Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial com base de data lake, arquitetura pronta para o futuro, IA integrada e novos recursos. Se você não estiver familiarizado com o data warehouse, comece com Fabric Data Warehouse. As cargas de trabalho existentes de pools de SQL dedicados podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
No pool de SQL dedicado, as exibições materializadas fornecem um método de baixa manutenção para consultas analíticas complexas obterem um desempenho rápido sem nenhuma alteração de consulta. Este artigo discute as diretrizes gerais sobre como usar visões materializadas.
Visões materializadas versus visões padrão
O pool de SQL dá suporte a exibições padrão e materializadas. Ambas são tabelas virtuais criadas com expressões SELECT e apresentadas a consultas como tabelas lógicas. As exibições revelam a complexidade da computação de dados comum e adicionam uma camada de abstração às alterações de computação para que não haja necessidade de reescrever consultas.
Uma exibição padrão calcula seus dados sempre que a exibição é usada. Não há dados armazenados em disco. Normalmente, as pessoas usam exibições padrão como uma ferramenta que ajuda a organizar os objetos lógicos e consultas em um banco de dados. Para usar uma exibição padrão, uma consulta precisa fazer referência direta a ela.
Uma exibição materializada pré-computa, armazena e mantém seus dados no pool de SQL dedicado, assim como uma tabela. A recomputação não é necessária sempre que uma exibição materializada é usada. É por isso que consultas que usam todos ou um subconjunto dos dados em exibições materializadas podem obter um desempenho mais rápido. Melhor ainda, as consultas podem usar uma exibição materializada sem fazer referência direta a ela, portanto, não é necessário alterar o código do aplicativo.
A maioria dos requisitos de exibição padrão ainda se aplicam a uma exibição materializada. Para obter detalhes sobre a sintaxe de exibição materializada e outros requisitos, consulte CREATE MATERIALIZED VIEW AS SELECT.
| Comparação | View | Visão Materializada |
|---|---|---|
| Visualizar definição | Armazenado no data warehouse do Azure. | Armazenado no data warehouse do Azure. |
| Exibir conteúdo | Gerado a cada vez que a visualização é utilizada. | Pré-processado e armazenado no data warehouse do Azure durante a criação da exibição. Atualizado à medida que os dados são adicionados às tabelas subjacentes. |
| Atualização de dados | Sempre atualizado | Sempre atualizado |
| Velocidade para recuperar dados de visualização de consultas complexas | Lento | Rápido |
| Armazenamento extra | No | Sim |
| Sintaxe | CREATE VIEW | CRIAR VISÃO MATERIALIZADA COMO SELECT |
Benefícios das visões materializadas
Uma visão materializada adequadamente projetada fornece os seguintes benefícios:
Tempo de execução reduzido para consultas complexas com JOINs e funções de agregação. Quanto mais complexa a consulta, maior o potencial de economia de tempo de execução. O maior benefício é obtido quando o custo de computação de uma consulta é alto e o conjunto de dados resultante é pequeno.
O otimizador de consulta no pool de SQL dedicado pode usar automaticamente visões materializadas implantadas para melhorar os planos de execução de consulta. Esse processo é transparente para os usuários que fornecem um desempenho de consulta mais rápido e não exige que as consultas façam referência direta às exibições materializadas.
Requer pouca manutenção nas vistas. Uma exibição materializada armazena dados em dois locais, um índice columnstore clusterizado para os dados iniciais no momento da criação da exibição e um repositório delta para as alterações de dados incrementais. Todas as alterações de dados das tabelas base são adicionadas automaticamente ao repositório delta de maneira síncrona. Um processo em segundo plano (movedor de tuplas) move periodicamente os dados do armazenamento delta para o índice columnstore da exibição. Esse design permite que a consulta de exibições materializadas retorne os mesmos dados que consultar diretamente as tabelas base.
Os dados em uma exibição materializada podem ser distribuídos de forma diferente das tabelas base.
Os dados em exibições materializadas obtém os mesmos benefícios de alta disponibilidade e resiliência que os dados em tabelas regulares.
Em comparação com outros provedores de data warehouse, as exibições materializadas implementadas no pool de SQL dedicado também fornecem os seguintes benefícios adicionais:
- Atualização automática e síncrona de dados com alterações de dados em tabelas base. Não é necessária nenhuma ação do usuário.
- Suporte amplo à função de agregação. Consulte CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- Suporte para recomendação de visualização materializada específica de consulta. Consulte EXPLAIN (Transact-SQL).
Cenários comuns
As visões materializadas tipicamente são usadas nos seguintes cenários:
Precisa melhorar o desempenho de consultas analíticas complexas em relação a dados grandes em tamanho
Consultas analíticas complexas geralmente usam mais funções de agregação e junções de tabelas, causando operações mais pesadas em termos de computação, como embaralhamentos e junções na execução de consultas. É por isso que essas consultas levam mais tempo para serem concluídas, especialmente em tabelas grandes.
Os usuários podem criar exibições materializadas para os dados retornados dos cálculos comuns de consultas, portanto, não há nenhuma recomputação necessária quando esses dados são necessários por consultas, permitindo menor custo de computação e resposta de consulta mais rápida.
Precisa de um desempenho mais rápido sem ou com mínimas alterações na consulta
As alterações de esquema e consulta em data warehouses normalmente são mantidas ao mínimo para dar suporte a operações e relatórios de ETL regulares. As pessoas podem usar exibições materializadas para ajuste de desempenho de consulta se o custo incorrido pelas exibições puder ser compensado pelo ganho no desempenho da consulta.
Em comparação com outras opções de ajuste, como dimensionamento e gerenciamento de estatísticas, é uma mudança de produção muito menos impactante para criar e manter uma exibição materializada e seu potencial ganho de desempenho também é maior.
- Criar ou manter visualizações materializadas não afeta as consultas executadas nas tabelas base.
- O otimizador de consulta pode usar automaticamente as exibições materializadas implantadas sem referência de exibição direta em uma consulta. Esse recurso reduz a necessidade de alterações de consulta no ajuste de desempenho.
Precisa de uma estratégia de distribuição de dados diferente para um desempenho de consulta mais rápido
O data warehouse do Azure é um sistema de processamento paralelo e massivamente distribuído (MPP).
O Synapse SQL é um sistema de consulta distribuída que permite que as empresas implementem cenários de data warehousing e virtualização de dados usando experiências T-SQL padrão familiares aos engenheiros de dados. Ele também expande os recursos do SQL para lidar com cenários de streaming e machine learning. Os dados em uma tabela de data warehouse são distribuídos entre 60 nós usando uma das três estratégias de distribuição (hash, round_robin ou replicadas).
A distribuição de dados é especificada no momento da criação da tabela e permanece inalterada até que a tabela seja descartada. A visualização materializada, sendo uma tabela virtual em disco, suporta distribuições de dados hash e round_robin. Os usuários podem escolher uma distribuição de dados diferente das tabelas base, mas ideal para o desempenho de consultas que usam frequentemente as exibições.
Diretrizes de design
Aqui está a orientação geral sobre como usar exibições materializadas para melhorar o desempenho da consulta:
Projeto para sua carga de trabalho
Antes de começar a criar exibições materializadas, é importante ter uma compreensão profunda da carga de trabalho em termos de padrões de consulta, importância, frequência e tamanho dos dados resultantes.
Os usuários podem executar EXPLAIN WITH_RECOMMENDATIONS <SQL_statement> para as exibições materializadas recomendadas pelo otimizador de consulta. Como essas recomendações são específicas de consulta, uma exibição materializada que beneficia uma única consulta pode não ser ideal para outras consultas na mesma carga de trabalho.
Avalie essas recomendações com suas necessidades de carga de trabalho em mente. As visões materializadas ideais são aquelas que beneficiam o desempenho da carga de trabalho.
Esteja ciente da compensação entre consultas mais rápidas e o custo
Para cada exibição materializada, há um custo de armazenamento de dados e um custo para manter a exibição. À medida que os dados são alterados nas tabelas base, o tamanho da exibição materializada aumenta e sua estrutura física também muda.
Para evitar degradação do desempenho da consulta, cada exibição materializada é mantida separadamente pelo mecanismo de data warehouse, incluindo a movimentação de linhas do armazenamento delta para os segmentos de índice do armazenamento de colunas e a consolidação de alterações de dados.
A carga de trabalho de manutenção sobe mais quando o número de exibições materializadas e as alterações na tabela base aumentam. Os usuários devem verificar se o custo incorrido de todas as exibições materializadas pode ser compensado pelo ganho de desempenho da consulta.
Você pode executar esta consulta para obter a lista de vistas materializadas em um banco de dados.
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Opções para reduzir o número de exibições materializadas:
Identifique conjuntos de dados comuns frequentemente usados pelas consultas complexas em sua carga de trabalho. Crie exibições materializadas para armazenar esses conjuntos de dados para que o otimizador possa usá-los como blocos de construção ao criar planos de execução.
Remova as visões materializadas que têm baixo uso ou que não são mais necessárias. Uma visualização materializada desabilitada não é mantida, mas ainda incorre em custos de armazenamento.
Combine visualizações materializadas criadas nas mesmas tabelas base ou em tabelas semelhantes, mesmo que seus dados não se sobreponham. A combinação de exibições materializadas pode resultar em uma exibição maior em tamanho do que a soma das exibições separadas, no entanto, o custo de manutenção da exibição deve reduzir. Por exemplo:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Nem todo ajuste de desempenho requer alteração de consulta
O otimizador de data warehouse pode usar automaticamente as exibições materializadas implantadas para melhorar o desempenho da consulta. Esse suporte é aplicado de forma transparente a consultas que não fazem referência às exibições, e a consultas que usam agregações não suportadas na criação de exibições materializadas. Nenhuma alteração de consulta é necessária. É possível verificar o plano de execução estimado de uma consulta para confirmar se uma exibição materializada é usada.
- Para obter mais informações sobre como recuperar o plano de execução real, consulte Monitorar a carga de trabalho do pool de SQL dedicado do Azure Synapse Analytics usando DMVs.
- Você pode recuperar um plano de execução estimado por meio do SSMS (SQL Server Management Studio) ou do SET SHOWPLAN_XML.
Monitorar exibições materializadas
Uma exibição materializada é armazenada no data warehouse assim como uma tabela com o CCI (índice columnstore clusterizado). A leitura de dados de uma exibição materializada inclui a verificação do índice e a aplicação de alterações no armazenamento delta. Quando o número de linhas no repositório delta é muito alto, resolver uma consulta a partir de uma visão materializada pode levar mais tempo do que consultar diretamente as tabelas base.
Para evitar a degradação do desempenho da consulta, recomenda-se executar DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD para monitorar o overhead_ratio da exibição (total_rows/base_view_row). Se o overhead_ratio for muito alto, considere reconstruir a visualização materializada para que todas as linhas no armazenamento delta sejam movidas para o índice columnstore.
Exibição materializada e cache do conjunto de resultados
Esses dois recursos são introduzidos no pool de SQL dedicado aproximadamente ao mesmo tempo para otimização do desempenho de consultas. O cache do conjunto de resultados é usado para obter alta simultaneidade e tempos de resposta rápidos de consultas repetitivas em relação a dados estáticos.
Para usar o resultado armazenado em cache, a forma da consulta de solicitação de cache deve corresponder à consulta que produziu o cache. Além disso, o resultado armazenado em cache deve ser aplicado a toda a consulta.
Exibições materializadas permitem alterações de dados nas tabelas base. Os dados em visões materializadas podem ser aplicados a uma parte de uma consulta. Esse suporte permite que as mesmas exibições materializadas sejam usadas por consultas diferentes que compartilham alguma computação para um desempenho mais rápido.
Exemplo
Este exemplo usa uma consulta semelhante a TPCDS que localiza clientes que gastam mais dinheiro via catálogo do que em lojas. Ele também identifica os clientes preferenciais e seu país/região de origem. A consulta envolve selecionar os TOP 100 registros da UNION de três subinstruções SELECT envolvendo SUM() e GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Verifique o plano de execução estimado da consulta. Há 18 operações de embaralhamento e 17 de junção, que levam mais tempo para serem executadas.
Agora, vamos criar uma exibição materializada para cada uma das três instruções sub-SELECT.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Verifique o plano de execução da consulta original novamente. Agora o número de junções muda de 17 para 5 e não há mais embaralhamento. Selecione o ícone de operação Filtrar no plano. Sua Lista de Resultados mostra que os dados são lidos das visões materializadas em vez das tabelas base.
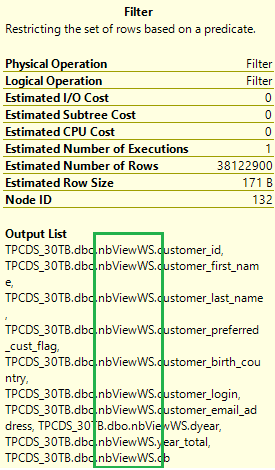
Com exibições materializadas, a mesma consulta é executada muito mais rapidamente sem nenhuma alteração de código.
Próximas Etapas
Para obter mais dicas de desenvolvimento, consulte Visão geral de desenvolvimento do SQL do Synapse.