Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Stream Analytics pode gerar dados no formato JSON para o Azure Cosmos DB. Ele habilita o arquivamento de dados e consultas de baixa latência em dados JSON não estruturados. Este artigo aborda algumas práticas recomendadas para implementar essa configuração (Stream Analytics para Cosmos DB). Se você não estiver familiarizado com Azure Cosmos DB, consulte a documentação do Azure Cosmos DB para começar.
Observação
- Neste momento, o Stream Analytics dá suporte à conexão com o Azure Cosmos DB somente por meio da API do SQL. Outras APIs do Azure Cosmos DB ainda não têm suporte. Se você direcionar o Stream Analytics para contas do Azure Cosmos DB criadas com outras APIs, é possível que os dados não sejam armazenados corretamente.
- É recomendável definir seu trabalho como nível de compatibilidade 1.2 ao usar o Azure Cosmos DB como saída.
Conceitos básicos do Azure Cosmos DB como um destino de saída
A saída do Azure Cosmos DB no Stream Analytics permite a gravação dos resultados do processamento de fluxo como uma saída em JSON nos contêineres do Azure Cosmos DB. O Stream Analytics não cria contêineres em seu banco de dados. Em vez disso, requer que você os crie antecipadamente. Em seguida, você pode controlar os custos de cobrança dos contêineres do Azure Cosmos DB. Também pode ajustar o desempenho, a consistência e a capacidade de seus contêineres diretamente usando as APIs do Azure Cosmos DB. As seções a seguir detalham algumas das opções de contêiner para o Azure Cosmos DB.
Ajustar a consistência, a disponibilidade e a latência
Para atender aos requisitos do aplicativo, o Azure Cosmos DB permite o ajuste do banco de dados e dos contêineres, além de compensações entre consistência, disponibilidade, latência e taxa de transferência.
Dependendo dos níveis de consistência de leitura exigidos pelo seu cenário em relação à latência de leitura e de gravação, você poderá escolher um nível de consistência em sua conta de banco de dados. Você pode melhorar a taxa de transferência expandindo as Unidades de Solicitação (RUs) no contêiner. Também por padrão, o Azure Cosmos DB habilita a indexação síncrona em cada operação CRUD para seu contêiner. Essa é outra opção útil para controlar o desempenho da leitura/gravação no Azure Cosmos DB. Para ter mais informações, consulte o artigo Alterar o banco de dados e os níveis de consistência da consulta.
Inserções e atualizações a partir do Stream Analytics
A integração do Stream Analytics com o Azure Cosmos DB permite inserir ou atualizar registros no contêiner de acordo com determinada coluna ID do Documento. Essa operação também é chamada de upsert. O Stream Analytics usa uma abordagem upsert otimista. Atualizações ocorrem somente quando uma inserção falha devido a conflito de ID do documento.
Com o nível de compatibilidade 1.0, o Stream Analytics executa essa atualização como uma operação de PATCH, de modo que permite atualizações parciais no documento. O Stream Analytics adiciona novas propriedades ou substitui uma propriedade existente de forma incremental. Porém, as alterações nos valores das propriedades da matriz em seu documento JSON resultam em substituir toda a matriz. Ou seja, a matriz não é mesclada.
Com 1.2, o comportamento de upsert é modificado para inserir ou substituir o documento. A seção mais adiante sobre o nível de compatibilidade 1.2 descreve ainda mais esse comportamento.
Se o documento JSON de entrada tiver um campo ID existente, esse campo será usado automaticamente como a coluna ID do Documento no Azure Cosmos DB. Todas as gravações subsequentes serão tratadas como tais, levando a uma destas situações:
- IDs exclusivas levam à inserção.
- IDs duplicadas e ID do Documento definidas para ID levam ao upsert.
- IDs duplicadas e ID do Documento não definidas levam a erros após o primeiro documento.
Se você quiser salvar todos os documentos, incluindo aqueles que têm uma ID duplicada, renomeie o campo ID em sua consulta (usando a palavra-chave AS). Permita que o Azure Cosmos DB crie o campo ID ou substitua a ID pelo valor de outra coluna (usando a palavra-chave AS ou a configuração da ID do Documento).
Particionamento de dados no Azure Cosmos DB
O Azure Cosmos DB dimensiona automaticamente as partições com base em sua carga de trabalho. Portanto, recomendamos que você use contêineres ilimitados para particionar seus dados. Quando o Stream Analytics grava em contêineres ilimitados, ele usa tanto gravadores paralelos quanto a etapa de consulta anterior ou um esquema de particionamento de entrada.
Observação
O Azure Stream Analytics dá suporte apenas a contêineres ilimitadas com chaves de partição no nível superior. Por exemplo, /region tem suporte. Não há suporte para chaves de partição aninhadas (por exemplo, /region/name).
Dependendo de sua escolha de chave de partição, você pode receber este aviso:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
É importante escolher uma propriedade de chave de partição que tenha um número de valores distintos e permita distribuir sua carga de trabalho uniformemente entre esses valores. Como um artefato natural de particionamento, as solicitações que envolvem a mesma chave de partição são limitadas pela taxa de transferência máxima de uma única partição.
O tamanho de armazenamento para documentos que pertencem ao mesmo valor de chave de partição é limitado a 20 GB (o limite de tamanho da partição física é de 50 GB). Uma chave de partição ideal é aquela que é exibida com frequência, como um filtro em suas consultas, e tem cardinalidade suficiente para garantir que sua solução seja escalonável.
As chaves de partição usadas para consultas de Stream Analytics e para o Azure Cosmos DB não precisam ser idênticas. Topologias totalmente paralelas recomendadas usando a chave de Partição de Entrada , PartitionId, como chave de partição da consulta do Stream Analytics, mas essa pode não ser a opção recomendada para uma chave de partição do contêiner do Azure Cosmos DB.
Uma chave de partição também é o limite para transações em procedimentos armazenados e gatilhos para o Azure Cosmos DB. Você deve escolher uma chave de partição para que os documentos que ocorrem simultaneamente em transações compartilhem o mesmo valor de chave de partição. O artigo Particionamento no Azure Cosmos DB fornece mais detalhes sobre como escolher uma chave de partição.
Para os contêineres fixos do Azure Cosmos DB, o Stream Analytics não permite escalar na vertical nem na horizontal depois que estão cheios. Eles têm um limite superior de 10 GB e uma taxa de transferência de 10.000 RU/s. Para migrar dados de um contêiner fixo para um contêiner ilimitado (por exemplo, um com pelo menos 1.000 RU/s e uma chave de partição), use a ferramenta de migração de dados ou a biblioteca de feed de alterações.
A capacidade de gravar em múltiplos contêineres fixos está sendo descontinuada. Não recomendamos isso para escalar horizontalmente seu trabalho do Stream Analytics.
Desempenho aprimorado com nível de compatibilidade 1.2
Com o nível de compatibilidade 1.2, o Stream Analytics dá suporte à integração nativa para gravação em massa no Azure Cosmos DB. Essa integração permite gravar com eficiência no Azure Cosmos DB enquanto maximiza a taxa de transferência e manipula com eficiência as solicitações de limitação.
O mecanismo de gravação aprimorado está disponível em um novo nível de compatibilidade devido a uma diferença no comportamento de upsert. Com os níveis anteriores a 1.2, o comportamento de upsert é inserir ou mesclar o documento. Com 1.2, o comportamento de upsert é modificado para inserir ou substituir o documento.
Com os níveis anteriores a 1.2, o Stream Analytics usa um procedimento armazenado personalizado para fazer o upsert em massa nos documentos por chave de partição no Azure Cosmos DB. Lá, um lote é registrado como uma transação. Mesmo quando um único registro atinge um erro transitório (limitação), todo o lote precisa ser repetido. Esse comportamento torna relativamente lentos até mesmo os cenários com limitação razoável.
O exemplo a seguir mostra dois trabalhos de Stream Analytics idênticos lendo da mesma entrada dos Hubs de Eventos do Azure. Ambos os trabalhos de Stream Analytics são totalmente particionados, utilizando uma consulta tipo pass-through e gravam em contêineres idênticos do Azure Cosmos DB. As métricas à esquerda são do trabalho configurado com o nível de compatibilidade 1.0. As métricas à direita são configuradas com 1.2. Uma chave de partição do contêiner do Azure Cosmos DB é um GUID exclusivo proveniente do evento de entrada.
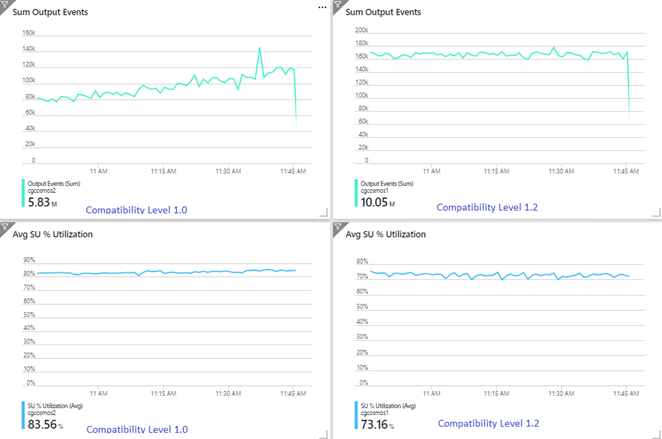
A taxa de eventos de entrada nos Hubs de Eventos é duas vezes maior que os contêineres do Azure Cosmos DB (20.000 RUs) são configurados para receberem, portanto, é esperada uma limitação no Azure Cosmos DB. No entanto, o trabalho com 1.2 está gravando consistentemente em uma taxa de transferência mais alta (eventos de saída por minuto) e uma menor utilização média de UA%. Em seu ambiente, essa diferença dependerá de mais alguns fatores. Esses fatores incluem opções do formato de evento, tamanho do evento/mensagem de entrada, chaves de partição e consulta.
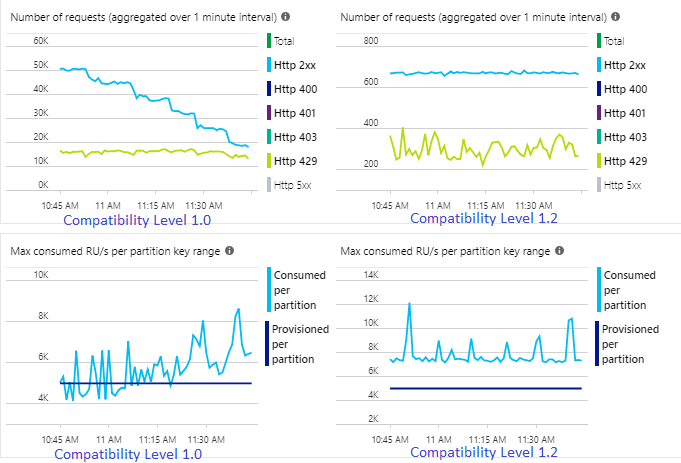
Com 1.2, o Stream Analytics é mais inteligente na utilização de 100% da taxa de transferência disponível no Azure Cosmos DB com poucos reenvios de limitação ou limitação de taxa. Esse comportamento fornece uma experiência melhor para outras cargas de trabalho, como consultas em execução no contêiner ao mesmo tempo. Se você quiser ver como o Stream Analytics é escalado horizontalmente com o Azure Cosmos DB como um coletor de 1.000 a 10.000 mensagens por segundo, experimente este projeto de exemplo do Azure.
A taxa de transferência da saída do Azure Cosmos DB é idêntica nos níveis 1.0 e 1.1. É altamente recomendável que você use o nível de compatibilidade 1.2 no Stream Analytics com o Azure Cosmos DB.
Configurações do Azure Cosmos DB para a saída em JSON
O uso do Azure Cosmos DB como uma saída no Stream Analytics gera o prompt a seguir para obter informações.
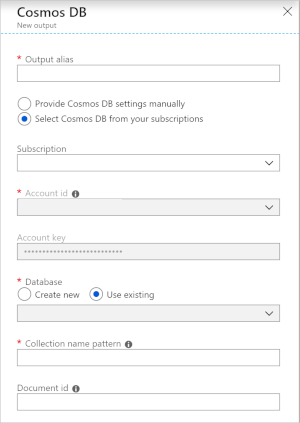
| Campo | Descrição |
|---|---|
| Alias de saída | Um apelido para se referir a essa saída na sua consulta de Stream Analytics. |
| Assinatura | A assinatura do Azure. |
| ID da Conta | O nome ou o URI do ponto de extremidade da conta do Azure Cosmos DB. |
| Chave de conta | A chave de acesso compartilhado da conta do Azure Cosmos DB. |
| Banco de dados | O nome do banco de dados do Azure Cosmos DB. |
| Nome do contêiner | O nome do contêiner, como MyContainer. Um contêiner chamado MyContainer deve existir. |
| ID do documento | Opcional. O nome da coluna em eventos de saída usado como a chave exclusiva que inserir ou atualizar as operações que devem ser baseadas. Se ficar vazio, todos os eventos serão inseridos, com nenhuma opção de atualização. |
Depois de configurar a saída do Azure Cosmos DB, você pode usá-la na consulta como o destino de uma na instrução INTO. Quando está usando uma saída do Azure Cosmos DB dessa forma, uma chave de partição precisa ser definida explicitamente.
O registro da saída deve conter uma coluna que diferencia maiúsculas de minúsculas, denominada segundo a chave de partição no Azure Cosmos DB. Para ter maior paralelização, a instrução pode exigir uma cláusula PARTITION BY que usa a mesma coluna.
Aqui está um exemplo de consulta:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Tratamento de erros e novas tentativas
Se ocorrer uma falha transitória, indisponibilidade de serviço ou limitação enquanto o Stream Analytics estiver enviando eventos para o Azure Cosmos DB, o Stream Analytics fará novas tentativas indefinidamente para concluir a operação com êxito. Mas ele não faz novas tentativas para as seguintes falhas:
- Não autorizado (código de erro HTTP 401)
- NotFound (código de erro HTTP 404)
- Forbidden (código de erro HTTP 403)
- BadRequest (código de erro HTTP 400)
Problemas comuns
Uma restrição de índice exclusivo é adicionada à coleção e os dados de saída do Stream Analytics violam essa restrição. Certifique-se de que os dados de saída do Stream Analytics não violem restrições de unicidade nem removam essas restrições. Para obter mais informações, consulte Restrições de chaves exclusivas no Azure Cosmos DB.
A coluna
PartitionKeynão existe.A coluna
Idnão existe.