Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
Traduções não em inglês são fornecidas apenas para conveniência. Consulte a versão EN-US deste documento para obter a versão de associação.
Este artigo fornece detalhes sobre como os dados fornecidos por você são processados, utilizados e armazenados pelo serviço de conversão de texto em fala do Azure AI Speech. Como um lembrete importante, você é responsável pelo seu uso e pela implementação dessa tecnologia e precisa obter todas as permissões necessárias, incluindo, se aplicável, do talento de voz e avatar (e, se aplicável, usuários de suas integrações de voz pessoal) para o processamento de sua voz, imagem, semelhança e/ou outros dados para desenvolver vozes sintéticas e/ou avatares.
Você também é responsável por obter quaisquer licenças, permissões ou outros direitos necessários para o conteúdo que você insere no serviço de conversão de texto em fala para gerar áudio, imagem e/ou vídeo. Algumas jurisdições podem impor requisitos legais especiais para a coleta, processamento e armazenamento de determinadas categorias de dados, como dados biométricos, e obrigar a divulgação do uso de vozes sintéticas, imagens e/ou vídeos aos usuários. Antes de usar o texto em fala para processar e armazenar dados de qualquer tipo e, se aplicável, criar uma voz neural personalizada, voz pessoal ou modelos de avatar personalizados, você deve garantir que esteja em conformidade com todos os requisitos legais que podem se aplicar a você.
Quais dados os serviços de conversão de texto em fala processam?
A voz neural predefinida e o avatar predefinido processam os seguintes tipos de dados:
- Entrada de texto para síntese de fala. Esse é o texto que você seleciona e envia para o serviço de texto para fala para gerar saída de áudio usando um conjunto de vozes neurais predefinidas, ou para gerar um avatar predefinido que pronuncia o áudio gerado a partir de vozes neurais, sejam elas predefinidas ou personalizadas.
Arquivo de declaração de reconhecimento do talento de voz gravado. Os clientes são obrigados a enviar uma declaração gravada específica pelo locutor, na qual reconhecem que sua voz será usada para criar vozes sintéticas.
Observação
Ao preparar seu script de gravação, certifique-se de incluir a declaração de reconhecimento obrigatória para que o talento de voz grave. Você pode encontrar a instrução em vários idiomas aqui. O idioma da declaração de reconhecimento deve ser o mesmo que o idioma dos dados de treinamento da gravação de áudio.
Dados de treinamento (incluindo arquivos de áudio e transcrições de texto relacionadas). Isso inclui gravações de áudio do locutor que concordou em usar sua voz para treinamento de modelos e as transcrições de texto relacionadas. Em um projeto pro de voz neural personalizado, você pode fornecer suas próprias transcrições de texto de áudio ou usar o recurso de transcrição de reconhecimento de fala automatizado disponível no Speech Studio para gerar uma transcrição de texto do áudio. As gravações de áudio e os arquivos de transcrição de texto serão usados como dados de treinamento do modelo de voz. Em um projeto de voz neural personalizada lite, você será solicitado a gravar a voz falando o script definido pela Microsoft no Speech Studio. Transcrições de texto não são necessárias para recursos de voz pessoal.
Texto como o script de teste. Você pode carregar seus próprios scripts baseados em texto para avaliar e testar a qualidade do modelo de voz neural personalizado gerando exemplos de áudio de síntese de fala. Isso não se aplica a recursos de voz pessoais.
Entrada de texto para síntese de fala. Esse é o texto que você seleciona e envia para o serviço de conversão de texto em fala para gerar um áudio usando sua voz neural personalizada.
Como os serviços de texto para fala processam dados?
Voz neural predefinida
O diagrama a seguir ilustra como seus dados são processados para síntese com voz neural predefinida. A entrada é texto e a saída é áudio. Observe que nem o conteúdo de áudio de entrada nem de saída será armazenado nos logs da Microsoft.

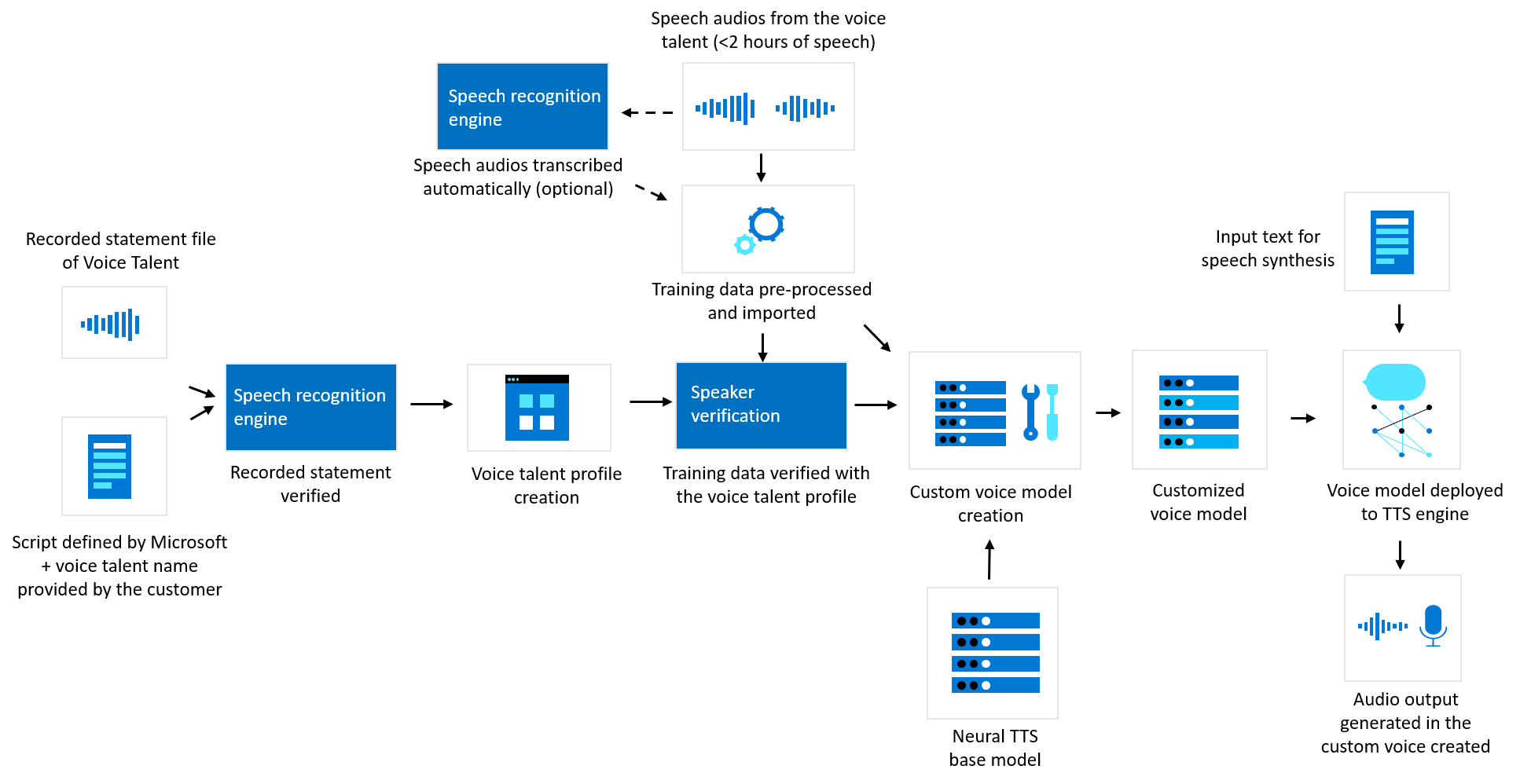
Voz neural personalizada
O diagrama a seguir ilustra como seus dados são processados para voz neural personalizada. Este diagrama aborda três tipos diferentes de processamento: como a Microsoft verifica arquivos de declaração de reconhecimento gravados do talento de voz antes do treinamento personalizado do modelo de voz neural, como a Microsoft cria um modelo de voz neural personalizado com seus dados de treinamento e como a conversão de texto em fala processa sua entrada de texto para gerar conteúdo de áudio.
Avatar de conversão de texto em fala
O diagrama abaixo ilustra como seus dados são processados para síntese com avatar de conversão de texto em fala predefinido. Há três componentes em um fluxo de trabalho de geração de conteúdo de avatar: analisador de texto, sintetizador de áudio TTS e sintetizador de vídeo de avatar do TTS. Para gerar vídeo de avatar, o texto é primeiramente inserido no analisador de texto, que fornece a saída na forma de sequência de fonemas. Em seguida, o sintetizador de áudio TTS prevê os recursos acústicos do texto de entrada e sintetiza a voz. Essas duas partes são fornecidas por modelos de conversão de texto em voz. Em seguida, o modelo Avatar de conversão de texto em fala Neural prevê a imagem da sincronização labial com os recursos acústicos, para que o vídeo sintético seja gerado.
![]()
Tradução de vídeo (versão prévia)
O diagrama a seguir ilustra como seus dados são processados com tradução de vídeo. Cliente carrega o vídeo como entrada para tradução de vídeo, o áudio do diálogo é extraído e a tecnologia de reconhecimento de voz transcreve o áudio em texto. Em seguida, o conteúdo do texto será traduzido para o conteúdo do idioma de destino e, usando o recurso de conversão de texto em fala, o áudio traduzido será mesclado com o conteúdo original do vídeo como saída de vídeo.

Verificação de declaração de reconhecimento registrada
A Microsoft exige que os clientes carreguem um arquivo de áudio no Speech Studio com uma declaração gravada do talento de voz reconhecendo que o cliente usará sua voz para criar uma voz sintética. A Microsoft pode usar a tecnologia de reconhecimento de fala e conversão de fala em texto da Microsoft para transcrever essa declaração de reconhecimento gravada em texto e verificar se o conteúdo na gravação corresponde ao script predefinido fornecido pela Microsoft. Essa declaração de reconhecimento, juntamente com as informações de talento que você fornece com o áudio, é usada para criar um perfil de talento de voz. Você deve associar dados de treinamento ao perfil de talento de voz relevante ao iniciar o treinamento de voz neural personalizado.
A Microsoft também pode processar assinaturas de voz biométricas do arquivo de declaração de reconhecimento gravado do profissional de voz e do áudio aleatório dos conjuntos de dados de treinamento para confirmar, com razoável confiança, que a assinatura de voz na gravação da declaração de reconhecimento e as gravações de dados de treinamento correspondem, usando a Verificação do Locutor de IA do Azure. Uma assinatura de voz também pode ser chamada de "modelo de voz" ou "impressão de voz" e é um vetor numérico que representa as características de voz de um indivíduo extraídas de gravações de áudio de uma pessoa falando. Essa proteção técnica destina-se a ajudar a evitar o uso indevido da voz neural personalizada, impedindo, por exemplo, que os clientes treinem modelos de voz com gravações de áudio e usem os modelos para falsificar a voz de uma pessoa sem seu conhecimento ou consentimento.
As assinaturas de voz são usadas pela Microsoft apenas para fins de verificação de alto-falante ou como necessário para investigar o uso indevido dos serviços.
O Adendo de Proteção de Dados de Produtos e Serviços da Microsoft ("DPA") define as obrigações dos clientes e da Microsoft em relação ao processamento e à segurança dos dados do cliente e dados pessoais em conexão com o Azure e é incorporado por referência ao contrato empresarial dos clientes para os serviços do Azure. O processamento de dados da Microsoft nesta seção é regido na seção Operações Comerciais de Interesse Legítimo do Adendo de Proteção de Dados.
Treinar um modelo de voz neural personalizado
Os dados de treinamento (áudio de fala) que os clientes enviam ao Speech Studio são pré-processados usando ferramentas automatizadas para verificação de qualidade, incluindo verificação de formato de dados, pontuação de pronúncia, detecção de ruído, mapeamento de script etc. Os dados de treinamento são então importados para o componente de treinamento de modelo da plataforma de voz personalizada. Durante o processo de treinamento, os dados de treinamento (transcrições de áudio de voz e texto) são decompostos em mapeamentos refinados de acústico de voz e texto, como uma sequência de fonemas. Por meio de uma modelagem de inclinação de máquina mais complexa, o serviço cria um modelo de voz, que pode ser usado para gerar áudio que soa semelhante ao talento de voz e pode até ser gerado em diferentes idiomas a partir da gravação de dados de treinamento. O modelo de voz é um modelo de computador de conversão de texto em fala que pode imitar características vocais exclusivas de um alto-falante específico. Ele representa um conjunto de parâmetros no formato binário que não é legível por humanos e não contém gravações de áudio.
Os dados de treinamento de um cliente são usados apenas para desenvolver os modelos de voz personalizados desse cliente e não são usados pela Microsoft para treinar ou melhorar qualquer modelo de sintetização de voz da Microsoft.
Geração de conteúdo de síntese de fala/áudio
Depois que o modelo de voz for criado, você poderá usá-lo para criar conteúdo de áudio por meio do serviço de conversão de texto em fala com duas opções diferentes.
Para síntese de fala em tempo real, envie o texto de entrada para o serviço de fala por meio do SDK do TTS ou da API RESTful. O texto em fala processa o texto de entrada e retorna arquivos de conteúdo de áudio de saída em tempo real para o aplicativo que fez a solicitação.
Para síntese assíncrona de áudio longo (síntese em lote), envie os arquivos de texto de entrada para o serviço em lote de conversão de texto em fala por meio da API de Áudio Longo para criar áudios de forma assíncrona com mais de 10 minutos (por exemplo, audiolivros ou palestras). Ao contrário da síntese realizada usando a API de conversão de texto em fala, as respostas não são retornadas em tempo real com a API de Áudio Longo. Os áudios são criados de forma assíncrona e você pode acessar e baixar os arquivos de áudio sintetizados quando eles são disponibilizados no serviço de síntese em lote.
Você também pode usar seu modelo de voz personalizado para gerar conteúdo de áudio por meio de uma ferramenta de Criação de Conteúdo de Áudio sem código e optar por salvar o conteúdo de áudio de entrada ou saída de texto com a ferramenta no armazenamento do Azure.
Processamento de dados para versão lite de voz neural personalizada (versão prévia)
O modelo "Custom neural voice lite" é um tipo de projeto em pré-visualização pública que permite gravar de 20 a 50 exemplos de voz no Speech Studio e criar um modelo de voz neural personalizada leve para fins de demonstração e avaliação. O script de gravação e o script de teste são predefinidos pela Microsoft. Um modelo de voz sintética que você cria usando o neural voice lite personalizado pode ser implantado e usado de forma mais ampla somente se você solicitar e receber acesso completo ao custom neural voice (sujeito a termos aplicáveis).
A voz sintética e a gravação de áudio relacionada que você envia por meio do Speech Studio serão automaticamente excluídas dentro de 90 dias, a menos que você obtenha acesso total à voz neural personalizada e opte por implantar a voz sintética, nesse caso, você controlará a duração de sua retenção. Se o talento de voz quiser ter a voz sintética e as gravações de áudio relacionadas excluídas antes de 90 dias, elas poderão excluí-las diretamente no portal ou entrar em contato com sua empresa para fazer isso.
Além disso, antes de implantar qualquer modelo de voz sintética criado usando um projeto de voz neural personalizada lite, o talento de voz deve fornecer uma gravação adicional na qual reconhece que a voz sintética será usada para outros fins além de demonstração e avaliação.
Processamento de dados para API de voz pessoal (versão prévia)
A voz pessoal permite que os clientes criem uma voz sintética usando uma amostra de voz humana curta. O arquivo de confirmação verbal descrito acima é exigido de cada usuário que utiliza a integração no seu aplicativo. A Microsoft pode processar assinaturas de voz biométricas do arquivo de instrução de voz gravado de cada usuário e de seu exemplo de treinamento gravado (também conhecido como prompt) para confirmar, com um grau razoável de confiança, se a assinatura de voz na gravação da instrução de confirmação e na gravação de dados de treinamento correspondem usando a Verificação de Locutor com IA da Azure.
O exemplo de treinamento será usado para criar o modelo de voz. O modelo de voz pode ser usado para gerar fala com entrada de texto fornecida ao serviço por meio da API, sem a necessidade de implantação adicional.
Armazenamento e retenção de dados
Todos os serviços de texto para fala
Entrada de texto para síntese de fala: A Microsoft não retém ou armazena o texto que você fornece com o texto de síntese em tempo real para a API de fala. Os scripts fornecidos por meio da API de Áudio Longo para conversão de texto em fala ou por meio da API de lote de avatar de conversão de texto em fala para avatar de conversão de texto em fala são armazenados no armazenamento do Azure para processar a solicitação de síntese em lote. O texto de entrada pode ser excluído por meio da API de exclusão a qualquer momento.
Conteúdo de áudio e vídeo de saída: A Microsoft não armazena conteúdo de áudio ou vídeo gerado com a API de síntese em tempo real. Se você estiver usando a tradução de vídeo ou a API de Áudio Longo para API de lote de avatar de conversão de texto em fala, o conteúdo de áudio ou vídeo de saída será armazenado no armazenamento do Azure. Esses áudios ou vídeos podem ser removidos a qualquer momento por meio da operação de exclusão .
Declaração de confirmação registrada e dados de verificação do locutor: as assinaturas de voz são usadas pela Microsoft apenas para fins de verificação do locutor ou como necessário para investigar o uso indevido dos serviços. As assinaturas de voz serão mantidas somente pelo tempo necessário para executar a verificação do locutor, o que pode ocorrer de tempos em tempos. A Microsoft pode exigir essa verificação antes de permitir que você treine ou treine novamente modelos de voz neural personalizados no Speech Studio ou conforme necessário. A Microsoft manterá o arquivo de declaração de confirmação gravado e os dados de perfil do locutor pelo tempo necessário para preservar a segurança e a integridade do Azure Speech AI.
Modelos de voz neural personalizados: embora você mantenha os direitos de uso exclusivos para seu modelo de voz neural personalizado, a Microsoft pode manter independentemente uma cópia de modelos de voz neural personalizados pelo tempo necessário. A Microsoft pode usar seu modelo de voz neural personalizado com a única finalidade de proteger a segurança e a integridade dos serviços de IA do Microsoft Azure.
A Microsoft protegerá e armazenará cópias da declaração de confirmação gravada de cada talento de voz e modelos de voz neural personalizados com a mesma segurança de alto nível que usa para seus outros Serviços do Azure. Saiba mais na Central de Confiabilidade da Microsoft.
Dados de treinamento: Você envia dados de treinamento de voz do talento de voz para gerar modelos de voz por meio do Speech Studio, que serão mantidos e armazenados por padrão no armazenamento do Azure (consulte a criptografia do Armazenamento do Azure para obter dados no REST para obter detalhes). Você pode acessar e excluir qualquer um dos dados de treinamento usados para criar modelos de voz por meio do Speech Studio.
Você pode gerenciar o armazenamento de seus dados de treinamento por meio do BYOS (Traga seu próprio armazenamento). Com esse método de armazenamento, os dados de treinamento podem ser acessados apenas para fins de treinamento de modelo de voz e, de outra forma, serão armazenados via BYOS.
Observação
A voz pessoal não dá suporte ao BYOS. Seus dados serão armazenados no armazenamento do Azure gerenciado pela Microsoft. Você pode acessar e excluir qualquer um dos dados de treinamento (áudio prompt) usados para criar modelos de voz por meio da API. A Microsoft pode manter independentemente uma cópia de modelos de voz pessoais pelo tempo necessário. A Microsoft pode usar seu modelo de voz pessoal com a única finalidade de proteger a segurança e a integridade dos serviços de IA do Microsoft Azure.