Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Esse recurso está na versão prévia.
O Fabric Runtime oferece integração perfeita no ecossistema do Microsoft Fabric, oferecendo um ambiente robusto para projetos de engenharia de dados e ciência de dados alimentados pelo Apache Spark.
Este artigo apresenta o Fabric Runtime 2.0 Public Preview, o runtime mais recente projetado para cálculos de Big Data no Microsoft Fabric. Ele destaca os principais recursos e componentes que fazem desta versão um passo significativo para análise escalonável e cargas de trabalho avançadas.
O Fabric Runtime 2.0 incorpora os seguintes componentes e atualizações projetados para aprimorar seus recursos de processamento de dados:
- Apache Spark 4.1
- Sistema operacional: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,2
- R: 4.5.2
Importante
A equipe do Microsoft Fabric está lançando uma atualização para o Microsoft Fabric Runtime 2.0. Como parte dessa atualização, a atualização para Python introduz uma mudança marcante para clientes que utilizam artefatos do Ambiente com bibliotecas de python e roda. Os clientes veem uma das duas mensagens de erro durante a execução de um Notebook ou de uma Definição de Trabalho do Spark (SJD):
- Erro: aviso: 1 descontinuação (desde a versão 2.13.0); para mais detalhes, ative
:setting -deprecationou:replay -deprecation. Fonte: SparkCoreService. - "LibraryManagementError": "Foi detectada uma atualização para o ambiente base de Spark Python. Por favor, republique o meio ambiente.|UserError"
Ações necessárias
Republique seu Ambiente (incluindo as bibliotecas). Para isso, remova todas as bibliotecas, publique o Ambiente, adicione novamente todas as bibliotecas e publique novamente. Esse processo recria o ambiente usando o runtime Python atualizado e resolve o problema.
Dica
O Fabric Runtime 2.0 inclui suporte para o Mecanismo de Execução Nativa, que pode melhorar significativamente o desempenho sem mais custos. Você pode habilitar o mecanismo de execução nativo no nível do ambiente para que todos os trabalhos e notebooks herdem automaticamente os recursos de desempenho aprimorados.
Habilitar o Runtime 2.0
Você pode habilitar o Runtime 2.0 no nível do workspace ou no nível do item de ambiente. Use a configuração do workspace para aplicar o Runtime 2.0 como o padrão para todas as cargas de trabalho do Spark em seu workspace. Como alternativa, crie um item de ambiente com o Runtime 2.0 para usar com notebooks específicos ou definições de trabalho do Spark, o que substitui o padrão do workspace.
Habilitar o Runtime 2.0 nas configurações do Workspace
Para definir o Runtime 2.0 como o padrão para todo o workspace:
Navegue até a página de configurações do Workspace no workspace do Fabric.
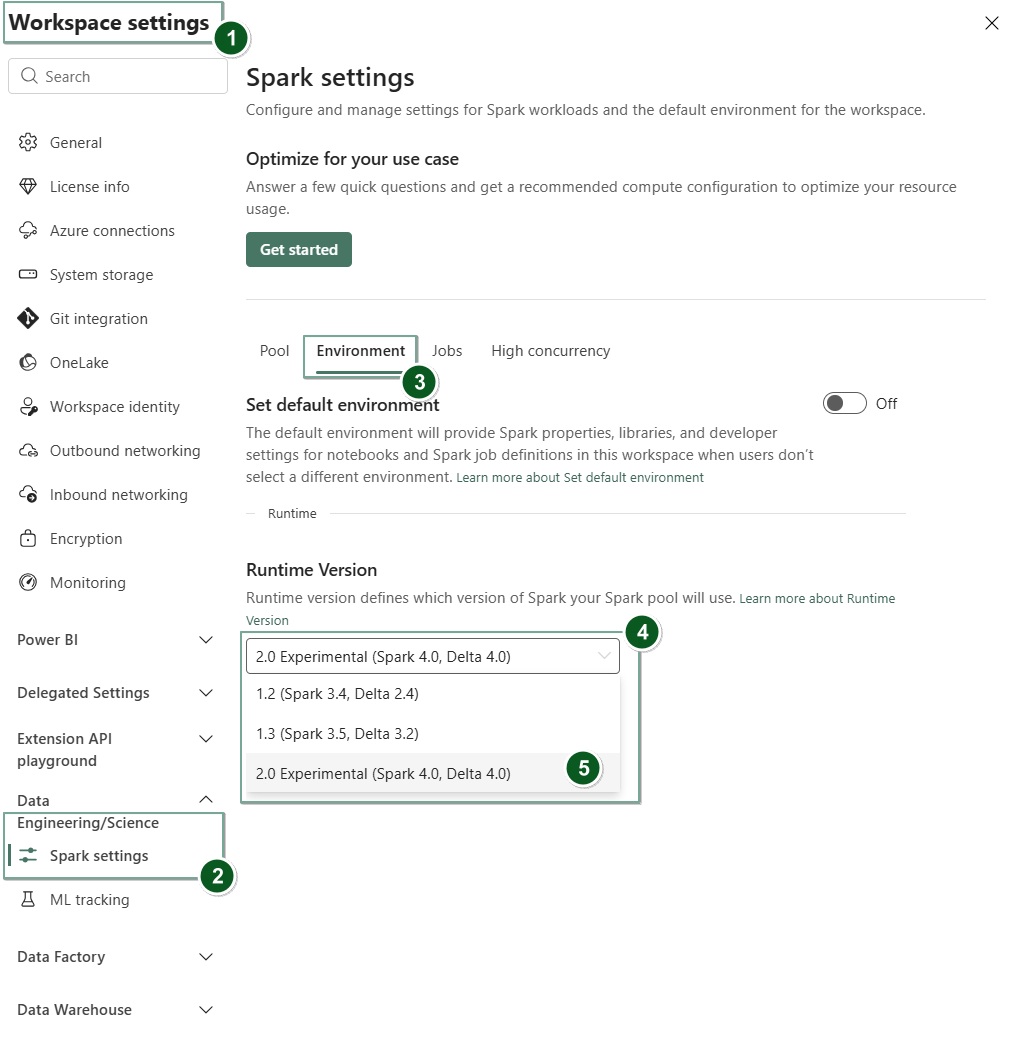
Selecione a guia Engenharia de Dados/Ciência e selecione as configurações do Spark.
Selecione a guia Ambiente.
No menu suspenso Versão do runtime, selecione Prévia Pública 2.0 (Spark 4.1, Delta 4.2) e salve suas alterações.
O runtime 2.0 é definido como o runtime padrão para seu workspace.

Habilitar o Runtime 2.0 em um item de Ambiente
Para usar o Runtime 2.0 com notebooks específicos ou definições de trabalho do Spark:
Crie um novo item de Ambiente ou abra um existente.
No menu suspenso Runtime, selecione Visualização Pública 2.0 (Spark 4.1, Delta 4.2), Salvar e Publicar suas alterações.
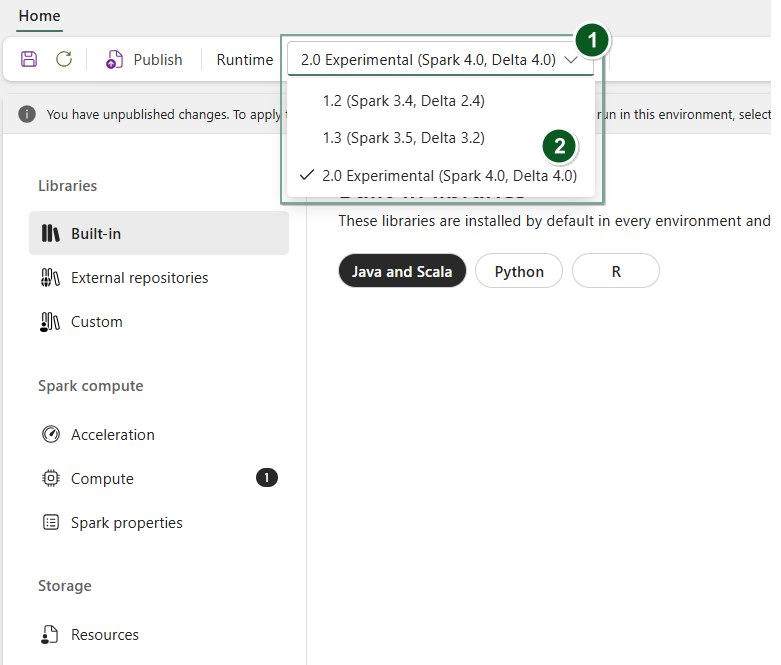
Em seguida, você pode usar esse item de Ambiente com seu Notebook ou Definição de Trabalho do Spark.

Agora você pode começar a experimentar as melhorias e funcionalidades mais recentes introduzidas no Fabric Runtime 2.0 (Spark 4.1 e Delta Lake 4.2).
Versão prévia pública
A fase pública de pré-visualização do Fabric Runtime 2.0 oferece acesso a novos recursos e APIs tanto do Spark 4.1 quanto do Delta Lake 4.2. A versão prévia permite que você use os aprimoramentos mais recentes baseados em Spark e Delta imediatamente, assegurando também uma preparação e transição suaves para mudanças melhoradas e aprimoradas, como as versões mais recentes do Java, Scala e Python.
Dica
Para obter informações atualizadas, uma lista detalhada de alterações e as notas de versão específicas dos runtimes do Fabric, verifique e inscreva-se em Versões e Atualizações de Runtimes do Spark.
Principais destaques
Aprimoramentos do mecanismo de desempenho e execução
O Fabric Runtime 2.0 inclui o Mecanismo de Execução Nativa, que fornece melhorias significativas de desempenho em relação ao Spark de software livre. O mecanismo usa o processamento vetorizado para acelerar as consultas do Spark na infraestrutura do Lakehouse sem a necessidade de alterações de código.
Principais recursos de desempenho no Runtime 2.0:
- Até seis vezes mais rápido: os parâmetros de comparação mostram um desempenho até seis vezes mais rápido em comparação com o Spark de software livre em cargas de trabalho de TPC-DS.
- Análise de CSV vetorizada: o mecanismo de execução nativo inclui um analisador CSV vetorizado que acelera a ingestão de CSV e cargas de trabalho de consulta. A análise de JSON vetorizada e o suporte ao Streaming Estruturado do Spark são planejados para atualizações futuras.
Para habilitar o mecanismo de execução nativo, consulte o mecanismo de execução nativo para Engenharia de Dados do Fabric.
Apache Spark 4.1
O Apache Spark 4.0 marcou um marco significativo como o lançamento inaugural da série 4.x, incorporando o esforço coletivo da vibrante comunidade de software livre. Fabric Runtime 2.0 agora é executado no Apache Spark 4.1, que se baseia nessa base com melhorias adicionais.
Nesta versão, o SPARK SQL é significativamente enriquecido com novos recursos avançados projetados para aumentar a expressividade e a versatilidade para cargas de trabalho SQL, como suporte a tipo de dados VARIANT, funções definidas pelo usuário do SQL, variáveis de sessão, sintaxe de pipe e ordenação de cadeia de caracteres. PySpark demonstra dedicação contínua à sua área de funcionalidade e à experiência geral do desenvolvedor, trazendo uma API de plotagem nativa, uma nova API de Fonte de Dados em Python, suporte para UDTFs do Python e criação de perfil unificada para UDFs do PySpark, juntamente com vários outros aprimoramentos. O Streaming Estruturado evolui com as principais adições que fornecem maior controle e facilidade de depuração, notadamente a introdução da API de Estado Arbitrário v2 para um gerenciamento de estado mais flexível e a Fonte de Dados de Estado para facilitar a depuração.
Você pode verificar a lista completa e as alterações detalhadas aqui:
Observação
No Spark 4.x, o SparkR foi preterido e pode ser removido em uma versão futura.
Delta Lake 4.2
O Delta Lake 4.2 se baseia em lançamentos anteriores do Delta Lake, mantendo o compromisso de tornar o Delta Lake interoperável em vários formatos, mais fácil de trabalhar e mais eficiente. Inclui novos recursos poderosos, otimizações de desempenho e aprimoramentos fundamentais para o futuro dos lakehouses de dados abertos.
Para a lista completa e as mudanças detalhadas introduzidas com Delta Lake 3.3, 4.0, 4.1 e 4.2, veja:
Layout e otimização de dados
O Runtime 2.0 dá suporte a recursos de layout e otimização de dados para tabelas Delta:
- Ordenação Z: organize dados em arquivos de tabela Delta por colunas especificadas para melhorar o desempenho da consulta para consultas filtradas.
- Clustering Líquido: uma abordagem de clustering flexível que otimiza automaticamente o layout de dados sem manutenção manual.
- Carregamento de instantâneo delta paralelo: o mecanismo de execução nativo carrega instantâneos de tabela Delta em paralelo, reduzindo o tempo de inicialização da consulta para tabelas grandes.
Importante
Recursos específicos do Delta Lake 4.2 são experimentais e funcionam apenas em experiências Spark, como Cadernos e Definições de Cargos Spark. Se você precisar usar as mesmas tabelas delta lake em várias cargas de trabalho do Microsoft Fabric, não habilite esses recursos. Para saber mais sobre quais versões e recursos de protocolo são compatíveis em todas as experiências do Microsoft Fabric, veja Interoperabilidade do formato de tabela Delta Lake.
Gerenciamento de computação no Runtime 2.0
O Runtime 2.0 dá suporte aos seguintes recursos de gerenciamento de computação:
- Perfis de recurso: configure alocações de recursos predefinidas para sessões do Spark para corresponder aos requisitos de carga de trabalho e controlar os custos.
- Pools ao vivo personalizados (versão prévia): crie pools do Spark dedicados e pré-aquecidos que reduzam o tempo de inicialização da sessão. Os pools dinâmicos personalizados estão disponíveis em versão prévia para cargas de trabalho do Runtime 2.0.
Limitações e anotações
- Os recursos específicos do Delta Lake 4.x são experimentais e funcionam apenas em experiências do Spark, como notebooks e definições de trabalho do Spark. Se você precisar usar as mesmas tabelas delta lake em várias cargas de trabalho do Fabric, não habilite esses recursos. Para obter mais informações, consulte a interoperabilidade do formato de tabela Delta Lake.
- O runtime 2.0 está em versão prévia pública. Alguns recursos e APIs podem ser alterados antes da disponibilidade geral.
- A extensão VS Code do Fabric Spark oferece suporte ao Runtime 2.0 para desenvolvimento de blocos de notas e definição de trabalhos no Spark.
Conteúdo relacionado
- Ambientes de execução do Apache Spark no Fabric – Visão geral, gerenciamento de versões e suporte a múltiplos ambientes de execução
- Guia de migração do Spark Core
- Guias de migração de SQL, Datasets e DataFrame
- Guia de migração de Streaming Estruturado
- Guia de migração de MLlib (aprendizado de máquina)
- Guia de migração do PySpark (Python no Spark)
- Guia de migração do SparkR (R no Spark)