas. Consulte a observação do SAP 2382421, para obter mais detalhes.[A] instalar o pacote de cliente NFS.
yum install nfs-utils[AH] configuração do Red Hat para HANA.
Configure o RHEL conforme descrito no portal do cliente Red Hat e nas seguintes observações do SAP:
- 2292690 - Banco de dados do SAP HANA: configurações do sistema operacional recomendadas para RHEL 7
- 2777782 - BD do SAP HANA: configurações do sistema operacional recomendadas para o RHEL 8
- 2455582 – Linux: executar aplicativos SAP compilados com GCC 6.x
- 2593824 – Linux: executar aplicativos SAP compilados com GCC 7.x
- 2886607 – Linux: executando aplicativos SAP compilados com GCC 9.x
Preparar os sistemas de arquivos
As seções a seguir fornecem etapas para a preparação de seus sistemas de arquivos. Você optou por implantar '/hana/shared' em um compartilhamento NFS no Arquivos do Azure ou em um volume NFS no Azure NetApp Files.
Montar os sistemas de arquivos compartilhados (NFS do Azure NetApp Files)
Neste exemplo, os sistemas de arquivos compartilhados do HANA são implantados no Azure NetApp Files e montados via NFSv4.1. Siga as etapas desta seção somente se estiver usando NFS no Azure NetApp Files.
[AH] Prepare o sistema operacional para executar o SAP HANA nos sistemas NetApp com o NFS, conforme descrito na nota do SAP 3024346 – Configurações do kernel do Linux para NetApp com o NFS. Crie o arquivo de configuração /etc/sysctl.d/91-NetApp-HANA.conf para as definições de configuração do NetApp.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] Ajuste as configurações de sunrpc, conforme recomendado na nota do SAP 3024346 – Configurações do kernel do Linux para NetApp com o NFS.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Crie pontos de montagem para os volumes de banco de dados do HANA.
mkdir -p /hana/shared[AH] Verifique a configuração do domínio NFS. Verifique se o domínio está configurado como o domínio do Azure NetApp Files padrão:
defaultv4iddomain.com. Confira se o mapeamento está definido comonobody.
(Esta etapa só é necessária se você estiver usando o Azure NetAppFiles NFS v4.1.)Importante
É preciso que você defina o domínio NFS em
/etc/idmapd.confna VM para corresponder à configuração de domínio padrão no Azure NetApp Files:defaultv4iddomain.com. Se houver uma incompatibilidade entre a configuração de domínio no cliente NFS e o servidor NFS, as permissões para arquivos nos volumes do Azure NetApp que forem montados nas VMs serão exibidas comonobody.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Verifique
nfs4_disable_idmapping. Ele deve ser definido comoY. Para criar a estrutura de diretório em quenfs4_disable_idmappingestá localizado, execute o comando mount. Você não poderá criar o diretório manualmente em /sys/modules, pois o acesso é reservado para o kernel ou os drivers.
Esta etapa só é necessária se você estiver usando o Azure NetAppFiles NFSv4.1.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPara obter mais informações sobre como alterar o parâmetro
nfs4_disable_idmapping, consulte o portal do cliente do Red Hat.[AH1] Monte os volumes do Azure NetApp Files compartilhados nas VMs do SITE1 HANA DB.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Monte os volumes do Azure NetApp Files compartilhados nas VMs do SITE2 HANA DB.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Verifique se os sistemas de arquivos correspondentes
/hana/shared/estão montados em todas as VMs do HANA DB com o protocolo NFS versão NFSv4.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
Montar os sistemas de arquivos compartilhados (NFS dos Arquivos do Azure)
Neste exemplo, os sistemas de arquivos compartilhados do HANA são implantados no NFS nos Arquivos do Azure. Siga as etapas desta seção apenas se estiver usando NFS no Arquivos do Azure.
[AH] Crie pontos de montagem para os volumes de banco de dados do HANA.
mkdir -p /hana/shared[AH1] Monte os volumes do Azure NetApp Files compartilhados nas VMs do SITE1 HANA DB.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Monte os volumes do Azure NetApp Files compartilhados nas VMs do SITE2 HANA DB.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Verifique se os sistemas de arquivos
/hana/shared/correspondentes estão montados em todas as VMs do BD HANA com o protocolo NFS versão NFSv4.1.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
Preparar os dados e registrar em log os sistemas de arquivos locais
Na configuração apresentada, você implanta sistemas de arquivos /hana/data e /hana/log em um disco gerenciado e anexa esses sistemas de arquivos localmente a cada VM do BD HANA. Execute as etapas a seguir para criar os volumes de dados e de log locais em cada máquina virtual do HANA DB.
Configure o layout do disco com o LVM (gerenciador de volumes lógicos) . O exemplo a seguir considera que cada máquina virtual HANA tem três discos de dados anexados e que esses discos são usados para criar dois volumes.
[AH] Liste todos os discos disponíveis:
ls /dev/disk/azure/scsi1/lun*Saída de exemplo:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Crie volumes físicos para todos os discos que você deseja usar:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Crie um grupo de volumes para os arquivos de dados. Use um grupo de volumes para os arquivos de log e outro para o diretório compartilhado do SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Crie os volumes lógicos. Um volume linear é criado quando você usar
lvcreatesem a opção-i. Sugerimos que você crie um volume distribuído para melhorar o desempenho de E/S. Alinhe os tamanhos das distribuições aos valores documentados nas configurações de armazenamento de VM do SAP HANA. O argumento-ideve ser o número de volumes físicos subjacentes e o argumento-Ié o tamanho da distribuição. Neste artigo, dois volumes físicos são usados para o volume de dados, portanto, o argumento da chave-ié definido com2. O tamanho da distribuição para o volume de dados é de256 KiB. Um volume físico é usado para o volume do log, portanto, não é necessário usar explicitamente as opções-iou-Ipara os comandos de volume do log.Importante
Use e defina a opção
-ipara o número do volume físico subjacente quando você usar mais de um volume físico para cada volume de dados ou do log. Use a opção-Ipara especificar o tamanho da distribuição na criação de um volume distribuído. Veja Configurações de armazenamento de VM do SAP HANA para ver as configurações de armazenamento recomendadas, incluindo tamanhos de distribuição e número de discos.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Crie os diretórios de montagem e copie o UUID de todos os volumes lógicos:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Crie as entradas
fstabpara os volumes lógicos e monte:sudo vi /etc/fstabInsira a seguinte linha no arquivo
/etc/fstab:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Monte os novos volumes:
sudo mount -a
Instalação
Neste exemplo, para implantar o SAP HANA em uma configuração de expansão com HSR em VMs do Azure, usamos o HANA 2.0 SP4.
Preparar para a instalação do HANA
[AH] Antes da instalação do HANA, defina a senha raiz. Você pode desabilitar a senha raiz após a conclusão da instalação. Execute como comando
rootpara definir a senhapasswd.[1,2] Alterar as permissões em
/hana/shared.chmod 775 /hana/shared[1] Confira se você pode entrar em hana-s1-db2 e hana-s1-db3 por meio do SSH (secure shell), sem precisar fornecer uma senha. Se esse não for o caso, troque chaves
ssh, conforme documentado em Usando a autenticação baseada em chave.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Confira se você pode entrar em hana-s2-db2 e hana-s2-db3 por meio do SSH, sem precisar fornecer uma senha. Se esse não for o caso, troque chaves
ssh, conforme documentado em Usando a autenticação baseada em chave.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Instale os pacotes adicionais que são necessários para o HANA 2.0 SP4. Para saber mais, confira a Nota SAP 2593824 para RHEL 7.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Desabilite o firewall temporariamente, para que ele não interfira na instalação do HANA. Você pode habilitá-lo novamente após a conclusão da instalação do HANA.
# Execute as root systemctl stop firewalld systemctl disable firewalld
Instalação do HANA no primeiro nó de cada site
[1] Instale o SAP HANA seguindo as instruções no Guia de instalação e atualização do SAP HANA 2.0. As instruções a seguir mostram a instalação do SAP HANA no primeiro nó do SITE 1.
Inicie o programa
hdblcmcomorootdo diretório de software de instalação do HANA. Use o parâmetrointernal_networke passe o espaço de endereço para a sub-rede que é usada para a comunicação entre nós do HANA../hdblcm --internal_network=10.23.1.128/26No prompt, insira os valores a seguir:
- Em Escolher uma ação, insira 1 (para instalar).
- Em Componentes adicionais para a instalação: insira 2, 3.
- Em caminho de instalação: pressione ENTER (o padrão é /hana/shared).
- Em Nome do Host Local, pressione ENTER para aceitar o padrão.
- Em Você deseja adicionar outros hosts ao sistema? , insira n.
- Em ID do Sistema do SAP HANA, insira HN1.
- Em Número de instância [00], insira 03.
- Em Grupo de Trabalho do Host Local [padrão], pressione ENTER para aceitar o padrão.
- Em Selecionar Uso do Sistema / Inserir Índice [4] , insira 4 (personalizado).
- Em Local dos Volumes de Dados [/hana/data/HN1], pressione ENTER para aceitar o padrão.
- Em Local dos Volumes do Log [/hana/log/HN1], pressione ENTER para aceitar o padrão.
- Em Restringir a alocação máxima de memória? [n]: insira n.
- Em Nome do Host do Certificado Para o Host hana-s1-db1 [hana-s1-db1], pressione ENTER para aceitar o padrão.
- Em Senha de Usuário do Agente Host SAP (sapadm) , insira a senha.
- Em Confirmar a Senha de Usuário do Agente Host SAP (sapadm) , insira a senha.
- Em Senha do Administrador do Sistema (hn1adm) , insira a senha.
- Em Diretório Base do Administrador do Sistema [/usr/SAP/HN1/Home], pressione ENTER para aceitar o padrão.
- Em Shell de Logon do Administrador do Sistema [/bin/sh], pressione ENTER para aceitar o padrão.
- Em ID de Usuário do Administrador do Sistema [1001], pressione ENTER para aceitar o padrão.
- Em Inserir ID do Grupo de Usuários (sapsys) [79], pressione ENTER para aceitar o padrão.
- Em Senha do Usuário do Banco de Dados do Sistema (sistema) , insira a senha do sistema.
- Em Confirmar Senha do Usuário do Banco de Dados do Sistema (sistema) , insira a senha do sistema.
- Em Reiniciar o sistema após a reinicialização do computador? [n], insira n.
- Em Você deseja continuar (s/n) : valide o resumo e, se tudo estiver correto, inserir s.
[2] Repita a etapa anterior para instalar o SAP HANA no primeiro nó no SITE 2.
[1,2] Verifique o global.ini.
Exiba global.ini e verifique se a configuração da comunicação interna entre nós do SAP HANA está funcionando. Verificar a seção
communication. Ele deve ter o espaço de endereço para a sub-redeinterelisteninterfacedeve ser definido como.internal. Verificar a seçãointernal_hostname_resolution. Ele deve ter os endereços IP para as máquinas virtuais HANA que pertencem à sub-redeinter.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] Prepare global.ini para a instalação em um ambiente não compartilhado, conforme descrito na observação do SAP 2080991.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Reinicie o SAP HANA para ativar as alterações.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] Verifique se a interface do cliente usa os endereços IP da sub-rede
clientpara comunicação.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Para obter informações sobre como verificar a configuração, consulte a observação do SAP 2183363 - configuração de rede interna do SAP HANA.
[AH] Altere as permissões nos diretórios de dados e de log para evitar um erro de instalação do HANA.
sudo chmod o+w -R /hana/data /hana/log[1] Instale os nós do HANA secundários. As instruções de exemplo nesta etapa são para o SITE 1.
Inicie o programa
hdblcmresidente comoroot.cd /hana/shared/HN1/hdblcm ./hdblcmNo prompt, insira os valores a seguir:
- Em Escolher uma ação, insira 2 (para adicionar hosts).
- Em Inserir nomes de host separados por vírgula para adicionar, insira hana-s1-db2, hana-s1-db3.
- Em Componentes adicionais para a instalação: insira 2, 3.
- Em Inserir Nome do Usuário Raiz [root] , pressione ENTER para aceitar o padrão.
- Em Selecionar funções para o host 'hana-s1-db2' [1] , selecione 1 (para o trabalho).
- Em Inserir Grupo de Failover para o host 'hana-s1-db2' [padrão] , pressione ENTER para aceitar o padrão.
- Em Inserir o número da partição de armazenamento do host 'hana-s1-db2' [<<atribuir automaticamente>>], pressione Enter para aceitar o padrão.
- Em Inserir Grupo de Trabalho para o host 'hana-s1-db2' [padrão] , pressione ENTER para aceitar o padrão.
- Em Selecionar funções para o host 'hana-s1-db3' [1] , selecione 1 (para o trabalho).
- Em Inserir Grupo de Failover para o host 'hana-s1-db3' [padrão] , pressione ENTER para aceitar o padrão.
- Em Inserir o Número de Partição de Armazenamento do host 'hana-s1-db3' [<<atribuir automaticamente>>], pressione Enter para aceitar o padrão.
- Em Inserir Grupo de Trabalho para o host 'hana-s1-db3' [padrão] , pressione ENTER para aceitar o padrão.
- Em Senha do Administrador do Sistema (hn1adm) , insira a senha.
- Em Inserir Senha de Usuário do Agente Host SAP (sapadm) , insira a senha.
- Em Confirmar a Senha de Usuário do Agente Host SAP (sapadm) , insira a senha.
- Em Nome do Host do Certificado Para o Host hana-s1-db2 [hana-s1-db2], pressione ENTER para aceitar o padrão.
- Em Nome do Host do Certificado Para o Host hana-s1-db3 [hana-s1-db3], pressione ENTER para aceitar o padrão.
- Em Você deseja continuar (s/n) : valide o resumo e, se tudo estiver correto, inserir s.
[2] Repita a etapa anterior para instalar os nós de SAP HANA secundários no SITE 2.
Configurar a replicação do sistema SAP HANA 2.0
As etapas a seguir o ajudarão a configurar a replicação do sistema:
[1] Configurar a replicação do sistema no SITE 1:
Faça backup dos bancos de dados como hn1adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Observação
Ao usar o LSS (Repositório Seguro Local), os backups do SAP HANA são independentes e exigem que você defina uma senha de backup para as chaves raiz de criptografia. Consulte a nota do SAP 3571561 para obter instruções detalhadas. A senha deve ser definida para SYSTEMDB e banco de dados de locatário individual.
Copie os arquivos PKI do sistema para o site secundário:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Crie o site primário:
hdbnsutil -sr_enable --name=HANA_S1[2] Configurar a replicação do sistema no SITE 2:
Registre o segundo site para iniciar a replicação do sistema. Execute o seguinte comando como <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Verifique o status de replicação e aguarde até que todos os bancos de dados estão em sincronia.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Altere a configuração do HANA para que a comunicação para a replicação do sistema HANA é direcionada por meio das interfaces da rede virtual de replicação do sistema HANA.
Parar o HANA em ambos os sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBEditar o global.ini para adicionar o mapeamento de host para replicação de sistema HANA. Usar os endereços IP da sub-rede
hsr.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Iniciar o HANA em ambos os sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Para obter mais informações, confira Resolução de nome do host para replicação do sistema.
[AH] Habilite novamente o firewall e abra as portas necessárias.
Habilitar novamente o firewall.
# Execute as root systemctl start firewalld systemctl enable firewalldAbra as portas de firewall necessárias. Você precisará ajustar as portas para o seu número de instância do HANA.
Importante
Crie regras de firewall para permitir a comunicação entre nós do HANA e o tráfego do cliente. As portas necessárias estão listadas em Portas TCP/IP de todos os produtos SAP. Os comandos a seguir são apenas exemplos. Você usa o número 03 do sistema, nesse cenário.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Criar um cluster do Pacemaker
Para criar um cluster básico do Pacemaker, siga as etapas em Configuração do Pacemaker no Red Hat Enterprise Linux no Azure. Inclua todas as máquinas virtuais, incluindo o fabricante principal no cluster.
Importante
Não definir quorum expected-votes como 2. Esse não é um cluster de dois nós. Verifique se a propriedade de cluster concurrent-fencing está habilitada, assim o isolamento de nó é desserializado.
Criar os recursos do sistema de arquivos
Para a próxima parte desse processo, você precisa criar recursos do sistema de arquivos. Este é o procedimento:
[1,2] Parar o SAP HANA em ambos os sites de replicação. Executar como <sid>adm.
sapcontrol -nr 03 -function StopSystem[AH] Desmonte o sistema de arquivos
/hana/shared, que foi montado temporariamente para a instalação em todas as VMs do BD HANA. Antes de poder desmontá-lo, você precisa interromper todos os processos e as sessões que estão usando o sistema de arquivos.umount /hana/shared[1] Crie os recursos de cluster do sistema de arquivos para
/hana/sharedno estado desabilitado. Você usa--disabledporque precisa definir as restrições de local, antes que as montagens sejam habilitadas.
Você optou por implantar '/hana/shared' em um compartilhamento NFS no Arquivos do Azure ou em um volume NFS no Azure NetApp Files.Neste exemplo, o sistema de arquivos '/hana/shared' é implantado no Azure NetApp Files e montado sobre NFSv4.1. Siga as etapas desta seção somente se estiver usando NFS no Azure NetApp Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
Os valores de tempo limite sugeridos permitem que os recursos do cluster resistam a pausas específicas do protocolo, relacionadas à renovação de concessões NFSv4.1 no Azure NetApp Files. Para obter mais informações, confira Prática recomendada do NFS no NetApp.
Neste exemplo, o sistema de arquivos '/hana/shared' é implantado no NFS nos Arquivos do Azure. Siga as etapas desta seção apenas se estiver usando NFS no Arquivos do Azure.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueO atributo
OCF_CHECK_LEVEL=20é adicionado à operação de monitoramento, para que as operações de monitoramento realizem um teste de leitura/gravação no sistema de arquivos. Sem esse atributo, a operação de monitoramento só verifica se o sistema de arquivos está montado. Isso pode ser um problema pois, quando a conectividade é perdida, o sistema de arquivos pode permanecer montado, apesar de estar inacessível.O atributo
on-fail=fencetambém é adicionado à operação de monitoramento. Com essa opção, se a operação de monitoramento falhar em um nó, esse nó será imediatamente isolado. Sem essa opção, o comportamento padrão é parar todos os recursos que dependem do recurso com falha, reiniciar o recurso com falha e, em seguida, iniciar todos os recursos que dependem do recurso com falha. Esse comportamento não só pode levar muito tempo quando um recurso SAP HANA depende do recurso com falha, mas também pode falhar completamente. O recurso SAP HANA não pode parar com êxito, se o compartilhamento NFS que contém os binários HANA estiver inacessível.Os tempos limite nas configurações acima podem precisar ser adaptados à configuração específica do SAP.
[1] Configurar e verificar os atributos do nó. Todos os nós do banco de dados do SAP HANA no site 1 de replicação recebem o atributo
S1e todos os nós do banco de dados do SAP HANA no site 2 de replicação recebem ao atributoS2.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Configurar as restrições, que determinam onde os sistemas de arquivos NFS serão montados e habilitam os recursos do sistema de arquivos.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Quando você habilitar os recursos do sistema de arquivos, o cluster montará os sistemas de arquivos
/hana/shared.[AH] Verifique se os volumes do Azure NetApp Files estão montados no
/hana/sharedem todas as VMs do BD HANA em ambos os sites.Exemplo, se estiver usando o Azure NetApp Files:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Exemplo, se estiver usando o NFS do Arquivos do Azure:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Configure e clone os recursos de atributo e configure as restrições, conforme a seguir:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneDica
Se sua configuração inclui sistemas de arquivos diferentes de /
hana/sharede esses sistemas de arquivos são montados em NFS inclua a opçãosequential=false. Essa opção garante que não exista nenhuma dependência de ordenação entre os sistemas de arquivos. Todos os sistemas de arquivos montados em NFS devem iniciar antes do recurso de atributo correspondente, mas eles não precisam iniciar em nenhuma ordem em relação ao outro. Para obter mais informações, consulte Como fazer para configurar a expansão da HSR do SAP HANA em um cluster do Pacemaker quando os sistemas de arquivos do HANA forem compartilhamentos NFS.[1] Coloque o Pacemaker no modo de manutenção, em preparo para a criação dos recursos de cluster do HANA.
pcs property set maintenance-mode=true
Crie os recursos de cluster do SAP HANA
Agora você está pronto para criar os recursos de cluster:
[A] Instalar o agente de recursos de expansão do HANA em todos os nós de cluster, incluindo o fabricante principal.
yum install -y resource-agents-sap-hana-scaleoutObservação
A fim de saber a versão mínima do pacote
resource-agents-sap-hana-scaleoutpara a versão do seu sistema operacional, consulte Políticas de suporte para clusters de HA do RHEL - gerenciamento do SAP HANA em um cluster.[1,2] Configure o gancho de replicação do sistema do HANA em um nó do BD HANA em cada site de replicação do sistema. O SAP HANA ainda deve estar inoperante.
resource-agents-sap-hana-scaleoutversão 0.185.3-0 ou mais recente inclui os ganchos SAPHanaSR e ChkSrv. É obrigatório para a operação correta do cluster habilitar o gancho SAPHanaSR. É altamente recomendável que você configure ambos os ganchos Python SAPHanaSR e ChkSrv.Ajustar
global.ini.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR-ScaleOut execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR-ScaleOut execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Se você apontar o parâmetro
pathpara a localização padrão/usr/share/SAPHanaSR-ScaleOut, o código do gancho Python será atualizado automaticamente por meio de atualizações do SO. O HANA usará as atualizações de código de gancho quando for reiniciado na próxima vez. Com um caminho próprio opcional como/hana/shared/myHooks, você pode desacoplar as atualizações do SO da versão do gancho que o HANA vai usar.Você pode ajustar o comportamento do gancho
ChkSrvusando o parâmetroaction_on_lost. Os valores válidos são: [ignore|stop|kill].Para obter mais informações sobre a implementação dos ganchos do SAP HANA, confira Habilitando o gancho SAP HANA srConnectionChanged() e Habilitando o gancho SAP HANA srServiceStateChanged() para ação de falha do processo hdbindexserver (opcional).
[AH] O cluster requer configuração de sudoers no nó de cluster para <sid>adm. Você consegue fazer isso criando um novo arquivo, neste exemplo. Execute os comandos como
root.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SRREBOOT = /usr/sbin/crm_attribute -n hana_hn1_gsh -v * -l reboot -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL, SRREBOOT Defaults!SOK, SFAIL, SRREBOOT !requiretty[1,2] Iniciar o SAP HANA em ambos os sites de replicação. Executar como <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Verifique a instalação do gancho. Executar como <sid>adm no site de replicação do sistema do HANA ativo.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Verifique a instalação do gancho ChkSrv. Executar como <sid>adm no site de replicação do sistema do HANA ativo.
cdtrace tail -20 nameserver_chksrv.trc[1] Crie os recursos de cluster do HANA. Executar os comandos a seguir como
root.Confira se o cluster já está no modo de manutenção.
Em seguida, crie o recurso de topologia do HANA.
Se você estiver criando um cluster de RHEL 7.x, use os seguintes comandos:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueSe estiver criando um cluster RHEL >= 8.x, use os seguintes comandos:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueCrie o recurso de instância do HANA.
Observação
Este artigo contém referências a um termo que a Microsoft não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Se você estiver criando um cluster de RHEL 7.x, use os seguintes comandos:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueSe estiver criando um cluster RHEL >= 8.x, use os seguintes comandos:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueImportante
É uma boa ideia definir
AUTOMATED_REGISTERcomofalse, enquanto você está executando testes de failover, para impedir que uma instância primária com falha seja registrada automaticamente como secundária. Após o teste, como uma melhor prática, definaAUTOMATED_REGISTERcomotruepara que após a tomada de controle, a replicação do sistema possa ser retomada automaticamente.Criar o IP virtual e os recursos associados.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Criar as restrições de cluster.
Se você estiver criando um cluster de RHEL 7.x, use os seguintes comandos:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueSe estiver criando um cluster RHEL >= 8.x, use os seguintes comandos:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Retire o cluster do modo de manutenção. Verifique se o status do cluster é
oke se todos os recursos foram iniciados.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupObservação
Os tempos limite na configuração anterior são apenas exemplos e podem ser adaptados à configuração específica do HANA. Por exemplo, talvez seja necessário aumentar o tempo limite de início, se o banco de dados do SAP HANA demorar mais para iniciar.
Configurar a replicação de sistema ativa/habilitada para leitura do HANA
A partir do SAP HANA 2.0 SPS 01, o SAP permite configurações ativas/habilitadas para leitura para replicação do sistema SAP HANA. Você pode usar os sistemas secundários da replicação de sistema SAP HANA ativamente para cargas de trabalho com uso intensivo de leitura usando essa funcionalidade. Para dar suporte uma configuração dessas em um cluster é necessário um segundo endereço IP virtual. Isso permite que os clientes acessem o banco de dados secundário do SAP HANA habilitado para leitura. Para garantir que o site de replicação secundária ainda possa ser acessado após uma tomada de controle, o cluster precisa mover o endereço IP virtual com o secundário do recurso SAP HANA.
Esta seção descreve as etapas adicionais que você deve seguir para gerenciar esse tipo de replicação do sistema em um cluster de alta disponibilidade do Red Hat, com um segundo endereço IP virtual.
Antes de continuar, verifique se você configurou totalmente o cluster de alta disponibilidade do Red Hat gerenciando o banco de dados do SAP HANA conforme descrito acima neste artigo.
Configuração adicional no Azure Load Balancer para configuração ativa/habilitada para leitura
Para prosseguir com o provisionamento do seu segundo IP virtual, certifique-se de ter configurado o Azure Load Balancer conforme descrito em Configurar o Azure Load Balancer.
Para o balanceador de carga padrão, siga estas etapas adicionais no mesmo balanceador de carga que você criou na seção anterior.
Crie um segundo pool de IPs de front-end:
- Abra o balanceador de carga, selecione pool de front-end e selecione Adicionar.
- Insira o nome do segundo pool de IPs de front-end (por exemplo, hana-secondaryIP).
- Defina a Atribuição como Estática e insira o endereço IP (por exemplo, 10.23.0.19).
- Selecione OK.
- Depois que o novo pool de IP de front-end for criado, anote o endereço IP do pool.
Em seguida, crie uma investigação de integridade:
- Abra o balanceador de carga, selecione investigações de integridade e selecione Adicionar.
- Insira o nome da nova investigação de integridade (por exemplo, hana-secondaryhp).
- Selecione TCP como o protocolo e a porta 62603. Mantenha o valor do Intervalo como 5 e o valor Limite não íntegro como 2.
- Selecione OK.
Em seguida, crie as regras de balanceamento de carga:
- Abra o balanceador de carga, selecione Regras de balanceamento de carga e selecione Adicionar.
- Insira o nome da nova regra do balanceador de carga (por exemplo hana-secondarylb).
- Selecione o endereço IP de front-end, o pool de back-end e a investigação de integridade que você criou anteriormente (por exemplo, hana-secondaryIP, hana-backend e hana-secondaryhp).
- Selecione Portas de HA.
- Certifique-se de habilitar IP Flutuante.
- Selecione OK.
Configurar a replicação de sistema ativa/habilitada para leitura do HANA
As etapas para configurar a replicação do sistema HANA são descritas na seção Configurar a replicação do sistema SAP HANA 2.0. Se você estiver implantando um cenário secundário habilitado para leitura durante a configuração da replicação do sistema no segundo nó, execute o seguinte comando como hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Adicionar um recurso de endereço IP virtual secundário para uma configuração ativa/habilitada para leitura
Você pode configurar o segundo IP virtual e as restrições adicionais com os comandos a seguir. Se a instância secundária estiver inativa, o IP virtual secundário será alternado para o primário.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Verifique se o status do cluster é ok e se todos os recursos foram iniciados. O segundo IP virtual será executado no site secundário com o recurso secundário SAP HANA.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
Na próxima seção, você pode encontrar o conjunto típico de testes de failover para executar.
Ao testar um cluster HANA configurado com um secundário habilitado para leitura, fique atento ao seguinte comportamento do segundo IP virtual:
Quando o recurso de cluster SAPHana_HN1_HDB03 se move para o site secundário (S2), o segundo IP virtual será movido para o outro site, ou seja, para hana-s1-db1. Se você configurou
AUTOMATED_REGISTER="false"e a replicação do sistema HANA não foi registrada automaticamente, o segundo IP virtual será executado em hana-s2-db1.Quando você está testando uma falha do servidor, os recursos do segundo IP virtual (secvip_HN1_03) e o recurso de porta do Azure Load Balancer (secnc_HN1_03) executam no servidor primário com os recursos de IP virtual primários. Enquanto o servidor secundário está inativo, os aplicativos que estão conectados ao banco de dados HANA habilitado para leitura vão se conectar ao banco de dados HANA primário. O comportamento é esperado. Isso permite que os aplicativos que estão conectados ao banco de dados HANA habilitado para leitura funcionem enquanto um servidor secundário está indisponível.
Durante o failover e o fallback, as conexões existentes para aplicativos que estão usando o segundo IP virtual para se conectar ao banco de dados do HANA podem ser interrompidas.
Testar failover do SAP HANA
Antes de iniciar um teste, verifique o cluster e o status de replicação do sistema SAP HANA.
Verifique se não há nenhuma ação de cluster com falha.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Verifique se a replicação do sistema SAP HANA está em sincronia.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Verifique a configuração do cluster para um cenário de falha, quando um nó perde o acesso ao compartilhamento NFS (
/hana/shared).Os agentes de recurso do SAP HANA dependem de binários, armazenados em
/hana/sharedpara executar operações durante o failover. O sistema de arquivos/hana/sharedé montado em NFS na configuração apresentada. Um teste executável é criar uma regra de firewall temporária para bloquear o acesso ao sistema de arquivos montado com NFS/hana/sharedem uma das VMs do site primário. Esse método valida se o cluster fará o failover, caso o acesso a/hana/sharedfor perdido no site de replicação do sistema ativo.Resultado esperado: quando você bloqueia o acesso ao sistema de arquivos montado com NFS
/hana/sharedem uma das VMs do site primário, a operação de monitoramento que executa a operação de leitura/gravação no sistema de arquivos falhará, pois não poderá acessar o sistema de arquivos e disparará o failover do recurso HANA. O mesmo resultado é esperado quando o nó do HANA perde o acesso ao compartilhamento NFS.Você pode verificar o estado dos recursos de cluster ao executar
crm_monoupcs status. Estado do recurso antes de iniciar o teste:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Para simular falha para
/hana/shared:- Se estiver usando NFS em ANF, confirme primeiro o endereço IP do volume ANF
/hana/sharedno site primário. Você pode fazer ao executardf -kh|grep /hana/shared. - Se estiver usando o NFS nos Arquivos do Azure, primeiro determine o endereço IP do ponto de extremidade privado para a sua conta de armazenamento.
Em seguida, configure uma regra de firewall temporária para bloquear o acesso ao endereço IP do sistema de arquivos NFS
/hana/sharedexecutando o comando a seguir em uma das VMs do site primário de replicação do sistema HANA.Neste exemplo, o comando foi executado em hana-s1-db1 para o volume ANF
/hana/shared.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPA VM do HANA que perdeu o acesso a
/hana/shared, deve ser reiniciada ou interrompida, dependendo da configuração do cluster. Os recursos de cluster são migrados para outro site de replicação do sistema do HANA.Se o cluster não tiver iniciado na VM que foi reiniciada, inicie o cluster executando o seguinte:
# Start the cluster pcs cluster startO sistema de arquivos
/hana/sharedé montado automaticamente quando o cluster inicia. Se você definirAUTOMATED_REGISTER="false", será necessário configurar a replicação de sistema SAP HANA no site secundário. Nesse caso, você pode executar esses comandos para reconfigurar o SAP HANA como secundário.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03O estado dos recursos, após o teste:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Se estiver usando NFS em ANF, confirme primeiro o endereço IP do volume ANF
Uma boa ideia é testar a configuração de cluster SAP HANA exaustivamente, executando também os testes documentados em HA para SAP HANA em VMs do Azure na RHEL.
Próximas etapas
- Planejamento e implementação de Máquinas Virtuais do Azure para o SAP
- Implantação de Máquinas Virtuais do Azure para SAP
- Implantação do DBMS de Máquinas Virtuais do Azure para SAP
- Volumes NFS v4.1 no Azure NetApp Files para SAP HANA
- Para saber como estabelecer a alta disponibilidade e o plano de recuperação de desastre do SAP HANA em VMs do Azure, consulte Alta disponibilidade do SAP HANA em VMs do Azure.