Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste início rápido, você usa o assistente de importação e vetorização de dados no portal do Azure para começar a usar a vetorização integrada. O assistente agrupa seu conteúdo e chama um modelo de inserção para vetorizar as partes em tempo de indexação e consulta.
Este início rápido usa PDFs baseados em texto do repositório azure-search-sample-data . No entanto, é possível utilizar imagens e mesmo assim concluir este guia de início rápido.
Pré-requisitos
Uma conta do Azure com uma assinatura ativa. Crie uma conta gratuitamente.
Um serviço do Azure AI Search. Recomendamos camada Básica ou superior.
Familiaridade com o assistente. Veja Importar assistentes de dados no portal do Azure.
Fontes de dados com suporte
O assistente de importação e vetorização de dadosdá suporte a uma ampla gama de fontes de dados do Azure. No entanto, este início rápido abrange apenas as fontes de dados que funcionam com arquivos inteiros, que são descritos na tabela a seguir.
| Fonte de dados com suporte | Descrição |
|---|---|
| Armazenamento de Blobs do Azure | Essa fonte de dados funciona com blobs e tabelas. Você deve usar uma conta de desempenho padrão (uso geral v2). As camadas de acesso podem ser quentes, frias ou geladas. |
| Azure Data Lake Storage (ADLS) Gen2 | Essa é uma conta de Armazenamento do Azure com um namespace hierárquico habilitado. Para confirmar se você tem o Data Lake Storage, verifique a guia Propriedades na página Visão Geral .
|
| OneLake | Esta fonte de dados está atualmente em versão prévia. Para obter informações sobre limitações e atalhos com suporte, consulte a indexação do OneLake. |
Modelos de inserção com suporte
Para a vetorização integrada, você deve usar um dos seguintes modelos de inserção em uma plataforma de IA do Azure. As instruções de implantação são fornecidas em uma seção posterior.
| Fornecedor | Modelos com suporte |
|---|---|
| OpenAI do Azure em Modelos da Fábrica de IA do Azure1, 2 | text-embedding-ada-002 text-embedding-3-small text-embedding-3-large |
| Recurso de multi-serviços dos serviços de IA do Azure3 | Para texto e imagens: Azure AI Vision multimodal4 |
| Catálogo de modelos do Azure AI Foundry | Para texto: Cohere-embed-v3-english Cohere-embed-v3-multilingual Para imagens: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
1 O endpoint do recurso do Azure OpenAI deve ter um subdomínio personalizado, como https://my-unique-name.openai.azure.com. Se você criou seu recurso no portal do Azure, esse subdomínio foi gerado automaticamente durante a instalação do recurso.
Não há suporte para 2 recursos do Azure OpenAI (com acesso a modelos de inserção) criados no portal do Azure AI Foundry . Somente os recursos do Azure OpenAI criados no portal do Azure são compatíveis com a habilidade do Azure OpenAI Embedding.
3 Para fins de cobrança, você deve anexar seu recurso de vários serviços de IA do Azure ao conjunto de habilidades em seu serviço do Azure AI Search. A menos que você use uma conexão sem chave (versão prévia) para criar o conjunto de habilidades, ambos os recursos devem estar na mesma região.
4 O modelo de inserção multimodal da Visão de IA do Azure está disponível em regiões selecionadas.
Requisitos de ponto de extremidade público
Para fins deste início rápido, todos os recursos anteriores devem ter acesso público habilitado para que os nós do portal do Azure possam acessá-los. Caso contrário, o assistente falhará. Após a execução do assistente, é possível habilitar os firewalls e os pontos de extremidade privados nos componentes de integração para segurança. Para obter mais informações, veja Proteger conexões nos assistentes de importação.
Se os pontos de extremidade privados já estiverem presentes e não puderem ser desabilitados, a opção alternativa será executar o respectivo fluxo de ponta a ponta por meio de um script ou um programa em uma máquina virtual. A máquina virtual precisa estar na mesma rede virtual do ponto de extremidade privado. Aqui está um exemplo de código python para vetorização integrada. O mesmo repositório GitHub contém amostras em outras linguagens de programação.
Acesso baseado em função
Você pode usar o Microsoft Entra ID com atribuições de função ou autenticação baseada em chave com strings de conexão de acesso total. Para conexões do Azure AI Search com outros recursos, recomendamos atribuições de função. Este início rápido assume funções.
Os serviços de pesquisa gratuitos dão suporte a conexões baseadas em função com o Azure AI Search. No entanto, eles não dão suporte a identidades gerenciadas em conexões de saída com o Armazenamento do Azure ou a Visão de IA do Azure. Essa falta de suporte requer autenticação baseada em chave em conexões entre serviços de pesquisa gratuitos e outros recursos do Azure. Para conexões mais seguras, use a camada Básica ou superior e habilite as funções e configure uma identidade gerenciada.
Para configurar o acesso baseado em função recomendado:
No serviço de pesquisa, habilite as funções e configure uma identidade gerenciada atribuída pelo sistema.
Atribua as seguintes funções a si mesmo:
Colaborador do Serviço de Pesquisa
Contribuinte de dados do índice de pesquisa
Leitor de dados de índice de pesquisa
Em sua plataforma de fonte de dados e no provedor de modelo de inserção, crie atribuições de função que permitam que seu serviço de pesquisa acesse dados e modelos. Consulte Preparar dados de exemplo e preparar modelos de inserção.
Observação
Se você não puder progredir pelo assistente devido à indisponibilidade de opções (por exemplo, você não pode selecionar uma fonte de dados ou um modelo de inserção), reveja as atribuições de função. Mensagens de erro indicam que modelos ou implantações não existem, quando a causa real é que o serviço de pesquisa não tem permissão para acessá-los.
Verificar o espaço
Se você estiver começando com o serviço gratuito, estará limitado a três índices, fontes de dados, conjuntos de habilidades e indexadores. O plano Básico limita você a 15. Este início rápido cria um de cada objeto, portanto, verifique se você tem espaço para itens extras antes de começar.
Preparar os dados de exemplo
Essa seção encaminha você para o conteúdo que funciona nesse início rápido. Antes de continuar, verifique se você concluiu os pré-requisitos para acesso baseado em função.
Entre no portal do Azure e selecione sua conta de Armazenamento do Azure.
No painel esquerdo, selecione Armazenamento de Dados>Contêineres.
Crie um novo contêiner e carregue os documentos em PDF do plano de saúde usados neste início rápido.
Para atribuir funções:
No painel esquerdo, selecione Controle de Acesso (IAM).
Selecione Adicionar>Adicionar atribuição de função.
Em Funções de Trabalho, selecione Leitor de Dados do Blob de Armazenamento e, em seguida, selecione Avançar.
Em Membros, selecione Identidade Gerenciada e selecione Selecionar membros.
Selecione sua assinatura e a identidade gerenciada do serviço de pesquisa.
(Opcional) Sincronizar exclusões em seu contêiner com exclusões no índice de pesquisa. Para configurar o indexador para detecção de exclusão:
Habilite a exclusão reversível na sua conta de armazenamento. Se você estiver usando exclusão lógica nativa, a próxima etapa não será necessária.
Adicione metadados personalizados que um indexador pode verificar para determinar quais blobs estão marcados para exclusão. Dê à sua propriedade personalizada um nome descritivo. Por exemplo, você pode nomear a propriedade "IsDeleted" e defini-la como false. Repita essa etapa para cada blob no contêiner. Quando você quiser excluir o blob, altere a propriedade para true. Para obter mais informações, consulte Alterar e excluir a detecção ao indexar do Armazenamento do Azure.
Preparar o modelo de inserção
O assistente pode usar modelos de incorporação implantados a partir do Azure OpenAI, do Azure AI Vision ou do catálogo de modelos no portal do Azure AI Foundry. Antes de continuar, verifique se você concluiu os pré-requisitos para acesso baseado em função.
O assistente dá suporte a text-embedding-ada-002, text-embedding-3-large e text-embedding-3-small. Internamente, o assistente usa a Habilidade AzureOpenAIEmbedding para se conectar ao OpenAI do Azure.
Entre no portal do Azure e selecione seu recurso do Azure OpenAI.
Para atribuir funções:
No painel esquerdo, selecione Controle de acesso (IAM).
Selecione Adicionar>Adicionar atribuição de função.
Em Funções de trabalho, selecione Usuário dos Serviços Cognitivos da OpenAI e selecione Avançar.
Em Membros, selecione Identidade Gerenciada e selecione Selecionar membros.
Selecione sua assinatura e a identidade gerenciada do serviço de pesquisa.
Para implantar um modelo de incorporação:
Entre no portal do Azure AI Foundry e selecione o recurso do Azure OpenAI.
No painel esquerdo, selecione Catálogo de modelos.
Implantar um modelo de incorporação compatível.
Iniciar o assistente
Para iniciar o assistente para pesquisa de vetor:
Entre no portal do Azure e selecione seu serviço do Azure AI Search.
Na página Visão geral, selecione Importar e vetorizar dados.

Selecione sua fonte de dados: Armazenamento de Blobs do Azure, ADLS Gen2 ou OneLake.
Selecione RAG.


Conectar-se aos seus dados
A próxima etapa é conectar-se a uma fonte de dados a ser usada para o índice de pesquisa.
Na página Conectar à sua página de dados, especifique a assinatura do Azure.
Selecione a conta de armazenamento e o contêiner que fornecem os dados de exemplo.
Se você habilitou a exclusão suave e, opcionalmente, adicionou metadados personalizados em Preparar dados de exemplo, selecione a caixa de seleção Habilitar controle de exclusão.
Nas execuções de indexação seguintes, o índice de pesquisa é atualizado para remover todos os documentos de pesquisa com base em blobs excluídos temporariamente no Armazenamento do Microsoft Azure.
Os blobs dão suporte à Exclusão temporária de blob nativa ou à Exclusão temporária usando metadados personalizados.
Se você configurou seus blobs para exclusão temporária, forneça o par nome-valor da propriedade de metadados. Recomendamos IsDeleted. Se IsDeleted for definido como true em um blob, o indexador removerá o documento de pesquisa correspondente na próxima execução do indexador.
O assistente não verifica se há configurações válidas no Armazenamento do Microsoft Azure nem gera um erro se os requisitos não forem atendidos. Em vez disso, a detecção da exclusão não funciona e seu índice de pesquisa provavelmente coletará documentos órfãos ao longo do tempo.
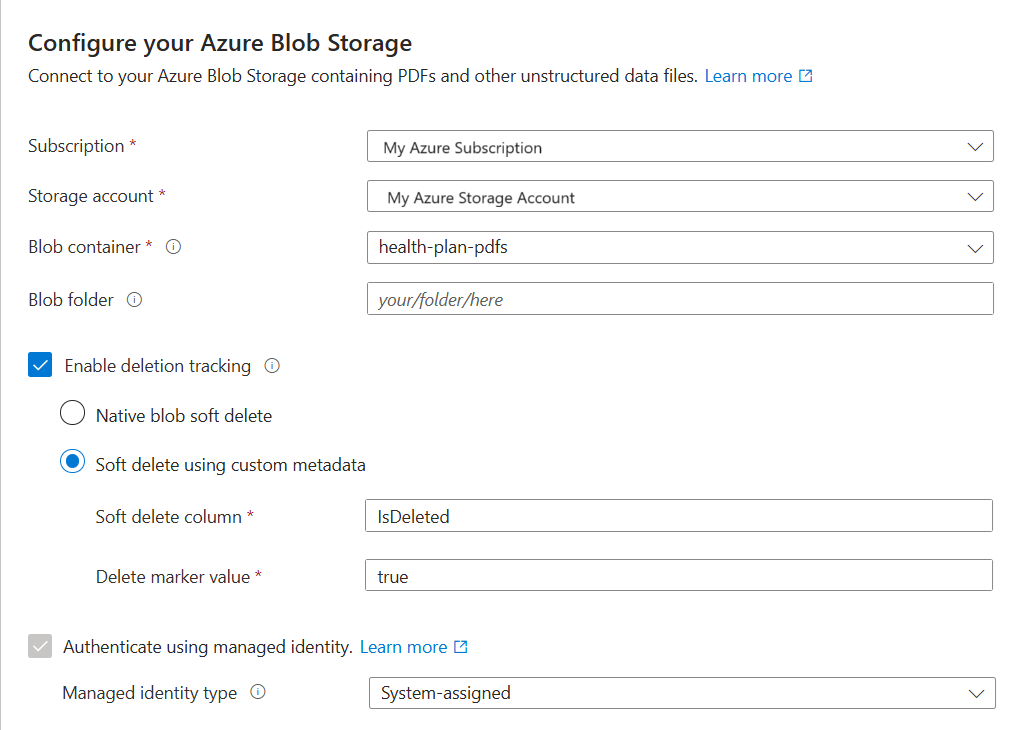
Selecione a caixa de seleção Autenticar usando identidade gerenciada .
Para o tipo de identidade gerenciada, selecione Atribuído pelo sistema.
A identidade deve ter a função Leitor de dados do blob de armazenamento no Armazenamento do Microsoft Azure.
Não ignore esta etapa. Ocorrerá um erro de conexão durante a indexação se o assistente não puder se conectar ao Armazenamento do Microsoft Azure.
Selecione Avançar.
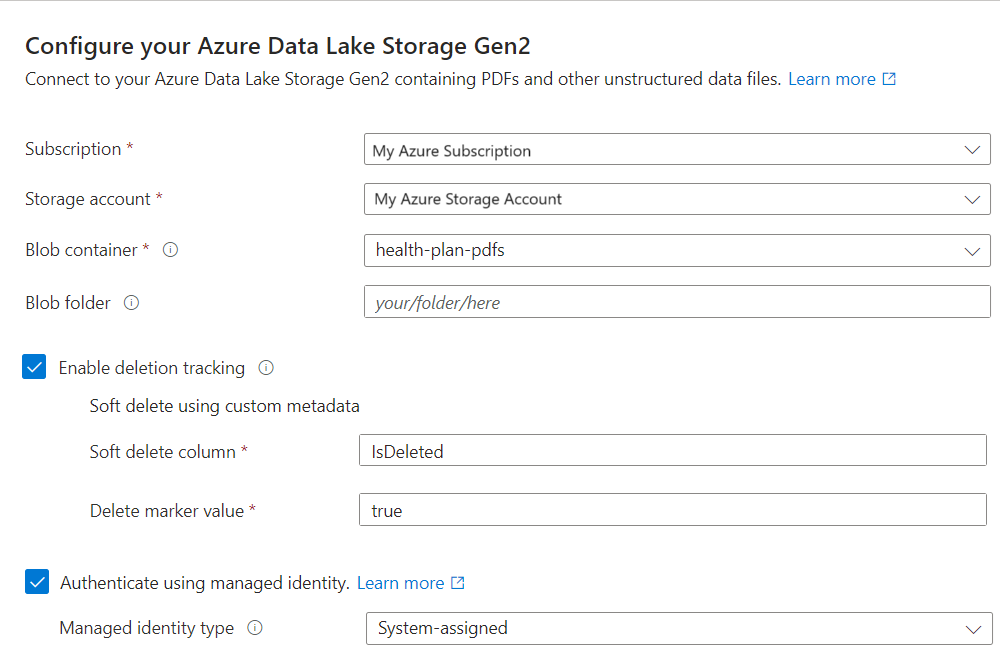
Vetorizar seu texto
Nesta etapa, você especifica um modelo de inserção para vetorizar dados em partes. O chunking é integrado e não configurável. Estas são as configurações efetivas:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
Na página Vetorizar seu texto , selecione a origem do modelo de inserção:
OpenAI do Azure
Catálogo de modelos do Azure AI Foundry
Visão de IA do Azure (por meio de um recurso de vários serviços dos serviços de IA do Azure na mesma região da Pesquisa de IA do Azure)
Especifique a assinatura do Azure.
Dependendo do recurso, faça a seguinte seleção:
Para o Azure OpenAI, selecione o modelo implantado em Preparar modelo de inserção.
Para o catálogo de modelos do AI Foundry, selecione o modelo implantado em Preparar o modelo de inserção.
Para incorporações multimodais da AI Vision, selecione seu recurso multisserviço.
Para o tipo de autenticação, selecione a identidade atribuída pelo sistema.
- A identidade deve ter uma função Usuário dos Serviços Cognitivos no recurso de vários serviços dos serviços de IA do Azure.
Marque a caixa de seleção que reconhece os efeitos de cobrança do uso desses recursos.
Selecione Avançar.
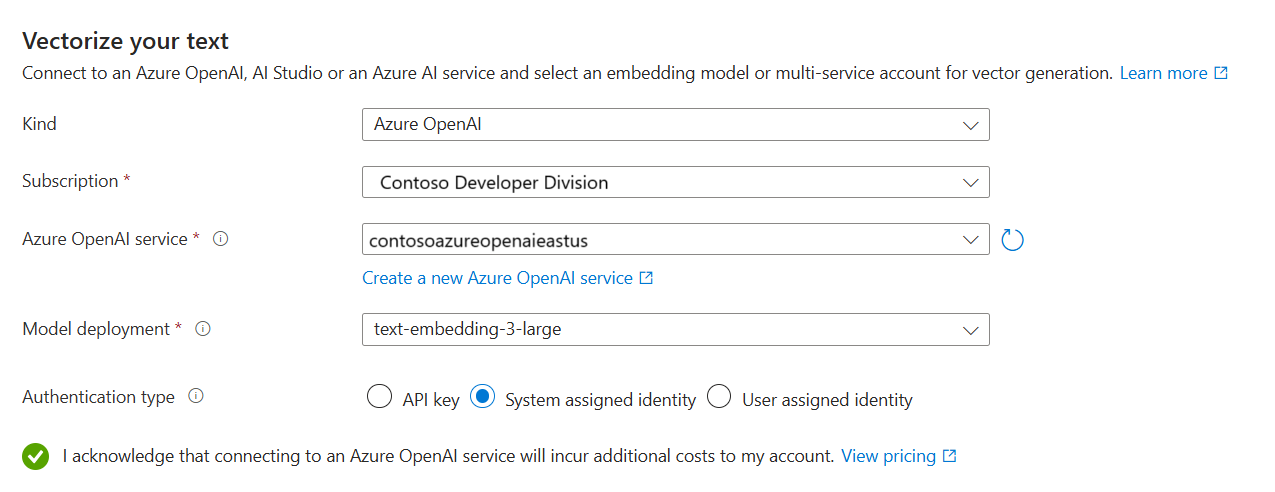
Vetorizar e enriquecer suas imagens
Os PDFs do plano de saúde incluem um logotipo corporativo, mas, caso contrário, não há imagens. Você pode ignorar esta etapa se estiver usando os documentos de exemplo.
No entanto, se você trabalha com conteúdo que inclui imagens úteis, pode aplicar a IA de duas maneiras:
Use um modelo de inserção de imagem com suporte do catálogo ou da API de inserções multimodal da Visão de IA do Azure para vetorizar imagens.
Use o OCR (Reconhecimento Óptico de Caracteres) para reconhecer texto em imagens. Essa opção invoca a Habilidade de OCR para ler texto de imagens.
O Azure AI Search e o recurso de IA do Azure devem estar na mesma região ou configurados para conexões de cobrança sem chave.
Na página Vetorizar suas imagens, especifique o tipo de conexão que o assistente deve fazer. Para a vetorização de imagens, o assistente pode se conectar aos modelos de inserção no Portal da Fábrica de IA do Azure ou na Visão de IA do Azure.
Especifique a assinatura.
Para o catálogo de modelos do Azure AI Foundry, especifique o projeto e a implantação. Para obter mais informações, consulte Preparar modelos de inserção.
(Opcional) Decodifique imagens binárias, como arquivos de documento digitalizados, e use OCR para reconhecer texto.
Marque a caixa de seleção que reconhece os efeitos de cobrança do uso desses recursos.
Selecione Avançar.
Adicionar classificação semântica
Na página Configurações avançadas, opcionalmente, você pode adicionar a classificação semântica para reclassificar os resultados no final da execução da consulta. A reclassificação promove para o topo as correspondências mais semanticamente relevantes.
Mapear novos campos
Principais pontos sobre esta etapa:
O esquema de índice fornece campos vetoriais e não vetoriais para dados segmentados.
Você pode adicionar campos, mas não pode excluir ou modificar os campos gerados.
O modo de processamento de documentos cria blocos (um documento de pesquisa por bloco).
Na página Configurações avançadas , opcionalmente, você pode adicionar novos campos, supondo que a fonte de dados forneça metadados ou campos que não sejam captados na primeira passagem. Por padrão, o assistente gera os campos descritos na tabela a seguir.
| Campo | Aplica-se a | Descrição |
|---|---|---|
| identificador_de_fragmento | Vetores de texto e imagem | Campo de cadeia de caracteres gerado. Pesquisável, recuperável e classificável. Essa é a chave do documento para o índice. |
| parent_id | Vetores de texto | Campo de cadeia de caracteres gerado. Recuperável e filtrável. Identifica o documento pai do qual a parte se origina. |
| parte | Vetores de texto e imagem | Campo de cadeia de caracteres. Versão legível por humanos da parte de dados. Pesquisável e recuperável, mas não filtrável, facetável ou classificável. |
| título | Vetores de texto e imagem | Campo de cadeia de caracteres. Título do documento legível por humanos ou título de página ou número de página. Pesquisável e recuperável, mas não filtrável, facetável ou classificável. |
| text_vector | Vetores de texto | Collection(Edm.single). Declaração vetorial da parte. Pesquisável e recuperável, mas não filtrável, facetável ou classificável. |
Você não pode modificar os campos gerados ou seus atributos, mas pode adicionar novos campos se sua fonte de dados os fornecer. Por exemplo, o Armazenamento de Blobs do Azure fornece uma coleção de campos de metadados.
Selecione Adicionar campo.
Selecione um campo de origem nos campos disponíveis, insira um nome de campo para o índice e aceite (ou substitua) o tipo de dados padrão.
Observação
Os campos de metadados são pesquisáveis, mas não recuperáveis, filtrados, facetáveis ou classificáveis.
Se você quiser restaurar o esquema para sua versão original, selecione Redefinir.
Agendar indexação
Na página Configurações avançadas , você também pode especificar um agendamento de execução opcional para o indexador. Depois de escolher um intervalo na lista suspensa, selecione Avançar.
Concluir o assistente
Na página Revisar sua configuração, especifique um prefixo para os objetos que o assistente cria. Um prefixo comum ajuda você a se manter organizado.
Selecione Criar.
Quando o assistente conclui a configuração, ele cria os seguintes objetos:
Conexão com uma fonte de dados.
Um índice com campos de vetor, vetorizadores, perfis de vetor e algoritmos de vetor. Você não pode criar ou modificar o índice padrão durante o fluxo de trabalho do assistente. Os índices estão em conformidade com a API REST 2024-05-01-preview.
O conjunto de habilidades com a habilidade Divisão de Texto para divisão em partes e uma habilidade de inserção para vetorização. A habilidade de incorporação é a habilidade do AzureOpenAIEmbeddingModel para o OpenAI do Azure ou a habilidade AML para o catálogo de modelos da Fábrica de IA do Azure. O conjunto de habilidades também tem a configuração de projeções de índiceque permite que os dados sejam mapeados de um documento na fonte de dados para as partes correspondentes em um índice “filho”.
Um indexador com mapeamentos de campo e mapeamentos de campo de saída (se aplicável).
Dica
Os objetos criados pelo assistente têm definições JSON configuráveis. Para exibir ou modificar essas definições, selecione Gerenciamento de pesquisa no painel esquerdo, onde você pode exibir seus índices, indexadores, fontes de dados e conjuntos de habilidades.
Verificar os resultados
O Gerenciador de pesquisa aceita cadeias de caracteres de texto como entrada e, em seguida, vetoriza o texto para execução da consulta de vetor.
No portal do Azure, vá paraÍndices de > de Pesquisa e selecione seu índice.
Selecione opções de consulta e, em seguida, selecione Ocultar valores de vetor nos resultados da pesquisa. Esta etapa torna os resultados mais legíveis.
No menu Exibir, selecione JSON para que você possa inserir texto para sua consulta vetorial no parâmetro de
textconsulta vetorial.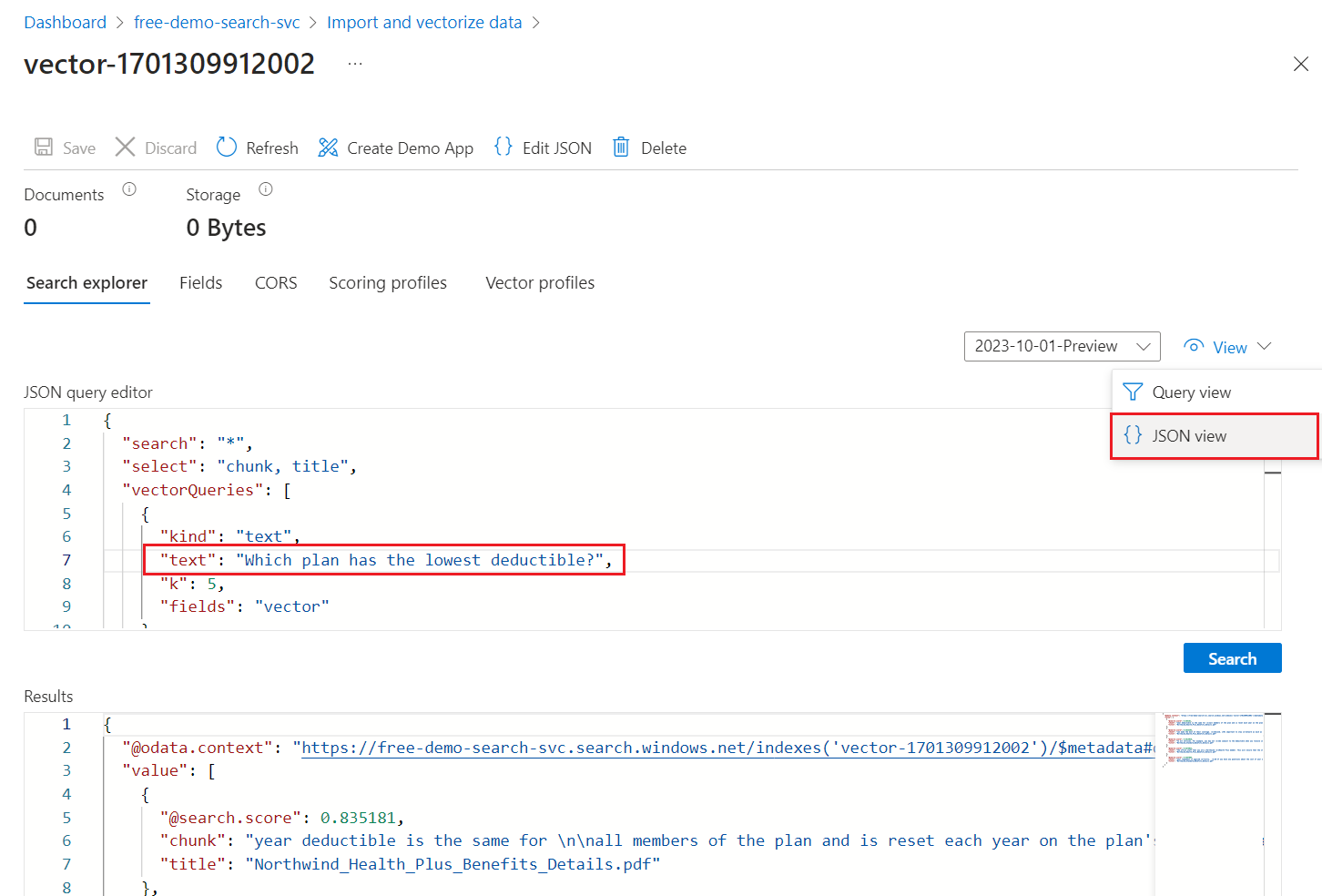
A consulta padrão é uma pesquisa vazia (
"*"), mas inclui parâmetros para retornar as correspondências numéricas. É uma consulta híbrida que executa consultas de texto e vetor em paralelo. Ele também inclui classificação semântica e especifica quais campos retornar nos resultados por meio da instruçãoselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Substitua os dois marcadores de asterisco (
*) por uma pergunta relacionada aos planos de saúde, comoWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Para executar a consulta, selecione Pesquisar.
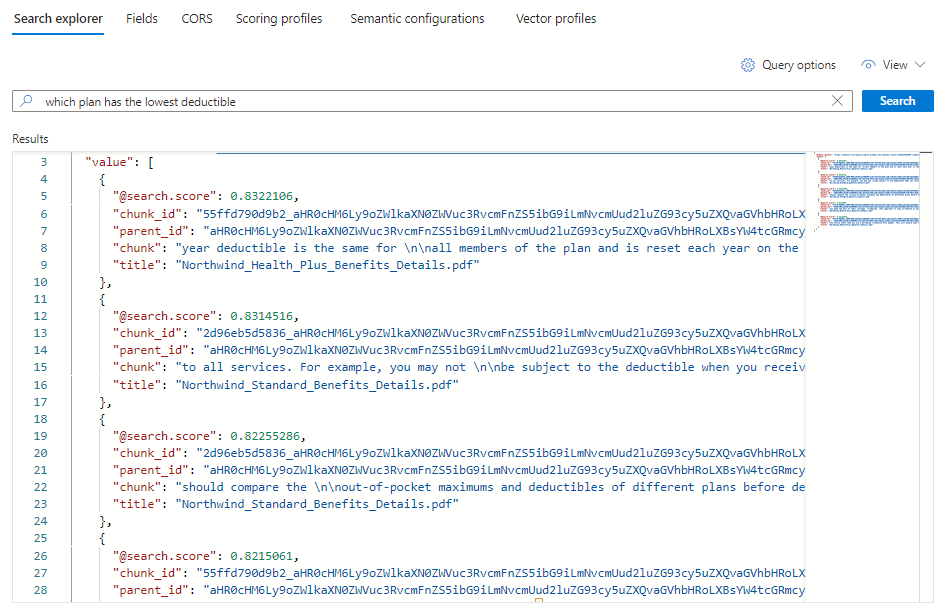
Cada documento é uma parte do PDF original. O campo
titlemostra de qual PDF veio cada parte. Cadachunké longo. Você pode copiar e colar um em um editor de texto para ler o valor inteiro.Para ver todas as partes de um documento específico, adicione um filtro para o campo
title_parent_idde um PDF específico. Você pode verificar a guia Campos do seu índice para confirmar se o campo é filtrável.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Limpeza
O Azure AI Search é um recurso faturável. Se não for mais necessário, exclua-o de sua assinatura para evitar encargos.
Próxima etapa
Este início rápido introduziu você ao assistente de importação e vetorização de dados, que cria todos os objetos necessários para a vetorização integrada. Para explorar cada etapa detalhadamente, consulte Configurar a vetorização integrada no Azure AI Search.