Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Observação
A tarefa do Apache Airflow é impulsionada pelo Apache Airflow.
O dbt (Data Build Tool) é uma CLI (interface de linha de comando) de código aberto que simplifica a transformação e modelagem de dados em warehouses de dados, gerenciando códigos SQL complexos de forma estruturada e sustentável. Ele permite que as equipes de dados criem transformações confiáveis e testáveis no núcleo de seus pipelines analíticos.
Quando combinados com o Apache Airflow, os recursos de transformação do dbt são aprimorados pelos recursos de agendamento, orquestração e gerenciamento de tarefas do Airflow. Essa abordagem combinada, usando a expertise de transformação do dbt juntamente com o gerenciamento de fluxos de trabalho do Airflow, oferece pipelines de dados eficientes e robustos, resultando em decisões mais rápidas e assertivas baseadas em dados.
Este tutorial ilustra como criar um DAG do Apache Airflow que utiliza o dbt para transformar dados armazenados no Data Warehouse do Microsoft Fabric.
Pré-requisitos
Para começar, você deve concluir os seguintes pré-requisitos:
Crie o Principal de Serviço. Adicione a entidade de serviço como
Contributorno workspace onde você cria o data warehouse.Se ainda não tiver um, crie um warehouse do Fabric. Faça a ingestão dos dados de amostra no warehouse usando pipeline de dados. Neste tutorial, usamos a amostra NYC Taxi-Green.
Transformar os dados armazenados no warehouse do Fabric usando a DBT
A seção mostrará detalhes sobre as seguintes etapas:
- Especificar os requisitos.
- Crie um projeto dbt no armazenamento gerenciado do Fabric fornecido pelo trabalho do Apache Airflow.
- Crie um DAG do Apache Airflow para orquestrar trabalhos do dbt
Especificar os requisitos
Crie um arquivo requirements.txt na pasta dags. Adicione os pacotes a seguir como requisitos do Apache Airflow.
astronomer-cosmos: este pacote é usado para executar seus projetos dbt core como DAGs e grupos de tarefas do Apache Airflow.
dbt-fabric: esse pacote é usado para criar um projeto dbt, que pode ser implantado em um Data Warehouse do Fabric
astronomer-cosmos==1.10.1 dbt-fabric==1.9.5
Crie um projeto dbt no armazenamento gerenciado Fabric, fornecido pela tarefa do Apache Airflow.
Nesta seção, criamos um projeto dbt de exemplo no trabalho do Apache Airflow para o conjunto de dados
nyc_taxi_greencom a estrutura de diretório a seguir.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetCrie a pasta chamada
nyc_taxi_greenna pastadagscom o arquivoprofiles.yml. Essa pasta contém todos os arquivos necessários para o projeto com DBT.
Copie o conteúdo a seguir em
profiles.yml. Esse arquivo de configuração contém detalhes de conexão de banco de dados e perfis usados pela DBT. Atualize os valores do marcador e salve o arquivo.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Crie o arquivo
dbt_project.ymle copie o conteúdo a seguir. Esse arquivo especifica a configuração em nível de projeto.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableCrie a pasta
modelsdentro da pastanyc_taxi_green. Neste tutorial, elaboramos a amostra de modelo no arquivo chamadonyc_trip_count.sqlque cria a tabela mostrando o número de viagens por dia e por fornecedor. Copie o conteúdo a seguir no arquivo.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Crie um DAG do Apache Airflow para orquestrar trabalhos do dbt
Crie um arquivo chamado
my_cosmos_dag.pyna pastadagse cole o conteúdo a seguir nele.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig from airflow import DAG DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Executar o DAG
Execute a DAG dentro de um processo do Apache Airflow.
Para ver o DAG carregado na interface do usuário do Apache Airflow, clique em
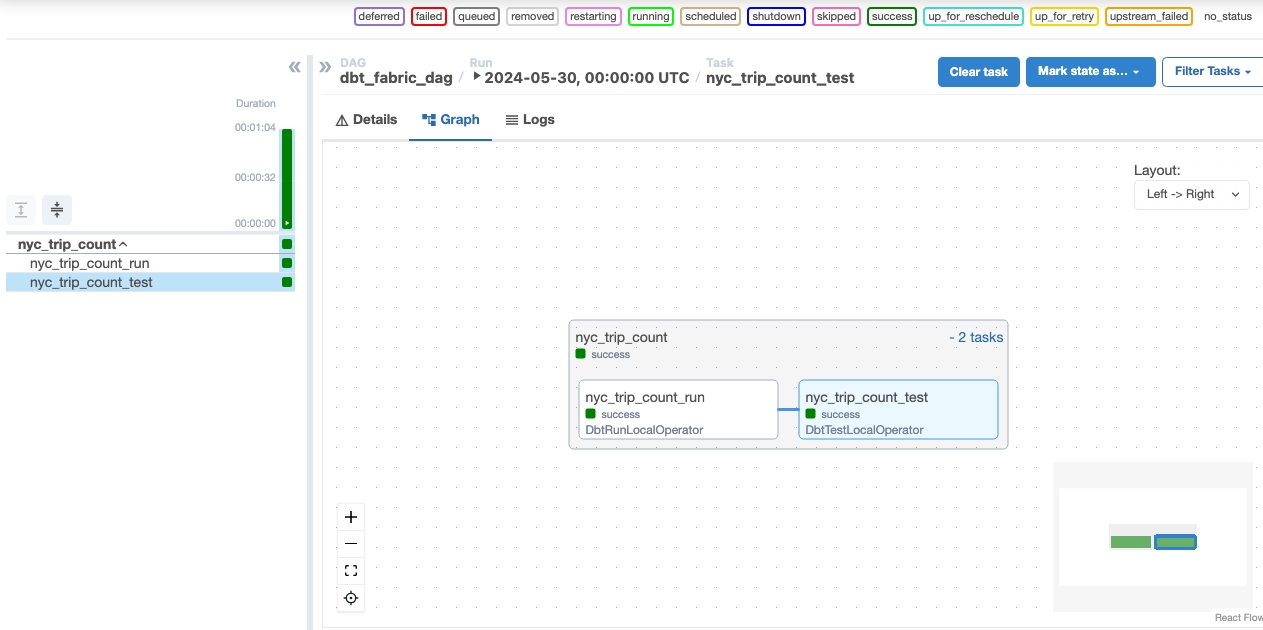
Monitor in Apache Airflow.



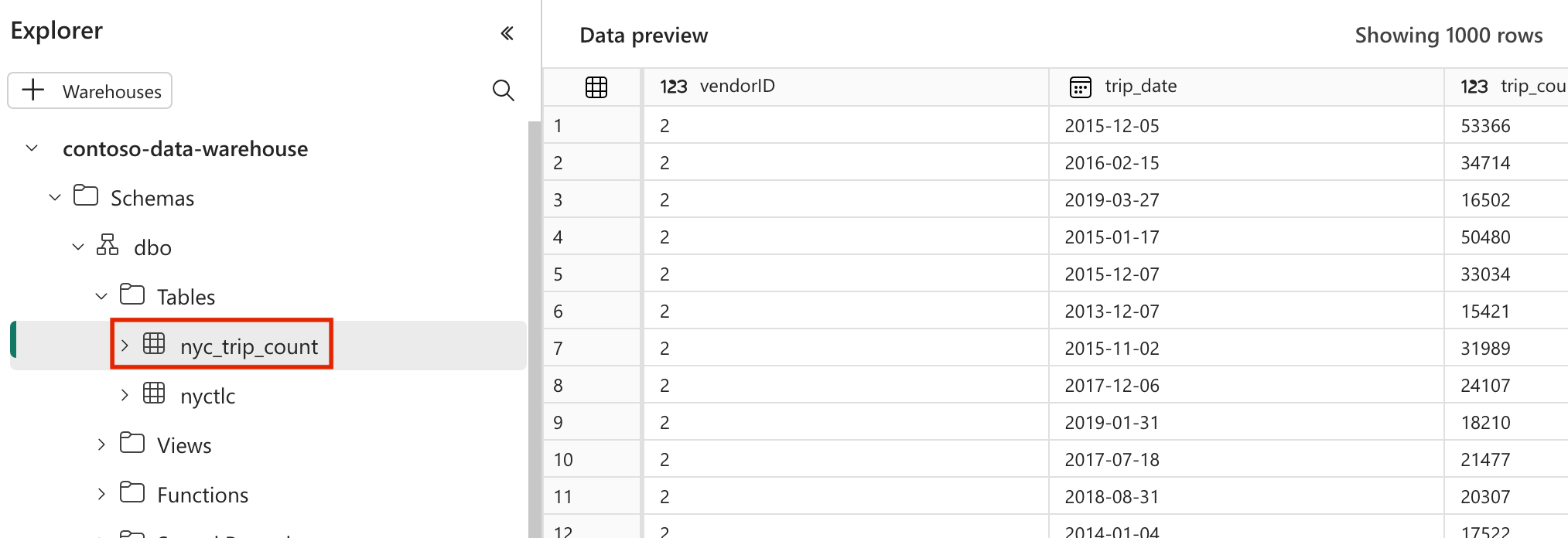
Validar os dados
- Após uma execução bem-sucedida, para validar seus dados, você pode ver a nova tabela chamada 'nyc_trip_count.sql' criada no data warehouse do Fabric.