Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
A semântica de grafos oferece suporte a duas abordagens principais para trabalhar com grafos: grafos transitórios criados na memória para cada consulta e grafos persistentes, definidos como modelos de grafos e instantâneos dentro do banco de dados. Este artigo fornece práticas recomendadas para ambos os métodos, permitindo que você selecione a abordagem ideal e use a semântica de grafo KQL com eficiência.
Esta orientação aborda:
- Estratégias de criação e otimização do grafo
- Técnicas de consulta e considerações de desempenho
- Design de esquema para grafos persistentes
- Integração com outros recursos do KQL
- Armadilhas comuns a serem evitadas
Abordagens de modelagem de grafo
Há duas abordagens para trabalhar com grafos: transitória e persistente.
Grafos transitórios
Criado dinamicamente usando o make-graph operador. Esses grafos existem somente durante a execução da consulta e são ideais para análise ad hoc ou exploratória em conjuntos de dados pequenos a médios.
Grafos persistentes
Definido usando modelos de grafo e instantâneos de grafo. Esses grafos são armazenados no banco de dados, dão suporte ao esquema e ao controle de versão e são otimizados para análises repetidas, em grande escala ou colaborativas.
Práticas recomendadas para grafos transitórios
Grafos transitórios, criados na memória usando o make-graph operador, são ideais para análise ad hoc, prototipagem e cenários em que a estrutura do grafo é alterada com frequência ou requer apenas um subconjunto de dados disponíveis.
Otimizar o tamanho do grafo para desempenho
make-graph cria uma representação na memória, incluindo tanto a estrutura quanto as propriedades. Otimize o desempenho:
- Aplicar filtros antecipadamente – selecione apenas nós, bordas e propriedades relevantes antes da criação do grafo
- Usar projeções – Remover colunas desnecessárias para minimizar o consumo de memória
- Aplicar agregações – Resumir dados quando apropriado para reduzir a complexidade do grafo
Exemplo: reduzindo o tamanho do grafo por meio de filtragem e projeção
Neste cenário, Bob mudou os gerentes de Alice para Eve. Para exibir apenas o estado organizacional mais recente, minimizando o tamanho do grafo:
let allEmployees = datatable(organization: string, name:string, age:long)
[
"R&D", "Alice", 32,
"R&D","Bob", 31,
"R&D","Eve", 27,
"R&D","Mallory", 29,
"Marketing", "Alex", 35
];
let allReports = datatable(employee:string, manager:string, modificationDate: datetime)
[
"Bob", "Alice", datetime(2022-05-23),
"Bob", "Eve", datetime(2023-01-01),
"Eve", "Mallory", datetime(2022-05-23),
"Alice", "Dave", datetime(2022-05-23)
];
let filteredEmployees =
allEmployees
| where organization == "R&D"
| project-away age, organization;
let filteredReports =
allReports
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate;
filteredReports
| make-graph employee --> manager with filteredEmployees on name
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, topManager = manager.name
Saída:
| empregado | Gerente Principal |
|---|---|
| Bob | Mallory |
Manter o estado atual com visões materializadas
O exemplo anterior mostrou como obter o último estado conhecido usando summarize e arg_max. Essa operação pode ser intensiva em computação, portanto, considere o uso de exibições materializadas para melhorar o desempenho.
Etapa 1: Criar tabelas com controle de versão
Crie tabelas com um mecanismo de versionamento para séries temporais de grafos.
.create table employees (organization: string, name:string, stateOfEmployment:string, properties:dynamic, modificationDate:datetime)
.create table reportsTo (employee:string, manager:string, modificationDate: datetime)
Etapa 2: Criar exibições materializadas
Use a função de agregação arg_max para determinar o estado mais recente:
.create materialized-view employees_MV on table employees
{
employees
| summarize arg_max(modificationDate, *) by name
}
.create materialized-view reportsTo_MV on table reportsTo
{
reportsTo
| summarize arg_max(modificationDate, *) by employee
}
Etapa 3: Criar funções auxiliares
Verifique se somente o componente materializado é usado e aplique filtros adicionais:
.create function currentEmployees () {
materialized_view('employees_MV')
| where stateOfEmployment == "employed"
}
.create function reportsTo_lastKnownState () {
materialized_view('reportsTo_MV')
| project-away modificationDate
}
Essa abordagem fornece consultas mais rápidas, maior simultaneidade e menor latência para análise de estado atual, preservando o acesso a dados históricos.
let filteredEmployees =
currentEmployees
| where organization == "R&D"
| project-away organization;
reportsTo_lastKnownState
| make-graph employee --> manager with filteredEmployees on name
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingPath = hasManager.manager
Implementar viagem no tempo em grafos
A análise de dados com base em estados de grafo histórico fornece um contexto temporal valioso. Implemente essa capacidade de "viagem no tempo" combinando filtros de tempo com summarize e arg_max.
.create function graph_time_travel (interestingPointInTime:datetime ) {
let filteredEmployees =
employees
| where modificationDate < interestingPointInTime
| summarize arg_max(modificationDate, *) by name;
let filteredReports =
reportsTo
| where modificationDate < interestingPointInTime
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate;
filteredReports
| make-graph employee --> manager with filteredEmployees on name
}
Exemplo de uso:
Consultar o gerente superior de Bob com base no estado do gráfico de junho de 2022:
graph_time_travel(datetime(2022-06-01))
| graph-match (employee)-[hasManager*2..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingPath = hasManager.manager
Saída:
| empregado | Gerente Principal |
|---|---|
| Bob | Dave |
Manipular vários tipos de nós e arestas
Ao trabalhar com grafos complexos que contêm vários tipos de nó, use um modelo de grafo de propriedades canônicas. Defina nós com atributos como nodeId (cadeia de caracteres), label (cadeia de caracteres) e properties (dinâmico), enquanto as bordas incluem source (cadeia de caracteres), destination (cadeia de caracteres), label (cadeia de caracteres) e properties campos (dinâmicos).
Exemplo: Análise de manutenção de fábrica
Considere um gerente de fábrica investigando problemas de equipamento e pessoal responsável. O cenário combina grafos de ativos de equipamentos de produção com a hierarquia da equipe de manutenção:
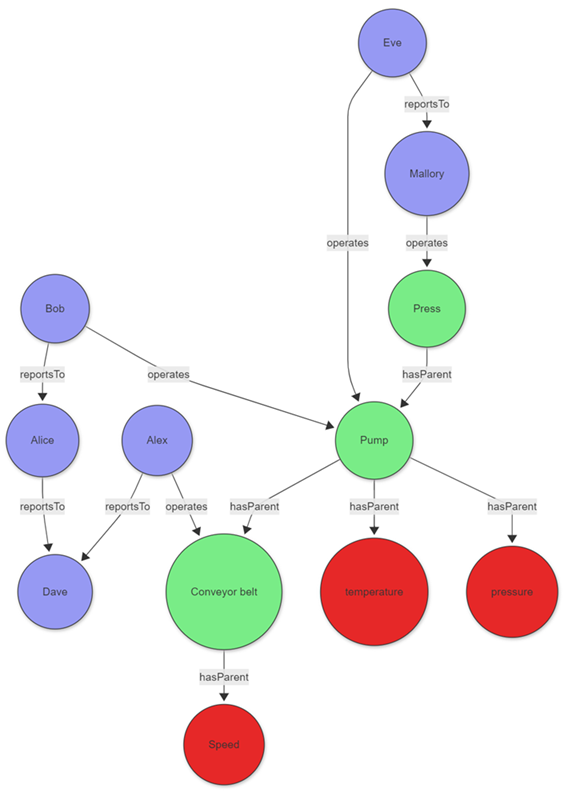
Os dados dessas entidades podem ser armazenados diretamente em seu cluster ou adquiridos usando consulta federada a um serviço diferente. Para ilustrar o exemplo, os seguintes dados tabulares são criados como parte da consulta:
let sensors = datatable(sensorId:string, tagName:string, unitOfMeasure:string)
[
"1", "temperature", "°C",
"2", "pressure", "Pa",
"3", "speed", "m/s"
];
let timeseriesData = datatable(sensorId:string, timestamp:string, value:double, anomaly: bool )
[
"1", datetime(2023-01-23 10:00:00), 32, false,
"1", datetime(2023-01-24 10:00:00), 400, true,
"3", datetime(2023-01-24 09:00:00), 9, false
];
let employees = datatable(name:string, age:long)
[
"Alice", 32,
"Bob", 31,
"Eve", 27,
"Mallory", 29,
"Alex", 35,
"Dave", 45
];
let allReports = datatable(employee:string, manager:string)
[
"Bob", "Alice",
"Alice", "Dave",
"Eve", "Mallory",
"Alex", "Dave"
];
let operates = datatable(employee:string, machine:string, timestamp:datetime)
[
"Bob", "Pump", datetime(2023-01-23),
"Eve", "Pump", datetime(2023-01-24),
"Mallory", "Press", datetime(2023-01-24),
"Alex", "Conveyor belt", datetime(2023-01-24),
];
let assetHierarchy = datatable(source:string, destination:string)
[
"1", "Pump",
"2", "Pump",
"Pump", "Press",
"3", "Conveyor belt"
];
Os funcionários, sensores e outras entidades e relações não compartilham um modelo de dados canônico. O operador de união pode ser usado para combinar e padronizar os dados.
A consulta a seguir une os dados do sensor com os dados da série temporal para identificar sensores com leituras anormais e, em seguida, usa uma projeção para criar um modelo comum para os nós de grafo.
let nodes =
union
(
sensors
| join kind=leftouter
(
timeseriesData
| summarize hasAnomaly=max(anomaly) by sensorId
) on sensorId
| project nodeId = sensorId, label = "tag", properties = pack_all(true)
),
( employees | project nodeId = name, label = "employee", properties = pack_all(true));
As bordas são transformadas de maneira semelhante.
let edges =
union
( assetHierarchy | extend label = "hasParent" ),
( allReports | project source = employee, destination = manager, label = "reportsTo" ),
( operates | project source = employee, destination = machine, properties = pack_all(true), label = "operates" );
Com os nós padronizados e os dados de bordas, você pode criar um grafo usando o operador make-graph
let graph = edges
| make-graph source --> destination with nodes on nodeId;
Depois que o grafo for criado, defina o padrão de caminho e projeira as informações necessárias. O padrão começa em um nó de tag, seguido por uma aresta de comprimento variável para um ativo. Esse ativo é operado por um operador que se reporta a um gerente superior por meio de uma borda de comprimento variável chamada reportsTo. A seção de restrições do operador de correspondência de grafo, nesse caso, a cláusula where, filtra as etiquetas para aquelas com uma anomalia que foram operadas em um dia específico.
graph
| graph-match (tag)-[hasParent*1..5]->(asset)<-[operates]-(operator)-[reportsTo*1..5]->(topManager)
where tag.label=="tag" and tobool(tag.properties.hasAnomaly) and
startofday(todatetime(operates.properties.timestamp)) == datetime(2023-01-24)
and topManager.label=="employee"
project
tagWithAnomaly = tostring(tag.properties.tagName),
impactedAsset = asset.nodeId,
operatorName = operator.nodeId,
responsibleManager = tostring(topManager.nodeId)
Saída
| tagWithAnomaly | ativoImpactado | operatorName | gerenteResponsável |
|---|---|---|---|
| temperatura | Bomba | Véspera | Mallory |
A projeção no graph-match mostra que o sensor de temperatura exibiu uma anomalia no dia especificado. O sensor foi operado por Eve, que finalmente se reporta a Mallory. Com essas informações, o gerente da fábrica pode entrar em contato com Eve e, se necessário, Mallory para entender melhor a anomalia.
Práticas recomendadas para grafos persistentes
Grafos persistentes, definidos usando modelos de grafo e instantâneos de grafo, fornecem soluções robustas para necessidades avançadas de análise de grafo. Esses grafos se destacam em cenários que exigem análises repetidas de relações de dados grandes, complexas ou em evolução e facilitam a colaboração, permitindo que as equipes compartilhem definições de grafo padronizadas e resultados analíticos consistentes. Ao persistir estruturas de grafo no banco de dados, essa abordagem aprimora significativamente o desempenho de consultas recorrentes e dá suporte a recursos sofisticados de controle de versão.
Usar esquema e definição para consistência e desempenho
Um esquema claro para seu modelo de grafo é essencial, pois especifica os tipos de nós e arestas, juntamente com suas propriedades. Essa abordagem garante a consistência dos dados e permite uma consulta eficiente. Utilize a seção Definition para especificar como nós e bordas são construídos a partir de seus dados tabulares através das etapas AddNodes e AddEdges.
Aproveitar rótulos estáticos e dinâmicos para modelagem flexível
Ao modelar seu grafo, você pode utilizar abordagens de rotulagem estáticas e dinâmicas para obter uma flexibilidade ideal. Os rótulos estáticos são ideais para tipos de nó e borda bem definidos que raramente são alterados—defina-os na seção Schema e referencie-os na matriz Labels das suas etapas. Para casos em que os tipos de nó ou borda são determinados por valores de dados (por exemplo, quando o tipo é armazenado em uma coluna), use rótulos dinâmicos especificando um LabelsColumn em sua etapa para atribuir rótulos em runtime. Essa abordagem é especialmente útil para grafos com esquemas heterogêneos ou em evolução. Ambos os mecanismos podem ser combinados efetivamente, você pode definir uma Labels matriz para rótulos estáticos e também especificar um LabelsColumn para incorporar rótulos adicionais de seus dados, fornecendo flexibilidade máxima ao modelar grafos complexos com categorização fixa e controlada por dados.
Exemplo: usando rótulos dinâmicos para vários tipos de nó e borda
O exemplo a seguir demonstra uma implementação efetiva de rótulos dinâmicos em um grafo que representa relações profissionais. Nesse cenário, o grafo contém pessoas e empresas como nodos, com relações de emprego formando as arestas entre elas. A flexibilidade desse modelo vem da determinação de tipos de nó e borda diretamente de colunas nos dados de origem, permitindo que a estrutura do grafo se adapte organicamente às informações subjacentes.
.create-or-alter graph_model ProfessionalNetwork ```
{
"Schema": {
"Nodes": {
"Person": {"Name": "string", "Age": "long"},
"Company": {"Name": "string", "Industry": "string"}
},
"Edges": {
"WORKS_AT": {"StartDate": "datetime", "Position": "string"}
}
},
"Definition": {
"Steps": [
{
"Kind": "AddNodes",
"Query": "Employees | project Id, Name, Age, NodeType",
"NodeIdColumn": "Id",
"Labels": ["Person"],
"LabelsColumn": "NodeType"
},
{
"Kind": "AddEdges",
"Query": "EmploymentRecords | project EmployeeId, CompanyId, StartDate, Position, RelationType",
"SourceColumn": "EmployeeId",
"TargetColumn": "CompanyId",
"Labels": ["WORKS_AT"],
"LabelsColumn": "RelationType"
}
]
}
}
```
Essa abordagem de rotulagem dinâmica fornece flexibilidade excepcional ao modelar grafos com vários tipos de nó e borda, eliminando a necessidade de modificar seu esquema sempre que um novo tipo de entidade aparecer em seus dados. Ao desacoplar o modelo lógico da implementação física, o grafo pode evoluir continuamente para representar novas relações sem exigir alterações estruturais no esquema subjacente.
Estratégias de particionamento multilocatário para cenários ISV em larga escala
Em grandes organizações, particularmente em cenários ISV, os grafos podem consistir em vários bilhões de nós e bordas. Essa escala apresenta desafios exclusivos que exigem abordagens estratégicas de particionamento para manter o desempenho, gerenciando custos e complexidade.
Noções básicas sobre o desafio
Ambientes multilocatários em larga escala geralmente exibem as seguintes características:
- Bilhões de nós e bordas – grafos em escala empresarial que excedem os recursos tradicionais do banco de dados de grafo
- Distribuição de tamanho do locatário - normalmente segue uma lei de potência em que 99,9% de locatários têm grafos pequenos a médios, enquanto 0,1% têm grafos enormes
- Requisitos de desempenho – necessidade de análise em tempo real (dados atuais) e recursos de análise histórica
- Considerações de custo – Balancear entre os custos de infraestrutura e os recursos analíticos
Particionamento por limites naturais
A abordagem mais eficaz para gerenciar grafos em larga escala é particionar por limites naturais, normalmente identificadores de locatário ou unidades organizacionais:
Principais estratégias de particionamento:
- Particionamento baseado em locatário – Separar grafos por cliente, organização ou unidade de negócios
- Particionamento geográfico – Dividir por região, país ou localização do datacenter
- Particionamento temporal – separado por períodos de tempo para análise histórica
- Particionamento funcional – Divisão por área de domínio ou aplicativo de negócios
Exemplo: estrutura organizacional multitenante
// Partition employees and reports by tenant
let tenantEmployees =
allEmployees
| where tenantId == "tenant_123"
| project-away tenantId;
let tenantReports =
allReports
| where tenantId == "tenant_123"
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate, tenantId;
tenantReports
| make-graph employee --> manager with tenantEmployees on name
| graph-match (employee)-[hasManager*1..5]-(manager)
where employee.name == "Bob"
project employee = employee.name, reportingChain = hasManager.manager
Abordagem híbrida: grafos transitórios versus persistentes pelo tamanho do locatário
A estratégia mais econômica combina grafos transitórios e persistentes com base nas características do locatário:
Locatários pequenos a médios (99,9% de locatários)
Use grafos transitórios para a maioria dos locatários:
Vantagens:
- Sempre dados atualizados up-to – nenhuma manutenção de instantâneo necessária
- Menor sobrecarga operacional – nenhum modelo de grafo ou gerenciamento de instantâneos
- Econômico – Sem custos adicionais de armazenamento para estruturas de grafo
- Disponibilidade imediata – Sem atrasos de pré-processamento
Padrão de implementação:
.create function getTenantGraph(tenantId: string) {
let tenantEmployees =
employees
| where tenant == tenantId and stateOfEmployment == "employed"
| project-away tenant, stateOfEmployment;
let tenantReports =
reportsTo
| where tenant == tenantId
| summarize arg_max(modificationDate, *) by employee
| project-away modificationDate, tenant;
tenantReports
| make-graph employee --> manager with tenantEmployees on name
}
// Usage for small tenant
getTenantGraph("small_tenant_456")
| graph-match (employee)-[reports*1..3]-(manager)
where employee.name == "Alice"
project employee = employee.name, managerChain = reports.manager
Locatários grandes (0,1% de locatários)
Use grafos persistentes para os maiores locatários:
Vantagens:
- Escalabilidade – Manipular grafos que excedem as limitações de memória
- Otimização de desempenho – eliminar a latência de construção para consultas complexas
- Análise avançada – Suporte a algoritmos de grafo sofisticados e análise
- Análise histórica – Vários instantâneos para comparação temporal
Padrão de implementação:
// Create graph model for large tenant (example: Contoso)
.create-or-alter graph_model ContosoOrgChart ```
{
"Schema": {
"Nodes": {
"Employee": {
"Name": "string",
"Department": "string",
"Level": "int",
"JoinDate": "datetime"
}
},
"Edges": {
"ReportsTo": {
"Since": "datetime",
"Relationship": "string"
}
}
},
"Definition": {
"Steps": [
{
"Kind": "AddNodes",
"Query": "employees | where tenant == 'Contoso' and stateOfEmployment == 'employed' | project Name, Department, Level, JoinDate",
"NodeIdColumn": "Name",
"Labels": ["Employee"]
},
{
"Kind": "AddEdges",
"Query": "reportsTo | where tenant == 'Contoso' | summarize arg_max(modificationDate, *) by employee | project employee, manager, modificationDate as Since | extend Relationship = 'DirectReport'",
"SourceColumn": "employee",
"TargetColumn": "manager",
"Labels": ["ReportsTo"]
}
]
}
}
```
// Create snapshot for Contoso
.create graph snapshot ContosoSnapshot from ContosoOrgChart
// Query Contoso's organizational graph
graph("ContosoOrgChart")
| graph-match (employee)-[reports*1..10]-(executive)
where employee.Department == "Engineering"
project employee = employee.Name, executive = executive.Name, pathLength = array_length(reports)
Práticas recomendadas para cenários ISV
- Comece com grafos transitórios – Comece todos os novos usuários com grafos transitórios por simplicidade
- Monitorar padrões de crescimento – Implementar a detecção automática de locatários que exigem grafos persistentes
- Criação de snapshot em lote – Agendar atualizações de snapshot durante períodos de baixa utilização
- Isolamento de locatários – Garanta que os modelos de grafo e instantâneos estejam isolados corretamente entre locatários
- Gerenciamento de recursos – Usar grupos de carga de trabalho para impedir que consultas de locatários grandes afetem locatários menores
- Otimização de custo – examinar e otimizar regularmente o limite persistente/transitório com base nos padrões de uso reais
Essa abordagem híbrida permite que as organizações forneçam uma análise de dados sempre atual para a maioria dos locatários, fornecendo recursos de análise em escala empresarial para os maiores locatários, otimizando o custo e o desempenho em toda a base de clientes.