Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Microsoft Fabric é um serviço de análise integrada que acelera o tempo para obter insights em data warehouses e sistemas de Big Data. A visualização de dados em notebooks é um recurso importante que permite que você obtenha informações sobre seus dados, ajudando os usuários a identificar padrões, tendências e exceções com facilidade.
Ao trabalhar com o Apache Spark no Fabric, você tem opções internas para visualizar dados, incluindo recursos de gráfico de notebook do Fabric e acesso a bibliotecas populares de software livre.
Os notebooks de malha também permitem converter resultados tabulares em gráficos personalizados sem escrever nenhum código, permitindo uma experiência de exploração de dados mais intuitiva e perfeita.
Comando de visualização integrado - função display()
A função de visualização interna do Fabric permite que você transforme DataFrames do Apache Spark, DataFrames do Pandas e resultados de consultas SQL em visualizações de dados avançadas e interativas.
Usando a função de exibição , você pode renderizar DataFrames do PySpark e Scala Spark ou RDDs (conjuntos de dados distribuídos resilientes) como tabelas ou gráficos dinâmicos.
Você pode especificar a contagem de linhas do dataframe que está sendo renderizado. O valor padrão é 1000. O widget de exibição de saída do notebook dá suporte à exibição e à criação de perfil de, no máximo, 10000 linhas de um dataframe.

Você pode usar a função de filtro na barra de ferramentas global para aplicar regras personalizadas aos seus dados. A condição de filtro é aplicada a uma coluna especificada e os resultados são refletidos nas exibições da tabela e do gráfico.

Por padrão, a saída da instrução SQL utiliza o mesmo widget de saída com display().
Modo de exibição de tabela de dataframe avançado
Suporte à seleção gratuita no modo de exibição de tabela
Por padrão, a Exibição de Tabela é renderizada ao usar o comando display() em um notebook do Fabric. A pré-visualização aprimorada do dataframe oferece uma função intuitiva de seleção livre, projetada para melhorar a experiência de análise de dados ao habilitar opções de seleção flexíveis e interativas. Esse recurso permite que os usuários naveguem e explorem os dataframes com facilidade com eficiência.
Seleção de coluna
- coluna única: clique no cabeçalho da coluna para selecionar a coluna inteira.
- Várias colunas: depois de selecionar uma única coluna, pressione e segure a tecla 'Shift' e clique em outro cabeçalho de coluna para selecionar várias colunas.
Seleção de linha
- Linha única: clique em um cabeçalho de linha para selecionar a linha inteira.
- Várias linhas: depois de selecionar uma única linha, pressione e segure a tecla 'Shift' e clique em outro cabeçalho de linha para selecionar várias linhas.
Visualização de conteúdo da célula: visualizar o conteúdo de células individuais para obter uma visão rápida e detalhada dos dados sem a necessidade de escrever código adicional.
Resumo da coluna: obtenha um resumo de cada coluna, incluindo distribuição de dados e estatísticas de chave, para entender rapidamente as características dos dados.
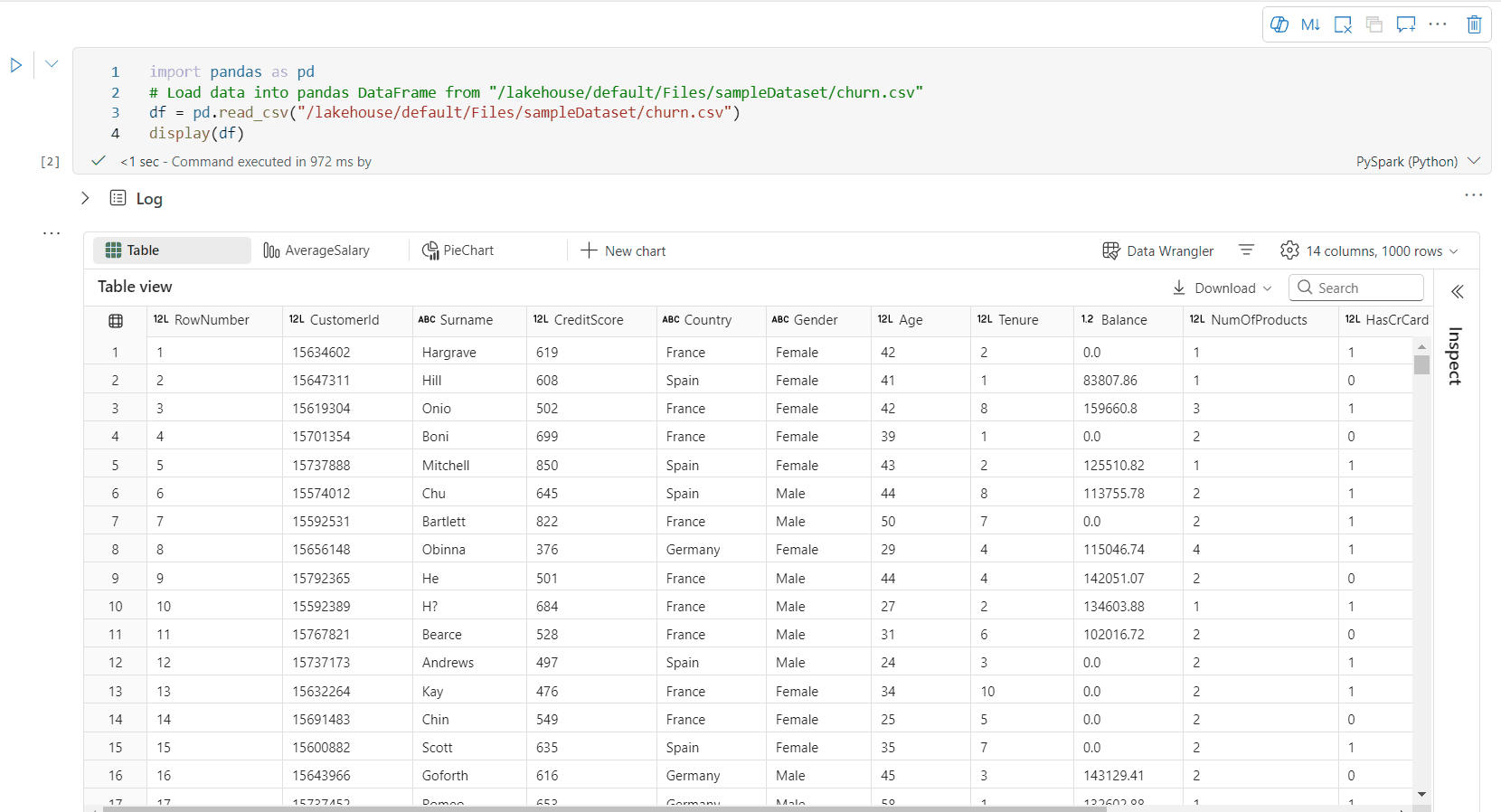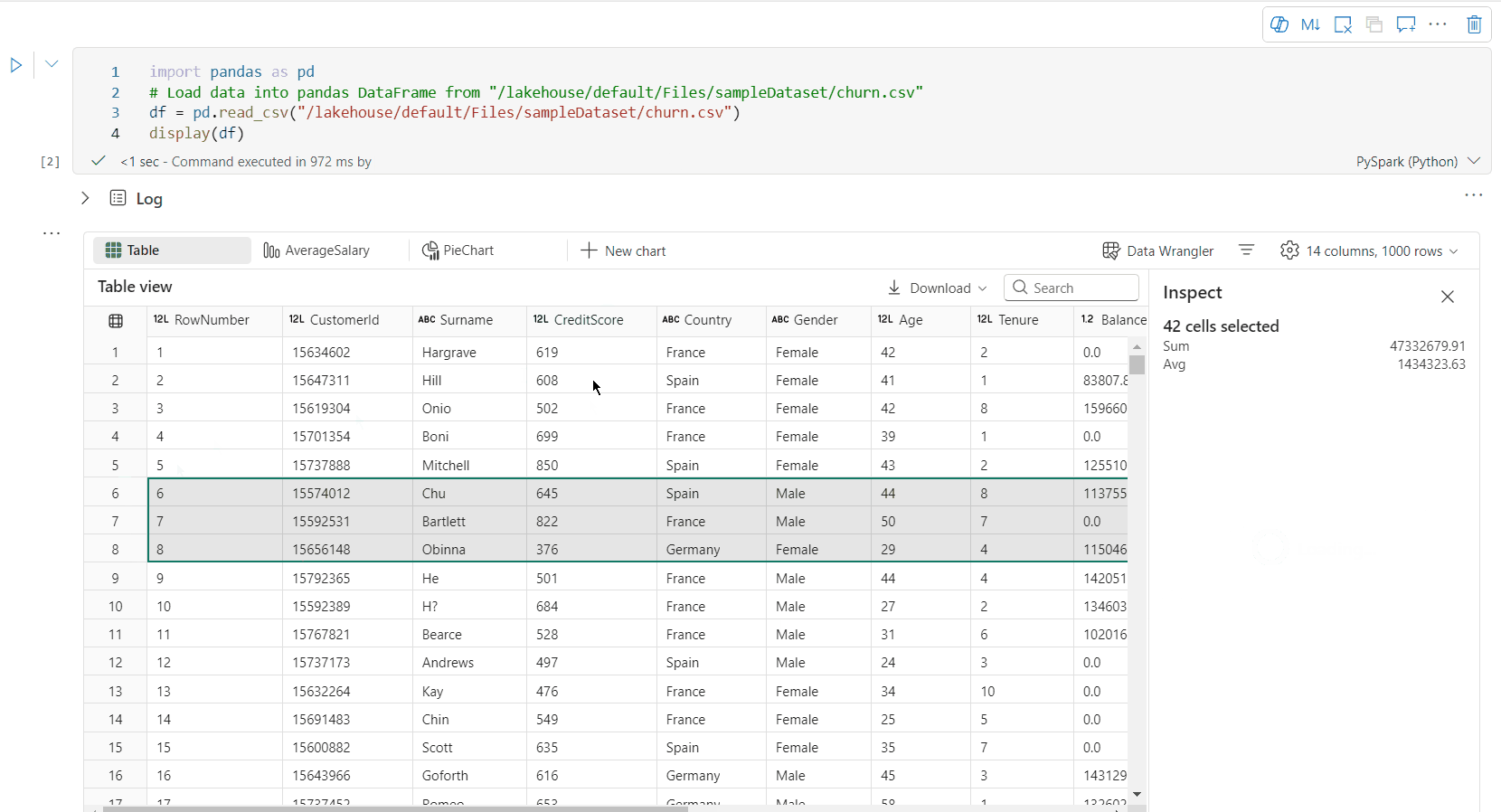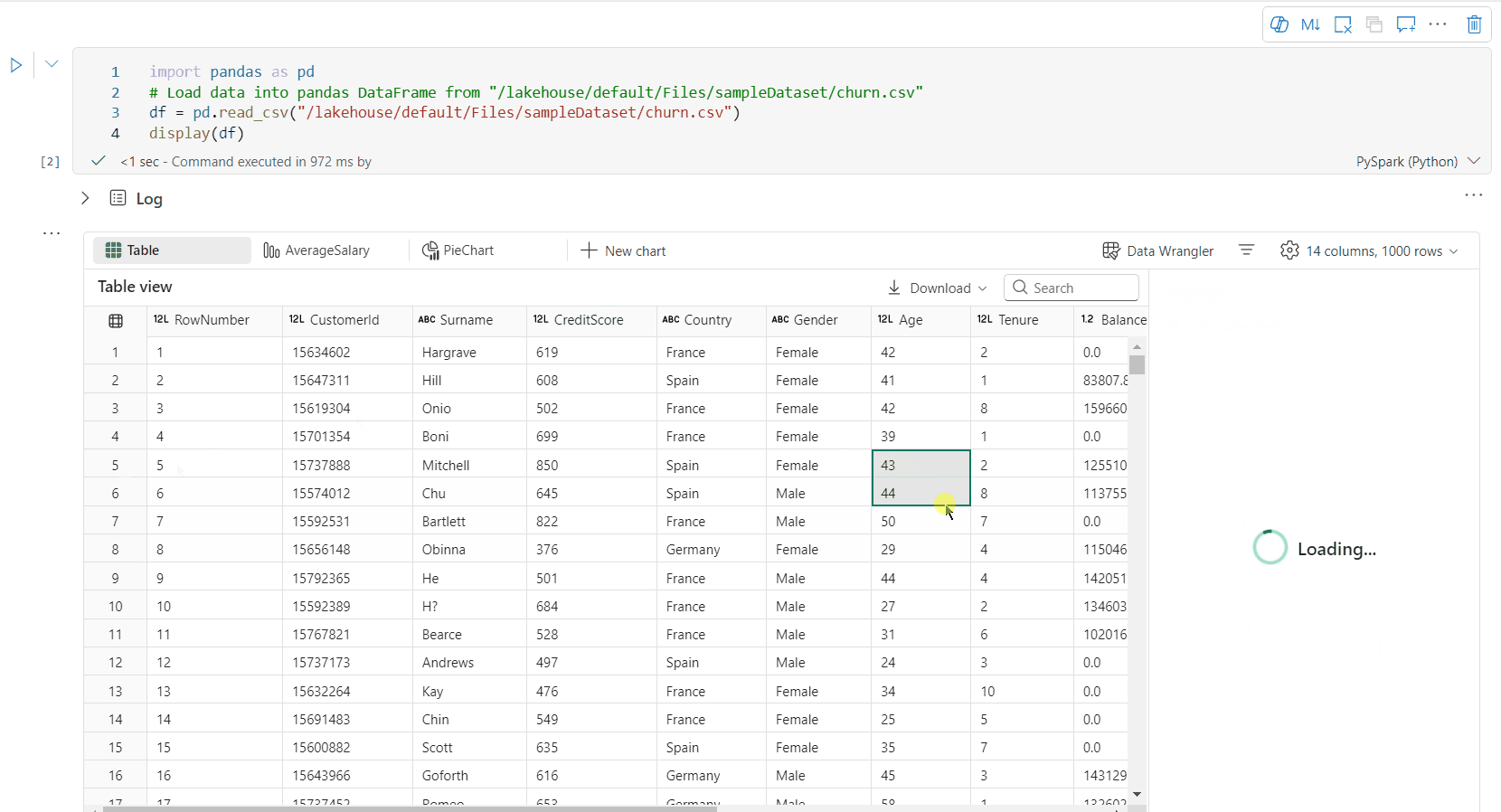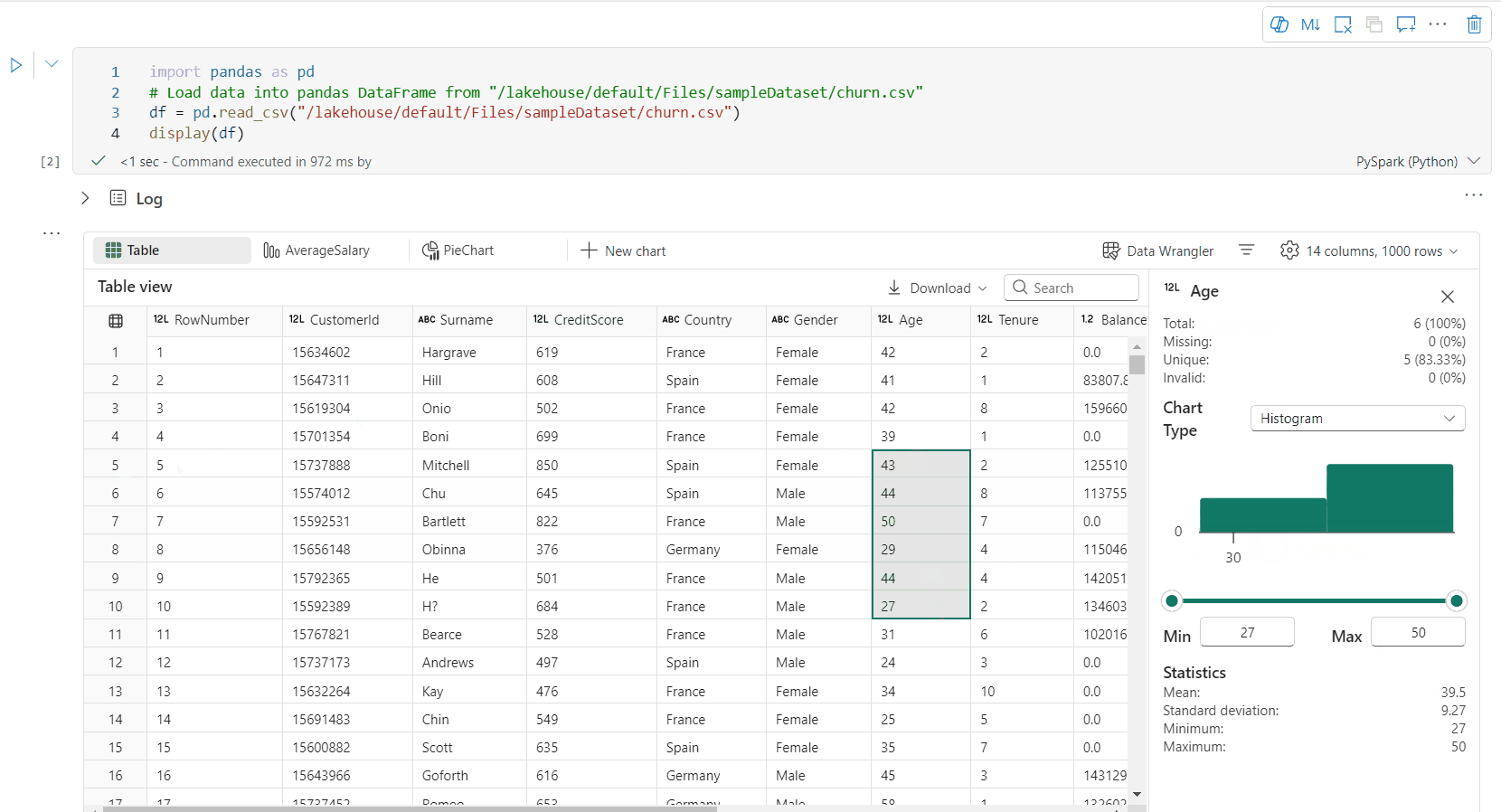
Seleção de área livre: selecione qualquer segmento contínuo da tabela para obter uma visão geral do total de células selecionadas e dos valores numéricos na área selecionada.
Copiar conteúdo selecionado: em todos os casos de seleção, você pode copiar rapidamente o conteúdo selecionado usando o atalho 'Ctrl + C'. Os dados selecionados são copiados no formato CSV, facilitando o processamento em outros aplicativos.

Suporte para criação de perfil de dados por meio do painel Inspecionar

Você pode criar o perfil do seu dataframe clicando no botão Inspecionar. Ele fornece a distribuição de dados resumida e mostra estatísticas de cada coluna.
Cada cartão no painel lateral "Inspecionar" mapeia para uma coluna do dataframe, e você pode exibir mais detalhes clicando no cartão ou selecionando uma coluna na tabela.
Você pode exibir os detalhes da célula clicando na célula da tabela. Esse recurso é útil quando o dataframe contém conteúdo do tipo string longo.
Visualização avançada do gráfico de DataFrame Rich aprimorada
O modo de exibição de gráfico aprimorado no comando display() oferece uma maneira mais intuitiva e dinâmica de visualizar seus dados.
Principais aprimoramentos:
Suporte a vários gráficos: adicione até cinco gráficos em um único widget de saída de exibição selecionando Novo Gráfico, permitindo comparações fáceis entre diferentes colunas.
Recomendações de gráfico inteligente: obtenha uma lista de gráficos sugeridos com base em seu DataFrame. Escolha editar uma visualização recomendada ou criar um gráfico personalizado do zero.

Personalização Flexível: personalize suas visualizações com configurações ajustáveis que se adaptam com base no tipo de gráfico selecionado.
Categoria Configurações básicas Descrição Tipo de gráfico A função de exibição oferece suporte a uma ampla variedade de tipos de gráficos, incluindo gráficos de barras, gráficos de dispersão, gráficos de linhas, tabela dinâmica e muito mais. Título Título O título do gráfico. Título Subtítulo O subtítulo do gráfico com mais descrições. Dados Eixo X Especifique a chave do gráfico. Dados Eixo Y Especifique os valores do gráfico. Legenda Mostrar Legenda Ativar/desativar a legenda. Legenda Cargo Personalize a posição da legenda. Outro Grupo de séries Use esta configuração para determinar os grupos para a agregação. Outro Agregação Use este método para agregar dados em sua visualização. Outro Empilhado Configure o estilo de exibição do resultado. Outro Valores ausentes e NULL Configure como são exibidos os valores de gráfico ausentes ou NULL. Observação
Além disso, você pode especificar o número de linhas exibidas, com uma configuração padrão de 1.000. O widget de saída do display no notebook dá suporte à visualização e análise de perfil de até 10.000 linhas de um DataFrame. Selecione Agregação em todos os resultados e, em seguida, selecione Aplicar para aplicar a geração de gráficos de todo o dataframe. Um trabalho do Spark é disparado quando a configuração do gráfico é alterada. Pode levar vários minutos para concluir o cálculo e renderizar o gráfico.
Categoria Configurações avançadas Descrição Cor Tema Defina o conjunto de cores do tema do gráfico. Eixo X Etiqueta Especifique um rótulo para o eixo X. Eixo X Escala Especifique a função de escala do eixo X. Eixo X Intervalo Especifique o intervalo de valores do eixo X. Eixo Y Etiqueta Especifique um rótulo para o eixo Y. Eixo Y Escala Especifique a função de escala do eixo Y. Eixo Y Intervalo Especifique o intervalo de valores do eixo Y. Exibir Mostrar rótulos Mostrar/ocultar os rótulos de resultado no gráfico. As alterações de configurações entrarão em vigor imediatamente e todas as configurações são salvas automaticamente no conteúdo do notebook.
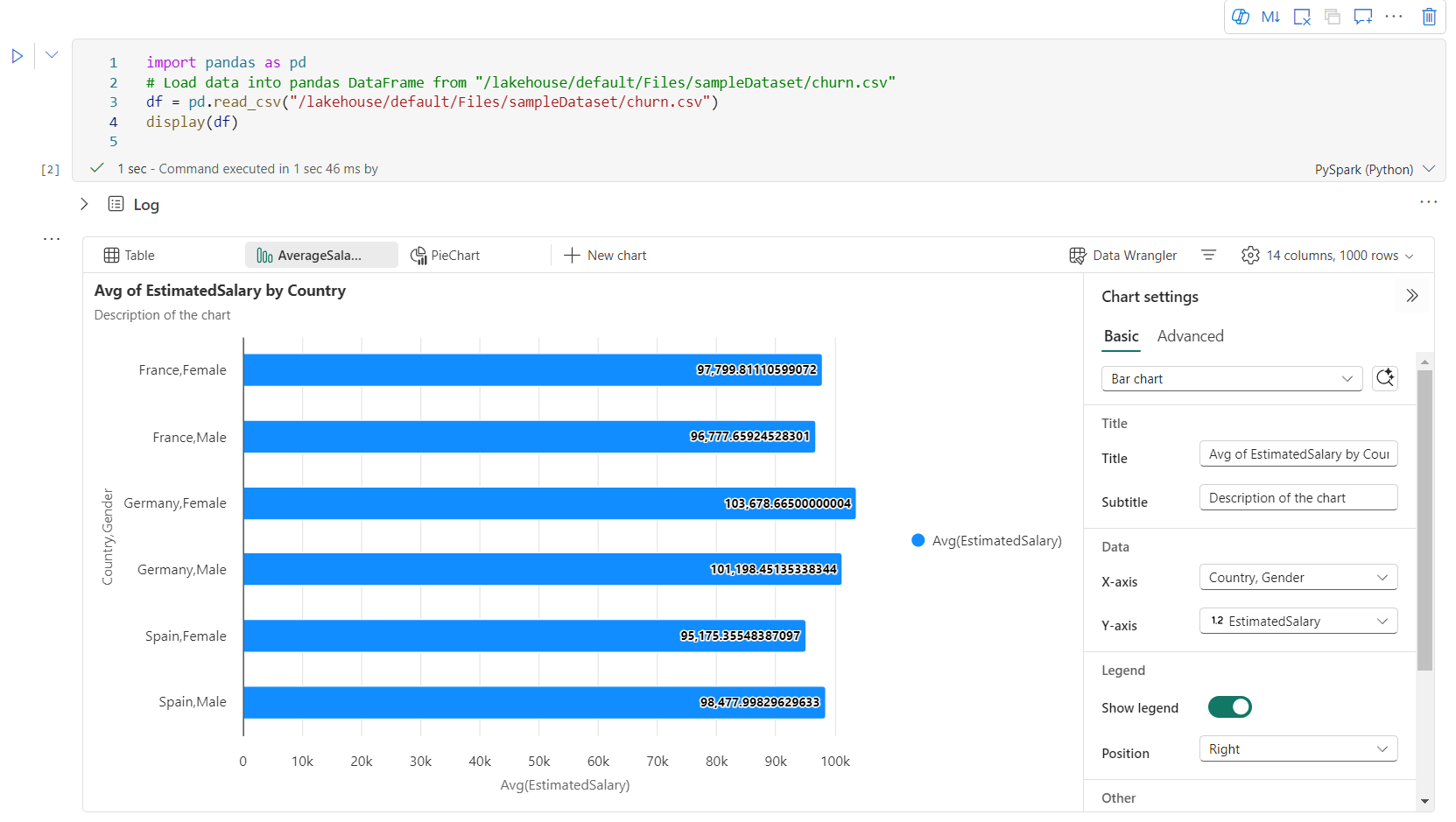
Você pode renomear, duplicar, excluir ou mover gráficos facilmente no menu de guias do gráfico. Você também pode arrastar e soltar abas para reordená-las. A primeira guia será exibida como o padrão quando o bloco de anotações for aberto.
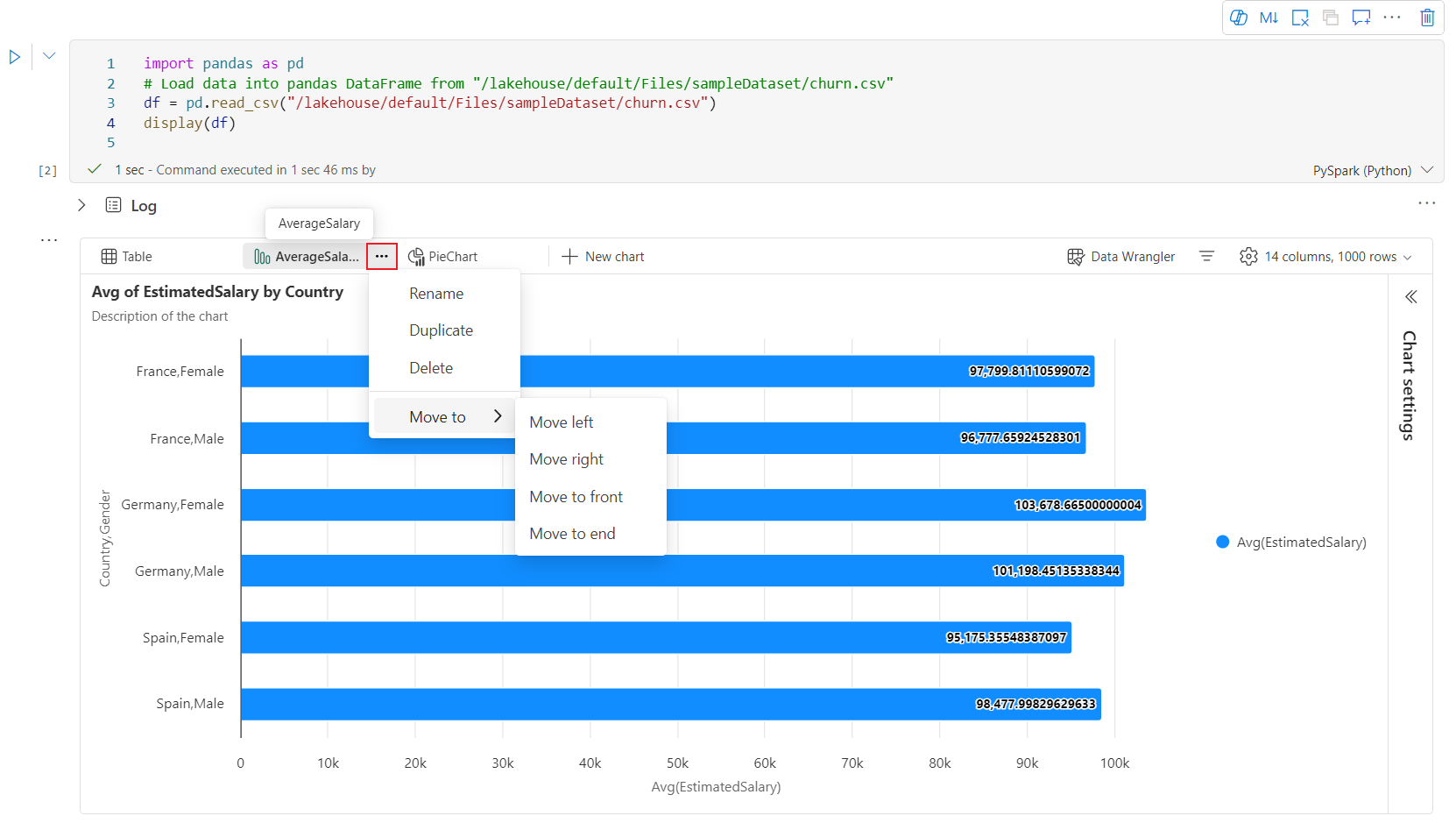
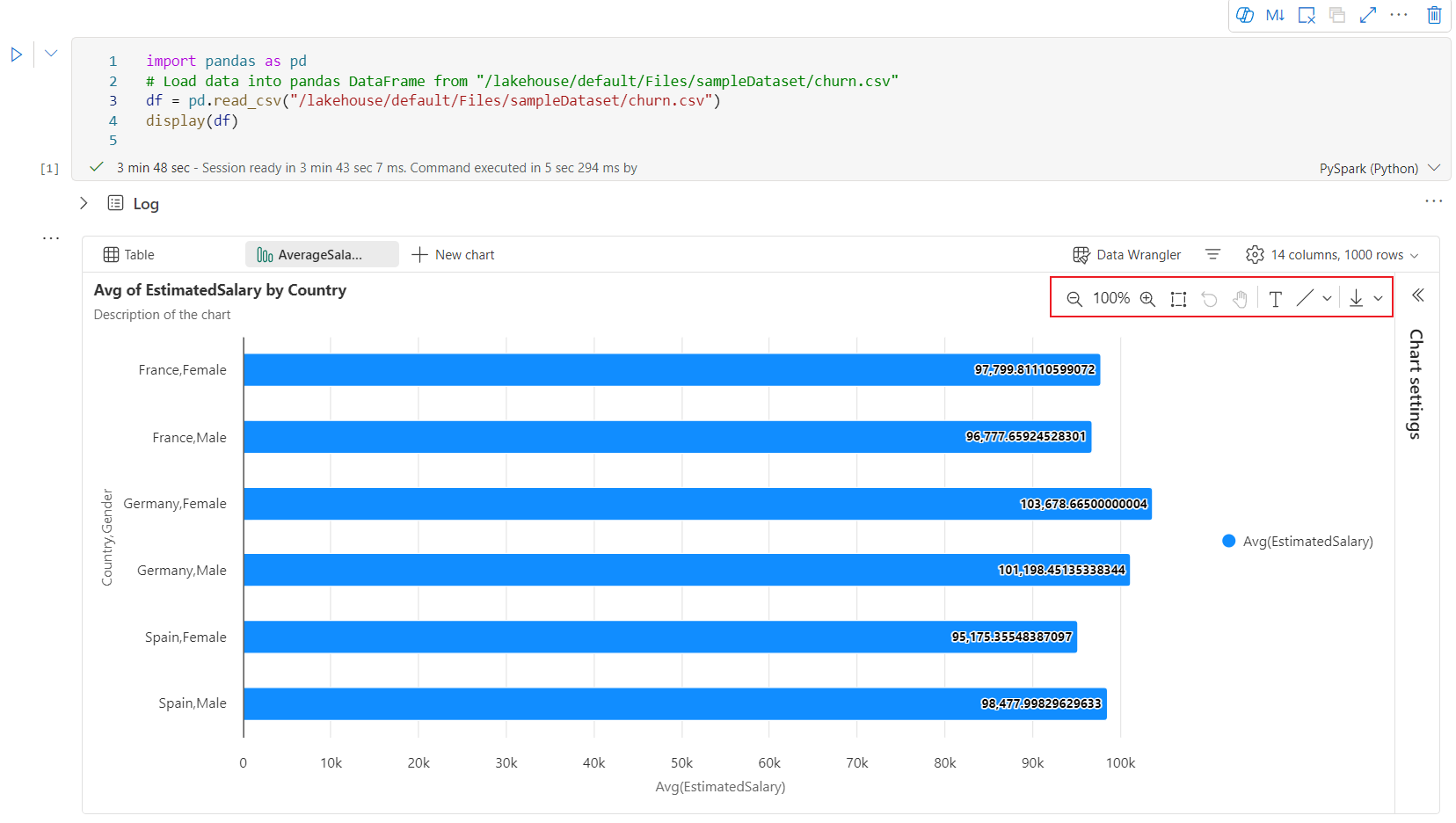
Uma barra de ferramentas interativa está disponível na nova experiência de gráfico quando o usuário passa o mouse em um gráfico. Operações de suporte como aproximar, afastar, selecionar para zoom, redefinir, navegar, editar anotações, etc.
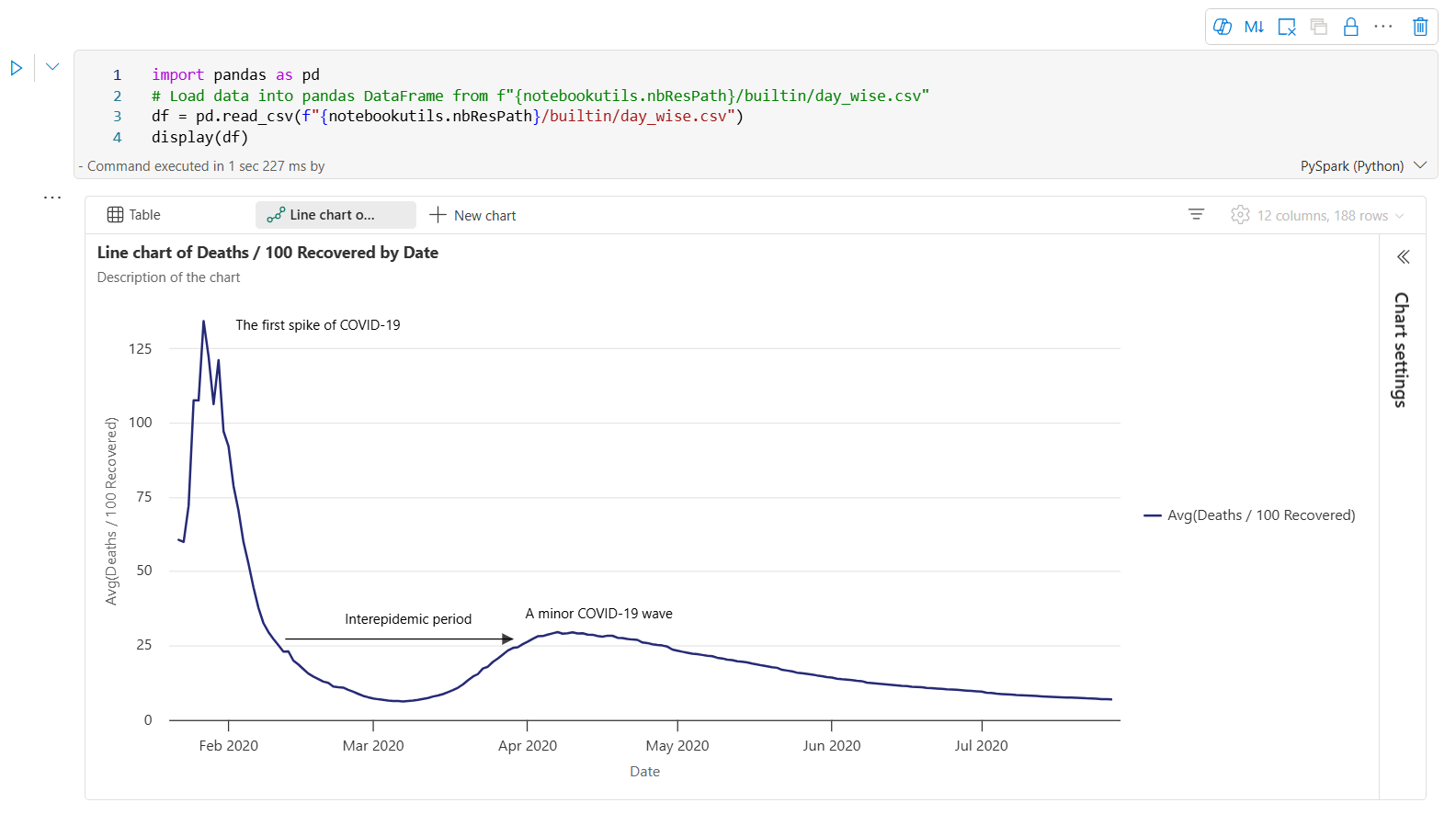
Aqui está um exemplo de anotação de gráfico.




exibição de resumo display()
Use display(df, summary = true) para verificar o resumo de estatísticas de um determinado de DataFrame do Apache Spark. O resumo inclui o nome da coluna, o tipo de coluna, os valores exclusivos e os valores ausentes para cada coluna. Você também pode selecionar uma coluna específica para ver seu valor mínimo, valor máximo, valor médio e desvio padrão.

opção displayHTML()
Os notebooks do Fabric dão suporte a elementos gráficos HTML usando a função de displayHTML.
A imagem a seguir é um exemplo de criação de visualizações usando D3.js.

Para criar essa visualização, execute o código a seguir.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Inserir um relatório do Power BI em um notebook
Importante
Esse recurso está na versão prévia.
O pacote Powerbiclient do Python agora tem suporte nativo em notebooks do Fabric. Não é necessário fazer nenhuma configuração extra (como o processo de autenticação) no runtime do Spark do Notebook Fabric 3.4. Basta importar powerbiclient e continuar sua exploração. Para saber mais sobre como usar o pacote powerbiclient, consulte a documentação powerbiclient.
O powerbiclient dá suporte aos seguintes principais recursos.
Renderizar um relatório existente do Power BI
É possível inserir e interagir facilmente com relatórios do Power BI nos notebooks com apenas algumas linhas de código.
A imagem a seguir é um exemplo de renderização do relatório existente do Power BI.

Execute o código a seguir para renderizar um relatório existente do Power BI.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Criar visuais de relatório a partir de um DataFrame do Spark
Use um DataFrame do Spark em seu notebook para gerar visualizações perspicazes rapidamente. Também poderá selecionar Salvar no relatório inserido para criar um item de relatório em um espaço de trabalho de destino.
A imagem a seguir é um exemplo de um QuickVisualize() a partir de um DataFrame do Spark.

Execute o código a seguir para renderizar um relatório de um DataFrame do Spark.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Criar visuais de relatório a partir de um DataFrame do pandas
Também poderá criar relatórios com base em um DataFrame do pandas no notebook.
A imagem a seguir é um exemplo de um QuickVisualize() a partir de um DataFrame do pandas.

Execute o código a seguir para renderizar um relatório de um DataFrame do Spark.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Bibliotecas populares
Quando se trata de visualização de dados, o Python oferece várias bibliotecas de gráficos que vêm incluídas com muitos recursos diferentes. Por padrão, cada pool do Apache Spark no Fabric contém um conjunto de bibliotecas de código aberto populares e selecionadas.
Matplotlib
Você pode renderizar bibliotecas de plotagem padrão, como Matplotlib, usando as funções de renderização internas para cada biblioteca.
A imagem a seguir é um exemplo de criação de um gráfico de barras usando Matplotlib.


Execute o código de exemplo a seguir para desenhar esse gráfico de barras.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Você pode renderizar bibliotecas HTML ou interativas, como a bokeh, usando displayHTML(df).
A imagem a seguir é um exemplo de como plotar glifos em um mapa usando bokeh.

Para desenhar esta imagem, execute o código de exemplo a seguir.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Você pode renderizar bibliotecas HTML ou interativas, como a Plotly, usando displayHTML() .
Para desenhar esta imagem, execute o código de exemplo a seguir.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
Exibia a saída HTML de DataFrames do pandas como a saída padrão. Os notebooks do Fabric mostram automaticamente o conteúdo HTML com estilo.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df