Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: ✅ endpoint de análise SQL e Warehouse do Microsoft Fabric
Os pools de SQL personalizados dão aos administradores mais controle de como os recursos são alocados para lidar com solicitações. Neste início rápido, você configurará pools de SQL personalizados e observará os valores do classificador usando a API REST do Fabric.
Os administradores do workspace podem usar o nome do aplicativo (ou o nome do programa) da cadeia de conexão para rotear solicitações para pools de computação diferentes. Os administradores do workspace também podem controlar a porcentagem de recursos que cada pool de computação SQL pode acessar, com base no limite de escala elástica da capacidade do workspace.
A API REST do Fabric define um ponto de extremidade unificado para operações.
Pré-requisitos
- Acesso a um item do Warehouse em um workspace. Você deve ser um membro da função Administrador.
Obter a configuração de IP atual
Use a API a seguir para obter a configuração atual.
Exemplo do Bloco de Anotações do Fabric
Você pode executar o seguinte exemplo de código Python em um bloco de anotações do Fabric Spark.
- O código envia uma
GETsolicitação para a API de configuração do pool de SQL personalizado e retorna a configuração personalizada do pool de SQL para o workspace. - O
workspace_idcampo usa omssparkutils.runtime.contextpara obter o GUID do workspace em que o bloco de anotações é executado. Para configurar um pool SQL personalizado em um workspace diferente, atualize o `workspace_id` para o GUID do workspace onde deseja configurar os pools SQL personalizados.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Configurar pools de SQL personalizados
O exemplo do Python a seguir habilita e configura pools de SQL personalizados. Você pode executar esse código Python em um bloco de anotações do Fabric Spark.
- A configuração de pools de SQL personalizados só está ativa quando
customSQLPoolsEnabledo atributo é definido como true. Você pode especificar um payload na definição do objetocustomSQLPools, mas se você não configurar customSQLPoolsEnabled como verdadeiro, o payload será ignorado e o gerenciamento autônomo de carga de trabalho será usado. - O código configura dois pools de SQL personalizados
ContosoSQLPooleAdhocPool.- O
ContosoSQLPoolestá definido para receber 70% dos recursos disponíveis. O classificador nome do aplicativo tem o valor deMyContosoApp. - Todas as consultas SQL provenientes de uma cadeia de conexão que especifica o nome do
MyContosoAppaplicativo são classificadas para oContosoSQLPoolpool de SQL personalizado e têm acesso a 70% do total de nós de capacidade intermitível. - Todas as consultas SQL que não contêm
MyContosoAppno nome do aplicativo da cadeia de conexão são enviadas para oAdhocpool SQL personalizado, que é definido como pool padrão. Essas solicitações obtêm acesso a 30% do total de nós de capacidade intermitível.
- O
- Todas as configurações personalizadas do pool de SQL devem ter um Pool de SQL padrão identificado definindo o
isDefaultatributo como true. - A soma de todos os
maxResourcePercentagevalores deve ser menor ou igual a 100%. - O
workspace_idcampo usa omssparkutils.runtime.contextpara obter o GUID do workspace em que o bloco de anotações é executado. Para configurar um pool SQL personalizado em um workspace diferente, atualize o `workspace_id` para o GUID do workspace onde deseja configurar os pools SQL personalizados.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Dica
Use estes valores úteis do classificador de Nome do Aplicativo (regex) para o tráfego do Fabric:
- Para classificar consultas de pipelines do Fabric, use
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - Para classificar consultas do Power BI, use
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - Para classificar consultas do editor de consultas SQL do portal do Fabric, use
DMS_user.
Definir o nome do aplicativo no SSMS (SQL Server Management Studio)
O classificador para pools de SQL personalizados utiliza o nome do aplicativo ou o parâmetro do nome do programa em cadeias de conexão padrão.
No SSMS (SQL Server Management Studio), especifique o nome do servidor para o warehouse e forneça autenticação. O Microsoft Entra MFA é recomendado.
Selecione o botão Avançado .
Na página Propriedades Avançadas , em Contexto, altere o valor do Nome do Aplicativo para
MyContosoApp.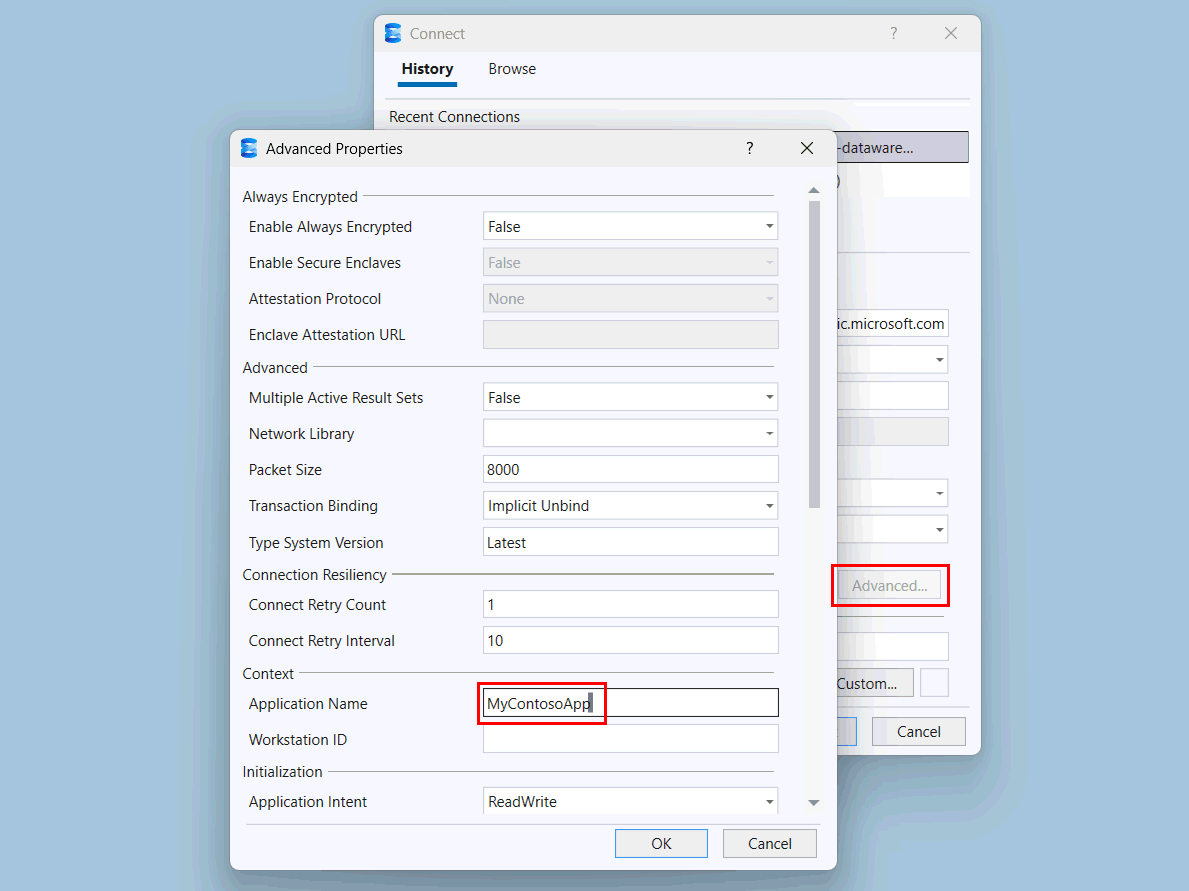
Selecione OK.
Selecione Conectar.
Para gerar alguma atividade de exemplo, use essa conexão no SSMS para executar uma consulta simples em seu warehouse, por exemplo:
SELECT * FROM dbo.DimDate;

Observe os insights de consultas para o pool SQL customizado
Examine a exibição
sys.dm_exec_sessionsde gerenciamento dinâmico para ver queMyContosoAppestá sendo reconhecido como o nome do aplicativo passado do SSMS para o mecanismo SQL.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Por exemplo:
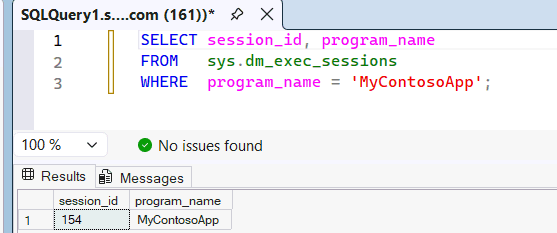
Como o
program_namecorresponde ao nome do aplicativo no pool de SQL personalizadoMyContosoApp, essa consulta utiliza os recursos desse pool. Para provar qual pool de SQL personalizado a consulta usou, você pode consultar a exibição de sistema queryinsights.exec_requests_history. Aguarde de 10 a 15 minutos para que os insights da consulta se preencham, e então execute a consulta a seguir.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';Você também pode identificar o pool de uma consulta por sua ID de Declaração. No editor de consultas SQL do portal do Fabric, execute uma consulta no seu endpoint de warehouse ou de análise SQL.
SELECT * FROM dbo.DimDate;Selecione a guia Mensagens e registre o ID da Declaração para a execução da consulta. No editor de consultas SQL, o
program_nameé oDMS_user, que você configurou para usar o pool de SQL personalizadoMyContosoAppanteriormente.Aguarde de 10 a 15 minutos para que os insights de consulta sejam preenchidos.
Recupere a
sql_pool_namee outras informações para verificar se o pool de SQL personalizado adequado foi usado.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Reverter a configuração dos pools de SQL personalizados
Para retornar o workspace para o estado original, altere a customSQLPoolsEnabled propriedade para False. Se você quiser preservar a configuração de pools de SQL personalizados, precisará passar cada nome de pool na lista customSQLPools.
Este exemplo de código Python desabilita pools de SQL personalizados e retorna para a configuração de gerenciamento autônomo de carga de trabalho de SELECT e não-SELECT pools. Uma PATCH solicitação é chamada com a customSQLPoolsEnabled propriedade definida como False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)