Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A API Prompt é uma API Web experimental que lhe permite pedir um pequeno modelo de linguagem (SLM) incorporado no Microsoft Edge, a partir do código JavaScript da extensão do seu site ou browser. Utilize a API Prompt para gerar e analisar texto ou criar lógica de aplicação com base na entrada do utilizador e descobrir formas inovadoras de integrar capacidades de engenharia de pedidos na sua aplicação Web.
Conteúdo detalhado:
- Disponibilidade da API de Pedido
- Alternativas e benefícios da API prompt
- Modelos de linguagem pequenos incorporados no Microsoft Edge
- O modelo Phi-4-mini
- O modelo Aion-1.0-Instruct
- Ativar a API de Pedido
- Veja um exemplo de trabalho
- Utilizar a API de Pedido
- Enviar comentários
- Confira também
Disponibilidade da API de Pedido
A API prompt está disponível como uma pré-visualização do programador nos canais Microsoft Edge Canary e Edge Dev, a partir da versão 138.0.3309.2.
A API Prompt destina-se a ajudar a descobrir casos de utilização e a compreender os desafios dos SLMs incorporados. Espera-se que esta API seja bem-sucedida por outras APIs experimentais para tarefas específicas com tecnologia de IA, como a escrita de assistência e tradução de texto. Para saber mais sobre estas outras APIs, veja:
- Resumir, escrever e reescrever texto com as APIs de assistência de escrita
- Traduzir texto com a API do Microsoft Translator
- Detetar idiomas com a API do Detetor de Idiomas
Alternativas e benefícios da API prompt
Para tirar partido das capacidades de IA em sites e extensões de browser, também pode utilizar os seguintes métodos:
Enviar pedidos de rede para serviços de IA baseados na cloud, como soluções de IA Azure.
Execute modelos de IA locais com a API de Rede Neural Web (WebNN) ou o Runtime ONNX para Web.
A API de Pedido utiliza um SLM que é executado no mesmo dispositivo onde são utilizadas as entradas e saídas do modelo (ou seja, localmente). Isto tem os seguintes benefícios em comparação com as soluções baseadas na cloud:
Custo reduzido: Não existem custos associados à utilização de um serviço de IA na cloud.
Independência da rede: Para além da transferência do modelo inicial, não existe latência de rede ao pedir o modelo e também pode ser utilizada quando o dispositivo está offline.
Privacidade melhorada: A entrada de dados para o modelo nunca sai do dispositivo e não é recolhida para preparar modelos de IA.
A API Prompt utiliza um modelo fornecido pelo Microsoft Edge e incorporado no browser, que inclui os benefícios adicionais em soluções locais personalizadas, como as baseadas no WebGPU, WebNN ou WebAssembly:
Custo único partilhado: O modelo fornecido pelo browser é transferido na primeira vez que a API é chamada e partilhada em todos os sites que são executados no browser, reduzindo os custos de rede para o utilizador e programador.
Utilização simplificada para programadores Web: O modelo incorporado pode ser executado através de APIs Web simples e não requer conhecimentos de IA/ML ou com arquiteturas de terceiros.
Modelos de linguagem pequenos incorporados no Microsoft Edge
Nos canais Microsoft Edge Canary e Dev, a partir da versão 138.0.3309.2, a API Prompt utiliza o modelo Phi-4-mini, incorporado no Microsoft Edge.
A partir da versão 150.0.4070, a API Prompt também pode ser utilizada com o modelo de pré-lançamento Aion-1.0-Instruct, que também está incorporado no Microsoft Edge. O Aion-1.0-Instruct é um modelo mais pequeno, mais rápido e eficiente do que o Phi-4-mini e é suportado em dispositivos com GPUs menos capazes ou sem GPU, através da inferência da CPU. Se a classe de desempenho do seu dispositivo não for alta o suficiente para suportar Phi-4-mini, pode testar o modelo pré-lançamento Aion-1.0-Instruct.
Para saber mais sobre ambos os modelos e como ativar o Aion-1.0-Instruct, leia as secções abaixo.
O modelo Phi-4-mini
A API prompt permite-lhe pedir Phi-4-mini, que está incorporado no Microsoft Edge. O Phi-4-mini é um poderoso modelo de linguagem pequena que se destaca em tarefas baseadas em texto. Para saber mais sobre a Phi-4-mini e as suas capacidades, consulte o modelo card em microsoft/Phi-4-mini-instruct.
Aviso de isenção
Tal como outros modelos de linguagem, a família de modelos Phi pode comportar-se potencialmente de formas injustas, pouco fiáveis ou ofensivas. Para saber mais sobre as considerações de IA do modelo, veja Considerações de IA Responsável.
Requisitos de hardware
A pré-visualização do programador da API Prompt destina-se a trabalhar em dispositivos com capacidades de hardware que produzem saídas de SLM com qualidade e latência previsíveis. A API prompt está atualmente limitada a:
Sistema operativo: Windows 10 ou 11 e macOS 13.3 ou posterior.
Armazenamento: Pelo menos 20 GB disponíveis no volume que contém o seu perfil edge. Se o armazenamento disponível ficar abaixo dos 10 GB, o modelo será eliminado para garantir que outras funcionalidades do browser têm espaço suficiente para funcionar.
GPU: 5,5 GB de VRAM ou mais.
Rede: Plano de dados ilimitado ou ligação não atendida. O modelo não é transferido se utilizar uma ligação com tráfego limitado.
Para marcar se o seu dispositivo suportar a pré-visualização do programador da API Prompt, consulte Ativar a API prompt abaixo e marcar a classe de desempenho do dispositivo.
Devido à natureza experimental da API prompt, poderá observar problemas em configurações de hardware específicas. Se vir problemas em configurações de hardware específicas, envie feedback ao abrir um novo problema no repositório MSEdgeExplainers.
Disponibilidade do modelo Phi-4-mini
É necessária uma transferência inicial do modelo Phi-4-mini da primeira vez que um site chama uma API que requer um modelo no dispositivo. Pode monitorizar a transferência do modelo Phi-4-mini ao utilizar a opção monitor ao criar uma nova sessão da API prompt. Para saber mais, veja Monitorizar o progresso da transferência do modelo, abaixo.
O modelo Aion-1.0-Instruct
No Microsoft Edge Canary ou Edge Dev, a partir da versão 150.0.4070, a API prompt também pode ser utilizada com o modelo de pré-lançamento Aion-1.0-Instruct, incorporado no Microsoft Edge.
Este modelo Aion-1.0-Instruct é significativamente mais pequeno, mais rápido e eficiente do que o Phi-4-mini e é suportado em dispositivos com GPUs menos capazes ou sem GPU, através da inferência da CPU.
Espera-se que o Aion-1.0-Instruct seja disponibilizado como modelo de código aberto em julho de 2026.
Ativar a instrução Aion-1.0 para a API de Pedido
Por predefinição, a API prompt utiliza o modelo Phi-4-mini. Para utilizar o Aion-1.0-Instruct no Microsoft Edge Canary ou no Edge Dev, ative o sinalizador Ativar modelo de idioma pré-lançamento no dispositivo , conforme descrito nos passos abaixo. Quando este sinalizador está ativado, Aion-1.0-Instruct substitui Phi-4-mini como o modelo predefinido da API prompt.
Certifique-se de que está a utilizar a versão mais recente do Edge Canary ou edge Dev (versão 150.0.4070 ou posterior). Consulte Tornar-se um Microsoft Edge Insider.
No Edge Canary ou Edge Dev, abra um novo separador ou janela e aceda a
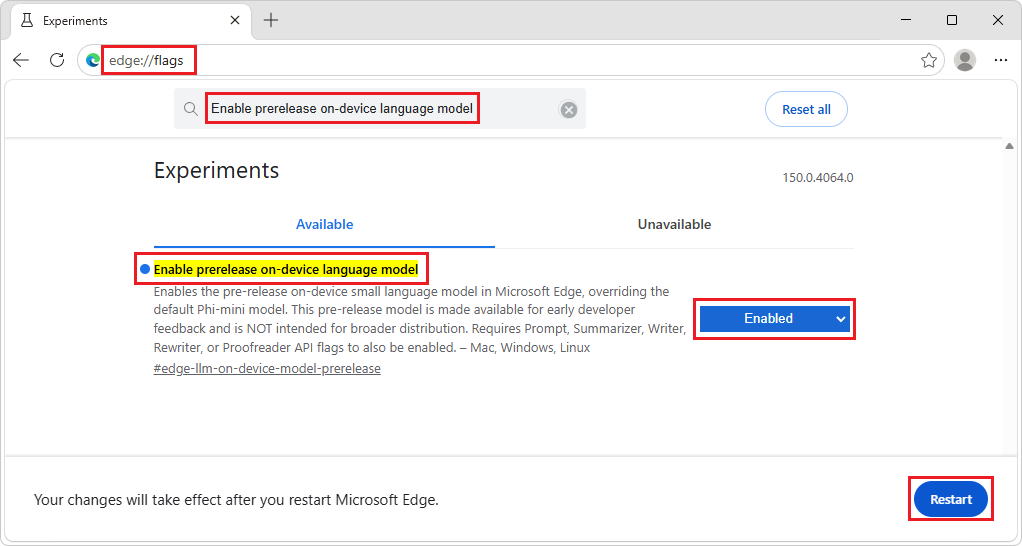
edge://flags.Na caixa de pesquisa na parte superior da página, introduza Ativar modelo de idioma no dispositivo de pré-lançamento.
Na lista pendente Ativar pré-lançamento do modelo de idioma no dispositivo , selecione Ativado e, em seguida, clique no botão Reiniciar :
Para marcar que a instrução Aion-1.0 está a ser utilizada como modelo de linguagem no dispositivo, aceda a
edge://on-device-internals, clique em Estado do Modelo e, em marcar, o Nome do Modelo está definido como Aion-1.0-Instruct.
Aviso de isenção
O modelo Aion-1.0-Instruct é disponibilizado no Microsoft Edge 150.0.4070 para testes e comentários para programadores iniciais. Além das considerações de IA Responsável listadas acima, tenha em atenção que, dado o seu estado de pré-lançamento, os comportamentos e capacidades do modelo estão sujeitos a alterações.
Disponibilidade do modelo Aion-1.0-Instruct
É necessária uma transferência inicial do modelo Aion-1.0-Instruct na primeira vez que um site chama uma API que requer um modelo no dispositivo. Pode monitorizar a transferência do modelo Aion-1.0-Instruct ao utilizar a opção monitor ao criar uma nova sessão da API Prompt. Para saber mais, veja Monitorizar o progresso da transferência do modelo, abaixo.
Ativar a API de Pedido
Para utilizar a API prompt no Microsoft Edge:
Certifique-se de que está a utilizar a versão mais recente do Microsoft Edge Canary ou Edge Dev (versão 138.0.3309.2 ou posterior). Consulte Tornar-se um Microsoft Edge Insider.
No Edge Canary ou Edge Dev, abra um novo separador ou janela e aceda a
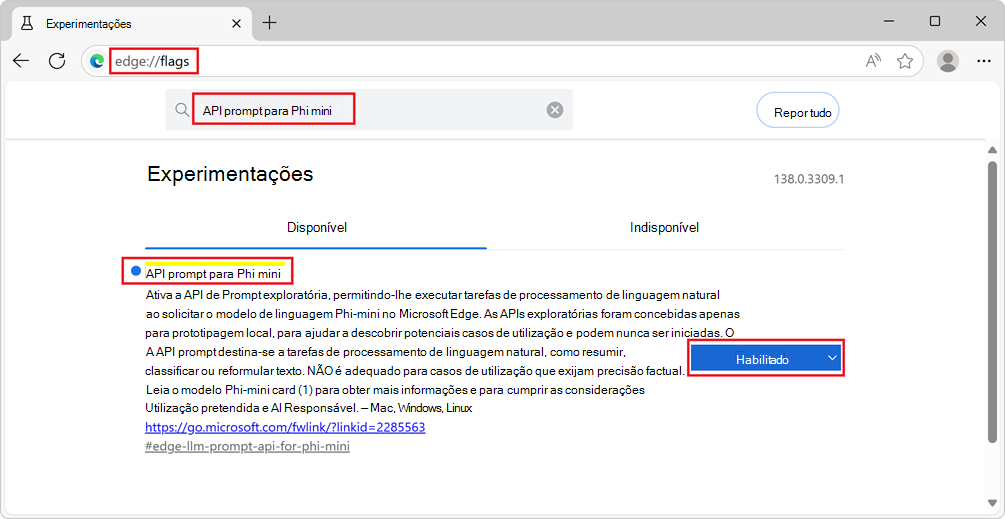
edge://flags/.Na caixa de pesquisa, na parte superior da página, introduza API de Pedido para modelo de idioma no dispositivo.
A página é filtrada para mostrar o sinalizador correspondente.
Em API de Pedido para modelo de linguagem no dispositivo, selecione Ativado:
Opcionalmente, para registar informações localmente que possam ser úteis para depurar problemas, ative também o sinalizador Ativar registos de depuração do modelo de IA no dispositivo .
Reinicie o Edge Canary ou o Edge Dev.
Para marcar se o seu dispositivo cumprir os requisitos de hardware para a pré-visualização do programador da API Prompt, abra um novo separador, aceda a
edge://on-device-internalse marcar o valor da Classe de desempenho do dispositivo.Se a classe de desempenho do dispositivo for Alta ou superior, a API prompt deve ser suportada no seu dispositivo.
Se a classe de desempenho do dispositivo for Média ou Baixa, a API prompt só é suportada através do modelo Aion-1.0-Instruct de pré-lançamento, que está disponível a partir da versão 150.0.4070 do Edge. Para testar o modelo Aion-1.0-Instruct, veja Enable Aion-1.0-Instruct for the Prompt API (Ativar Aion-1.0-Instruct) para a API prompt acima.
Se detetar problemas com estes modelos, crie um novo problema no repositório MSEdgeExplainers.
Veja um exemplo de trabalho
Para ver a API prompt em ação e rever o código existente que utiliza a API:
Ative a API prompt, conforme descrito acima.
No Edge Canary ou Edge Dev, abra um separador ou janela e aceda ao ambiente de trabalho da API Prompt.
Na navegação de ambientes de trabalho de IA incorporados à esquerda, a opção Prompt está selecionada.
Na faixa de informações na parte superior, marcar o status: inicialmente lê Transferência de modelos. Aguarde:
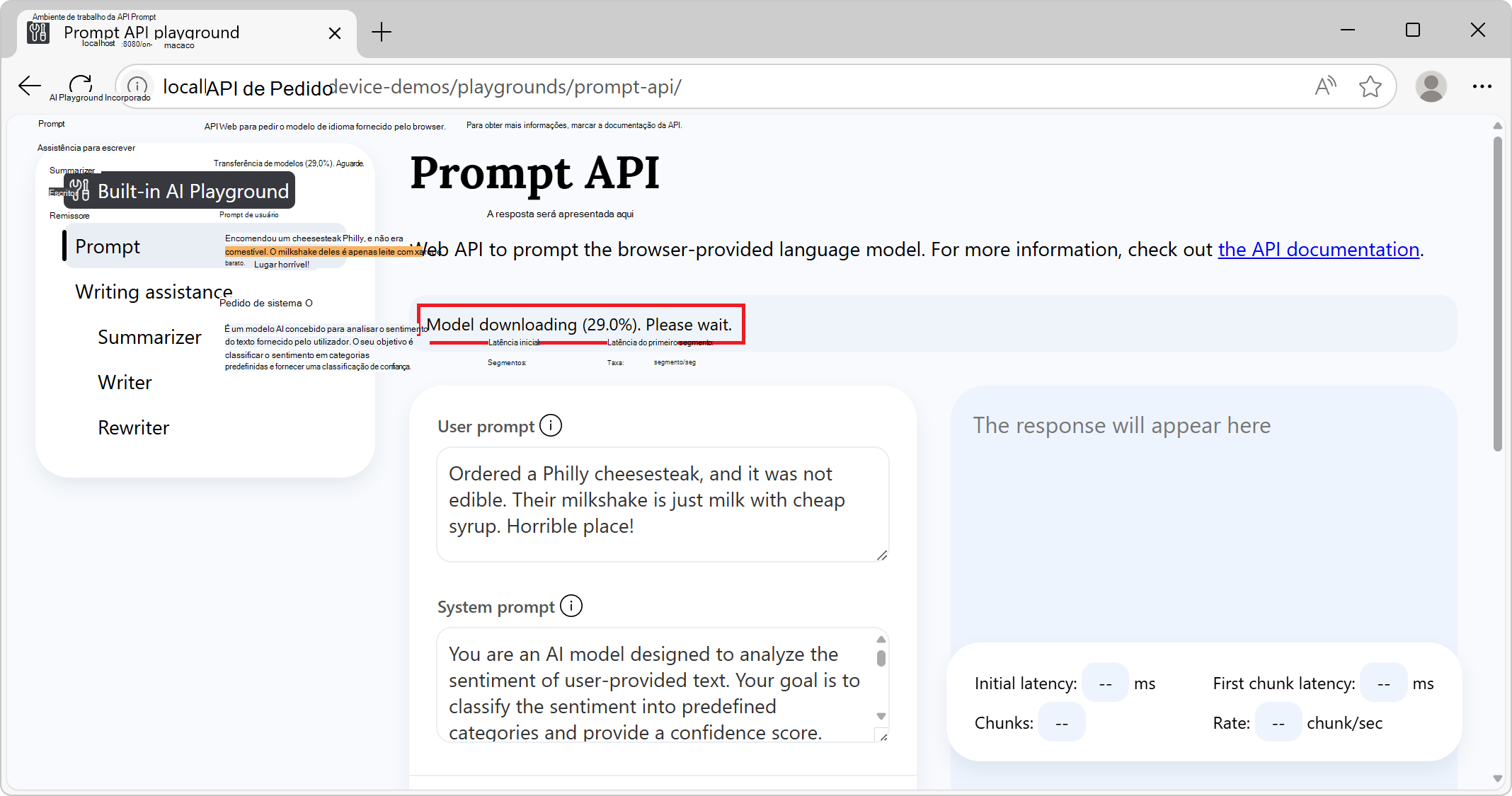
Após a transferência do modelo, a faixa de informações lê API e modelo prontos, indicando que a API e o modelo podem ser utilizados:

Se a transferência do modelo não iniciar, reinicie o Microsoft Edge e tente novamente.
A API prompt só é suportada em dispositivos que cumpram determinados requisitos de hardware. Para obter mais informações, veja Requisitos de hardware acima.
Opcionalmente, altere os valores das definições de pedido, tais como:
- Prompt de usuário
- Pedido de sistema
- Esquema de restrição de resposta
- Mais definições>Instruções da linha de comandos N-shot
Clique no botão Pedir , na parte inferior da página.
A resposta é gerada na secção de resposta da página:

Para parar de gerar a resposta, em qualquer altura, clique no botão Parar .
Veja também:
- /built-in-ai/ - Código fonte e Readme para parques de diversões de IA incorporados, incluindo o playground da API Prompt.
Utilizar a API de Pedido
Verificar se a API está ativada
Antes de utilizar a API no código do site ou da extensão, marcar que a API está ativada ao testar a presença do LanguageModel objeto:
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
Verificar se o modelo pode ser utilizado
A API prompt só pode ser utilizada se o dispositivo suportar a execução do modelo e depois de o modelo de linguagem e o runtime do modelo terem sido transferidos pelo Microsoft Edge.
Para marcar se a API puder ser utilizada, utilize o LanguageModel.availability() método :
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
Criar uma nova sessão
Criar uma sessão indica ao browser para carregar o modelo de idioma na memória, para que possa ser utilizado. Antes de poder pedir ao modelo de linguagem, crie uma nova sessão com o create() método :
// Create a LanguageModel session.
const session = await LanguageModel.create();
Para personalizar a sessão do modelo, pode transmitir opções para o create() método :
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
As opções disponíveis são:
monitor, para acompanhar o progresso da transferência do modelo.initialPrompts, para dar ao modelo contexto sobre os pedidos que serão enviados para o modelo e para estabelecer um padrão de interações de utilizador/assistente que o modelo deve seguir para futuras instruções.
Estas opções estão documentadas abaixo.
Monitorizar o progresso da transferência do modelo
Pode seguir o progresso da transferência do modelo com a opção monitor . Isto é útil quando o modelo ainda não foi totalmente transferido para o dispositivo onde será utilizado, para informar os utilizadores do seu site de que devem aguardar.
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
Fornecer ao modelo uma linha de comandos do sistema
Para definir um pedido de sistema, que é uma forma de dar ao modelo instruções a utilizar ao gerar texto em resposta a um pedido, utilize a opção initialPrompts .
O pedido de sistema que fornecer ao criar uma nova sessão é preservado para toda a existência da sessão, mesmo que a janela de contexto exceda devido a demasiados pedidos.
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
Colocar o { role: "system", content: "You are a helpful assistant." } pedido em qualquer lugar além da 0ª posição no initialPrompts irá rejeitar com um TypeError.
Pedido N-shot com initialPrompts
A initialPrompts opção também lhe permite fornecer exemplos de interações utilizador/assistente que pretende que o modelo continue a utilizar quando lhe for pedido.
Esta técnica também é conhecida como pedido N-shot e é útil para tornar as respostas geradas pelo modelo mais deterministas.
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
Clonar uma sessão para iniciar a conversação novamente com as mesmas opções
Clone uma sessão existente para pedir ao modelo sem o conhecimento das interações anteriores, mas com as mesmas opções de sessão.
A clonagem de uma sessão é útil quando pretende utilizar as opções de uma sessão anterior, mas sem influenciar o modelo com respostas anteriores.
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
]
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
Perguntar ao modelo
Para pedir ao modelo, depois de criar uma sessão de modelo, utilize os session.prompt() métodos ou session.promptStreaming() .
Aguarde pela resposta final
O prompt método devolve uma promessa que é resolvida depois de o modelo terminar de gerar texto em resposta ao pedido:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
Apresentar tokens à medida que são gerados
O promptStreaming método devolve imediatamente um objeto de fluxo. Utilize o fluxo para apresentar os tokens de resposta à medida que estão a ser gerados:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
Pode chamar os prompt métodos e promptStreaming várias vezes no mesmo objeto de sessão para continuar a gerar texto baseado em interações anteriores com o modelo nessa sessão.
Restringir a saída do modelo com um esquema JSON ou expressão regular
Para tornar o formato das respostas do modelo mais determinista e mais fácil de utilizar de forma programática, utilize a opção responseConstraint quando pedir o modelo.
A responseConstraint opção aceita um esquema JSON ou uma expressão regular:
Para fazer com que o modelo responda com um objeto JSON stringified que segue um determinado esquema, defina
responseConstraintcomo o esquema JSON que pretende utilizar.Para fazer com que o modelo responda com uma cadeia que corresponda a uma expressão regular, defina
responseConstraintpara essa expressão regular.
O exemplo seguinte mostra como fazer com que o modelo responda a um pedido com um objeto JSON que segue um determinado esquema:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
A execução do código acima devolve uma resposta que contém um objeto JSON com cadeias, como:
{"sentiment": "negative", "confidence": 0.95}
Em seguida, pode utilizar a resposta na sua lógica de código ao analisá-la com a JSON.parse() função :
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
Enviar várias mensagens por pedido
Além das cadeias, os prompt métodos e promptStreaming também aceitam uma matriz de objetos utilizados para enviar múltiplas mensagens com funções personalizadas. Os objetos que enviar devem estar no formulário { role, content }, onde role é user ou assistante content é a mensagem.
Por exemplo, para fornecer várias mensagens de utilizador e uma mensagem de assistente no mesmo pedido:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
Parar de gerar texto
Para abortar um pedido antes de a promessa devolvida por session.prompt() ter sido resolvida ou antes do fluxo devolvido por session.promptStreaming() ter terminado, utilize um AbortController sinal:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
Destruir uma sessão
Destrua a sessão para informar o browser de que já não precisa do modelo de linguagem, para que o modelo possa ser descarregado da memória.
Pode destruir uma sessão de duas formas diferentes:
- Ao utilizar o
destroy()método . - Ao utilizar um
AbortController.
Destruir uma sessão com o método destroy()
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
Destruir uma sessão com um AbortController
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
Enviar comentários
A pré-visualização do programador da API Prompt destina-se a ajudar a detetar casos de utilização para modelos de idiomas fornecidos pelo browser.
Estamos interessados em saber mais sobre:
- O intervalo de cenários para os quais pretende utilizar a API de Pedido.
- Quaisquer problemas com a API de Pedido.
- Quaisquer problemas com os modelos de linguagem.
- Se novas APIs específicas de tarefas seriam úteis.
Para enviar feedback sobre os seus cenários e as tarefas que pretende alcançar, adicione um comentário ao problema de feedback da API Prompt.
Se reparar em problemas ao utilizar a API, comunique-o no repositório.
Também pode contribuir para o debate sobre a conceção da API prompt no repositório do Grupo de Trabalho do W3C Web Machine Learning.
Confira também
- Especificação do rascunho da API Prompt
- repositório do GitHub webmachinelearning/prompt-api
- Escrever, reescrever e resumir texto com as APIs de Assistência de Escrita
- Corrigir erros de gramática, ortografia e pontuação no texto com a API do Proofreader
- Traduzir texto com a API do Microsoft Translator
- /built-in-ai/ - Código fonte e Readme para parques de diversões de IA incorporados, incluindo o playground da API Prompt.