Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste tutorial, você usará notebooks com o runtime do Spark para transformar e preparar dados brutos em seu sistema de lakehouse.
Pré-requisitos
Antes de começar, você deve concluir os tutoriais anteriores nesta série:
- Criar um lakehouse
- Ingerir dados no repositório de dados
- Certifique-se de que os esquemas de lakehouse estejam habilitados em seu lakehouse.
Preparar dados
Nas etapas anteriores do tutorial, você tem dados brutos ingeridos da origem para a seção Arquivos da lakehouse. Agora você pode transformar esses dados e prepará-los para criar tabelas delta.
Baixe os notebooks na pasta Código-fonte do Tutorial do Lakehouse.
No seu navegador, vá para o seu espaço de trabalho do Fabric no portal do Fabric.
Selecione Importar>Bloco de Anotações>deste computador.
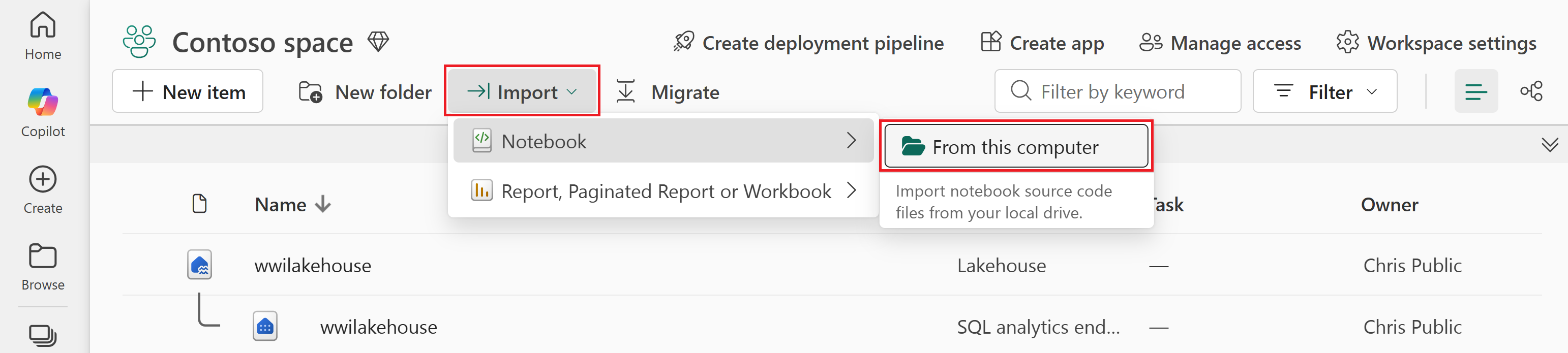
Selecione Carregar no painel Status de importação que se abre à direita da tela.
Selecione apenas o bloco de anotações que corresponde ao idioma de codificação preferido.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
SQL do Spark (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Selecione Abrir. Uma notificação que indica o status da importação aparece no canto superior direito da janela do navegador.
Depois que a importação for bem-sucedida, vá para a exibição de itens do workspace para verificar o notebook importado.
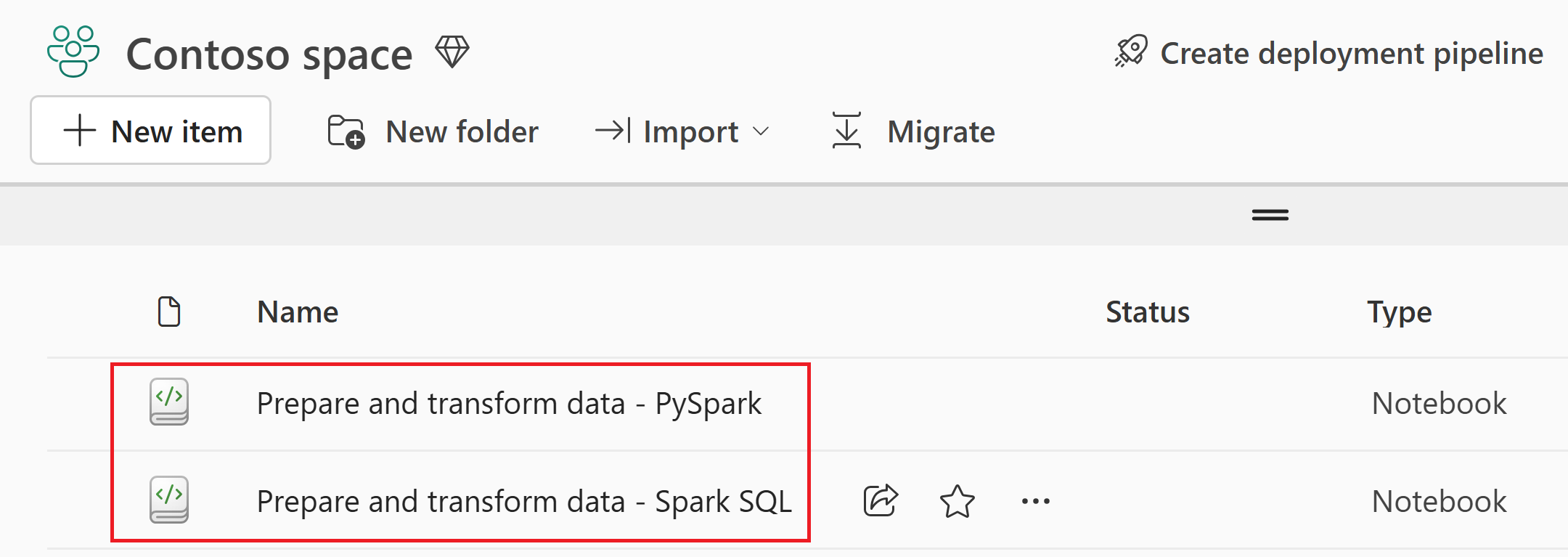
Selecione o wwilakehouse lakehouse para abri-lo, para que o bloco de anotações que você abrir em seguida esteja vinculado a ele.
No menu de navegação superior, selecione Abrir bloco de anotações>bloco de anotações existente.
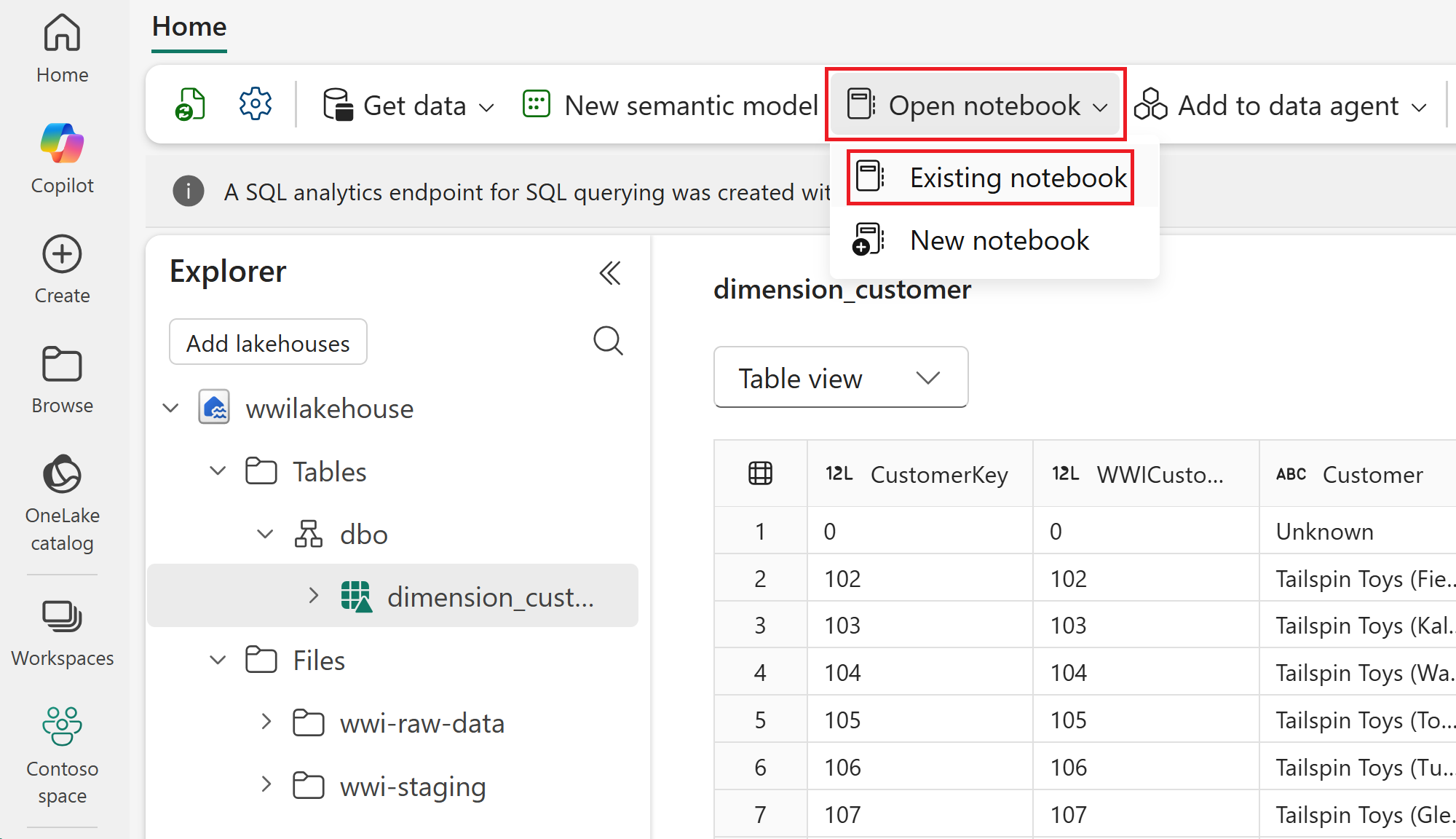
Selecione seu bloco de anotações importado para PySpark ou Spark SQL e selecione Abrir. O bloco de anotações já está vinculado à sua lakehouse aberta, conforme mostrado no Lakehouse Explorer.



Agora você está pronto para executar as células do notebook que criam e transformam suas tabelas Delta.
Nas seções a seguir, execute as células do notebook sequencialmente. Para executar uma célula, selecione o ícone Executar que aparece à esquerda da célula em foco. Você também pode selecionar Executar tudo na faixa de opções superior (Página Inicial) para executar todas as células em sequência.
Importante
Este tutorial requer que os esquemas do lakehouse sejam habilitados. Se os esquemas não estiverem habilitados, o código neste tutorial não funcionará conforme o esperado.
No bloco de anotações importado, você verá as seções Caminho 1 e Caminho 2 . Para este tutorial, use o Caminho 1 (esquemas de lakehouse habilitados) e ignore o Caminho 2 (esquemas de lakehouse não habilitados).
Criar tabelas Delta
Nesta seção, você executará as células do notebook para criar tabelas Delta com base nos dados brutos.
As tabelas seguem um esquema estrela, que é um padrão comum para organizar dados analíticos:
- Uma tabela de fatos (
fact_sale) contém os eventos mensuráveis da empresa – nesse caso, transações de vendas individuais com quantidades, preços e lucro. -
As tabelas de dimensão (
dimension_city,dimension_customer, ,dimension_date,dimension_employee)dimension_stock_itemcontêm os atributos descritivos que dão contexto aos fatos, como onde ocorreu uma venda, quem a fez e quando.
Nesta página do tutorial, selecione a guia que corresponde ao bloco de anotações importado e continue usando essa mesma guia para todas as etapas. As abas estão neste artigo, não no caderno.
Célula 1 – Configuração da sessão do Spark. Essa célula habilita dois recursos do Fabric que otimizam como os dados são gravados e lidos em células subsequentes. V-order otimiza o layout do arquivo Parquet para leituras mais rápidas e melhor compactação. A otimização da gravação reduz o número de arquivos gravados e aumenta o tamanho do arquivo individual.
Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
Célula 2 – Fato – Venda. Essa célula lê dados brutos de parquet de
Files/wwi-raw-data/full/fact_sale_1y_full, adiciona colunas referentes a partes da data (Ano, Trimestre e Mês) e gravafact_salecomo uma tabela Delta particionada por Ano e Trimestre.Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Célula 3 – Dimensões. Essa célula lê os conjuntos de dados parquet de cinco dimensões e grava-os como tabelas Delta (
dimension_city,dimension_customer,dimension_date,dimension_employeeedimension_stock_item) emTables/dbo/....Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
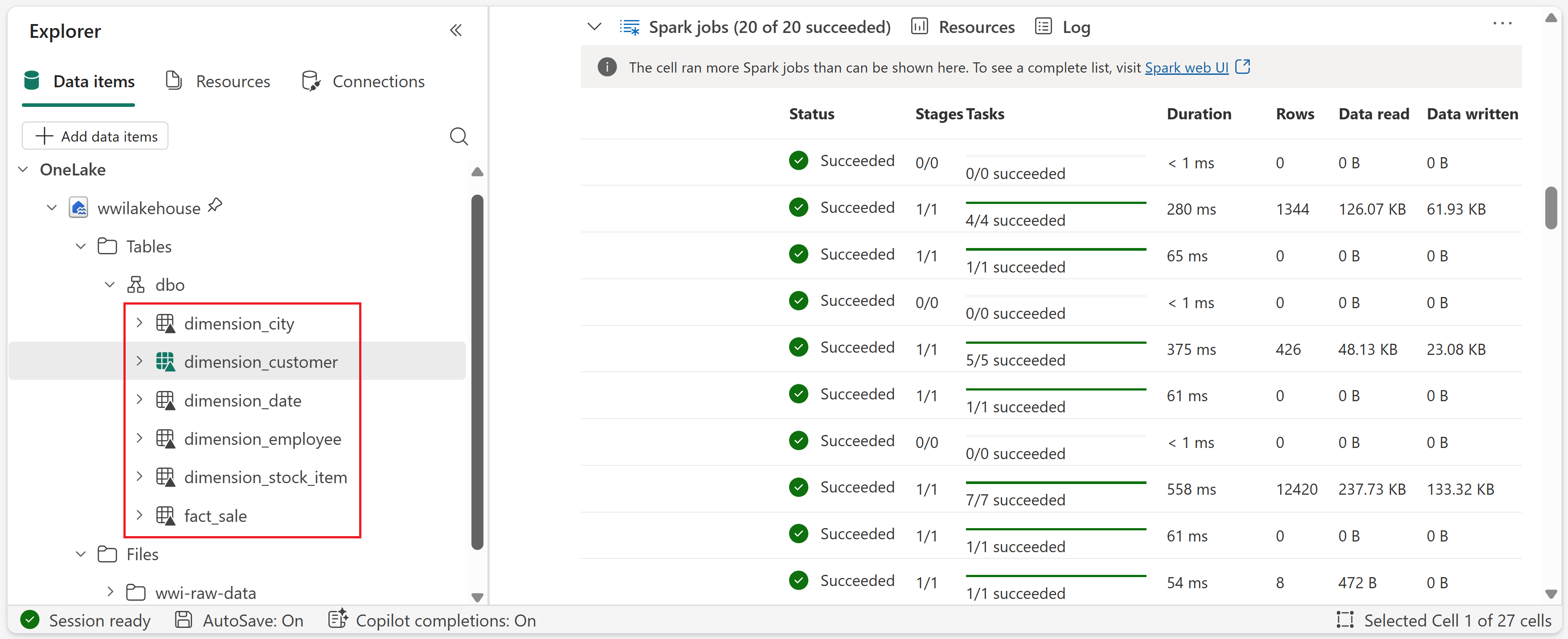
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Para validar as tabelas criadas, clique com o botão direito do mouse no wwilakehouse lakehouse no explorer e selecione Atualizar. As tabelas são exibidas.

Transformar dados para agregações de negócios
Nesta seção, você continuará no mesmo bloco de anotações e executará as próximas células para criar tabelas agregadas das tabelas Delta criadas na seção anterior.
Verifique se o bloco de anotações ainda está vinculado ao wwilakehouse.
Célula 4 – Carregar tabelas de origem para transformação (somente PySpark). Se você estiver usando o notebook PySpark, execute esta célula para carregar tabelas Delta em DataFrames para as etapas de agregação a seguir.
Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
Célula 5 – Criar
aggregate_sale_by_date_city. Essa célula une dados de vendas, data e cidade e, em seguida, cria a tabela de agregação no nível da cidade.Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Célula 6 – Criar
aggregate_sale_by_date_employee. Essa célula une dados de vendas, datas e funcionários e cria a tabela de agregação no nível do funcionário.Execute essa célula e aguarde até que ela seja concluída antes de passar para a próxima etapa.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Para validar as tabelas criadas, clique com o botão direito do mouse no wwilakehouse lakehouse no explorer e selecione Atualizar. As tabelas de agregação são exibidas.

Este tutorial grava dados em formato de arquivos Delta Lake. O Fabric descobre e registra automaticamente essas tabelas no metastore, portanto, você não precisa executar instruções separadas CREATE TABLE .