Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os blocos de notas do Jupyter fornecem um ambiente interativo para explorar, analisar e visualizar dados no Microsoft Sentinel data lake e tabelas federadas. Com os blocos de notas, pode escrever e executar código, documentar o fluxo de trabalho e ver resultados, tudo num único local. Isto facilita a exploração de dados, a criação de soluções de análise avançada e a partilha de informações com outras pessoas. Ao tirar partido do Python e do Apache Spark no Visual Studio Code, os blocos de notas ajudam-no a transformar dados de segurança não processados em inteligência acionável.
Este artigo mostra-lhe como explorar e interagir com dados do data lake com blocos de notas do Jupyter no Visual Studio Code.
Pré-requisitos
Integrar no data lake do Microsoft Sentinel
Para utilizar blocos de notas no Microsoft Sentinel data lake, primeiro tem de integrar no data lake. Se ainda não tiver integrado no data lake do Sentinel, veja Inclusão para Microsoft Sentinel data lake. Se tiver integrado recentemente no data lake, poderá demorar algum tempo até que seja ingerido um volume suficiente de dados antes de poder criar análises significativas com blocos de notas.
Permissões
Microsoft Entra ID funções fornecem acesso amplo a todas as áreas de trabalho no data lake. Em alternativa, pode conceder acesso a áreas de trabalho individuais com Azure funções RBAC. Os utilizadores com permissões RBAC Azure para Microsoft Sentinel áreas de trabalho podem executar blocos de notas nessas áreas de trabalho na camada do data lake. Para obter mais informações, veja Funções e permissões no Microsoft Sentinel.
Opcionalmente, Microsoft Sentinel o âmbito ou o RBAC ao nível da linha podem ser configurados para restringir ainda mais o acesso aos dados numa área de trabalho. Quando ativado, o âmbito ao nível da linha limita os dados devolvidos pelas consultas com base no âmbito atribuído pelo utilizador. Se o âmbito ao nível da linha não estiver configurado, o modelo de permissão ao nível da área de trabalho existente aplica-se inalterado. Para obter mais informações, veja Configure Microsoft Sentinel scoping (RBAC ao nível da linha) (pré-visualização).
Para criar novas tabelas personalizadas na camada de análise, a identidade gerida do data lake tem de ser atribuída à função Contribuidor do Log Analytics na área de trabalho do Log Analytics.
Para atribuir a função, siga os passos abaixo:
- No portal do Azure, navegue para a área de trabalho do Log Analytics à qual pretende atribuir a função.
- Selecione Controlo de acesso (IAM) no painel de navegação esquerdo.
- Selecione Adicionar atribuição de função.
- Na tabela Função , selecione Contribuidor do Log Analytics e, em seguida, selecione Seguinte
- Selecione Identidade gerida e, em seguida, selecione Selecionar membros.
- A identidade gerida do data lake é uma identidade gerida atribuída pelo sistema com o nome
msg-resources-<guid>. Selecione a identidade gerida e, em seguida, selecione Selecionar. - Selecione Rever e atribuir.
Para obter mais informações sobre como atribuir funções a identidades geridas, veja Atribuir funções de Azure com o portal do Azure.
Instalar Visual Studio Code e a extensão Microsoft Sentinel
Se ainda não tiver Visual Studio Code, transfira e instale Visual Studio Code para Mac, Linux ou Windows.
A extensão Microsoft Sentinel para Visual Studio Code (VS Code) é instalada a partir do marketplace de extensões. Para instalar a extensão, siga estes passos:
- Selecione o Marketplace de Extensões na barra de ferramentas esquerda.
- Procure Sentinel.
- Selecione a extensão Microsoft Sentinel e selecione Instalar.
- Após a instalação da extensão, o Microsoft Sentinel
 é apresentado na barra de ferramentas à esquerda.
é apresentado na barra de ferramentas à esquerda.

Instale a extensão GitHub Copilot para Visual Studio Code para ativar a conclusão de código e sugestões em blocos de notas.
- Procure GitHub Copilot no Marketplace de Extensões e instale-o.
- Após a instalação, inicie sessão no GitHub Copilot com a sua conta do GitHub.
Explorar tabelas de camadas do data lake
Depois de instalar a extensão Microsoft Sentinel, pode começar a explorar tabelas de camadas do data lake e a criar blocos de notas do Jupyter para analisar os dados.
Iniciar sessão na extensão Microsoft Sentinel
Selecione o Microsoft Sentinel
na barra de ferramentas à esquerda.É apresentada uma caixa de diálogo com o seguinte texto A extensão "Microsoft Sentinel" quer iniciar sessão com a Microsoft. Selecione Permitir.
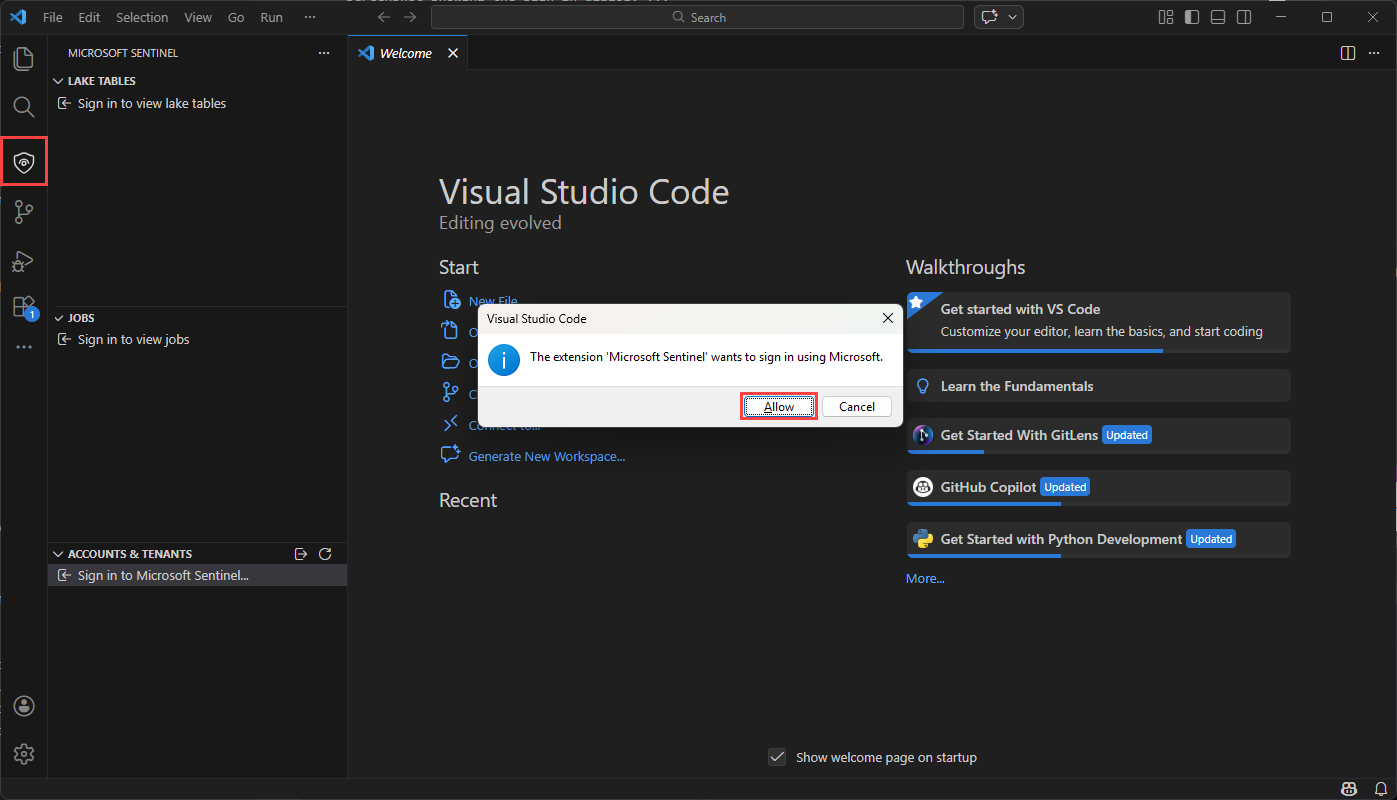
Selecione o nome da sua conta para concluir o início de sessão.
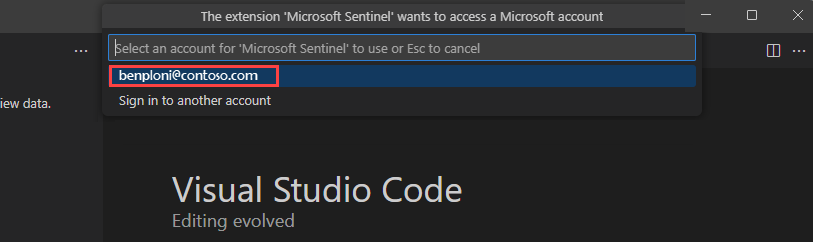
Se tiver várias contas de convidado associadas ao seu início de sessão, pode alternar facilmente entre contas. Para alternar entre contas, selecione o nome da conta no canto inferior esquerdo da janela Visual Studio Code. Só é possível selecionar uma conta de cada vez.
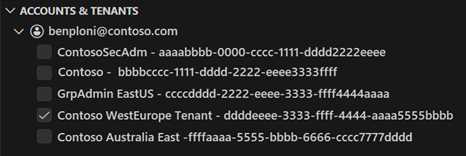
Importante
Alternar entre contas desliga todas as sessões ativas do pyspark.



Ver tabelas e tarefas do data lake
Depois de iniciar sessão, a extensão Sentinel apresenta uma lista de tabelas lake e Tarefas no painel esquerdo. As tabelas são agrupadas pela base de dados e categoria. As tabelas federadas são apresentadas na categoria Tabelas federadas em Tabelas de sistema. Selecione uma tabela para ver as definições de coluna.
Para obter informações sobre Tarefas, veja Tarefas e Agendamento. Para obter mais informações sobre tabelas federadas, veja Using federated tables in the Microsoft Sentinel data lake (Utilizar tabelas federadas no data lake do Microsoft Sentinel).

Criar um novo bloco de notas
Para criar um novo bloco de notas, utilize um dos seguintes métodos.
Introduza > na caixa de pesquisa ou prima Ctrl+Shift+P e, em seguida, introduza Criar Novo Jupyter Notebook.

Selecione Ficheiro > Novo Ficheiro e, em seguida, selecione Jupyter Notebook na lista pendente.
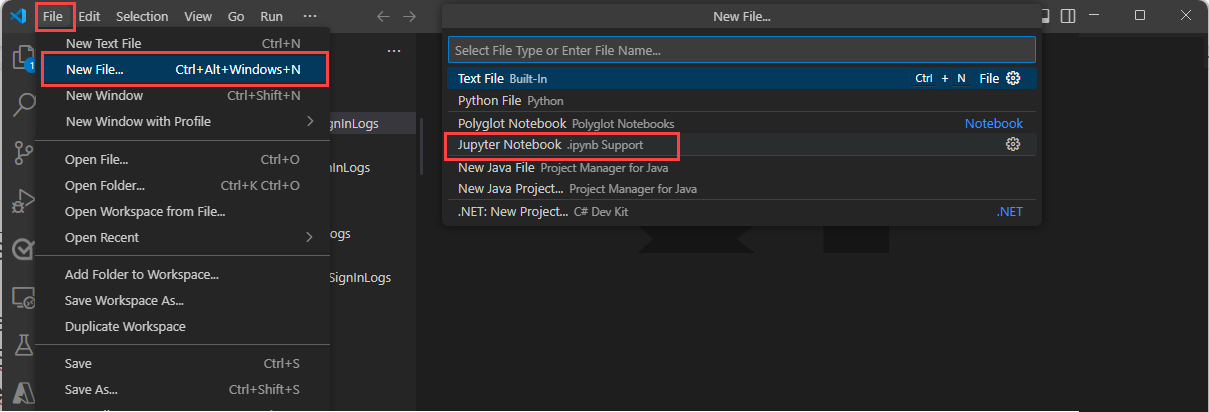
No novo bloco de notas, cole o seguinte código na primeira célula.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df_filtered = df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False) # Transform the dataframe df_transformed = df.filter(df.mail.isNotNull()).select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId") write_options = { 'mode': 'overwrite' } # Save to a new table data_provider.save_as_table(df_transformed, "EntraGroups_Processed_SPRK", write_options=write_options)


O editor fornece a conclusão do código intellisense para os nomes da MicrosoftSentinelProvider classe e da tabela no data lake.
Selecione o triângulo Executar para executar o código no bloco de notas. Os resultados são apresentados no painel de saída abaixo da célula de código.
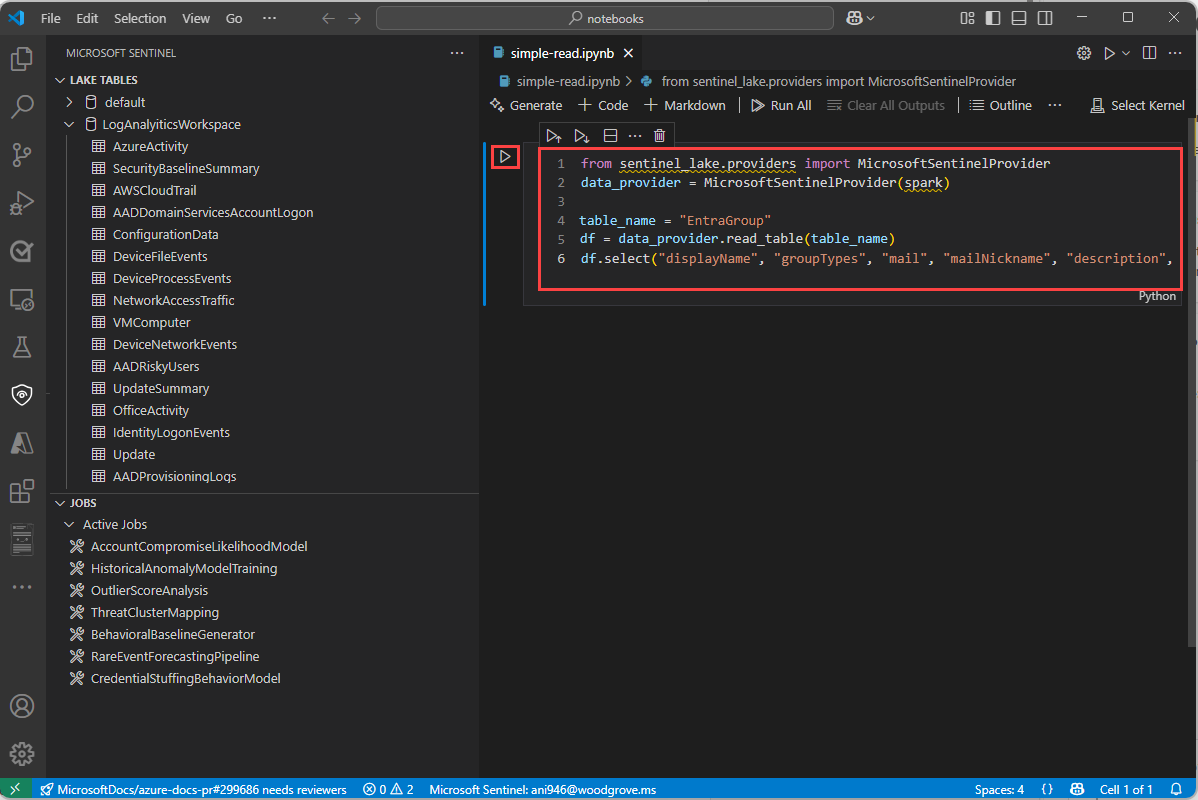
Selecione Microsoft Sentinel na lista para obter uma lista de conjuntos de runtime.
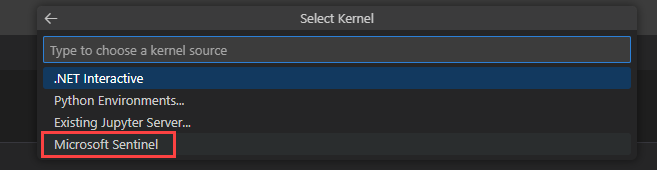
Selecione Médio para executar o bloco de notas no conjunto de runtime de tamanho médio. Para obter mais informações sobre os diferentes runtimes, veja Selecting the appropriate Microsoft Sentinel runtime (Selecionar o runtime de Microsoft Sentinel adequado).



Observação
Selecionar o kernel inicia a sessão do Spark e executa o código no bloco de notas. Depois de selecionar o conjunto, a sessão pode demorar entre 3 a 5 minutos. As execuções subsequentes são executadas mais rapidamente, uma vez que a sessão já está ativa.
Quando a sessão é iniciada, o código no bloco de notas é executado e os resultados são apresentados no painel de saída abaixo da célula de código, por exemplo: 
Para blocos de notas de exemplo que demonstram como interagir com o data lake Microsoft Sentinel, veja Blocos de notas de exemplo para Microsoft Sentinel data lake.
Barra de status
A barra de status na parte inferior do bloco de notas fornece informações sobre o estado atual do bloco de notas e a sessão do Spark. A barra de status inclui as seguintes informações:
A percentagem de utilização do vCore para o conjunto do Spark selecionado. Paire o cursor do rato sobre a percentagem para ver o número de vCores utilizados e o número total de vCores disponíveis no conjunto. As percentagens representam a utilização atual em cargas de trabalho interativas e de trabalhos para a conta com sessão iniciada.
A ligação status da sessão do Spark, por exemplo
Connecting,ConnectedouNot Connected.

Definir tempos limite de sessão
Pode definir o tempo limite da sessão e avisos de tempo limite para blocos de notas interativos. Estas definições são mantidas nas definições da extensão para que sejam preservadas em todas as sessões.
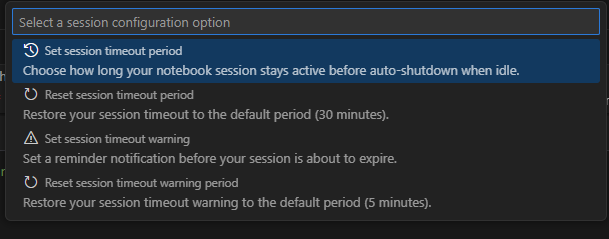
Para alterar o tempo limite, selecione o status de ligação na barra de status na parte inferior do bloco de notas. Escolha dentre as seguintes opções:
Definir o período de tempo limite da sessão: define o tempo em minutos antes de a sessão exceder o limite de tempo. A predefinição é 30 minutos.
Repor o período de tempo limite da sessão: repõe o tempo limite da sessão para o valor predefinido de 30 minutos.
Definir o período de aviso de tempo limite da sessão: define o tempo em minutos antes do tempo limite em que é apresentado um aviso de que a sessão está prestes a exceder o limite de tempo. A predefinição é 5 minutos.
Repor o período de aviso de tempo limite da sessão: repõe o aviso de tempo limite da sessão para o valor predefinido de 5 minutos.

Utilizar GitHub Copilot em blocos de notas
Utilize GitHub Copilot para o ajudar a escrever código em blocos de notas. GitHub Copilot fornece sugestões de código e conclusão automática com base no contexto do seu código. Para utilizar GitHub Copilot, certifique-se de que tem a extensão GitHub Copilot instalada no Visual Studio Code.
Copie o código dos Blocos de notas de exemplo para Microsoft Sentinel data lake e guarde-o na pasta de blocos de notas para fornecer contexto para GitHub Copilot. GitHub Copilot poderão então sugerir conclusões de código com base no contexto do seu bloco de notas.
O exemplo seguinte mostra GitHub Copilot a gerar uma revisão de código.

Microsoft Sentinel Provider class (Classe de fornecedor de Microsoft Sentinel)
Para ligar ao Microsoft Sentinel data lake, utilize a SentinelLakeProvider classe .
Esta classe faz parte do access_module.data_loader módulo e fornece métodos para interagir com o data lake. Para utilizar esta classe, importe-a e crie uma instância da classe com uma spark sessão.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Para obter mais informações sobre os métodos disponíveis, veja Microsoft Sentinel Provider class reference (Referência da classe fornecedor de Microsoft Sentinel).
Selecione o conjunto de runtime adequado
Existem três conjuntos de runtime disponíveis para executar os seus blocos de notas do Jupyter na extensão Microsoft Sentinel. Cada conjunto foi concebido para diferentes cargas de trabalho e requisitos de desempenho. A escolha do conjunto de runtime afeta o desempenho, o custo e o tempo de execução dos trabalhos do Spark.
| Conjunto de Runtime | Casos de Utilização Recomendados | Características |
|---|---|---|
| Small | Desenvolvimento, testes e análise exploratória simples. Pequenas cargas de trabalho com transformações simples. Eficiência de custos priorizada. |
Adequado para cargas de trabalho pequenas Transformações simples. Custo mais baixo, tempo de execução mais longo. |
| Medium | Tarefas ETL com associações, agregações e preparação de modelos de ML. Moderar cargas de trabalho com transformações complexas. |
Desempenho melhorado em Pequena. Processa o paralelismo e operações moderadas de memória intensiva. |
| Large | Aprendizagem profunda e cargas de trabalho de ML. Mistura de dados extensa, associações grandes ou processamento em tempo real. Tempo de execução crítico. |
Memória elevada e poder de computação. Atrasos mínimos. Melhor para cargas de trabalho grandes, complexas ou sensíveis ao tempo. |
Observação
Quando acedido pela primeira vez, as opções de kernel podem demorar cerca de 30 segundos a carregar.
Depois de selecionar um conjunto de runtime, a sessão pode demorar entre 3 a 5 minutos.
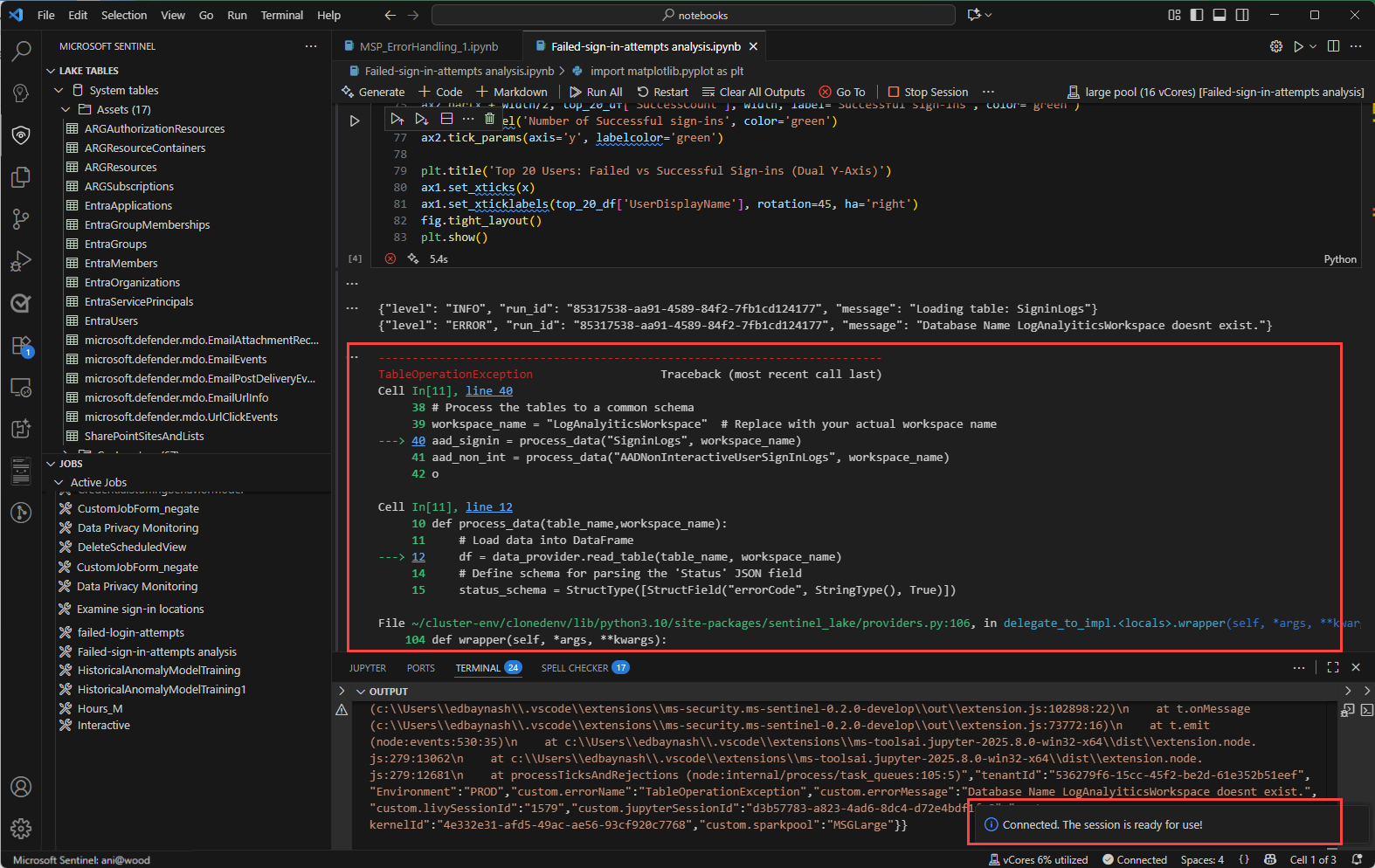
Ver mensagens, registos e erros
Os registos de mensagens e as mensagens de erro são apresentados em três áreas do Visual Studio Code.
O painel Saída .
- No painel Saída, selecione Microsoft Sentinel no menu pendente.
- Selecione Depurar para incluir entradas de registo detalhadas.
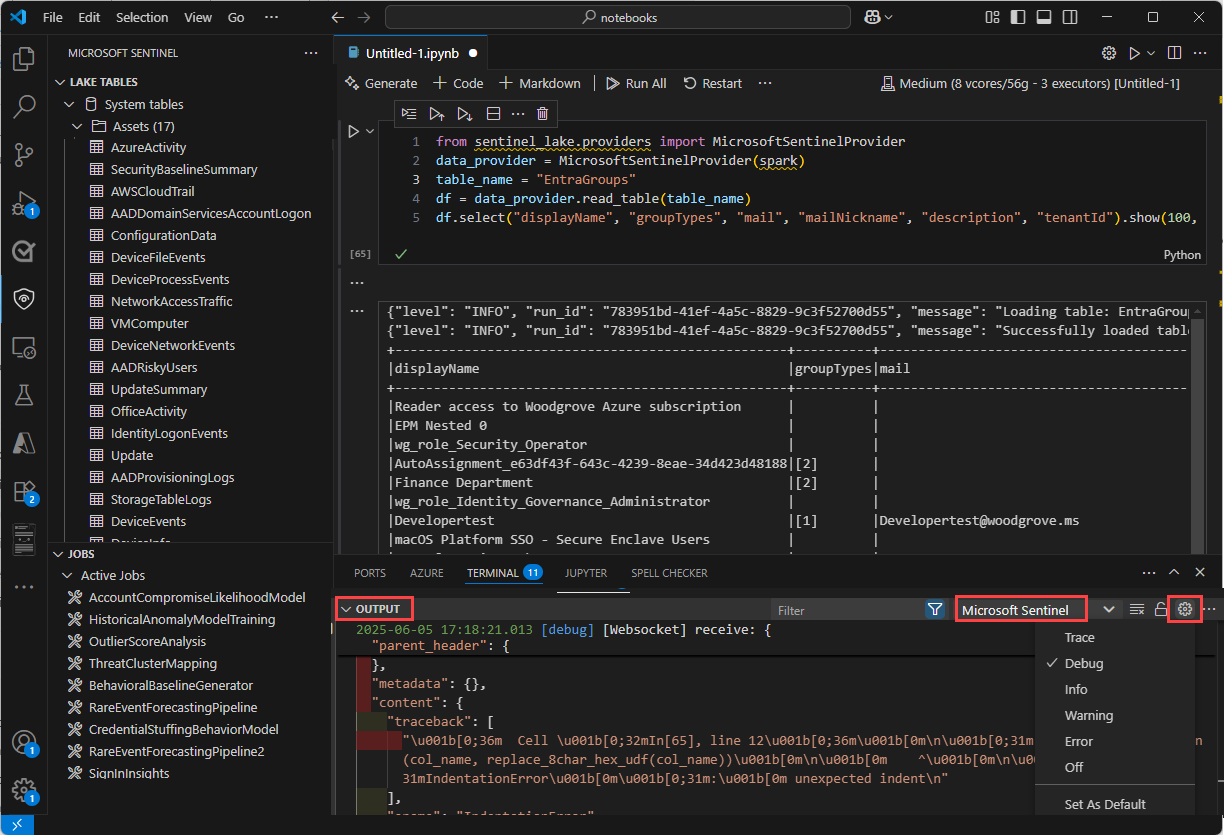
As mensagens em linha no bloco de notas fornecem feedback e informações sobre a execução de células de código. Estas mensagens incluem a execução status atualizações, indicadores de progresso e notificações de erro relacionadas com o código na célula anterior
Um pop-up de notificação no canto inferior direito do Visual Studio Code, também conhecido como uma mensagem de alerta, fornece alertas e atualizações em tempo real sobre a status de operações no bloco de notas e a sessão do Spark. Estas notificações incluem mensagens, avisos e alertas de erro, como ligação bem-sucedida a uma sessão do Spark e avisos de tempo limite.


Tarefas e agendamento
Pode agendar tarefas para execução em alturas ou intervalos específicos com a extensão Microsoft Sentinel para Visual Studio Code. As tarefas permitem automatizar tarefas de processamento de dados para resumir, transformar ou analisar dados no data lake Microsoft Sentinel. As tarefas também são utilizadas para processar dados e escrever resultados em tabelas personalizadas na camada de análise ou camada de análise do data lake. Para obter mais informações sobre como criar e gerir tarefas, veja Criar e gerir tarefas de blocos de notas do Jupyter.
Parâmetros de serviço e limites para Blocos de Notas do VS Code
A secção seguinte lista os parâmetros de serviço e os limites do Microsoft Sentinel data lake ao utilizar blocos de notas do VS Code.
| Categoria | Parâmetro/limite |
|---|---|
| Tabela personalizada no escalão de análise | As tabelas personalizadas na camada de análise não podem ser eliminadas de um bloco de notas; Utilize o Log Analytics para eliminar estas tabelas. Para obter mais informações, consulte Adicionar ou eliminar tabelas e colunas no Azure Monitorizar Registos |
| Tempo limite do socket Web do gateway | 2 horas |
| Tempo limite da consulta interativa | 2 horas |
| Tempo limite de inatividade de sessão interativa | 20 minutos |
| Idioma | Python |
| Graph query timeout (Tempo limite de consulta de gráficos) | 7,5 minutos |
| Tempo limite da tarefa do bloco de notas | 8 horas |
| Máximo de tarefas simultâneas do bloco de notas | 3. As tarefas subsequentes são em fila de espera |
| Máximo de utilizadores em simultâneo na consulta interativa | 8-10 no Conjunto grande |
| Tempo de arranque da sessão | A sessão de computação do Spark demora cerca de 5 a 6 minutos a ser iniciada. Pode ver o status da sessão na parte inferior do seu Bloco de Notas do VS Code. |
| Bibliotecas suportadas | Apenas Azure Synapse bibliotecas 3.4 e a biblioteca do Fornecedor de Microsoft Sentinel para funções abstratas são suportadas para consultar o data lake. As instalações do Pip ou bibliotecas personalizadas não são suportadas. |
| Vs Code UX limit to display records (Limite de UX do VS Code para apresentar registos) | 100.000 linhas |
Solução de problemas
Para obter erros comuns e soluções ao trabalhar com blocos de notas, veja Resolução de problemas de blocos de notas no data lake do Microsoft Sentinel.
Conteúdo relacionado
- Resolver problemas de blocos de notas no data lake do Microsoft Sentinel
- Criar e gerir tarefas de blocos de notas
- Blocos de notas de exemplo para Microsoft Sentinel data lake
- Referência da classe fornecedor de Microsoft Sentinel
- descrição geral do data lake do Microsoft Sentinel
- Microsoft Sentinel funções e permissões do data lake.