Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este tutorial apresenta um exemplo de ponta a ponta de um fluxo de trabalho de Ciência de Dados do Synapse no Microsoft Fabric. Nesse cenário, criamos um modelo de detecção de fraude, em R, com algoritmos de machine learning treinados em dados históricos. Em seguida, usamos o modelo para detectar futuras transações fraudulentas.
Este tutorial aborda estas etapas:
- Instalar bibliotecas personalizadas
- Carregar os dados
- Entenda e processe os dados com a análise de dados exploratória e mostre o uso do recurso Fabric Data Wrangler
- Treinar modelos de machine learning com LightGBM
- Usar os modelos de machine learning para pontuação e previsões
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou cadastre-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o botão de alternância de experiência no canto inferior esquerdo da página inicial para mudar para o Fabric.
- Se necessário, crie um lakehouse do Microsoft Fabric, conforme descrito em Criar um lakehouse no Microsoft Fabric.
Acompanhar em um notebook
Você pode escolher uma destas opções para acompanhar em um notebook:
- Abrir e executar o notebook interno na experiência de Ciência de Dados do Synapse
- Carregar seu notebook do GitHub para a experiência de Ciência de Dados do Synapse
Abrir o bloco de anotações interno
O notebook de exemplo Detecção de fraudes acompanha este tutorial.
Para abrir o bloco de anotações de exemplo para este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Importar o notebook do GitHub
O notebook AIsample - R Fraud Detection.ipynb acompanha este tutorial.
Para abrir o bloco de anotações que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados para importar o bloco de anotações para o seu espaço de trabalho.
Se você prefere copiar e colar o código desta página, pode criar um notebook.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Etapa 1: Instalar bibliotecas personalizadas
Para desenvolvimento de modelo de machine learning ou análise de dados ad hoc, talvez seja necessário instalar rapidamente uma biblioteca personalizada para sua sessão do Apache Spark. Você tem duas opções para instalar bibliotecas.
- Use recursos de instalação embutidos, por exemplo,
install.packagesedevtools::install_version, para instalar somente no notebook atual. - Como alternativa, você pode criar um ambiente do Fabric, instalar bibliotecas de fontes públicas ou carregar bibliotecas personalizadas nele e, em seguida, o administrador do workspace pode anexar o ambiente como o padrão para o workspace. Todas as bibliotecas no ambiente ficarão disponíveis para uso em quaisquer notebooks e definições de trabalho do Spark no workspace. Para obter mais informações sobre ambientes, consulte criar, configurar e usar um ambiente no Microsoft Fabric.
Neste tutorial, use install.version() para instalar a biblioteca de aprendizado desequilibrado:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
Etapa 2: Carregar os dados
O conjunto de dados de detecção de fraude contém transações de cartão de crédito de setembro de 2013, que os titulares de cartão europeus fizeram ao longo de dois dias. O conjunto de dados contém apenas recursos numéricos devido a uma transformação PCA (Análise de Componente Principal) aplicada aos recursos originais. O PCA transformou todas as características, exceto Time e Amount. Para proteger a confidencialidade, não podemos fornecer os recursos originais ou mais informações em segundo plano sobre o conjunto de dados.
Estes detalhes descrevem o conjunto de dados:
- As características
V1,V2,V3, ...,V28são os principais componentes obtidos com o PCA. - O recurso
Timecontém os segundos decorridos entre uma transação e a primeira transação no conjunto de dados - O recurso
Amounté o valor da transação. Você pode usar esse recurso para um aprendizado dependente de exemplo e sensível ao custo - A coluna
Classé a variável de resposta (destino). Ele tem o valor1para fraude e0caso contrário
Apenas 492 transações, do total de 284.807 transações, são fraudulentas. O conjunto de dados está altamente desequilibrado, pois a classe minoritária (fraudulenta) representa apenas cerca de 0,172% dos dados.
Esta tabela mostra uma visualização dos dados de creditcard.csv:
| Hora | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Quantidade | Classe |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.3598071336738 | -0.0727811733098497 | 2.53634673796914 | 1.37815522427443 | -0.338320769942518 | 0.462387777762292 | 0.239598554061257 | 0.0986979012610507 | 0.363786969611213 | 0.0907941719789316 | -0.551599533260813 | -0.617800855762348 | -0.991389847235408 | -0.311169353699879 | 1.46817697209427 | -0.470400525259478 | 0.207971241929242 | 0.0257905801985591 | 0.403992960255733 | 0.251412098239705 | -0.018306777944153 | 0.277837575558899 | -0.110473910188767 | 0.0669280749146731 | 0.128539358273528 | -0.189114843888824 | 0.133558376740387 | -0.0210530534538215 | 149.62 | "0" |
| 0 | 1.19185711131486 | 0.26615071205963 | 0.16648011335321 | 0.448154078460911 | 0.0600176492822243 | -0.0823608088155687 | -0.0788029833323113 | 0.0851016549148104 | -0.255425128109186 | -0.166974414004614 | 1,61272666105479 | 1.06523531137287 | 0.48909501589608 | -0.143772296441519 | 0.635558093258208 | 0.463917041022171 | -0.114804663102346 | -0.183361270123994 | -0.145783041325259 | -0.0690831352230203 | -0.225775248033138 | -0.638671952771851 | 0.101288021253234 | -0.339846475529127 | 0.167170404418143 | 0.125894532368176 | -0.00898309914322813 | 0.0147241691924927 | 2.69 | "0" |
Baixar o conjunto de dados e carregar no lakehouse
Defina esses parâmetros para que você possa usar este notebook com conjuntos de dados diferentes:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
Esse código baixa uma versão disponível publicamente do conjunto de dados e, em seguida, armazena-a em um lakehouse do Fabric.
Importante
Certifique-se de adicionar um lakehouse ao notebook antes de executá-lo. Caso contrário, você receberá um erro.
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
Ler dados de data brutos do lakehouse
Esse código lê dados brutos da seção Arquivos do lakehouse:
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
Etapa 3: executar análise de dados exploratória
Use o comando display para exibir as estatísticas de alto nível do conjunto de dados:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
Imprima a distribuição de classes no conjunto de dados:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
Essa distribuição de classe mostra que a maioria das transações não são fraudulentas. Portanto, o pré-processamento de dados é necessário antes do treinamento do modelo para evitar o sobreajuste.
Exibir a distribuição de transações fraudulentas versus não fraudulentas
Exiba a distribuição de transações fraudulentas versus não fraudulentas com um gráfico, para mostrar o desequilíbrio de classe no conjunto de dados:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
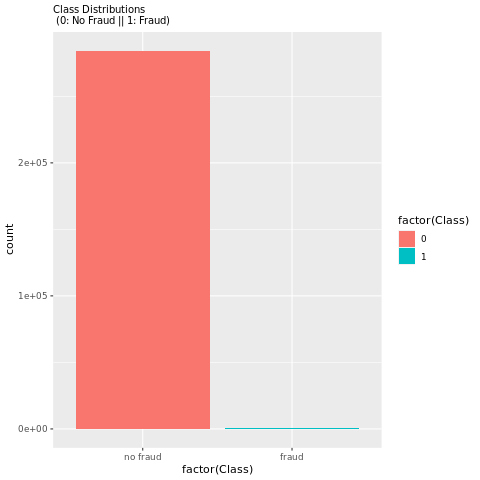
O gráfico mostra claramente o desequilíbrio do conjunto de dados:
Mostrar o resumo de cinco números
Mostre o resumo de cinco números (a pontuação mínima, o primeiro quartil, a mediana, o terceiro quartil e a pontuação máxima) para o valor da transação com gráficos de caixa:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
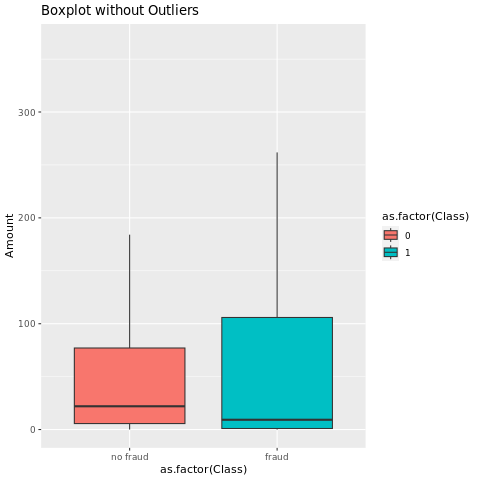
Para dados altamente desequilibrados, os gráficos de caixa podem não mostrar percepções precisas. No entanto, você pode resolver o problema de desequilíbrio Class primeiro e, em seguida, criar os mesmos gráficos para insights mais precisos.
Etapa 4: Treinar e avaliar os modelos
Aqui, você treina um modelo LightGBM para classificar as transações de fraude. Você treina um modelo LightGBM no conjunto de dados desequilibrado e no conjunto de dados equilibrado. Em seguida, você compara o desempenho de ambos os modelos.
Preparar conjuntos de dados de treinamento e teste
Antes do treinamento, divida os dados para os conjuntos de dados de treinamento e teste:
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
Aplicar SMOTE ao conjunto de dados de treinamento
A classificação desequilibrada tem um problema. Tem poucos exemplos de classe minoritária para um modelo aprender efetivamente o limite de decisão. O SMOTE (Técnica de Superamostragem de Minorias Sintéticas) pode resolver esse problema. SMOTE é a abordagem mais usada para sintetizar novos exemplos para a classe minoritária. Você pode acessar o SMOTE usando a biblioteca de imbalance instalada na Etapa 1.
Aplique SMOTE somente ao conjunto de dados de treinamento, em vez do conjunto de dados de teste. Ao pontuar o modelo com os dados de teste, você precisará de uma aproximação do desempenho do modelo em dados não vistos na produção. Para uma aproximação válida, seus dados de teste dependem da distribuição desequilibrada original para representar os dados de produção o mais próximo possível.
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
Para obter mais informações sobre o SMOTE, consulte os recursos "Desbalanceamento" do pacote e Trabalhando com conjuntos de dados desbalanceados no site do CRAN.
Treinar o modelo com LightGBM
Treine o modelo LightGBM com o conjunto de dados desequilibrado e o conjunto de dados balanceado (via SMOTE). Em seguida, compare o desempenho:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
Determinar a importância da característica
Determine a importância da característica para o modelo treinado no conjunto de dados desequilibrado.
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
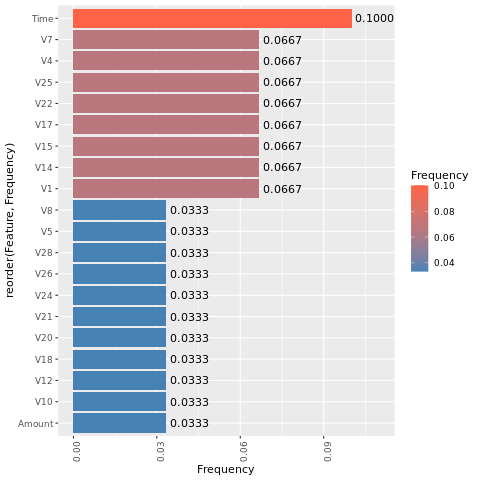
Para o modelo treinado no conjunto de dados balanceado (via SMOTE), calcule a importância do recurso:
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
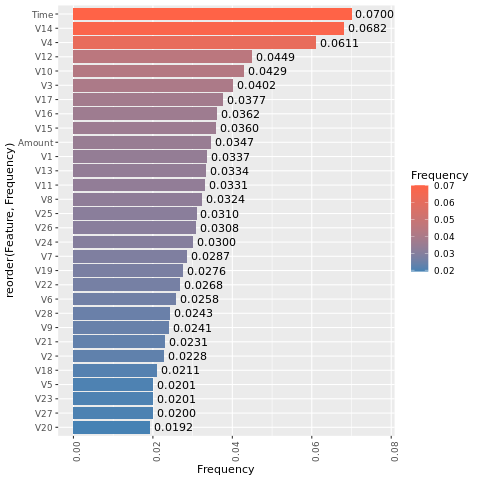
Uma comparação desses gráficos mostra claramente que conjuntos de dados de treinamento equilibrados e desequilibrados têm grandes diferenças de importância das características.
Avaliar os modelos
Aqui, você avalia os dois modelos treinados:
modeltreinado em dados brutos e desbalanceadossmote_modeltreinado em dados balanceados
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
Avaliar o desempenho do modelo com uma matriz de confusão
Uma matriz de confusão exibe o número de
- TP (verdadeiros positivos)
- TN (verdadeiros negativos)
- FP (falsos positivos)
- FN (falsos negativos)
que um modelo produz quando avaliado com os dados de teste. Para classificação binária, o modelo retorna uma matriz de confusão 2x2. Para classificação multiclasse, o modelo retorna uma matriz de confusão nxn, em que n é o número de classes.
Use uma matriz de confusão para resumir o desempenho dos modelos de machine learning treinados nos dados de teste:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }Plote a matriz de confusão para o modelo treinado no conjunto de dados desequilibrado:
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")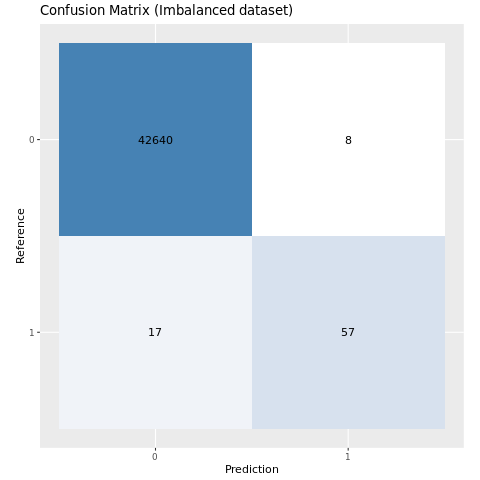
Plote a matriz de confusão para o modelo treinado no conjunto de dados equilibrado:
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")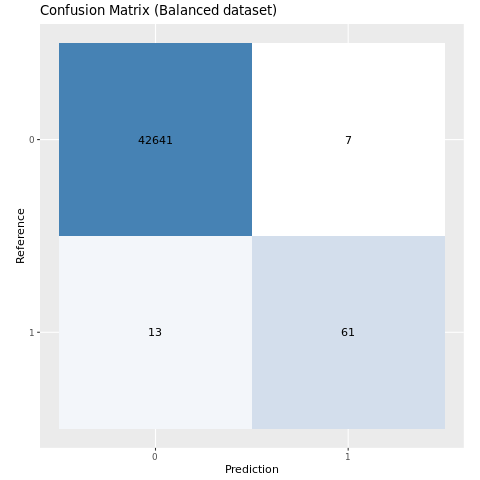
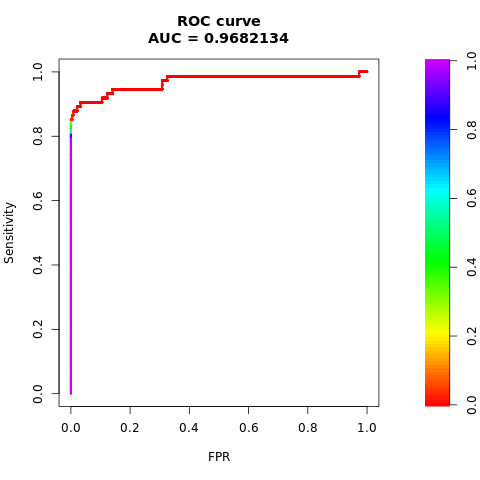
Avalie o desempenho do modelo com as medidas AUC-ROC e AUPRC
A medida AUC-ROC (Área sob a Curva da Característica de Operação do Receptor) avalia o desempenho dos classificadores binários. O gráfico AUC-ROC visualiza a compensação entre a taxa verdadeira positiva (TPR) e a taxa de falso positivo (FPR).
Em alguns casos, é mais apropriado avaliar o classificador com base na medida AUPRC (Área Sob a Curva Precision-Recall). A curva AUPRC combina estas taxas:
- A precisão ou o valor preditivo positivo (PPV)
- O recall, ou TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
Calcular as métricas AUC-ROC e AUPRC
Calcule e plote as métricas AUC-ROC e AUPRC para os dois modelos.
Conjunto de dados desequilibrado
Calcule as previsões:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
Imprima a área sob a curva AUC-ROC:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
Plote a curva de AUC-ROC:
# Plot AUC-ROC
plot(roc)
Imprima a curva AUPRC:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
Plote a curva AUPRC:
# Plot AUPRC
plot(pr)
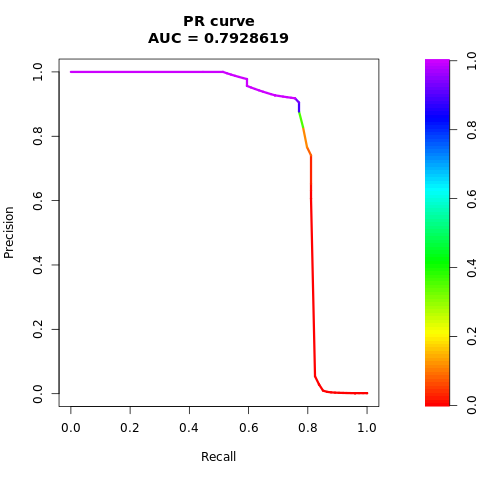
Conjunto de dados balanceado (via SMOTE)
Calcule as previsões:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
Imprima a curva de AUC-ROC:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
Plote a curva de AUC-ROC:
# Plot AUC-ROC
plot(smote_roc)
Imprima a curva AUPRC:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
Plote a curva AUPRC:
# Plot AUPRC
plot(smote_pr)
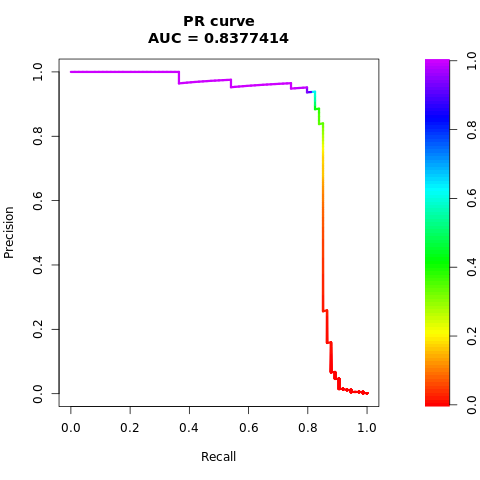
Os números anteriores mostram claramente que o modelo treinado no conjunto de dados equilibrado supera o modelo treinado no conjunto de dados desequilibrado, tanto para pontuações de AUC-ROC quanto de AUPRC. Esse resultado sugere que o SMOTE melhora efetivamente o desempenho do modelo ao trabalhar com dados altamente desequilibrado.