Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo fornece recomendações para trabalhar com diretórios que contêm um grande número de arquivos. Normalmente, é uma boa prática reduzir o número de arquivos em um único diretório, distribuindo os arquivos em vários diretórios. Entretanto, há situações em que não é possível evitar grandes diretórios. Considere as sugestões a seguir ao trabalhar com diretórios grandes em compartilhamentos de arquivos do Azure montados em clientes Linux.
Aplica-se a
| Modelo de gestão | Modelo de cobrança | Camada de mídia | Redundância | PME | NFS (Nota Fiscal de Serviços) |
|---|---|---|---|---|---|
| Microsoft.Storage | Provisionado v2 | HDD (padrão) | Local (LRS) |
|
|
| Microsoft.Storage | Provisionado v2 | HDD (padrão) | Zona (ZRS) |
|
|
| Microsoft.Storage | Provisionado v2 | HDD (padrão) | Localização geográfica (GRS) |
|
|
| Microsoft.Storage | Provisionado v2 | HDD (padrão) | GeoZone (GZRS) |
|
|
| Microsoft.Storage | Provisionado v1 | SSD (de alta qualidade) | Local (LRS) |
|
|
| Microsoft.Storage | Provisionado v1 | SSD (de alta qualidade) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago conforme o uso | HDD (padrão) | Local (LRS) |
|
|
| Microsoft.Storage | Pago conforme o uso | HDD (padrão) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago conforme o uso | HDD (padrão) | Localização geográfica (GRS) |
|
|
| Microsoft.Storage | Pago conforme o uso | HDD (padrão) | GeoZone (GZRS) |
|
|
Aumentar o número de buckets de hash
A quantidade total de RAM presente no sistema que faz a enumeração influencia o funcionamento interno de protocolos de sistema de arquivos como NFS e SMB. Mesmo que os usuários não estejam enfrentando alto uso de memória, a quantidade de memória disponível influencia o número de buckets de hash de inode que o sistema possui, o que impacta/melhora o desempenho da enumeração para diretórios grandes. É possível modificar o número de buckets de hash de inode que o sistema possui para reduzir as colisões de hash que podem ocorrer durante grandes cargas de trabalho de enumeração.
Para aumentar o número de buckets de hash de inode, modifique as configurações de inicialização:
Usando um editor de texto, edite o arquivo
/etc/default/grub.sudo vim /etc/default/grubAdicione o texto a seguir ao arquivo
/etc/default/grub. Esse comando define 128 MB como o tamanho da tabela de hash do inode, aumentando o consumo de memória do sistema em um máximo de 128 MB.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Se
GRUB_CMDLINE_LINUXjá existir, adicioneihash_entries=16777216separados por espaço, como esta:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Para aplicar as alterações, execute:
sudo update-grub2Reinicie o sistema:
sudo rebootPara verificar se as alterações são efetivas após a reinicialização, verifique os comandos de cmdline do kernel:
cat /proc/cmdlineSe
ihash_entriesestiver visível, o sistema aplicou a configuração e o desempenho da enumeração deve melhorar exponencialmente.Você também pode verificar a saída do dmesg para ver se a linha de comando do kernel foi aplicada:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Opções de montagem recomendadas
As opções de montagem a seguir são específicas da enumeração e podem reduzir a latência ao trabalhar com grandes diretórios.
actimeo
A actimeo opção de montagem especifica o tempo (em segundos) que o cliente armazena em cache atributos de um arquivo ou diretório antes de solicitar informações de atributo de um servidor. Durante esse período, as alterações que ocorrem no servidor permanecem não detectadas até que o cliente verifique o servidor novamente. Para clientes SMB, o tempo limite de cache de atributo padrão é definido como 1 segundo.
Em clientes NFS, especificar actimeo define todos os valores de acregmin, acregmax, acdirmin e acdirmax para o mesmo valor. Se actimeo não for especificado, o cliente usará os padrões para cada uma dessas opções.
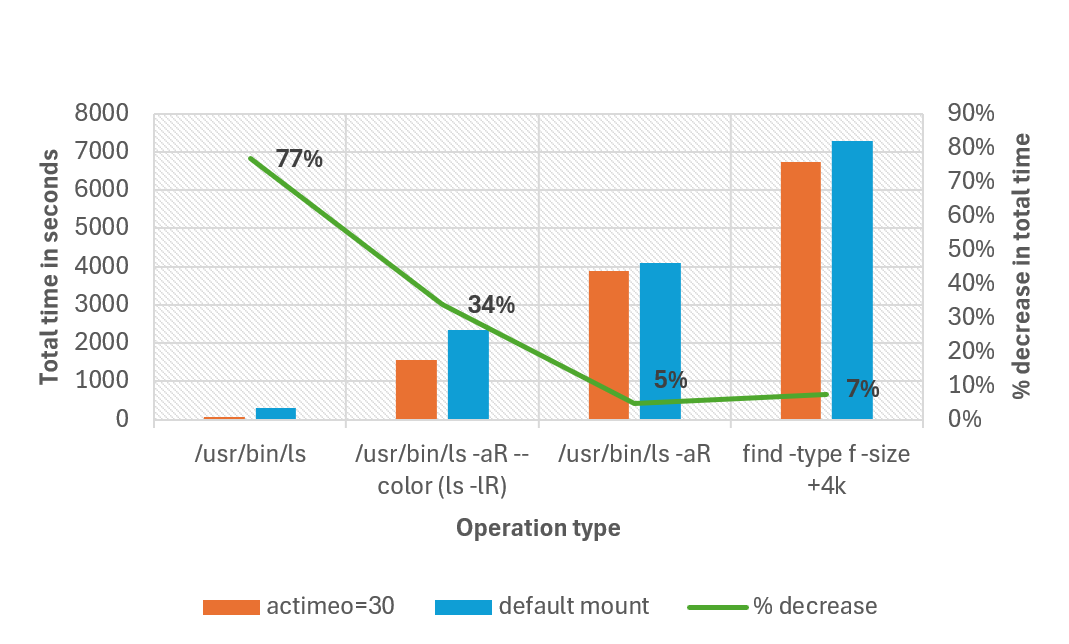
Recomendamos definir actimeo entre 30 e 60 segundos ao trabalhar com grandes diretórios. A definição de um valor nesse intervalo faz com que os atributos permaneçam válidos por um período maior no cache de atributos do cliente, permitindo que as operações obtenham atributos de arquivo do cache em vez de buscá-los por meio da transmissão. Isso pode reduzir a latência em situações em que os atributos armazenados em cache expiram enquanto a operação ainda está em execução.
O gráfico a seguir compara o tempo total necessário para concluir diferentes operações com a montagem padrão versus a definição de um valor actimeo de 30 para uma carga de trabalho que tem 1 milhão de arquivos em um único diretório. Em nossos testes, o tempo total de conclusão foi reduzido em até 77% para algumas operações. Todas as operações foram feitas com ls sem aliases.
nconnect do NFS
O NFS nconnect é uma opção de montagem do lado do cliente para compartilhamentos de arquivos NFS que permite usar várias conexões TCP entre o cliente e o compartilhamento de arquivos NFS. Recomendamos a configuração ideal de nconnect=4 para reduzir a latência e melhorar o desempenho. O recurso nconnect pode ser especialmente útil para cargas de trabalho que usam a E/S assíncrona ou síncrona de vários threads.
Saiba mais.
Comandos e operações
A forma como os comandos e as operações são especificados também pode afetar o desempenho. Listar todos os arquivos em um diretório grande usando o comando ls é um bom exemplo.
Observação
Algumas operações, como ls, find e du recursivas, precisam de nomes de arquivos e atributos de arquivos, portanto, combinam enumerações de diretórios (para obter as entradas) com um stat em cada entrada (para obter os atributos). Sugerimos o uso de um valor mais alto para o actimeo nos pontos de montagem em que você provavelmente executará esses comandos.
Use ls sem aliases
Em algumas distribuições Linux, o shell define automaticamente as opções padrão para o comando ls, como ls --color=auto. Isso altera a forma como ls funciona e adiciona mais operações à execução de ls. Para evitar a degradação do desempenho, recomendamos o uso do ls sem aliases. Você pode fazer isso de três maneiras:
Como uma solução alternativa temporária que afeta apenas a sessão atual, você pode remover o alias usando o comando
unalias ls.Para fazer uma alteração permanente, você pode editar o alias
lsno arquivobashrc/bash_aliasesdo usuário. No Ubuntu, edite~/.bashrcpara remover o alias dels.Em vez de chamar
ls, você poderá chamar diretamente o bináriols, por exemplo,/usr/bin/ls. Isso permite que você uselssem nenhuma opção que possa estar no alias. Você pode encontrar o local do binário executando o comandowhich ls.
Impedir que o ls classifique sua saída
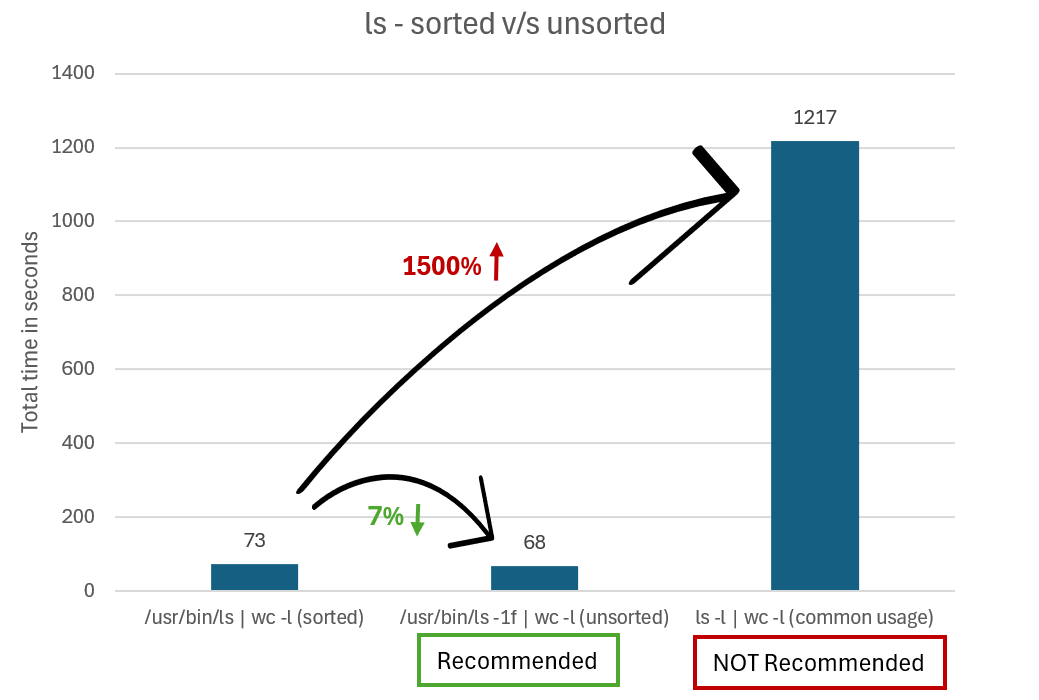
Ao usar ls com outros comandos, você pode melhorar o desempenho impedindo que ls classifique sua saída em situações em que não se importa com a ordem em que ls retorna os arquivos. A classificação da saída adiciona uma sobrecarga significativa.
Em vez de executar ls -l | wc -l para obter o número total de arquivos, você pode usar as opções -f ou -U com ls para evitar que a saída seja classificada. A diferença é que -f também mostra arquivos ocultos e -U não mostra.
Por exemplo, se estiver chamando diretamente o binário ls no Ubuntu, você executaria /usr/bin/ls -1f | wc -l ou /usr/bin/ls -1U | wc -l.
O gráfico a seguir compara o tempo necessário para gerar resultados usando ls sem aliases e não classificado versus ls classificado.
Operações de cópia e backup de arquivos
Ao copiar dados de um compartilhamento de arquivos ou fazer backup de compartilhamentos de arquivos para outro local, para obter o desempenho ideal, recomendamos usar um instantâneo do compartilhamento como origem em vez do compartilhamento de arquivos ao vivo com E/S ativa. Os aplicativos de backup devem executar comandos diretamente no instantâneo. Para obter mais informações, consulte Usar instantâneos de compartilhamento com os Arquivos do Azure.
Recomendações no nível do aplicativo
Ao desenvolver aplicativos que usam diretórios grandes, siga estas recomendações.
Ignore os atributos do arquivo. Se o aplicativo precisar apenas do nome do arquivo e não de atributos de arquivo, como tipo de arquivo ou hora da última modificação, você poderá usar várias chamadas para chamadas do sistema, como
getdents64com um bom tamanho de buffer para obter as entradas no diretório especificado sem o tipo de arquivo, tornando a operação mais rápida evitando operações extras que não são necessárias.Intercalar chamadas stat. Se o aplicativo precisar de atributos e do nome do arquivo, recomendamos intercalar as chamadas stat com
getdents64em vez de obter todos os registros até o final do arquivo comgetdents64e depois fazer um statx em todos os registros retornados. A intercalação das chamadas stat instrui o cliente a solicitar o arquivo e seus atributos de uma só vez, reduzindo o número de chamadas ao servidor. Quando combinado com um valor altoactimeo, a intercalação de chamadas de estatística pode aprimorar significativamente o desempenho. Por exemplo, em vez de[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ], coloque as chamadas statx após cadagetdents64da seguinte forma:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Aumentar a profundidade de E/S. Se possível, sugerimos configurar
nconnectcom um valor diferente de zero (maior que 1) e distribuir a operação entre vários threads ou usar a E/S assíncrona. Isso permite operações que podem ser assíncronas para se beneficiar de várias conexões simultâneas com o compartilhamento de arquivos.Forçar o uso do cache. Se o aplicativo estiver consultando os atributos de arquivo em um compartilhamento de arquivo que apenas um cliente montou, use a chamada de sistema statx com o sinalizador
AT_STATX_DONT_SYNC. Esse sinalizador garante que os atributos armazenados em cache sejam recuperados do cache sem sincronização com o servidor, evitando viagens extras de ida e volta à rede para obter os dados mais recentes.