Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:✅Armazém de dados no Microsoft Fabric
Este artigo destaca os recursos e inovações na arquitetura do Fabric Data Warehouse que alimentam seu desempenho, escalabilidade e eficiência de custo.
O Fabric Data Warehouse é executado em uma arquitetura pronta para o futuro em uma plataforma de dados convergida. Com um formato de armazenamento Delta aberto e uma integração do OneLake, seus dados no Fabric Data Warehouse estão prontos para análise.
Arquitetura de alto nível

O Fabric Data Warehouse é criado para análise em escala com os seguintes blocos de construção:
| Bloco de construção | Descrição |
|---|---|
| Otimizador de consulta unificado | Gera um plano de execução ideal para ambientes de nuvem distribuída, independentemente da qualidade das consultas SQL criadas pelo usuário. |
| Processamento de consulta distribuída | Dá suporte à execução de consulta paralela maciça com infraestrutura de nuvem de dimensionamento automático rápido, fornecendo instantaneamente os recursos de computação necessários para consultas. Cargas de trabalho SELECT e DML separadas usam pools distintos para execução eficiente e isolada. |
| Mecanismo de execução de consulta | Um mecanismo baseado em SQL para executar consultas de análise em grande quantidade de dados com desempenho rápido e alta simultaneidade. |
| Gerenciamento de metadados e transações | Os metadados residem no front-end, no back-end e no cache SSD local e no armazenamento remoto do OneLake. Dá suporte a transações simultâneas e garante a conformidade com ACID. |
| Armazenamento no OneLake | Tabelas estruturadas de log implementadas usando o formato de tabela Delta aberto, um modelo lakehouse no qual o armazenamento seguro é aberto. |
| Plataforma Fabric | A Plataforma Fabric fornece um modelo unificado de autenticação e segurança, monitoramento e auditoria. O Fabric Data Warehouse está disponível automaticamente para outros serviços da plataforma Fabric para atender às necessidades de negócios, incluindo o Power BI, pipelines de dados no Data Factory, Real-Time Intelligence e muito mais. |
Mecanismo de otimizador de consulta unificado
O otimizador de consulta unificado no Fabric Data Warehouse é o mecanismo que decide a maneira mais inteligente de executar suas consultas SQL.
Quando você envia uma consulta, o otimizador de consulta unificada analisa as possíveis maneiras de executá-la: como unir tabelas, onde mover dados e como usar recursos como CPU, memória e rede. O otimizador de consulta unificado não escolhe apenas a primeira opção, ele escolhe o plano mais ideal dentro do tempo permitido, avaliando o custo entre esses fatores e metadados e estatísticas disponíveis.
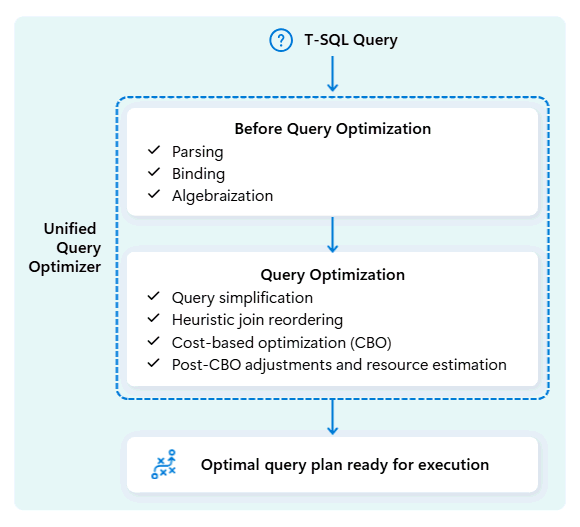
Ao otimizar o plano de execução de uma consulta, o otimizador de consulta unificado considera tudo de uma só vez: a forma da consulta, a distribuição de dados de suas tabelas e o custo de movimentação de dados versus o processamento localmente. O otimizador de consulta unificado pode fazer escolhas inteligentes, como optar por transmitir uma tabela pequena em vez de realocar uma grande, caso isso seja mais econômico. Isso significa menos embaralhamentos de dados desnecessários, melhor uso da computação e desempenho mais rápido, mesmo para consultas T-SQL complexas ou mal gravadas.
O desempenho consistente não exige que os desenvolvedores gastem tempo no ajuste manual de consulta T-SQL. Por exemplo, você não precisa determinar manualmente a melhor JOIN ordem em consultas. Se o SQL listar a tabela grande primeiro e uma tabela de dados menor e altamente seletiva segundo, o otimizador poderá alternar automaticamente suas posições para melhor desempenho. Ele usará a tabela menor como ponto de partida para a correspondência de linhas (o lado de construção) e a tabela maior como a que deve ser pesquisada (o lado de sondagem, verificado para correspondências). Essa abordagem minimiza o uso de memória, reduz a movimentação de dados e melhora o paralelismo, ao mesmo tempo em que fornece resultados precisos.
O otimizador de consulta unificado aprende continuamente com execuções de consulta passadas à medida que as cargas de trabalho evoluem, refinando seu algoritmo de otimização para fornecer o melhor desempenho possível. Os usuários se beneficiam da execução rápida da consulta automaticamente, independentemente da complexidade e sem a necessidade de intervir.
Mecanismo de processamento de consulta distribuída
No Fabric Data Warehouse, o mecanismo de processamento de consulta distribuída aloca recursos de computação para tarefas em planos de consulta. O mecanismo de processamento de consulta distribuída pode agendar tarefas entre nós de computação para que cada nó execute parte de um plano de consulta, permitindo a execução paralela para um desempenho mais rápido. Relatórios complexos em grandes conjuntos de dados podem se beneficiar do processamento de consulta distribuída.
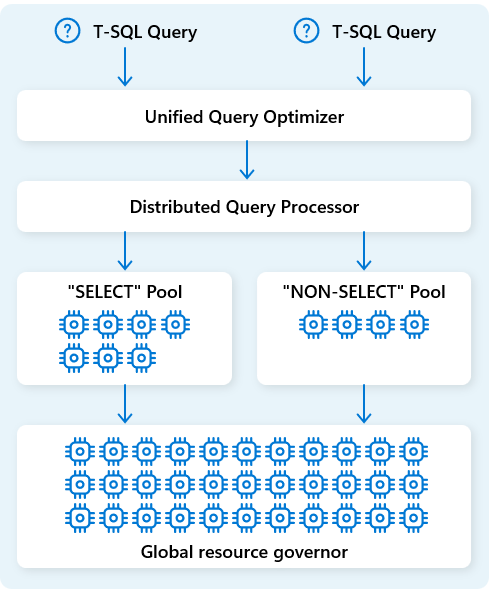
Para otimizar ainda mais os recursos, o mecanismo de processamento de consulta distribuída separa os recursos de computação em dois pools: para SELECT consultas e para tarefas de ingestão de dados (NON-SELECT consultas). Cada carga de trabalho recebe recursos dedicados conforme necessário. Isso significa, por exemplo, que seus processos de ETL executados à noite não atrasarão os painéis da manhã.
Com o provisionamento rápido de nós na nuvem, o mecanismo de processamento de consulta distribuída dimensiona automaticamente os recursos de computação para cima ou para baixo em resposta a alterações no volume de consulta, no tamanho dos dados e na complexidade da consulta. O Fabric Data Warehouse tem recursos de processamento paralelos para pequenos conjuntos de dados ou dados na escala de vários petabytes.
Mecanismo de execução de consulta
O mecanismo de execução de consulta é um processo que executa partes do plano de execução distribuída atribuídas aos nós de computação individuais. O mecanismo de execução de consulta baseia-se no mesmo mecanismo usado pelo SQL Server e pelo Banco de Dados SQL do Azure para usar a execução em modo de lote e formatos de dados columnar para análise eficiente em Big Data a um custo ideal.
O mecanismo de execução de consulta lê dados diretamente de arquivos Delta Parquet armazenados no Fabric OneLake e aproveita várias camadas de cache (memória e SSD) para acelerar o desempenho da consulta e garantir que as consultas sejam executadas em uma velocidade ideal. O mecanismo de execução de consulta processa dados na memória e, quando necessário, recupera dados adicionais do cache SSD ou do armazenamento OneLake.
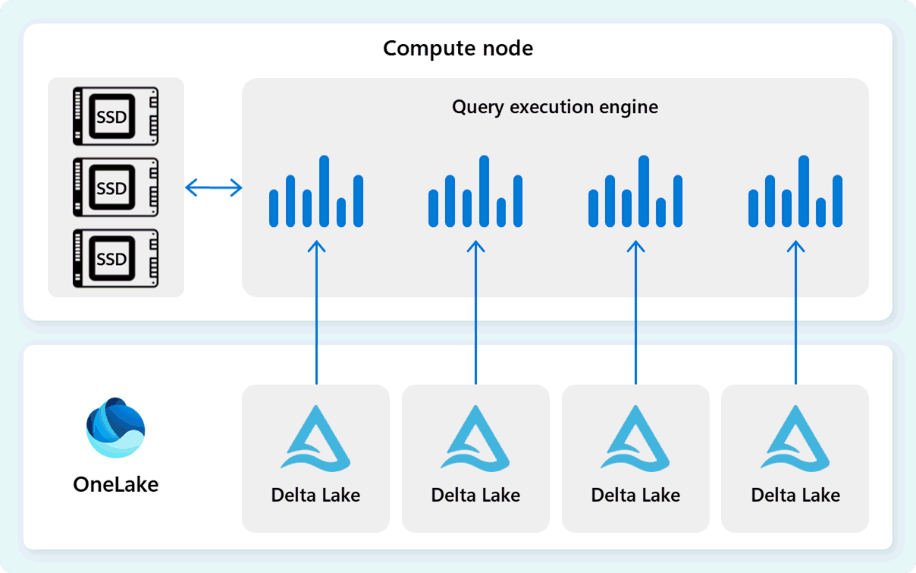
À medida que processa dados, o mecanismo de execução de consulta executa a eliminação de grupo de colunas e linhas para ignorar segmentos que não são relevantes para a consulta. Essa otimização reduz a quantidade de dados verificados dos arquivos e do cache de memória, ajudando a minimizar o uso de recursos e melhorar o tempo de execução geral.
O mecanismo de execução de consulta se destaca em filtrar e agregar bilhões de linhas, dando suporte aos padrões genéricos de análise de dados usados em soluções modernas de data warehouse. A execução do modo de lote aproveita a capacidade moderna da CPU de processar várias linhas em paralelo, reduzindo drasticamente a sobrecarga e fazendo com que as consultas sejam executadas até centenas de vezes mais rapidamente em comparação com a execução linha por linha tradicional.
Gerenciamento de metadados e transações
O mecanismo de warehouse usa metadados para descrever esquema de tabela, organização de arquivos, histórico de versão e estados transacionais. Esses metadados permitem que o mecanismo de warehouse gerencie e consulte dados com eficiência. O Fabric Data Warehouse oferece uma arquitetura robusta e abrangente de gerenciamento de transações e metadados, estendendo um gerenciador de transações OLTP para orquestrar operações de metadados altamente simultâneas e garantir a conformidade com ACID.
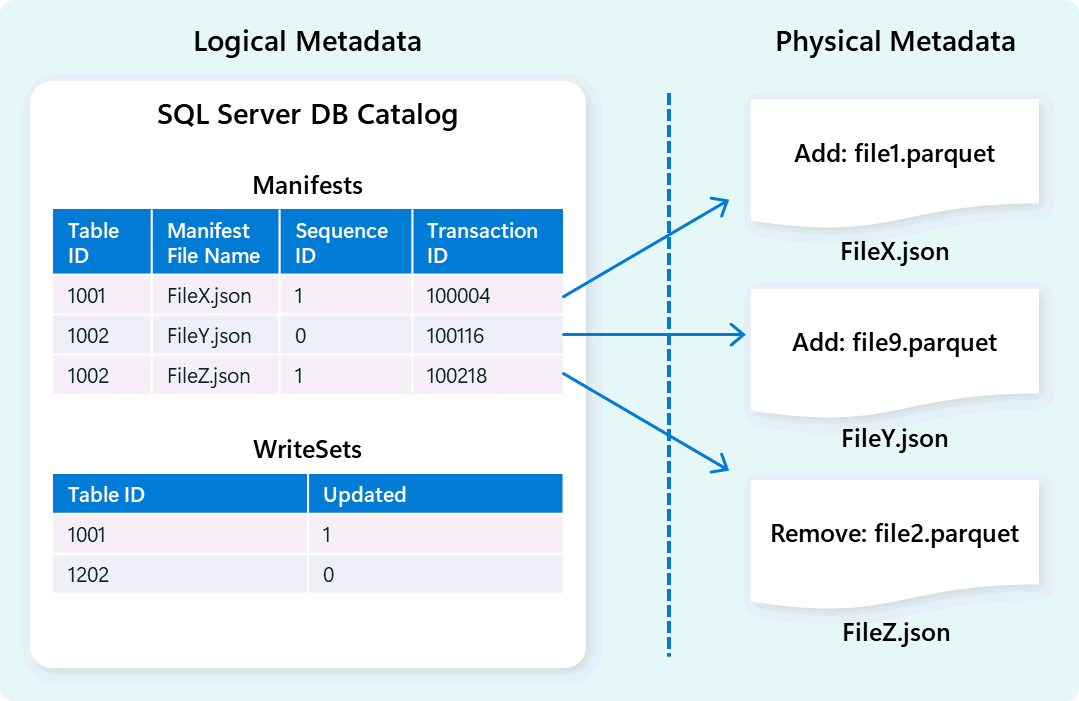
Esse design permite uma navegação rápida e confiável de estados transacionais, dando suporte a cargas de trabalho com alta simultaneidade, garantindo a consistência.
Armazenamento e ingestão de dados
O Fabric Data Warehouse usa uma arquitetura lakehouse com o formato Delta de software livre para armazenamento escalonável, seguro e de alto desempenho. O formato de tabela Delta dá suporte ao controle de versão de dados, permitindo o acesso instantâneo a instantâneos históricos por meio de funcionalidades como viagens no tempo e clonagem sem cópia para operações seguras de teste e reversão. Os dados do usuário são armazenados no OneLake, permitindo que todos os mecanismos do Fabric acessem dados compartilhados com eficiência sem redundância.
Com base nessa base, o Fabric Data Warehouse foi projetado para oferecer um desempenho ideal de ingestão de dados com foco na simplicidade e flexibilidade. O mecanismo gerencia com eficiência o armazenamento de dados de tabela por meio da compactação automática de dados, que consolida arquivos fragmentados em segundo plano para reduzir a verificação de dados desnecessária. Seu método de distribuição de dados inteligente divide e organiza dados em células micropartidas para aumentar o processamento paralelo e aprimorar os resultados da consulta. Esses recursos funcionam de forma autônoma, sem a necessidade de ajustes manuais.