Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Data Connect do Microsoft Graph permite que os desenvolvedores criem aplicativos que os clientes podem fornecer acesso gerenciado a seus conjuntos de dados em escala do Microsoft Graph. Este artigo fornece sugestões que o ajudam a tirar partido da funcionalidade Ligação de Dados do Microsoft Graph. Para obter uma introdução ao Data Connect do Microsoft Graph, consulte a visão geral.
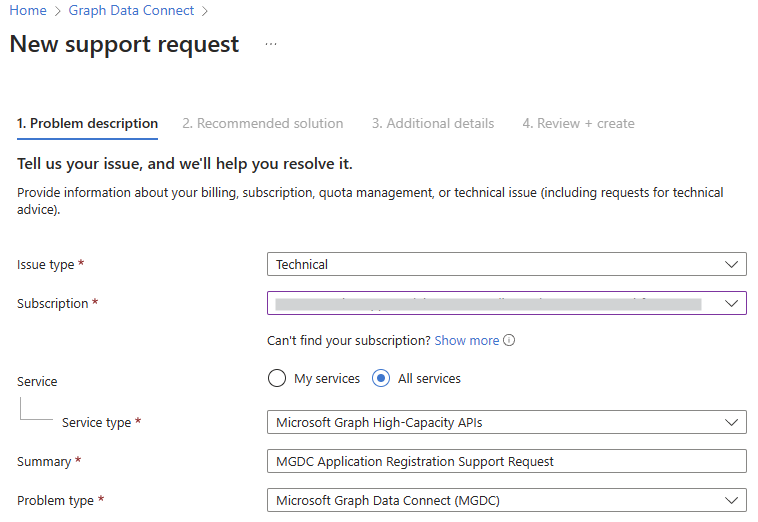
Para obter mais perguntas, veja Resolução de problemas ou criar um novo pedido de Suporte do Azure com as seguintes seleções:
- Tipo de serviço: selecione Microsoft Graph High-Capacity APIs
- Tipo de problema: escolha Microsoft Graph Data Connect (MGDC)
A Conexão de Dados do Microsoft Graph é adequada para mim?
As APIs do Microsoft Graph Data Connect e do Microsoft Graph fornecem acesso aos mesmos dados subjacentes, mas de formas muito diferentes. O Microsoft Graph Data Connect foi concebido para extrair grandes quantidades de conjuntos de dados em massa, dimensionáveis para toda a organização; enquanto as APIs do Microsoft Graph são adequadas para aceder a uma pequena quantidade de dados de utilizadores e grupos selecionados na sua organização.
Por exemplo, poderá querer utilizar o Microsoft Graph Data Connect para efetuar uma extração inicial do último ano de dados de e-mail e, em seguida, utilizar as APIs do Microsoft Graph para analisar e-mails em tempo real. As APIs do Microsoft Graph Data Connect e do Microsoft Graph são ferramentas diferentes para diferentes tarefas. É importante pensar sobre o qual método de acesso melhor se encaixa em seu cenário. Para obter mais informações, consulte Quando devo utilizar o Microsoft API do Graph ou o Microsoft Graph Data Connect.
Para que cenários as empresas utilizam dados do Microsoft 365?
Existem vários casos de utilização que podem ser alimentados por dados do Microsoft 365. Seguem-se alguns dos principais cenários em que os clientes estão interessados:
Análise de Relações com o Cliente: para líderes empresariais comerciais, vá além das informações tradicionais do CRM e compreenda as interações e relações dos clientes com base nos padrões de comunicação e colaboração.
Business Process Analytics: para melhores operações, veja como o trabalho realmente flui através da organização no dia-a-dia. Identifique os processos manuais e os estrangulamentos do fluxo de trabalho que devem ser automatizados ou otimizados.
Análise de Segurança e Conformidade: para proteger dados confidenciais, saiba como os funcionários estão a utilizar e a partilhar informações confidenciais. Implemente deteção de anomalias, informações sobre ameaças, análise de registos de auditoria, gestão de riscos e forenses legais.
Pessoas Productivity Analytics: para impulsionar a transformação, exporte as suas métricas de produtividade Viva, para que possa converter informações em soluções com adoção digital, reuniões inteligentes e conteúdos, locais de trabalho híbridos e alterações culturais.
Como diferem Viva Insights e o Microsoft Graph Data Connect?
Viva Insights e o Microsoft Graph Data Connect são complementares. Embora ambos dependam do Microsoft 365, o Viva Insights e o Data Connect servem diferentes audiências e necessidades.
Quando os clientes procuram informações e análises para além Viva Insights, o Data Connect fornece a extensibilidade para fornecer requisitos personalizados. Por exemplo, oferece registos de chamadas e transcrições do Teams, bem como conjuntos de dados do SharePoint Online, que não estão atualmente no âmbito de Viva Insights. Além disso, os dados não processados do Data Connect fornecem detalhes granulares que, de outra forma, não estão disponíveis a partir de Viva Insights.
Existe algum overhead inicial com o Microsoft Graph Data Connect?
Como o Data Connect foi projetado para extrair grandes quantidades de dados em massa, ocorre alguma sobrecarga antes que os dados possam ser extraídos. Essa sobrecarga é de aproximadamente 45 minutos, ou seja, todos os pipelines levarão no mínimo esse tempo, independentemente do tamanho dos dados. Se a sobrecarga inicial for demasiado longa para o seu caso de utilização, crie um novo pedido de Suporte do Azure, incluindo os detalhes mencionados na secção anterior.
Em que regiões está disponível o Microsoft Graph Data Connect?
O Microsoft Graph Data Connect está atualmente disponível em várias regiões nas seguintes geografias: América do Norte, Europa, Ásia-Pacífico, Reino Unido e Austrália. Outras regiões estarão disponíveis no futuro.
Para obter uma lista de regiões e mapeamentos do Office para o Azure, veja Conjunto de dados, regiões e sinks.
Que conjuntos de dados estão disponíveis através do Microsoft Graph Data Connect?
Estão disponíveis os seguintes tipos de conjuntos de dados:
Básico: conjuntos de dados gerados a partir de conteúdos e entradas criados por clientes não processados a partir de aplicações e serviços do Microsoft 365 (por exemplo, Microsoft Entra ID, Outlook ou conjuntos de dados do Teams).
Limpo: conjuntos de dados gerados pela normalização e eliminação de duplicados a partir de conjuntos de dados básicos ou conjuntos de dados criados a partir de sinais de comportamento ou atividade do utilizador no Microsoft 365 (por exemplo, SharePoint, Office 365 conjuntos de dados).
Organizado: conjuntos de dados personalizados gerados para cenários de análise ou casos de utilização específicos, ou conjuntos de dados de aplicações de análise originais do Microsoft 365 para a extensibilidade, por exemplo, Viva Insights métricas).
Estão disponíveis vários conjuntos de dados para cada um dos seguintes:
- Teams
- Outlook
- Microsoft Entra ID
- OneDrive/Sharepoint
- Viva Insights
Os novos conjuntos de dados são adicionados regularmente ao Microsoft Graph Data Connect. Para obter uma lista completa, veja Conjunto de dados, regiões e sinks.
Que conjuntos de dados estão em pré-visualização e que estão geralmente disponíveis?
Para obter informações sobre conjuntos de dados que estão geralmente disponíveis ou apenas em pré-visualização, veja Conjunto de dados, regiões e sinks.
Como é calculada a faturação?
O Microsoft Graph Data Connect cobra mensalmente aos clientes e também arredondamento fracionável ao calcular a fatura. Cada execução de pipeline é faturada separadamente.
Por exemplo, um cliente tem 20 execuções de pipeline no mês, cada uma com 500 linhas. No total, o cliente executa pipelines para 10 000 linhas nesse mês. No entanto, a fatura não será de 10 000 linhas/1000 linhas = 10 unidades.
Em vez disso, o cliente é cobrado por 20 unidades porque o Microsoft Graph Data Connect arredonda frações. Uma vez que 500 linhas/1000 linhas = 0,5 e 0,5 é uma fração, arredonda até 1. O cliente é faturado uma unidade por execução de pipeline, o que resulta em 20 unidades faturadas no total.
O que posso fazer se um conjunto de dados ainda não for suportado para o meu inquilino?
Para conjuntos de dados de pré-visualização, certifique-se de que cumpre os critérios descritos em Conjuntos de dados, regiões e sinks. Estes conjuntos de dados só estão disponíveis para os clientes que optaram por participar nos mesmos explicitamente.
Para perguntas, crie um novo pedido de Suporte do Azure, incluindo os detalhes mencionados na secção anterior.
Para que cenários é melhor o Microsoft Graph Data Connect?
As organizações que podem explorar grandes conjuntos de dados que potencializem suas ferramentas de produtividade podem obter insights incríveis sobre os desafios e as oportunidades que podem encontrar. Os clientes criam aplicações em vários cenários, tais como redes organizacionais para análise de produtividade de pessoas, partilha de informações sobre a análise de segurança e conformidade, pontos fortes de relação entre vendedores para análise de relações com os clientes e muito mais.
É possível que meus dados permaneçam dentro da assinatura da organização com a Conexão de Dados do Microsoft Graph?
O Microsoft Graph Data Connect respeita o limite do inquilino organizacional ao entregar os conjuntos de dados pedidos. Os recursos do Azure e os serviços do Microsoft 365 têm de estar localizados dentro do mesmo Microsoft Entra inquilino para aceder ao seu conjunto de dados do Microsoft 365. O acesso a conjuntos de dados entre inquilinos não está disponível atualmente.
As entidades de serviços são requeridas com a Conexão de Dados do Microsoft Graph?
Ao criar o Azure Synapse ou o pipeline do Data Factory, tem de fornecer um principal de serviço ao serviço ligado do Microsoft 365. No Azure, uma entidade de serviço é uma identidade de segurança que representa um aplicativo ou serviço (e não um usuário). O Data Connect usa essa entidade de serviço como sua identidade ao obter acesso autorizado aos dados do Microsoft 365.
Se você criar um Aplicativo Gerenciado do Azure para que outras pessoas usem em seus locatários, você ainda irá fornecer uma entidade de serviço para uso do aplicativo. A entidade de serviço ficará armazenada em seu (do fornecedor) locatário. No entanto, se o aplicativo precisar de outras entidades de serviço, seu cliente (instalador) irá criá-las em seu próprio locatário. Por exemplo, o pipeline Azure Synapse ou Azure Data Factory provavelmente precisa de acesso a um recurso de armazenamento no Azure. O cliente criaria a entidade de serviço com permissões para a conta de armazenamento para uso do pipeline.
Para obter mais informações sobre como criar a sua aplicação com Azure Synapse ou Azure Data Factory, veja o guia de introdução ao Data Connect.
Cada execução de pipeline exigirá um novo pedido de consentimento?
Desde que o âmbito dos dados que estão a ser extraídos permaneça o mesmo para conjuntos de dados, colunas, utilizadores e sink, a execução do pipeline não requer um novo pedido de consentimento. Em vez disso, o pipeline utiliza o consentimento ativo aprovado. A execução de um pipeline com o mesmo âmbito para datas diferentes não requer um novo consentimento.
Posso eliminar a duplicação de emails quando necessário?
Quando você extrair emails do conjunto de dados Message, geralmente haverá vários objetos JSON para o mesmo email. Estes duplicados existem porque, quando é enviado um e-mail para várias pessoas, existe uma cópia do e-mail na caixa de correio de cada destinatário. Como o conjunto de dados é extraído de cada caixa de correio, haverá todas as cópias entre os usuários. Em alguns cenários, talvez seja necessário manter cada cópia, mas em outros talvez você queira remover as duplicatas.
Você pode eliminar as duplicatas dos objetos JSON exportados baseados em internetMessageId das mensagens: duas mensagens com o mesmo internetMessageId são cópias duplicadas da mesma instância. Como as duplicatas podem existir em diferentes blobs, você deve eliminar as duplicatas em todos os blobs em vez de fazer isso em cada blob separadamente.
Posso usar o campo puser para determinar a relevância do usuário?
Os dados extraídos incluem algumas propriedades meta que não existem se forem usadas as APIs correspondentes do Microsoft Graph. Especificamente, o campo puser pode ser útil para determinar de quais usuários os dados foram extraídos. No cenário em que você tem duas cópias do mesmo email em caixas de correio diferentes, você pode usar o campo puser para determinar as caixas de correio de origem das cópias. O campo puser também é útil para conjuntos de dados, como o conjunto de dados Manager. O JSON exportado inclui informações sobre um gerenciador, mas isso é útil apenas se você souber o que gerenciam. O campo puser indicará qual gerenciador corresponde ao objeto JSON.
A configuração do locatário no modo híbrido é compatível?
Se sua configuração do Microsoft 365 tiver alguns usuários no Exchange Online e alguns usuários no Exchange local, os usuários que estão no Exchange local não terão suporte. Infelizmente, o Data Connect não é atualmente suportado para utilizadores do Exchange no local.
Há suporte para contas de recursos?
Atualmente não apoiamos o acesso a mensagens ou eventos a partir de contas de recursos.
Por que às vezes vejo vários arquivos por execução de pipeline do ADF, mas outras vezes vejo apenas um arquivo por execução?
O Data Connect do Microsoft Graph leva a lista de usuários para cada execução de pipeline e, em seguida, distribui a extração e curadoria do conjunto de dados em vários trabalhos executados em paralelo. Para cada execução paralela, um arquivo de saída é gerado no coletor de dados definido por você. Para alguns casos, se a lista de usuários for pequena, eles podem ser mapeados em um trabalho de extração e curadoria e, nesses casos, apenas um arquivo de saída seria gerado no coletor de dados.