Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
As políticas de rede fornecem microssegmentação para pods da mesma forma que os NSGs (Grupos de Segurança de Rede) fornecem para VMs. A implementação do Gerenciador de Políticas de Rede do Azure é compatível com a especificação de política de rede de Kubernetes padrão. É possível usar rótulos para selecionar um grupo de pods e definir uma lista de regras de entrada e saída que filtram o tráfego de e para esses pods. Saiba mais sobre as políticas de rede do Kubernetes na documentação do Kubernetes.
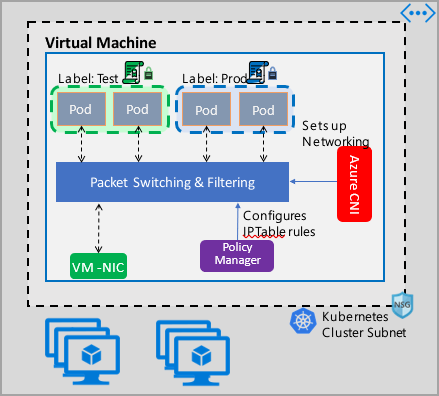
A implementação do Gerenciador de Políticas de Rede do Azure funciona com a CNI do Azure que fornece a integração de rede virtual para contêineres. Há suporte para o Gerenciador de Políticas de Rede no Linux e no Windows Server. A implementação impõe a filtragem de tráfego configurando as regras de permissão e negação de IP com base nas políticas definidas em Linux IPTables ou ACLPolicies do HNS (Serviço de Rede Host) para Windows Server.
Planejar a segurança para o cluster Kubernetes
Ao implementar a segurança para o cluster, use grupos de segurança de rede (NSGs) para filtrar o tráfego que entra e sai da sub-rede do cluster (tráfego Norte-Sul). Use o Gerenciador de Políticas de Rede do Azure para o tráfego entre pods no seu cluster (tráfego Leste-Oeste).
Usando o Gerenciador de Políticas de Rede do Azure
O Gerenciador de Políticas de Rede do Azure pode ser usado das maneiras a seguir para fornecer microssegmentação para pods.
AKS (Serviço de Kubernetes do Azure)
O Gerenciador de Políticas de Rede está disponível nativamente no AKS e pode ser habilitado no momento da criação do cluster.
Para saber mais, confira Proteger o tráfego entre os pods usando as políticas de rede no AKS (Serviço de Kubernetes do Azure).
Clusters Kubernetes Faça você mesmo (DIY) no Azure
Para cluster DIY, instale primeiro o plug-in do CNI e o habilite em todas as máquinas virtuais em um cluster. Para ver instruções detalhadas, confira Implantar o plug-in em um cluster Kubernetes que você implanta por conta própria.
Depois que o cluster for implantado, execute o seguinte comando kubectl para baixar e aplicar o daemon set do Gerenciador de Políticas de Rede do Azure ao cluster.
Para Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Para Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
A solução também é um software livre e o código está disponível no repositório da Rede de Contêiner do Azure.
Monitorar e visualizar as configurações de rede com o Azure NPM
O Gerenciador de Políticas de Rede do Azure inclui métricas do Prometheus informativas que permitem monitorar e entender melhor suas configurações. Ele fornece visualizações internas no portal do Azure ou nos Laboratórios do Grafana. Você pode começar a coletar essas métricas usando o Azure Monitor ou um servidor Prometheus.
Benefícios das métricas do Gerenciador de Políticas de Rede do Azure
Os usuários anteriormente só podiam aprender sobre a configuração de rede com os comandos iptables e ipset executados dentro de um nó de cluster, o que resulta em uma saída detalhada e difícil de entender.
No geral, as métricas fornecem:
Contagens de políticas, regras de ACL, ipsets, entradas de ipset e entradas em qualquer ipset determinado
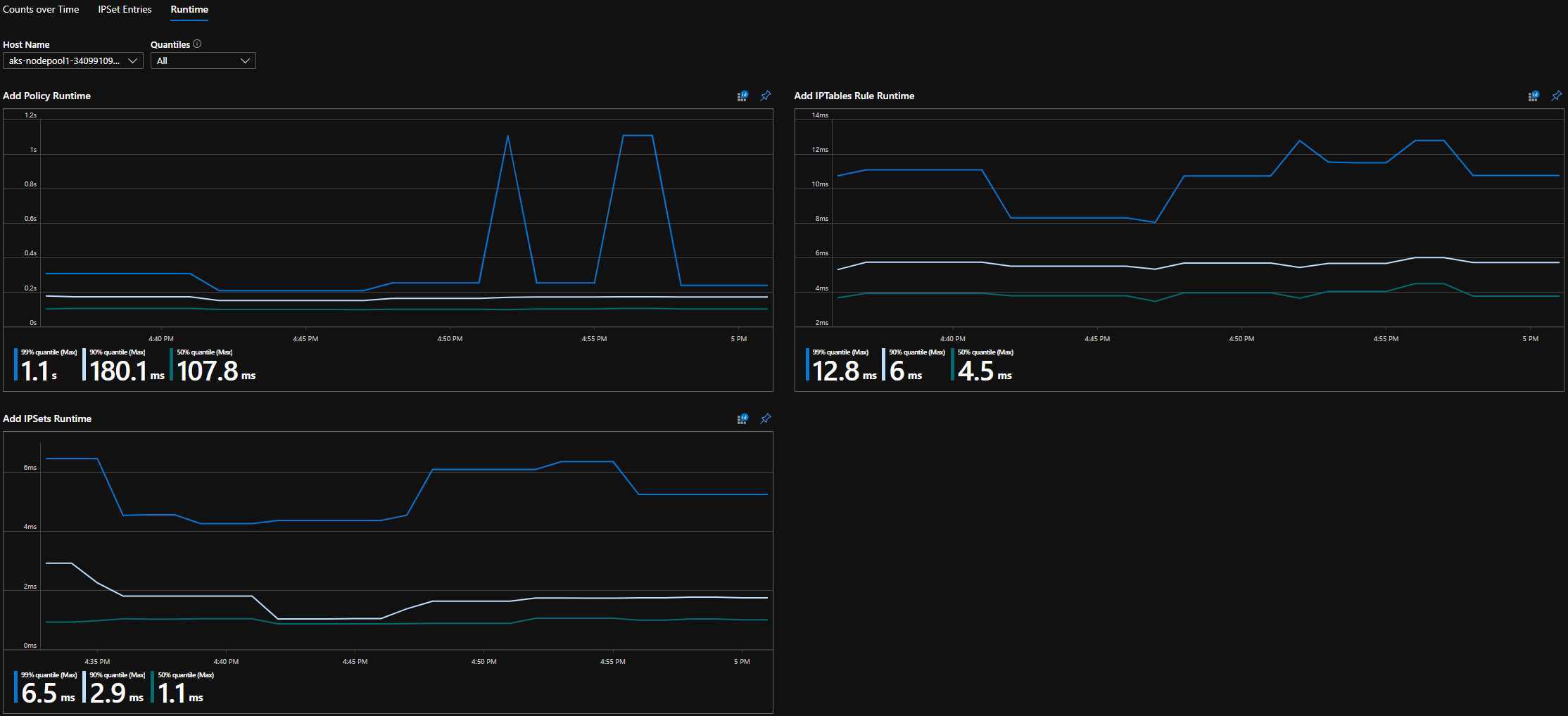
Tempos de execução para chamadas individuais do sistema operacional e para lidar com eventos de recurso do kubernetes (mediana, percentil 90º e percentil 99º)
Informações de falha para lidar com eventos de recurso do kubernetes (esses eventos de recurso falharão quando uma chamada do sistema operacional falhar)
Exemplo de casos de uso de métricas
Alertas por meio de um Prometheus AlertManager
Veja uma configuração para esses alertas conforme a seguir.
Alerta quando um Gerenciador de Políticas de Rede tem uma falha com uma chamada do sistema operacional ou ao traduzir uma política de rede.
Alerta quando o tempo médio para aplicar alterações a um evento de criação foi de mais de 100 milissegundos.
Visualizações e depuração por meio do painel do Grafana ou da pasta de trabalho do Azure Monitor
Veja quantas regras de IPTables suas políticas criam (ter uma grande quantidade de regras de IPTables pode aumentar ligeiramente a latência).
Correlacionar as contagens de cluster (por exemplo, ACLs) aos tempos de execução.
Obter o nome amigável de um ipset em uma determinada regra de IPTables (por exemplo,
azure-npm-487392representapodlabel-role:database).
Todas as métricas suportadas
A lista a seguir possui as métricas com suporte. Qualquer rótulo quantile tem valores possíveis 0.5, 0.9e 0.99. Qualquer rótulo had_error tem valores possíveis false e true, representando se a operação foi bem-sucedida ou falhou.
| Nome da métrica | Descrição | Tipo de métrica Prometheus | Rótulos |
|---|---|---|---|
npm_num_policies |
número de políticas de rede | Medidor | - |
npm_num_iptables_rules |
número de regras IPTables | Medidor | - |
npm_num_ipsets |
número de IPSets | Medidor | - |
npm_num_ipset_entries |
número de entradas de endereço de IP em todos os IPSets | Medidor | - |
npm_add_iptables_rule_exec_time |
tempo de execução para adicionar uma regra IPTables | Resumo | quantile |
npm_add_ipset_exec_time |
tempo de execução para adicionar um IPSet | Resumo | quantile |
npm_ipset_counts (avançado) |
número de entradas dentro de cada IPSet individual | GaugeVec |
set_name & set_hash |
npm_add_policy_exec_time |
tempo de execução para adicionar uma política de rede | Resumo |
quantile & had_error |
npm_controller_policy_exec_time |
tempo de execução para atualizar/excluir uma política de rede | Resumo |
quantile e had_error e operation (com valores update ou delete) |
npm_controller_namespace_exec_time |
runtime para criar/atualizar/excluir um namespace | Resumo |
quantile e had_error e operation (com valores create, update ou delete) |
npm_controller_pod_exec_time |
runtime para criar/atualizar/excluir um pod | Resumo |
quantile e had_error e operation (com valores create, update ou delete) |
Também há uma métrica "exec_time_count" e "exec_time_sum" para cada métrica de Resumo "exec_time".
As métricas podem ser recortadas por meio do Azure Monitor para Contêineres ou por meio de Prometheus.
Configure o Azure Monitor
A primeira etapa é habilitar o Azure Monitor para contêineres para o cluster Kubernetes. As etapas podem ser encontradas na Visão geral do Azure Monitor para contêineres. Quando o Azure Monitor para contêineres estiver habilitado, configure o ConfigMap do Azure Monitor para contêineres para habilitar a integração do Gerenciador de Políticas de Rede e a coleta de métricas do Gerenciador de Políticas de Rede do Prometheus.
O ConfigMap do Azure Monitor para contêineres tem uma seção integrations com configurações para coletar métricas do Gerenciador de Políticas de Rede.
Essas configurações são desabilitadas por padrão no ConfigMap. A habilitação da configuração básica collect_basic_metrics = true coleta métricas básicas do Gerenciador de Políticas de Rede. A habilitação da configuração avançada collect_advanced_metrics = true coleta métricas avançadas, além de métricas básicas.
Depois de editar o ConfigMap, salve-o localmente e aplique o ConfigMap ao cluster da seguinte maneira.
kubectl apply -f container-azm-ms-agentconfig.yaml
O snippet de código a seguir é do ConfigMap do Azure Monitor para contêineres, que mostra a integração do Gerenciador de Políticas de Rede habilitada com a coleta de métricas avançadas.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
As métricas avançadas são opcionais e ligá-las ativará automaticamente a coleta de métricas básicas. As métricas avançadas atualmente incluem apenas Network Policy Manager_ipset_counts.
Saiba mais sobre as configurações de coleta do Azure Monitor para contêineres no mapa de configurações.
Opções de visualização para o Azure Monitor
Quando a coleta de métricas do Gerenciador de Políticas de Rede estiver habilitada, você poderá exibir as métricas no portal do Azure usando o insights do contêiner ou no Grafana.
Exibir no portal do Azure em insights para o cluster
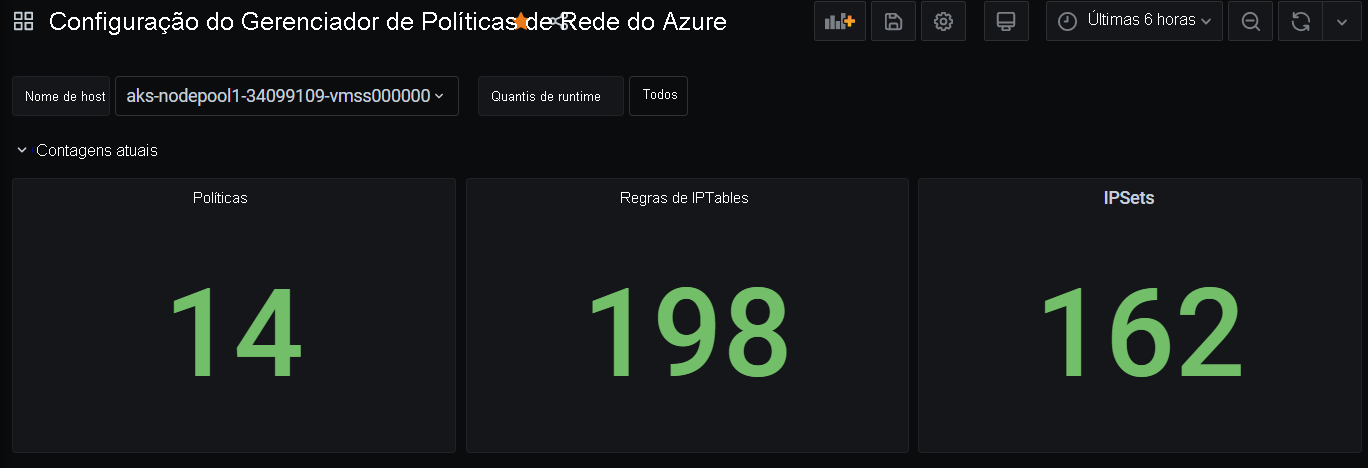
Abra o portal do Azure. Quando estiver nos insights do cluster, navegue até Pastas de Trabalho e abra Configuração do Gerenciador de Políticas de Rede (Gerenciador de Políticas de Rede).
Além de exibir a pasta de trabalho, você também pode consultar diretamente as métricas do Prometheus em “Logs” na seção insights. Por exemplo, essa consulta retorna todas as métricas que estão sendo coletadas.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Você também pode consultar diretamente a análise de logs para as métricas. Para obter mais informações, veja Introdução a Consultas do Log Analytics.
Exibir no painel do Grafana
Configure o servidor Grafana e uma fonte de dados de análise de logs conforme descrito aqui. Em seguida, importe o Painel do Grafana com um back-end do Log Analytics para seus Laboratórios do Grafana.
O painel tem visuais semelhantes à Pasta de trabalho do Azure. Você pode adicionar painéis para gráficos e visualizar métricas do Gerenciador de Políticas de Rede na tabela InsightsMetrics.
Configurar para o servidor Prometheus
Alguns usuários podem optar por coletar métricas com um servidor Prometheus em vez do Azure Monitor para contêineres. Basta você adicionar dois trabalhos à sua configuração de recorte para coletar métricas do Gerenciador de Políticas de Rede.
Para instalar um servidor Prometheus, adicione este repositório do Helm no cluster:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
em seguida, adicione um servidor
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
em que prometheus-server-scrape-config.yaml é formado por:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Você também pode substituir o trabalho azure-npm-node-metrics pelo conteúdo abaixo ou incorporá-lo a um trabalho já existente para os pods do Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Configurar alertas para AlertManager
Se você usar um servidor Prometheus, poderá configurá um AlertManager da mesma forma. Aqui está uma configuração de exemplo para as duas regras de alerta descrita acima:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Opções de visualização para Prometheus
Ao usar um servidor Prometheus, somente o painel do Grafana é compatível.
Se você ainda não fez isso, configure o servidor Grafana e defina uma fonte de dados do Prometheus. Em seguida, importe o Painel do Grafana com um back-end do Prometheus para seus Laboratórios do Grafana.
Os elementos visuais desse painel são idênticos ao painel com um back-end do insights de contêiner/análise de logs.
Painéis de exemplo
A seguir estão alguns painéis de exemplo para métricas do Gerenciador de Políticas de Rede em insights de contêiner (CI) e Grafana.
Contagens de resumo de CI
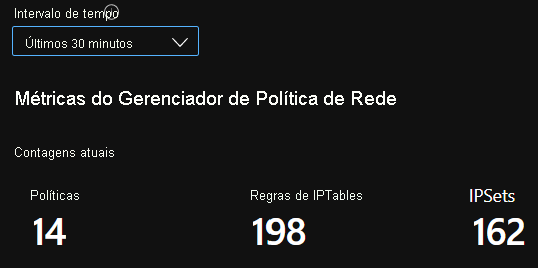
Contagens de CI ao longo do tempo

Entradas de IPSet de CI

Quantis de runtime de CI
Contagens de resumo do painel do Grafana
Contagens do painel do Grafana ao longo do tempo

Entradas IPSet do painel do Grafana

Quantis de runtime do painel do Grafana

Próximas etapas
Saiba mais sobre Serviço de Kubernetes do Azure.
Saiba mais sobre redes de contêiner.
Implante o plug-in para clusters Kubernetes ou contêineres do Docker.