Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:✅Armazém de dados no Microsoft Fabric
Este tutorial explica como usar IDENTITY colunas no Fabric Data Warehouse para criar e gerenciar chaves substitutas com eficiência.
Importante
Esse recurso está na versão prévia.
Pré-requisitos
- Para ter acesso a um item do Warehouse em um workspace, com permissão de Colaborador ou superior.
- Escolha sua ferramenta de consulta. Este tutorial apresenta o editor de consultas SQL no portal do Microsoft Fabric, mas você pode usar qualquer ferramenta de consulta T-SQL.
- Compreensão básica do T-SQL.
O que é uma coluna IDENTITY?
Uma IDENTITY coluna é uma coluna numérica que gera automaticamente valores exclusivos para novas linhas. Isso o torna ideal para implementar chaves substitutas, pois garante que cada linha receba um identificador exclusivo sem entrada manual.
Criar uma coluna IDENTITY
Para definir uma IDENTITY coluna, especifique a palavra-chave IDENTITY na definição de coluna da CREATE TABLE sintaxe T-SQL:
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
[column_name] BIGINT IDENTITY,
[ ,... n ],
-- Other columns here
);
Observação
No Fabric Data Warehouse, o bigint é o único tipo de dados com suporte para IDENTITY colunas. Além disso, não há suporte para as propriedades seed e increment do T-SQL IDENTITY. Para obter mais informações, consulte as colunas IDENTITY e IDENTITY (Transact-SQL). Para obter mais informações sobre como criar tabelas, consulte Criar tabelas no Warehouse no Microsoft Fabric.
Criar uma tabela com uma coluna IDENTITY
Neste tutorial, criaremos uma versão mais simples da tabela a Trip partir do conjunto de dados aberto do NY Taxi e adicionaremos uma nova TripIDIDENTITY coluna a ela. Cada vez que uma nova linha é inserida, TripID é atribuída com um novo valor exclusivo na tabela.
Definir uma tabela com uma
IDENTITYcoluna:CREATE TABLE dbo.Trip ( TripID BIGINT IDENTITY, DateID int, MedallionID int, HackneyLicenseID int, PickupTimeID int, DropoffTimeID int );Em seguida, usamos
COPY INTOpara ingerir alguns dados nesta tabela. Ao usarCOPY INTOcom umaIDENTITYcoluna, você deve fornecer a lista de colunas, mapeando para colunas nos dados de origem.COPY INTO Trip (DateID 1, MedallionID 2, HackneyLicenseID 3, PickupTimeID 4, DropoffTimeID 5) FROM 'https://nytaxiblob.blob.core.windows.net/2013/Trip2013' WITH ( FILE_TYPE = 'CSV', FIELDTERMINATOR = '|', COMPRESSION = 'GZIP' );Podemos visualizar os dados e os valores atribuídos à
IDENTITYcoluna com uma consulta simples:SELECT TOP 10 * FROM Trip;A saída inclui o valor gerado automaticamente para a
TripIDcoluna para cada linha.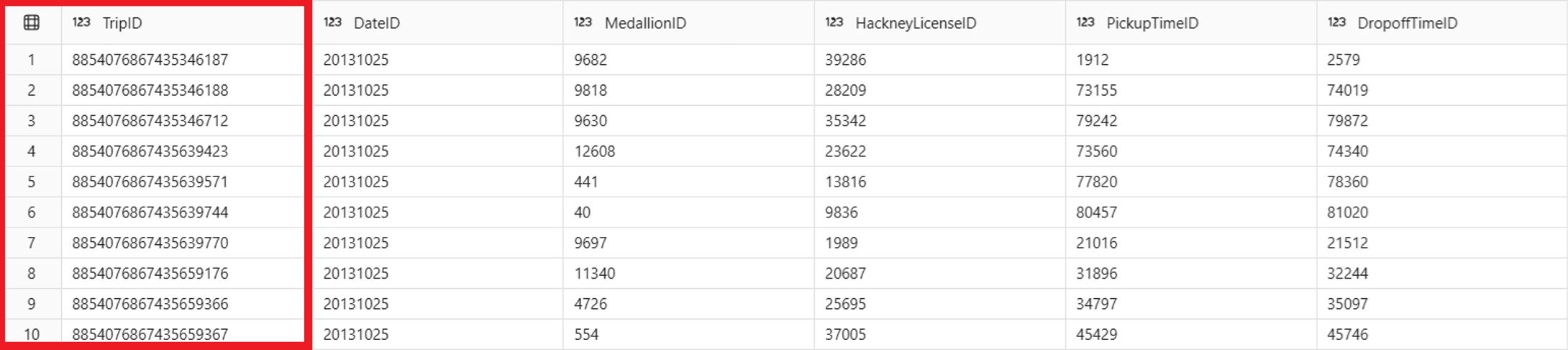
Importante
Seus valores podem ser diferentes dos observados neste artigo.
IDENTITYas colunas produzem valores aleatórios que têm a garantia de serem exclusivos, mas podem haver lacunas nas sequências e os valores podem não estar em ordem.Você também pode usar
INSERT INTOpara ingerir novas linhas em sua tabela.INSERT INTO dbo.Trip VALUES (20251104, 3524, 28804, 51931, 52252);A lista de colunas pode ser fornecida com
INSERT INTO, mas não é obrigatória. Ao fornecer uma lista de colunas, especifique o nome de todas as colunas para as quais você está fornecendo dados de entrada, exceto para aIDENTITYcoluna:INSERT INTO dbo.Trip (DateID, MedallionID, HackneyLicenseID, PickupTimeID, DropoffTimeID) VALUES (20251104, 8410, 24939, 74609, 49583);Podemos examinar as linhas inseridas com uma consulta simples:
SELECT * FROM dbo.Trip WHERE DateID = 20251104;

Observe os valores atribuídos às novas linhas:
