Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo fornece uma visão geral dos tipos que ajudam na leitura de dados que atravessam vários buffers. Eles são usados principalmente para dar suporte PipeReader a objetos.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> é um contrato para gravação em buffer síncrono. No nível mais baixo, a interface:
- É básico e não é difícil de usar.
- Permite o acesso a um Memory<T> ou Span<T>. O
Memory<T>ouSpan<T>pode ser gravado e você pode determinar quantos itensTforam gravados.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
O método anterior:
- Solicita um buffer de pelo menos 5 bytes do
IBufferWriter<byte>usandoGetSpan(5). - Grava bytes para a cadeia de caracteres ASCII "Hello" no
Span<byte>retornado. - Chamadas IBufferWriter<T> para indicar quantos bytes foram gravados no buffer.
Esse método de gravação usa o Memory<T>/Span<T> buffer fornecido pelo IBufferWriter<T>. Como alternativa, o Write método de extensão pode ser usado para copiar um buffer existente para o IBufferWriter<T>.
Write faz o trabalho de chamar GetSpan/Advance conforme apropriado, portanto, não há necessidade de chamar Advance depois de escrever:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> é uma implementação de IBufferWriter<T> cujo repositório de backup é uma única matriz contígua.
Problemas comuns do IBufferWriter
-
GetSpaneGetMemoryretorne um buffer com pelo menos a quantidade de memória solicitada. Não suponha tamanhos exatos do buffer. - Não há garantia de que chamadas sucessivas retornarão o mesmo buffer ou um buffer de tamanho igual.
- Um novo buffer deve ser solicitado após a chamada
Advancepara continuar gravando mais dados. Um buffer adquirido anteriormente não pode ser gravado apósAdvanceter sido chamado.
ReadOnlySequence<T>
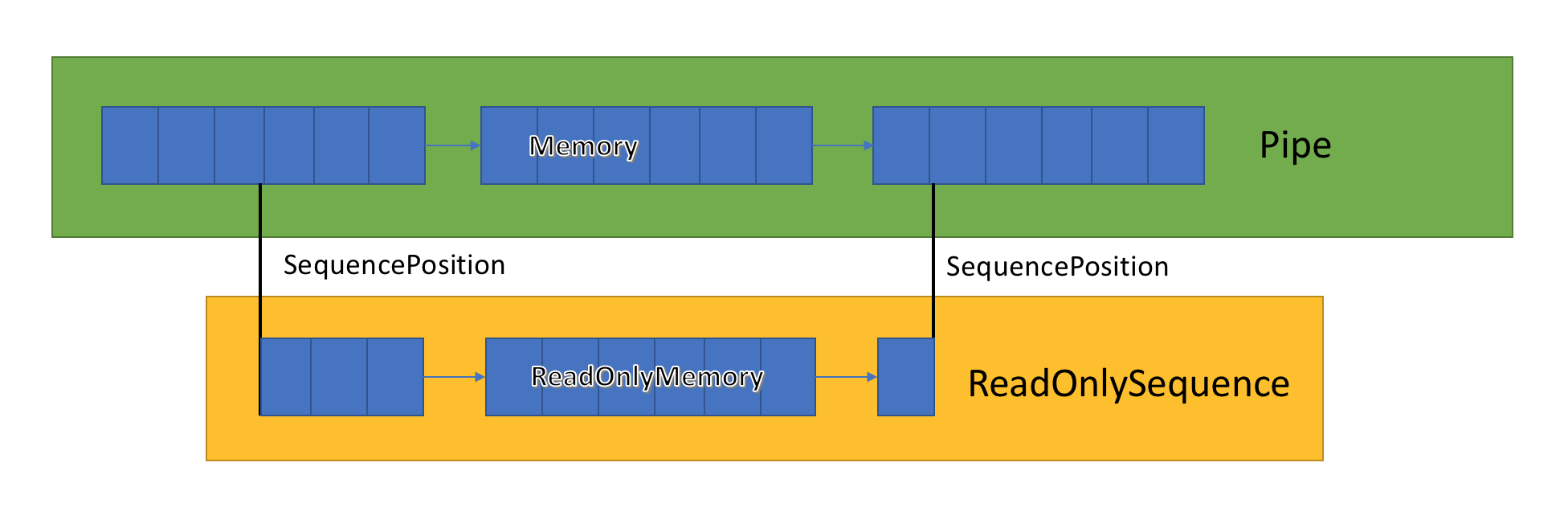
ReadOnlySequence<T> é um struct que pode representar uma sequência contígua ou não contígua de T. Ele pode ser construído a partir de:
- Um
T[] - Um
ReadOnlyMemory<T> - Um par de nó de lista vinculada ReadOnlySequenceSegment<T> e índice para representar a posição inicial e final da sequência.
A terceira representação é a mais interessante, pois tem implicações de desempenho em várias operações no ReadOnlySequence<T>:
| Representação | Operação | Complexidade |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Devido a essa representação mista, o ReadOnlySequence<T> expõe os índices como SequencePosition em vez de um número inteiro. Um SequencePosition:
- É um valor opaco que representa um índice em
ReadOnlySequence<T>onde se originou. - Consiste em duas partes, um inteiro e um objeto. O que esses dois valores representam está vinculado à implementação de
ReadOnlySequence<T>.
Acessar dados
O ReadOnlySequence<T> expõe dados como um enumerável de ReadOnlyMemory<T>. A enumeração de cada um dos segmentos pode ser feita usando um foreach básico:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
O método anterior pesquisa cada segmento em busca de um byte específico. Se você precisar acompanhar o SequencePosition de cada segmento, ReadOnlySequence<T>.TryGet é mais apropriado. O próximo exemplo altera o código anterior para retornar um SequencePosition em vez de um inteiro. Retornar um SequencePosition tem o benefício de permitir que o chamador evite uma segunda verificação para obter os dados em um índice específico.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
A combinação de SequencePosition e TryGet age como um enumerador. O campo de posição é modificado no início de cada iteração para ser o início de cada segmento dentro do ReadOnlySequence<T>.
O método anterior existe como um método de extensão em ReadOnlySequence<T>.
PositionOf pode ser usado para simplificar o código anterior:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Processar um ReadOnlySequence<T>
O processamento de um ReadOnlySequence<T> pode ser desafiador, pois os dados podem ser divididos entre vários segmentos dentro da sequência. Para obter o melhor desempenho, divida o código em dois caminhos:
- Um caminho rápido que lida com o caso de segmento único.
- Um caminho lento que lida com a divisão de dados entre segmentos.
Há algumas abordagens que podem ser usadas para processar dados em sequências multi segmentadas:
- Use o
SequenceReader<T>. - Analisar segmento de dados por segmento, acompanhando o
SequencePositione o índice dentro do segmento analisado. Isso evita alocações desnecessárias, mas pode ser ineficiente, especialmente para buffers pequenos. - Copie o
ReadOnlySequence<T>para uma matriz contígua e trate-a como um único buffer:- Se o tamanho do
ReadOnlySequence<T>for pequeno, pode ser razoável copiar os dados em um buffer alocado em pilha usando o operador stackalloc. - Copie o
ReadOnlySequence<T>para uma matriz em pool usando ArrayPool<T>.Shared. - Use
ReadOnlySequence<T>.ToArray(). Isso não é recomendado em caminhos críticos, pois aloca um novoT[]no heap.
- Se o tamanho do
Os exemplos a seguir demonstram alguns casos comuns para processamento ReadOnlySequence<byte>:
Processar dados binários
O exemplo a seguir analisa o comprimento de um inteiro big-endian de 4 bytes desde o início de ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Processar dados de texto
O exemplo a seguir:
- Localiza a primeira nova linha (
\r\n) emReadOnlySequence<byte>e a retorna por meio do parâmetro out 'line'. - Corta essa linha, excluindo a
\r\ndo buffer de entrada.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Segmentos vazios
É válido armazenar segmentos vazios dentro de um ReadOnlySequence<T>. Segmentos vazios podem ocorrer ao enumerar segmentos explicitamente:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
O código anterior cria um ReadOnlySequence<byte> segmento com segmentos vazios e mostra como esses segmentos vazios afetam as várias APIs:
-
ReadOnlySequence<T>.Slicecom umSequencePositionapontando para um segmento vazio preserva esse segmento. -
ReadOnlySequence<T>.Slicecom um int ignora os segmentos vazios. - Enumerar o
ReadOnlySequence<T>enumera os segmentos vazios.
Possíveis problemas com ReadOnlySequence<T> e SequencePosition
Há vários resultados incomuns ao lidar com um ReadOnlySequence<T>/SequencePosition versus um ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int normal:
-
SequencePositioné um marcador de posição para uma posição específicaReadOnlySequence<T>, não uma posição absoluta. Como ele é relativo a um específicoReadOnlySequence<T>, ele não tem significado se usado fora do local de origemReadOnlySequence<T>. - A aritmética não pode ser feita em
SequencePositionsem oReadOnlySequence<T>. Isso significa fazer coisas básicas comoposition++é escritoposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)não dá suporte a índices negativos. Isso significa que é impossível obter o penúltimo caractere sem percorrer todos os segmentos. - Dois
SequencePositionnão podem ser comparados, dificultando:- Saiba se uma posição é maior ou menor que outra.
- Escreva alguns algoritmos de análise.
-
ReadOnlySequence<T>é maior que uma referência de objeto e deve ser passado por dentro ou ref sempre que possível. PassarReadOnlySequence<T>porinourefreduz as cópias do struct. - Segmentos vazios:
- São válidos dentro de um
ReadOnlySequence<T>. - Pode aparecer ao iterar usando o método
ReadOnlySequence<T>.TryGet. - Pode aparecer fatiando a sequência usando o método
ReadOnlySequence<T>.Slice()com objetosSequencePosition.
- São válidos dentro de um
SequenceReader<T>
- É um novo tipo que foi introduzido no .NET Core 3.0 para simplificar o processamento de um
ReadOnlySequence<T>. - Unifica as diferenças entre um único segmento
ReadOnlySequence<T>e vários segmentosReadOnlySequence<T>. - Fornece auxiliares para ler dados binários e de texto (
byteechar) que podem ou não ser divididos entre segmentos.
Há métodos internos para lidar com o processamento de dados binários e delimitados. A seção a seguir demonstra como esses mesmos métodos são com o SequenceReader<T>:
Acessar dados
SequenceReader<T> tem métodos para enumerar dados dentro do ReadOnlySequence<T> diretamente. O código a seguir é um exemplo de processamento de um ReadOnlySequence<byte> e um byte por vez:
while (reader.TryRead(out byte b))
{
Process(b);
}
O CurrentSpan expõe o Span do segmento atual, que é semelhante ao que foi feito no método manualmente.
Usar posição
O código a seguir é um exemplo de implementação de FindIndexOf usando o SequenceReader<T>:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Processar dados binários
O exemplo a seguir analisa o comprimento de um inteiro big-endian de 4 bytes desde o início de ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Processar dados de texto
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Problemas comuns do SequenceReader<T>
- Como
SequenceReader<T>é um struct mutável, ele sempre deve ser passado por referência. -
SequenceReader<T>é uma estrutura de referência, portanto, só pode ser usada em métodos síncronos e não pode ser armazenada em campos. Para obter mais informações, confira Evitar alocações. -
SequenceReader<T>é otimizado para uso como leitor somente de encaminhamento.Rewinddestina-se a pequenos backups que não podem ser resolvidos utilizando outras APIs deRead,PeekeIsNext.
Colaborar conosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde você também pode criar e revisar problemas e solicitações de pull. Para obter mais informações, confira o nosso guia para colaboradores.