Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial com base de data lake, arquitetura pronta para o futuro, IA integrada e novos recursos. Se você não estiver familiarizado com o data warehouse, comece com Fabric Data Warehouse. As cargas de trabalho existentes de pools de SQL dedicados podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste artigo, você aprenderá a consultar um arquivo CSV usando o pool de SQL sem servidor no Azure Synapse Analytics. Arquivos CSV podem ter diferentes formatos:
- Com e sem linha de cabeçalho
- Com valores delimitados por tabulação e vírgula
- Com terminações de linha de estilo do Windows e Unix
- Valores não citados e entre aspas e caracteres de escape
Todas essas variações serão abordadas abaixo.
Exemplo de Início Rápido
A função OPENROWSET permite que você leia o conteúdo do arquivo CSV fornecendo a URL do arquivo.
Ler um arquivo CSV
A maneira mais fácil de ver o conteúdo do seu arquivo CSV é fornecer a URL do arquivo para a função OPENROWSET, especificar o formato CSV em FORMAT e a versão 2.0 em PARSER_VERSION. Se o arquivo estiver publicamente disponível ou se sua identidade do Microsoft Entra puder acessar esse arquivo, você poderá ver o conteúdo do arquivo usando a consulta como esta mostrada no exemplo a seguir:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
A opção firstrow é usada para ignorar a primeira linha no arquivo CSV que representa o cabeçalho nesse caso. Verifique se você pode acessar este arquivo. Se o arquivo estiver protegido com a chave SAS ou a identidade personalizada, você precisará configurar a credencial no nível do servidor para o logon SQL.
Importante
Se o arquivo CSV contiver caracteres UTF-8, verifique se você está usando uma ordenação de banco de dados UTF-8 (por exemplo Latin1_General_100_CI_AS_SC_UTF8).
Uma incompatibilidade entre a codificação de texto no arquivo e no agrupamento pode causar erros inesperados de conversão.
É possível alterar facilmente o agrupamento padrão do banco de dados atual usando a seguinte instrução T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Uso da fonte de dados
O exemplo anterior usa o caminho completo para o arquivo. Como alternativa, você pode criar uma fonte de dados externa com a localização que aponta para a pasta raiz do armazenamento:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
É possível usar a fonte de dados criada e o caminho relativo para o arquivo na função OPENROWSET:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Se uma fonte de dados estiver protegida com a chave SAS ou a identidade personalizada, você poderá configurar a fonte de dados com a credencial no escopo do banco de dados.
Especificar explicitamente o esquema
OPENROWSET permite especificar explicitamente quais colunas você deseja ler no arquivo usando a cláusula WITH:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Os números após um tipo de dados na cláusula WITH representam o índice de coluna no arquivo CSV.
Importante
Se o arquivo CSV contiver caracteres UTF-8, verifique se você está especificando explicitamente alguma ordenação UTF-8 (por exemplo Latin1_General_100_CI_AS_SC_UTF8) para todas as colunas na WITH cláusula ou defina alguma ordenação UTF-8 no nível do banco de dados.
Uma incompatibilidade entre a codificação de texto no arquivo e no agrupamento pode causar erros inesperados de conversão.
É possível alterar facilmente o agrupamento padrão do banco de dados atual usando a seguinte instrução T-SQL:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Você pode definir facilmente a ordenação nos tipos de coluna usando a seguinte definição: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Nas seções a seguir, você aprenderá a consultar vários tipos de arquivos CSV.
Pré-requisitos
A primeira etapa é criar um banco de dados no qual as tabelas serão criadas. Em seguida, inicialize os objetos executando o script de instalação nesse banco de dados. Esse script de instalação criará as fontes de dados, as credenciais no escopo do banco de dados e os formatos de arquivo externos que são usados nessas amostras.
Nova linha de estilo Windows
A consulta a seguir mostra como ler um arquivo CSV sem uma linha de cabeçalho, com uma nova linha de estilo do Windows e colunas delimitadas por vírgula.
Visualização do arquivo:
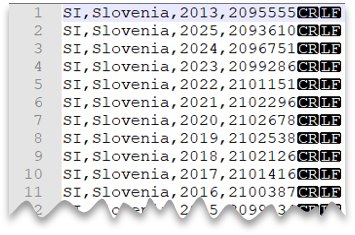
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nova linha de estilo UNIX
A consulta a seguir mostra como ler um arquivo CSV sem uma linha de cabeçalho, com uma nova linha de estilo Unix e colunas delimitadas por vírgula. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
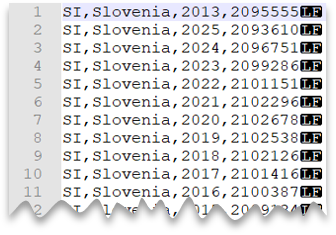
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Linha de cabeçalho
A consulta a seguir mostra como ler um arquivo com uma linha de cabeçalho, usando uma nova linha estilo Unix e colunas delimitadas por vírgula. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
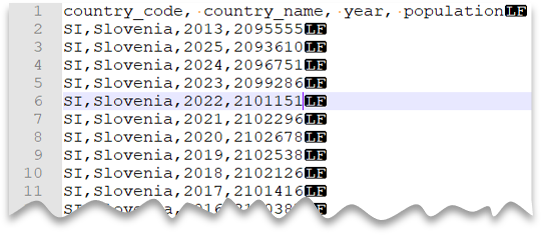
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
A opção HEADER_ROW = TRUE resultará na leitura dos nomes das colunas da linha de cabeçalho do arquivo. É ótimo para fins de exploração quando você não está familiarizado com o conteúdo do arquivo. Para obter o melhor desempenho, consulte a seção Usar tipos de dados apropriados nas práticas recomendadas. Além disso, você pode ler mais sobre a sintaxe OPENROWSET aqui.
Caractere de aspas personalizado
A consulta a seguir mostra como ler um arquivo com uma linha de cabeçalho, com uma nova linha de estilo UNIX, com colunas delimitadas por vírgula e valores entre aspas. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
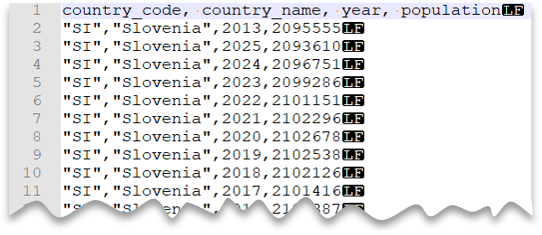
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Observação
Essa consulta retornaria os mesmos resultados se o parâmetro FIELDQUOTE fosse omitido, pois FIELDQUOTE tem como valor padrão as aspas duplas.
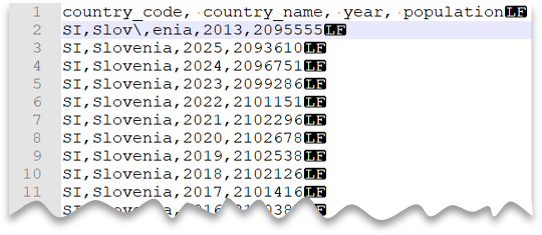
Caracteres de escape
A consulta a seguir mostra como ler um arquivo com uma linha de cabeçalho, com uma nova linha de estilo UNIX, colunas delimitadas por vírgula e um caractere de escape usado pelo delimitador de campo (vírgula) dentro dos valores. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Observação
Essa consulta falharia se ESCAPECHAR não fosse especificado, uma vez que a vírgula em "Slov,enia" seria tratada como delimitador de campo em vez de parte do nome do país/região. Nesse caso, "Slov,enia" seria tratada como duas colunas. Ou seja, a linha específica teria uma coluna a mais que as outras linhas, e uma coluna a mais que o definido na cláusula WITH.
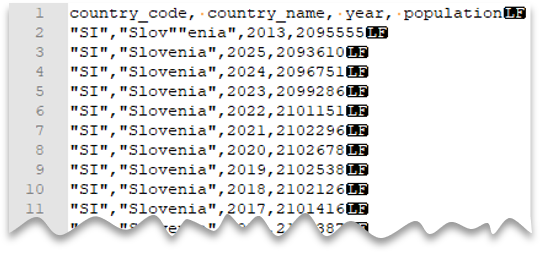
Caracteres de aspas com escape
A consulta a seguir mostra como ler um arquivo com uma linha de cabeçalho, com uma nova linha no estilo UNIX, colunas delimitadas por vírgula e um caractere de aspas duplas com escape dentro dos valores. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Observação
O caractere de aspas deve ter escape com outro caractere de aspas. O caractere de aspas poderá aparecer no valor da coluna somente se o valor for encapsulado com caracteres de aspas.
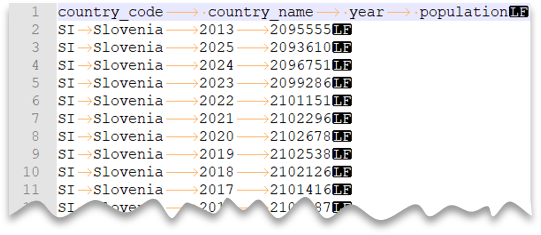
Arquivos delimitados por tabulação
A consulta a seguir mostra como ler um arquivo CSV com uma linha de cabeçalho, com uma nova linha de estilo Unix e colunas delimitadas por tabulação. Observe que o arquivo está em um local diferente, quando comparado a outros exemplos.
Visualização do arquivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Retornar um subconjunto de colunas
Até agora, você especificou um esquema de arquivo CSV usando a cláusula WITH e listando todas as colunas. Você só pode especificar as colunas que realmente precisa em sua consulta usando um número ordinal para cada coluna necessária. Colunas não relevantes serão omitidas.
A consulta a seguir retorna o número de nomes de país/região distintos em um arquivo, especificando apenas as colunas necessárias:
Observação
Dê uma olhada na cláusula WITH na consulta abaixo e observe que há um valor "2" (sem aspas) no final da linha em que coluna [country_name] é definida. Isso significa que a coluna [country_name] é a segunda coluna no arquivo. A consulta ignorará todas as colunas no arquivo, exceto a segunda.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Como consultar arquivos acrescentáveis
Os arquivos CSV usados na consulta não devem ser alterados enquanto a consulta está em execução. Na consulta de execução longa, o pool de SQL pode fazer novas tentativas de leitura, ler partes dos arquivos ou até mesmo ler o arquivo várias vezes. Alterações no conteúdo dos arquivos causariam resultados errados. Portanto, o pool de SQL falhará na consulta se detectar que o tempo de modificação de qualquer arquivo é alterado durante a execução da consulta.
Em alguns cenários, é melhor ler os arquivos que são acrescentados constantemente. Para evitar falhas de consulta devido a arquivos que são acrescentados constantemente, você pode permitir que a função OPENROWSET ignore as leituras possivelmente inconsistentes usando a configuração ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
A opção de leitura ALLOW_INCONSISTENT_READS desabilitará a verificação de tempo de modificação do arquivo durante o ciclo de vida da consulta e lerá o que estiver disponível no arquivo. Nos arquivos anexáveis, o conteúdo existente não é atualizado e apenas novas linhas são adicionadas. Portanto, a probabilidade de resultados errados é minimizada em comparação com os arquivos atualizáveis. Essa opção pode permitir que você leia os arquivos acrescentados com frequência sem precisar lidar com os erros. Na maioria dos cenários, o pool de SQL vai ignorar apenas algumas linhas que são acrescentadas aos arquivos durante a execução da consulta.
Conteúdo relacionado
Os próximos artigos mostrarão como: