Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este módulo leva cerca de 25 minutos para ser concluído. Você cria um fluxo de dados, aplica transformações e move os dados brutos da tabela de camada de dados bronze para uma tabela de camada de dados de ouro .
Com os dados brutos carregados na tabela Bronze Lakehouse do último módulo, agora você pode enriquecê-los. Você a combinará com outra tabela que contém descontos para cada fornecedor e suas viagens em um dia específico. Em seguida, a tabela final gold Lakehouse é carregada e fica pronta para consumo.
As etapas de alto nível no fluxo de dados são:
- Obtenha dados brutos da tabela Lakehouse criada pelo trabalho de cópia no Módulo 1: Ingestão de dados com um trabalho de cópia.
- Transforme os dados importados da tabela Lakehouse.
- Conecte-se a um arquivo CSV que contém dados de descontos.
- Transforme os dados de descontos.
- Combine os dados de viagens e descontos.
- Carregue a consulta de saída na tabela Gold Lakehouse.
Pré-requisitos
Módulo 1 desta série de tutoriais: Ingestão de dados com uma tarefa de cópia
Obter dados de uma tabela Lakehouse
Na barra lateral, selecione seu workspace, selecione Novo item e, em seguida, Dataflow Gen2 para criar um novo Fluxo de Dados Gen2.
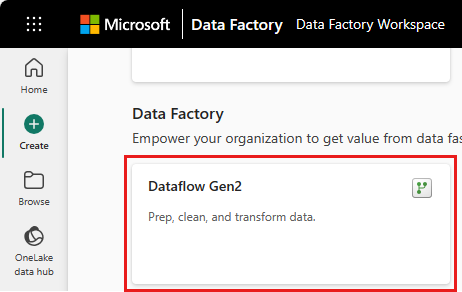
No novo menu de fluxo de dados, selecione Obter dados e, em seguida, Mais....
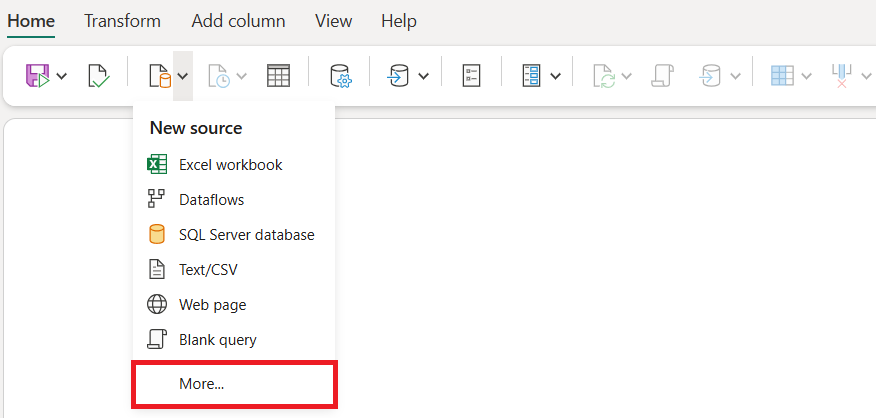
Procure e selecione o conector lakehouse .
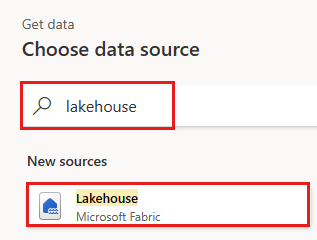
A caixa de diálogo Conectar à fonte de dados é exibida e uma nova conexão é criada automaticamente para você com base no usuário conectado no momento. Selecione Próximo.
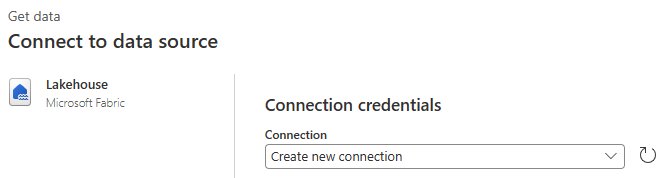
A caixa de diálogo Escolher dados é exibida. Use o painel de navegação para localizar o Lakehouse que você criou para o destino no módulo anterior. Pode estar na pasta Meu espaço de trabalho. Selecione a tabela de dados Bronze . Em seguida, selecione Criar.
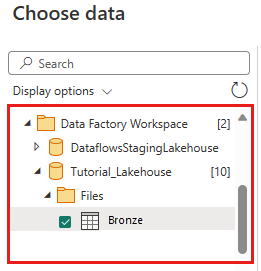
(Opcional) Depois que a tela for preenchida com os dados, você poderá definir informações de perfil de coluna , pois isso é útil para criação de perfil de dados. Você pode aplicar a transformação certa e direcionar os valores de dados certos com base nela.
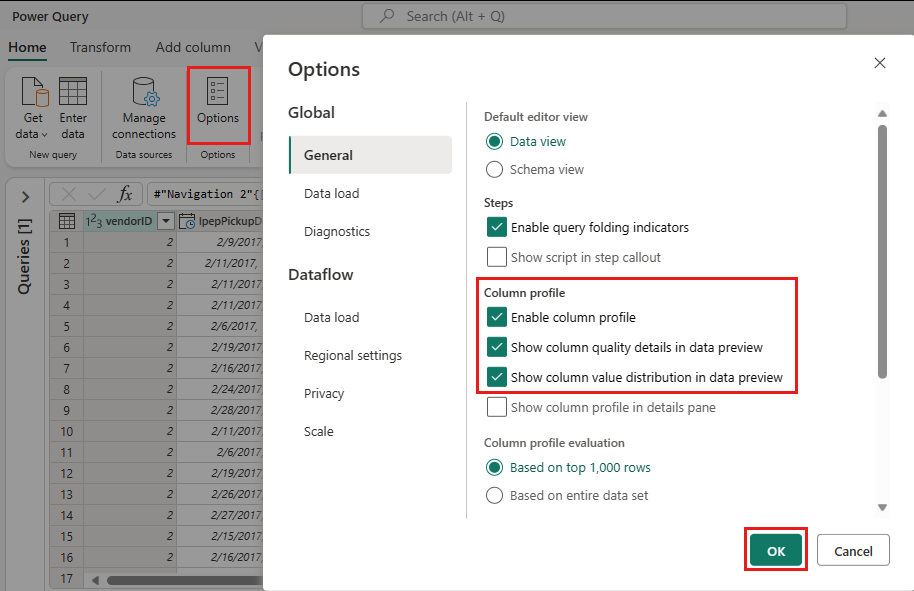
Para fazer isso, selecione Opções no painel da faixa de opções, selecione as três primeiras opções no perfil Coluna e selecione OK.



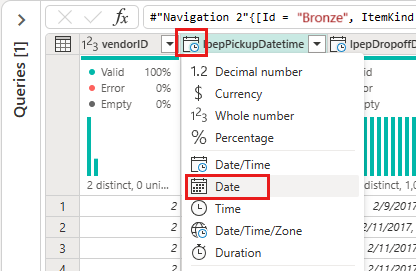
Transformar os dados importados do Lakehouse
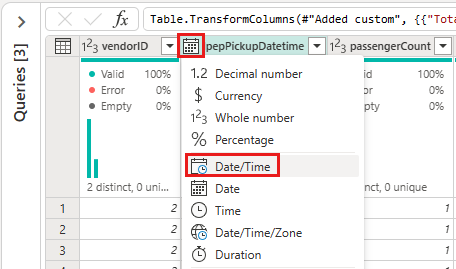
Selecione o ícone de tipo de dados no cabeçalho da coluna da segunda coluna, IpepPickupDatetime, para exibir um menu de lista suspensa e selecione o tipo de dados no menu para converter a coluna do tipo Data/Hora em Data .
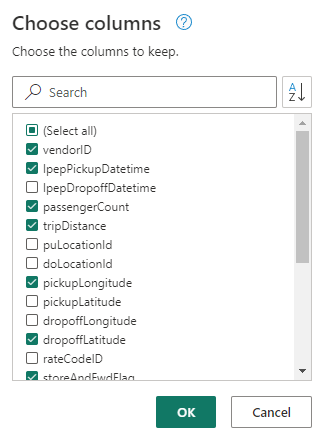
(Opcional) Na guia Página Inicial da faixa de opções, selecione a opção Escolher colunas no grupo Gerenciar colunas .

(Opcional) Na caixa de diálogo Escolher colunas , desmarque algumas colunas listadas aqui e selecione OK.
- ID do fornecedor
- lpepPickupDatetime
- númeroDePassageiros
- distância da viagem
- picukupLongitude
- dropoffLatitude
- storeAndFwdFlag
- totalAmount
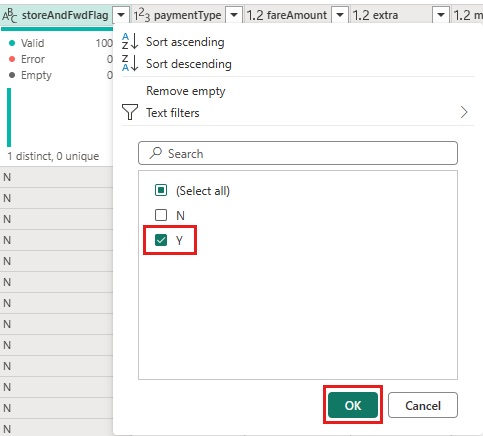
Selecione o filtro da coluna storeAndFwdFlag e o menu suspenso de filtragem e classificação. (Se você vir que uma lista de avisos pode estar incompleta, selecione Carregar mais para ver todos os dados.)

Selecione 'Y' para mostrar apenas as linhas em que um desconto foi aplicado e selecione OK.
Aguarde até que os dados sejam filtrados.
Selecione o menu lista suspensa de filtro e classificação de coluna IpepPickupDatetime, selecione Filtros de data e escolha o filtro Entre... fornecido para tipos de Data e Data/Hora.
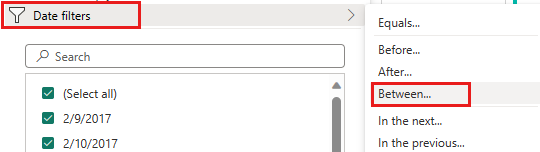
Na caixa de diálogo Filtrar linhas , selecione datas entre 1º de janeiro de 2015 e 31 de janeiro de 2015 e selecione OK.
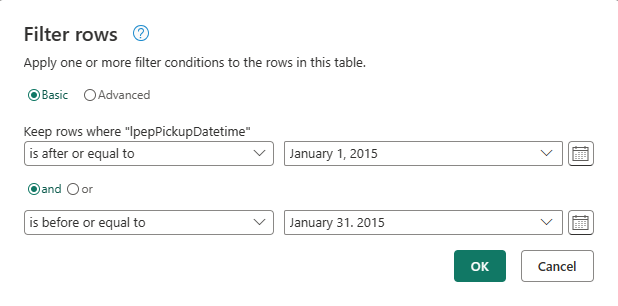
Aguarde até que os dados sejam filtrados.

Conectar-se a um arquivo CSV que contém dados de desconto
Com os dados das viagens em mãos, queremos carregar os dados que contêm os respectivos descontos para cada dia e VendorID, e preparar adequadamente os dados antes de combiná-los com os dados das viagens.
Na guia Página Inicial no menu editor de fluxo de dados, selecione a opção Obter dados e escolha Texto/CSV.
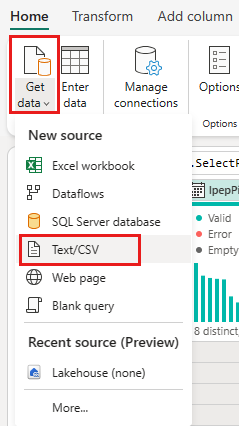
Na caixa de diálogo Conectar à fonte de dados , forneça os seguintes detalhes:
-
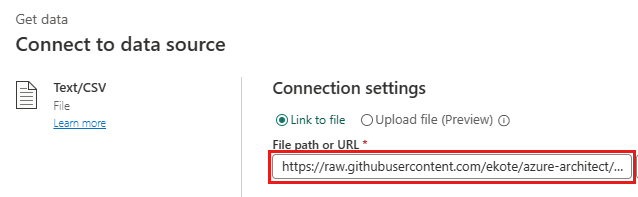
Caminho do arquivo ou URL -
https://raw.githubusercontent.com/ekote/azure-architect/master/Generated-NYC-Taxi-Green-Discounts.csv - Tipo de autenticação – Anônimo
Em seguida, selecione Avançar.
-
Caminho do arquivo ou URL -
Na caixa de diálogo Visualizar dados do arquivo , selecione Criar.



Transforme os dados de desconto
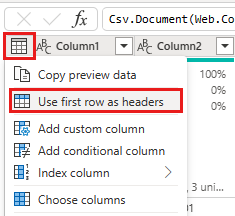
Examinando os dados, vemos que os cabeçalhos parecem estar na primeira linha. Promova-os para cabeçalhos selecionando o menu de contexto da tabela no canto superior esquerdo da área de grade de visualização para selecionar Usar a primeira linha como cabeçalhos.
Observação
Depois de promover os cabeçalhos, você pode ver uma nova etapa adicionada ao painel Etapas Aplicadas na parte superior do editor de fluxo de dados para os tipos de dados de suas colunas.
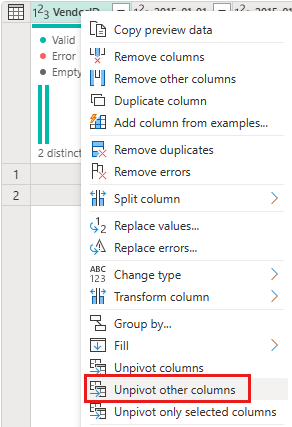
Clique com o botão direito do mouse na coluna VendorID e, no menu de contexto exibido, selecione a opção Despivotar outras colunas. Isso permite que você transforme colunas em pares de atributo-valor, em que as colunas se tornam linhas.
Com a tabela desemparelhada, renomeie as colunas Atributo e Valor clicando duas vezes nelas e alterando Atributo para Data e Valor para Desconto.
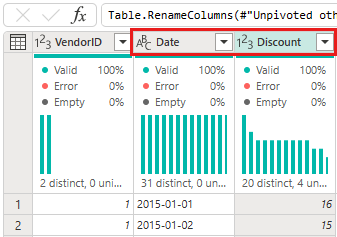
Altere o tipo de dados da coluna Data selecionando o menu de tipo de dados à esquerda do nome da coluna e escolhendo Data.
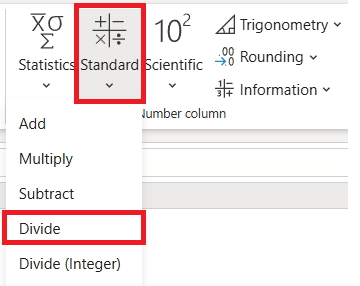
Selecione a coluna Desconto e, em seguida, selecione a guia Transformar no menu. Na seção Número de coluna , selecione Transformações numéricas padrão no submenu e escolha Dividir.
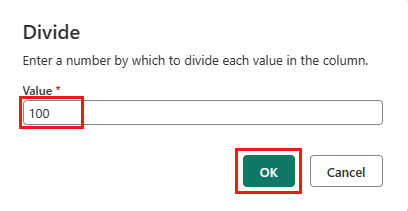
Na caixa de diálogo Dividir , insira o valor 100.

Combinar dados de viagens e descontos
A próxima etapa é combinar ambas as tabelas em uma única tabela que tenha o desconto que deve ser aplicado à viagem e o total ajustado.
Primeiro, alterne o botão Modo de exibição Diagrama na parte inferior direita da janela, para que você possa ver as duas consultas.
Selecione sua consulta de dados original (em nosso exemplo, chamada Bronze) e, na guia Página Inicial, no menu Combinar, escolha Mesclar consultas e Mesclar consultas como novas.
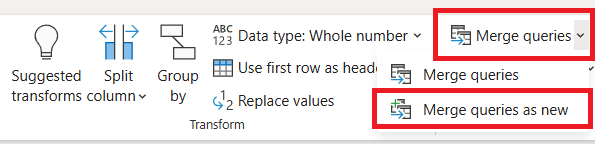
Na caixa de diálogo Mesclagem, selecione uma mesclagem externa esquerda e, em seguida, selecione Generated-NYC-Taxi-Green-Discounts na lista suspensa de tabela Direita para mesclagem, e, em seguida, clique no ícone de "lâmpada" no canto superior direito da caixa de diálogo para ver o mapeamento sugerido de colunas entre as duas tabelas.
Escolha o mapeamento sugerido para mapear a VendorID e as colunas de data de ambas as tabelas. Quando ambos os mapeamentos são adicionados, os cabeçalhos de coluna correspondentes são realçados em cada tabela.
Uma mensagem é mostrada solicitando que você permita a combinação de dados de várias fontes de dados para exibir os resultados. Selecione OK na caixa de diálogo Mesclagem .

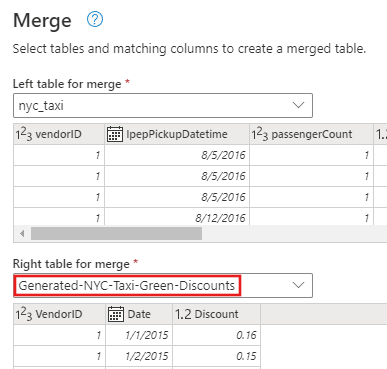
Na área da tabela, você verá inicialmente um aviso de que "As informações são necessárias sobre a privacidade dos dados". Selecione Continuar para endereçar o aviso.

Para este tutorial, selecione Ignorar Verificações de Níveis de Privacidade para este documento, pois são dados de exemplo que não têm informações confidenciais. Para suas próprias fontes de dados, defina os níveis de privacidade apropriados para proteger seus dados confidenciais.
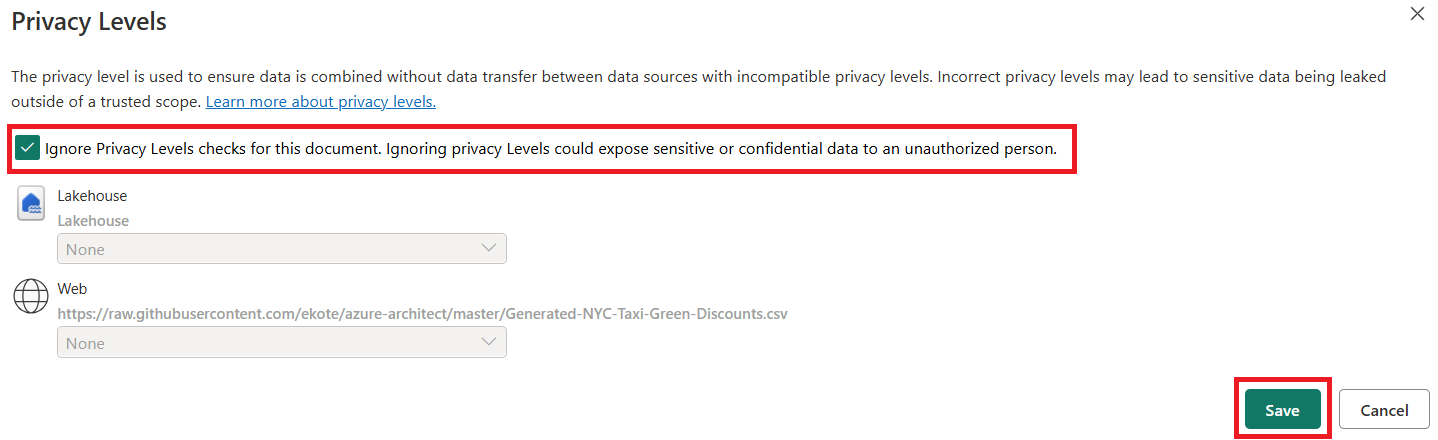
Clique em Salvar.
Observe como uma nova consulta foi criada na visualização de Diagrama mostrando a relação da nova consulta Merge com as duas consultas que você criou anteriormente. Olhando para o painel de tabela do editor, role para a direita na lista de colunas de consulta mesclada para ver que está presente uma nova coluna com valores de tabela. Esta é a coluna "Generated NYC Taxi-Green-Discounts" e seu tipo é [Table]. No cabeçalho da coluna, há um ícone com duas setas indo em direções opostas, permitindo que você selecione colunas da tabela. Desmarque todas as colunas, exceto Desconto, e selecione OK.
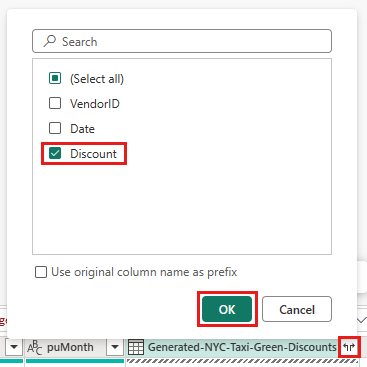
Com o valor de desconto agora no nível da linha, podemos criar uma nova coluna para calcular o valor total após o desconto. Para fazer isso, selecione a guia Adicionar coluna na parte superior do editor e escolha a coluna Personalizada no grupo Geral .
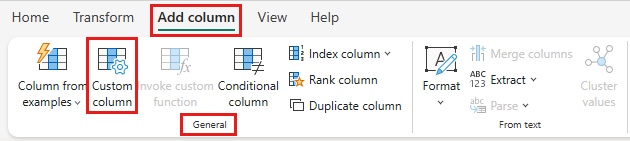
Na caixa de diálogo Coluna personalizada, você pode usar a linguagem de fórmula Power Query (também conhecida como M) para definir como sua nova coluna deve ser calculada. Insira TotalAfterDiscount para o novo nome da coluna, selecione Moeda para o tipo de dados e forneça a seguinte expressão M para a fórmula de coluna personalizada:
se [totalAmount] > 0 então [totalAmount] * (1 - [Discount]) senão [totalAmount]
Em seguida, selecione OK.
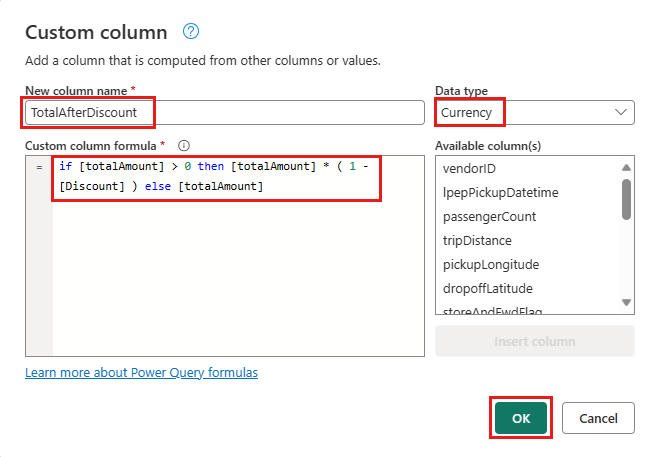
Selecione a coluna TotalAfterDiscount recém-criada e, em seguida, selecione a guia Transformar na parte superior da janela do editor. No grupo coluna Número, selecione a lista suspensa Arredondamento e, em seguida, escolha Arredondar....
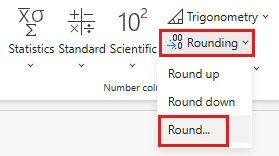
Na caixa de diálogo Round, insira 2 para o número de casas decimais e selecione OK.
Altere o tipo de dados do IpepPickupDatetime de Data para Data/Hora.
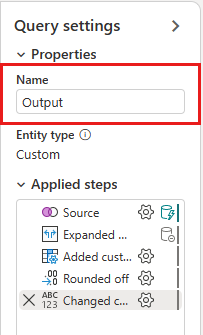
Por fim, expanda o painel configurações de consulta do lado direito do editor se ele ainda não estiver expandido e renomeie a consulta de Mesclagem para Saída.






Carregar a consulta de saída em uma tabela no Lakehouse
Com a consulta de saída agora totalmente preparada e com os dados prontos para saída, podemos definir o destino de saída para a consulta.
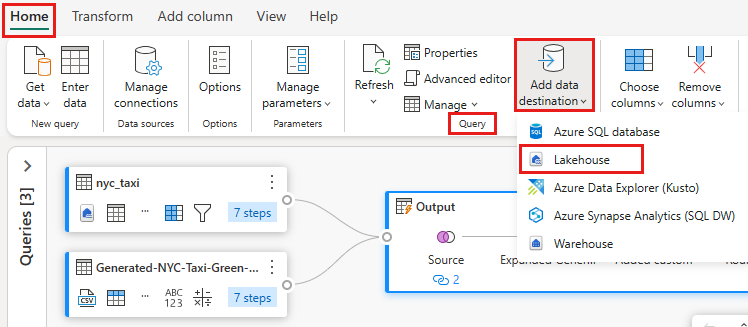
Selecione a consulta de mesclagem saída criada anteriormente. Em seguida, selecione a guia Página Inicial no editor e adicione o destino de dados do agrupamento Consultas para selecionar um destino Lakehouse.
Na caixa de diálogo Conectar ao destino de dados , sua conexão já deve estar selecionada. Selecione Avançar para continuar.
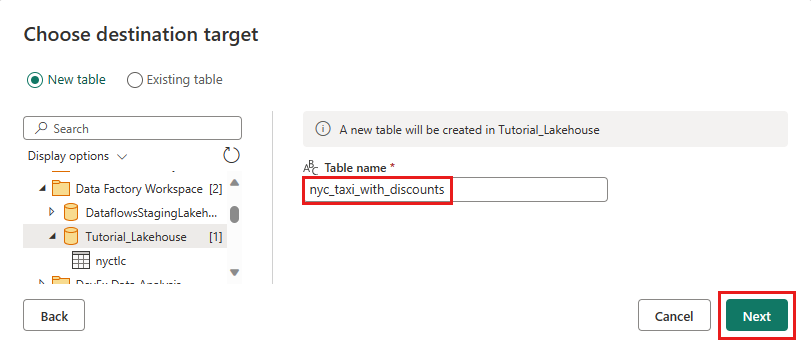
Na caixa de diálogo Escolher destino, navegue até o Lakehouse onde deseja carregar os dados, nomeie a nova tabela como nyc_taxi_with_discounts e, em seguida, selecione Avançar novamente.
Na caixa de diálogo Escolher configurações de destino , você pode usar as configurações automáticas ou desmarcar as configurações automáticas e deixar o método de atualização De substituição padrão, verificar se as colunas estão mapeadas corretamente e selecionar Salvar configurações.
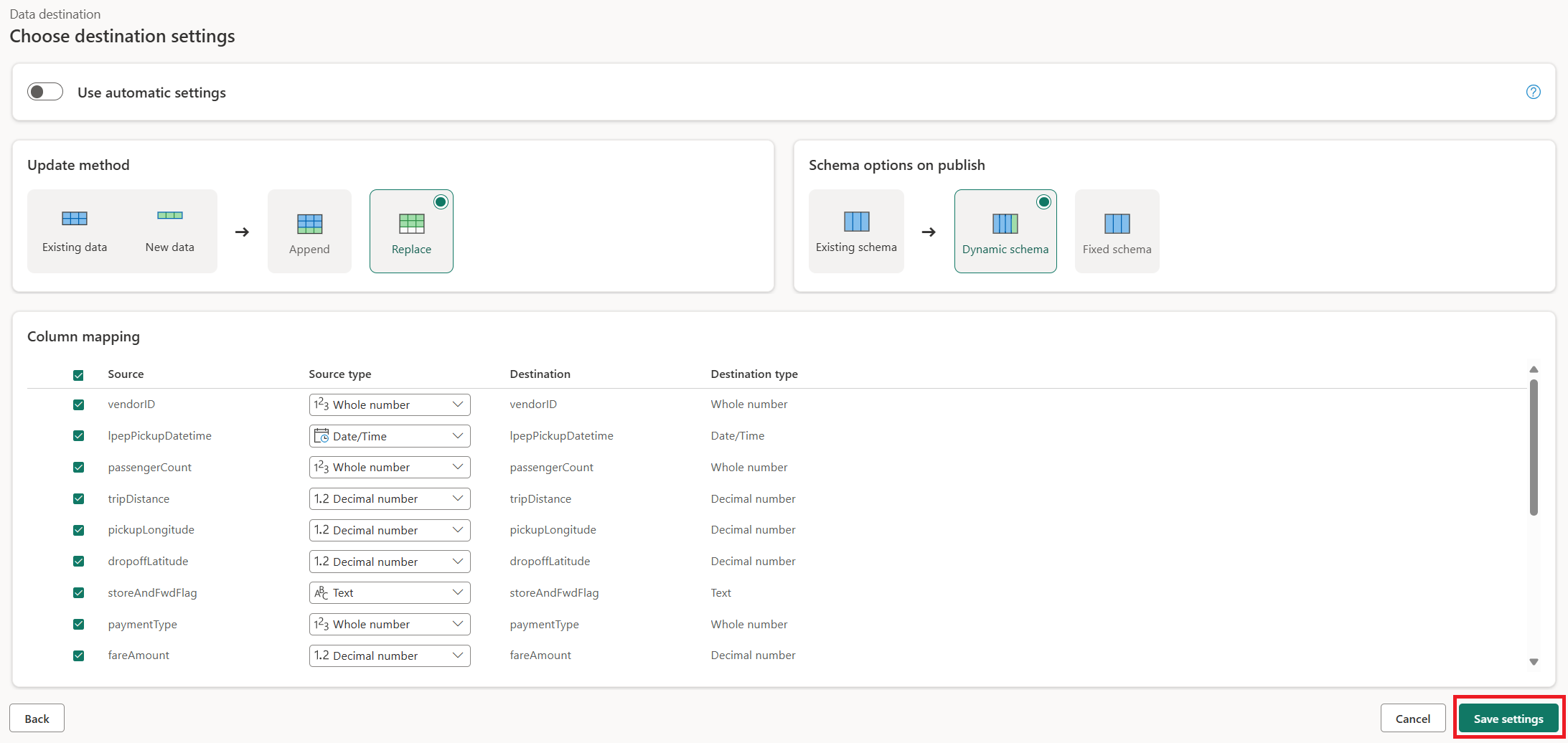
Na janela principal do editor, confirme se você vê o destino de saída no painel de configurações de consulta para a tabela Saída em Destino de dados e, em seguida, selecione Salvar & executar.
Importante
Quando o primeiro Dataflow Gen2 é criado em um espaço de trabalho, os itens de Lakehouse e Warehouse são provisionados junto com o endpoint de análise SQL e modelos semânticos relacionados. Esses itens são compartilhados por todos os fluxos de dados no espaço de trabalho e são necessários para a operação do Fluxo de Dados Gen2, não devem ser excluídos e não devem ser usados diretamente pelos usuários. Os itens são um detalhe de implementação do Fluxo de Dados Gen2. Os itens não são visíveis no espaço de trabalho, mas podem estar acessíveis em outras experiências, como o Notebook, o endpoint SQL, o Lakehouse e o Warehouse. Você pode reconhecer os itens pelo prefixo no nome. O prefixo dos itens é "DataflowsStaging".
(Opcional) Na página da área de trabalho, você pode renomear seu fluxo de dados clicando nos três pontos ao lado do nome do fluxo de dados que aparece após selecionar a linha e escolhendo Configurações. Neste exemplo, renomeamos-o para nyc_taxi_with_discounts.
Selecione o ícone de atualização para o fluxo de dados sob as reticências Mais opções e, quando concluído, você deverá ver sua nova tabela Lakehouse criada conforme configurada nas configurações de Destino de Dados.
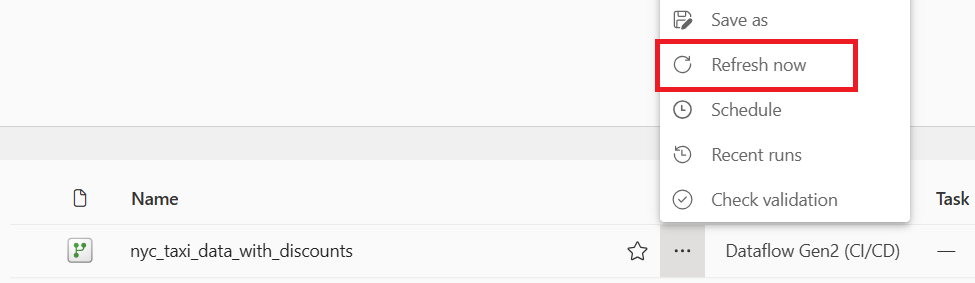
Verifique seu Lakehouse e veja a nova tabela carregada lá.
