Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Dica
Esse conteúdo é um trecho do eBook, arquitetura de microsserviços do .NET para aplicativos .NET em contêineres, disponível em do .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Os componentes de persistência de dados fornecem acesso aos dados hospedados dentro dos limites de um microsserviço (ou seja, o banco de dados de um microsserviço). Eles contêm a implementação real de componentes, como repositórios e classes de Unidade de Trabalho , como objetos personalizados do EF DbContext (Entity Framework). O EF DbContext implementa os padrões do Repositório e da Unidade de Trabalho.
O padrão de repositório
O padrão de repositório é um padrão de design Domain-Driven destinado a manter as preocupações de persistência fora do modelo de domínio do sistema. Uma ou mais abstrações de persistência - interfaces - são definidas no modelo de domínio e essas abstrações têm implementações na forma de adaptadores específicos de persistência definidos em outro lugar no aplicativo.
As implementações do repositório são classes que encapsulam a lógica necessária para acessar fontes de dados. Eles centralizam a funcionalidade de acesso a dados comum, fornecendo melhor capacidade de manutenção e desassociando a infraestrutura ou a tecnologia usada para acessar bancos de dados do modelo de domínio. Se você usar um Object-Relational Mapper (ORM) como o Entity Framework, o código que deve ser implementado será simplificado, graças ao LINQ e à tipagem forte. Isso permite que você se concentre na lógica de persistência de dados em vez de no encanamento de acesso a dados.
O padrão de repositório é uma maneira bem documentada de trabalhar com uma fonte de dados. No livro Padrões da Arquitetura de Aplicativo Empresarial, Martin Fowler descreve um repositório da seguinte maneira:
Um repositório executa as tarefas de um intermediário entre as camadas do modelo de domínio e o mapeamento de dados, agindo de maneira semelhante a um conjunto de objetos de domínio na memória. Os objetos cliente criam consultas declarativamente e as enviam para os repositórios para obter respostas. Conceitualmente, um repositório encapsula um conjunto de objetos armazenados no banco de dados e operações que podem ser executadas neles, fornecendo uma maneira mais próxima da camada de persistência. Os repositórios, também, dão suporte à finalidade de separar, claramente e em uma direção, a dependência entre o domínio de trabalho e a alocação ou mapeamento de dados.
Definir um repositório por agregação
Para cada agregação ou raiz de agregação, você deve criar uma classe de repositório. Você pode aproveitar genéricos C# para reduzir o número total de classes concretas que você precisa manter (conforme demonstrado posteriormente neste capítulo). Em um microsserviço com base em padrões de DDD (design de Domain-Driven), o único canal que você deve usar para atualizar o banco de dados deve ser os repositórios. Isso ocorre porque eles têm uma relação um-para-um com a raiz de agregação, que controla os invariáveis da agregação e a consistência transacional. Não há problema em consultar o banco de dados por meio de outros canais (como você pode fazer seguindo uma abordagem CQRS), pois as consultas não alteram o estado do banco de dados. No entanto, a área transacional (ou seja, as atualizações) sempre deve ser controlada pelos repositórios e pelas raízes de agregação.
Basicamente, um repositório permite que você preencha dados na memória provenientes do banco de dados na forma das entidades de domínio. Depois que as entidades estiverem na memória, elas poderão ser alteradas e, em seguida, mantidas de volta para o banco de dados por meio de transações.
Conforme observado anteriormente, se você estiver usando o padrão de arquitetura CQS/CQRS, as consultas iniciais serão executadas por consultas laterais fora do modelo de domínio, executadas por instruções SQL simples usando o Dapper. Essa abordagem é muito mais flexível do que os repositórios porque você pode consultar e unir todas as tabelas necessárias e essas consultas não são restritas por regras das agregações. Esses dados vão para a camada de apresentação ou o aplicativo cliente.
Se o usuário fizer alterações, os dados a serem atualizados serão provenientes do aplicativo cliente ou da camada de apresentação para a camada do aplicativo (como um serviço de API Web). Quando você recebe um comando em um manipulador de comandos, usa repositórios para obter os dados que deseja atualizar do banco de dados. Atualize-o na memória com os dados passados com os comandos e, em seguida, adicione ou atualize os dados (entidades de domínio) no banco de dados por meio de uma transação.
É importante enfatizar novamente que você deve definir apenas um repositório para cada raiz de agregação, conforme mostrado na Figura 7-17. Para atingir a meta da raiz de agregação para manter a consistência transacional entre todos os objetos dentro da agregação, você nunca deve criar um repositório para cada tabela no banco de dados.
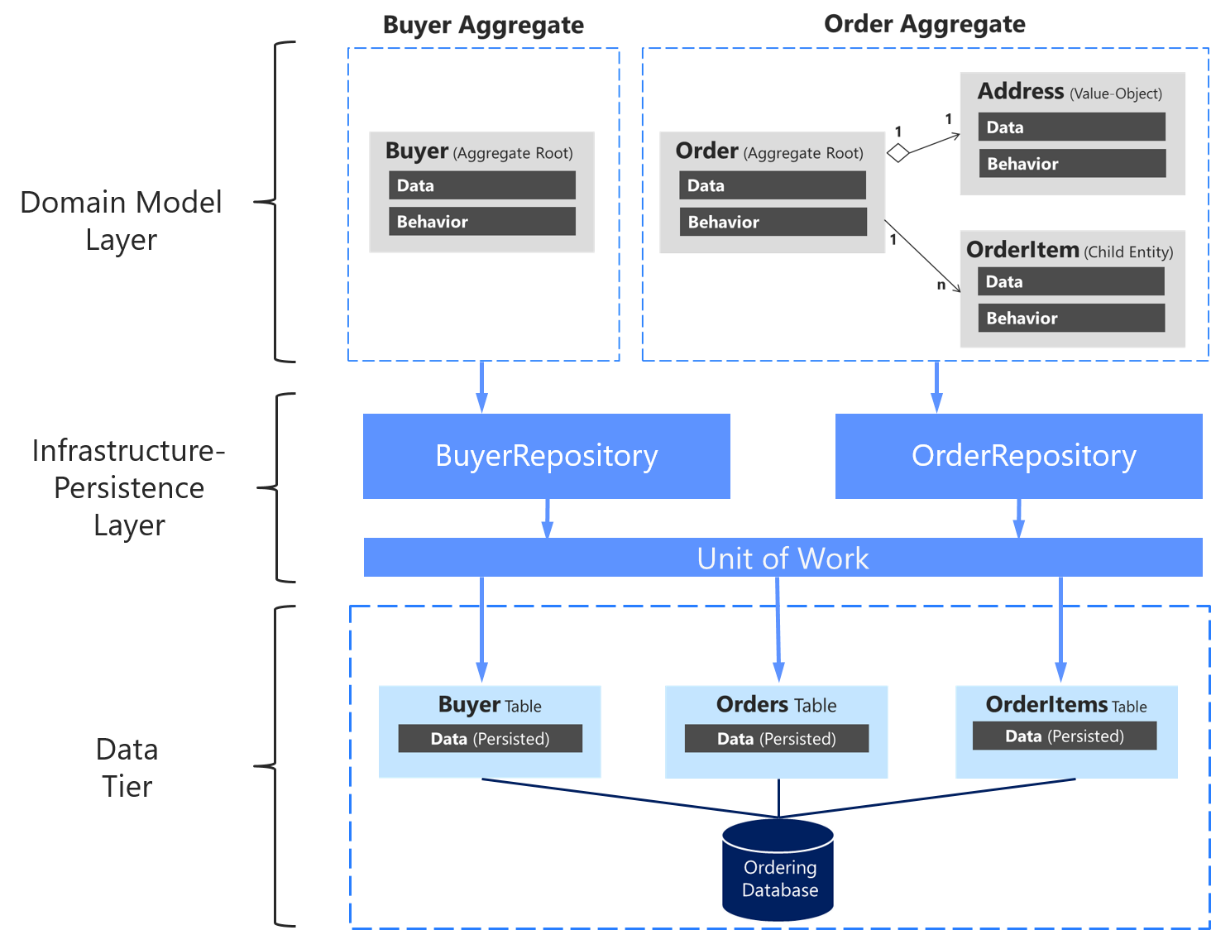
Figura 7-17. A relação entre repositórios, agregações e tabelas de banco de dados
O diagrama acima mostra as relações entre as camadas Domínio e Infraestrutura: a Agregação do Comprador depende do IBuyerRepository e a Agregação do Pedido depende das interfaces IOrderRepository, essas interfaces são implementadas na camada Infraestrutura pelos repositórios correspondentes que dependem do UnitOfWork, também implementado lá, que acessa as tabelas na Camada de dados.
Impor uma raiz de agregação por repositório
Pode ser valioso implementar o design do repositório de modo que ele imponha a regra de que apenas as raízes agregadas devem ter repositórios. Você pode criar um tipo de repositório genérico ou base que restrinja o tipo de entidades com as quais ele funciona para garantir que elas tenham a interface de IAggregateRoot marcador.
Assim, cada classe de repositório implementada na camada de infraestrutura implementa seu próprio contrato ou interface, conforme mostrado no código a seguir:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Cada interface de repositório específica implementa a interface IRepository genérica:
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
No entanto, uma maneira melhor de fazer com que o código imponha a convenção de que cada repositório está relacionado a uma única agregação é implementar um tipo de repositório genérico. Dessa forma, é explícito que você está usando um repositório para direcionar uma agregação específica. Isso pode ser feito facilmente implementando uma interface base genérica IRepository , como no seguinte código:
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
O padrão de repositório facilita o teste da lógica do aplicativo
O padrão do Repositório permite que você teste facilmente seu aplicativo com testes de unidade. Lembre-se de que os testes de unidade testam apenas seu código, não a infraestrutura, de modo que as abstrações do repositório facilitam o alcance dessa meta.
Conforme observado em uma seção anterior, é recomendável que você defina e coloque as interfaces do repositório na camada de modelo de domínio para que a camada de aplicativo, como o microsserviço da API Web, não dependa diretamente da camada de infraestrutura em que você implementou as classes reais do repositório. Ao fazer isso e usar a Injeção de Dependência nos controladores da API Web, você pode implementar repositórios fictícios que retornam dados falsos em vez de dados do banco de dados. Essa abordagem desacoplada permite que você crie e execute testes de unidade que concentram a lógica do aplicativo sem a necessidade de conectividade com o banco de dados.
As conexões com bancos de dados podem falhar e, mais importante, executar centenas de testes em um banco de dados é ruim por dois motivos. Primeiro, pode levar muito tempo devido ao grande número de testes. Em segundo lugar, os registros de banco de dados podem mudar e afetar os resultados de seus testes, especialmente se os testes estiverem sendo executados em paralelo, para que eles não sejam consistentes. Os testes de unidade normalmente podem ser executados em paralelo; Os testes de integração podem não dar suporte à execução paralela dependendo de sua implementação. O teste no banco de dados não é um teste de unidade, mas um teste de integração. Você deve ter muitos testes de unidade em execução rápida, mas menos testes de integração em relação aos bancos de dados.
Em termos de separação de preocupações para testes de unidade, sua lógica opera em entidades de domínio na memória. Ela considera que a classe de repositório as entregou. Depois que sua lógica modifica as entidades de domínio, ela pressupõe que a classe de repositório as armazenará corretamente. O ponto importante aqui é criar testes de unidade em relação ao seu modelo de domínio e sua lógica de domínio. As raízes agregadas são os principais limites de consistência no DDD.
Os repositórios implementados no eShopOnContainers baseiam-se na implementação do DbContext do EF Core dos padrões de repositório e unidade de trabalho, usando seu rastreador de alterações, para que eles não dupliquem essa funcionalidade.
A diferença entre o padrão Repositório e o padrão de classe de Acesso a Dados legada (classe DAL)
Um objeto DAL típico executa diretamente operações de persistência e acesso a dados no armazenamento, geralmente no nível de uma única tabela e linha. Operações CRUD simples implementadas com um conjunto de classes DAL frequentemente não dão suporte a transações (embora isso nem sempre seja o caso). A maioria das abordagens de classe DAL faz uso mínimo de abstrações, o que resulta no acoplamento rígido entre classes de aplicativo ou BLL (camada lógica de negócios) que chamam os objetos DAL.
Ao usar o repositório, os detalhes de implementação da persistência são encapsulados longe do modelo de domínio. O uso de uma abstração fornece facilidade de estender o comportamento por meio de padrões como Decoradores ou Proxies. Por exemplo, preocupações de corte cruzado, como cache, registro em log e tratamento de erros, podem ser aplicadas usando esses padrões em vez de codificadas no próprio código de acesso a dados. Também é trivial dar suporte a vários adaptadores de repositório que podem ser usados em ambientes diferentes, desde desenvolvimento local até ambientes de preparo compartilhados até produção.
Implementação da unidade de trabalho
Uma unidade de trabalho refere-se a uma única transação que envolve várias operações de inserção, atualização ou exclusão. Em termos simples, isso significa que, para uma ação específica do usuário, como um registro em um site, todas as operações de inserção, atualização e exclusão são tratadas em uma única transação. Isso é mais eficiente do que lidar com várias operações de banco de dados de maneira tagarela.
Essas várias operações de persistência são executadas posteriormente em uma única ação quando o código da camada de aplicativo o comanda. A decisão sobre a aplicação das alterações na memória ao armazenamento real do banco de dados normalmente se baseia no padrão unidade de trabalho. No EF, o padrão unidade de trabalho é implementado por um DbContext e é executado quando uma chamada é feita para SaveChanges.
Em muitos casos, esse padrão ou maneira de aplicar operações no armazenamento pode aumentar o desempenho do aplicativo e reduzir a possibilidade de inconsistências. Ele também reduz o bloqueio de transações nas tabelas de banco de dados, pois todas as operações pretendidas são confirmadas como parte de uma transação. Isso é mais eficiente em comparação com a execução de muitas operações isoladas no banco de dados. Portanto, o ORM selecionado pode otimizar a execução no banco de dados agrupando várias ações de atualização na mesma transação, em vez de muitas execuções de transação pequenas e separadas.
O padrão unidade de trabalho pode ser implementado com ou sem usar o padrão repositório.
Repositórios não devem ser obrigatórios
Repositórios personalizados são úteis pelos motivos citados anteriormente e essa é a abordagem para o microsserviço de ordenação no eShopOnContainers. No entanto, não é um padrão essencial implementar em um design DDD ou mesmo no desenvolvimento geral do .NET.
Por exemplo, Jimmy Bogard, ao fornecer comentários diretos para este guia, disse o seguinte:
Este provavelmente será o meu maior comentário. Eu realmente não sou fã de repositórios, principalmente porque eles ocultam os detalhes importantes do mecanismo de persistência subjacente. É por isso que eu opto pelo MediatR também para comandos. Posso aproveitar todo o poder da camada de persistência e transferir todo esse comportamento de domínio para os meus agregados principais. Normalmente, não quero zombar dos meus repositórios. Ainda preciso fazer esse teste de integração com a coisa real. Ir para CQRS significava que não tínhamos mais necessidade de repositórios.
Repositórios podem ser úteis, mas não são essenciais para o design de DDD da maneira como o padrão de agregação e um modelo de domínio avançado são. Portanto, use o padrão de repositório ou não, conforme achar mais adequado.
Recursos adicionais
Padrão de repositório
Edward Hieatt e Rob me. Padrão de repositório.
https://martinfowler.com/eaaCatalog/repository.htmlO padrão de repositório
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. Domain-Driven Design: Abordando a complexidade no coração do software. (Livro; inclui uma discussão sobre o padrão de repositório)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Padrão de unidade de trabalho
Martin Fowler. Padrão de unidade de trabalho.
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementando o repositório e a unidade de padrões de trabalho em um aplicativo MVC ASP.NET
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
Colaborar conosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde você também pode criar e revisar problemas e solicitações de pull. Para obter mais informações, confira o nosso guia para colaboradores.