Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Um cluster Citus consiste em uma instância de coordenador e várias instâncias de trabalho. Os dados são fragmentados nos trabalhos enquanto o coordenador armazena metadados sobre esses fragmentos. Você executa todas as consultas para o cluster por meio do coordenador. O coordenador particiona a consulta em fragmentos de consulta menores em que cada fragmento de consulta pode ser executado independentemente em um fragmento. O coordenador atribui os fragmentos de consulta aos trabalhadores, supervisiona sua execução, mescla seus resultados e retorna o resultado final ao usuário. O diagrama a seguir fornece uma breve descrição da arquitetura de processamento de consulta.
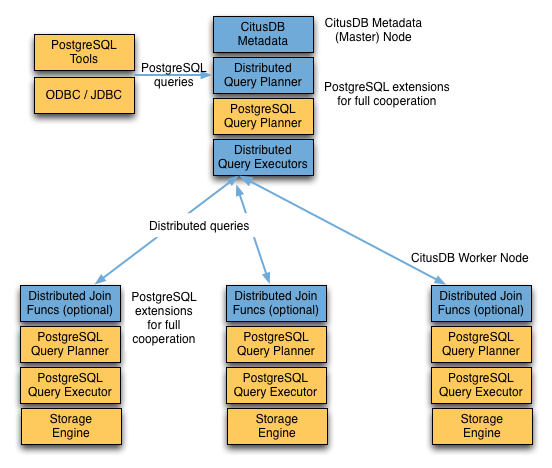
O pipeline de processamento de consulta do Citus envolve dois componentes:
- Planejador de Consultas Distribuídas e Executor
- Planejador e Executor do PostgreSQL
As seções a seguir discutem esses componentes com mais detalhes.
Planejador de consultas distribuídas
O planejador de consultas distribuídas do Citus usa uma consulta SQL e a planeja para execução distribuída.
Para SELECT consultas, o planejador primeiro cria uma árvore de plano da consulta de entrada e a transforma em sua forma commutativa e associativa para que possa ser paralelizada. Ele também aplica várias otimizações para garantir que as consultas sejam executadas de maneira escalonável e que a E/S da rede seja minimizada.
Em seguida, o planejador divide a consulta em duas partes: a consulta coordenadora, que é executada no coordenador e nos fragmentos de consulta de trabalho, que são executados em fragmentos individuais nos trabalhos. Em seguida, o planejador atribui os fragmentos de consulta aos trabalhadores de modo que todos os seus recursos sejam usados com eficiência. Após essa etapa, o plano de consulta distribuída é passado para o executor distribuído para execução.
O processo de planejamento para pesquisas chave-valor na coluna de distribuição ou consultas de modificação é ligeiramente diferente, pois elas atingem exatamente um fragmento. Quando o planejador recebe uma consulta de entrada, ele decide o fragmento correto para o qual a consulta deve ser roteada. Ele determina o fragmento certo para a consulta extraindo a coluna de distribuição na linha de entrada e procurando os metadados. Em seguida, o planejador reescreve o SQL desse comando para referenciar a tabela de fragmentos em vez da tabela original. Esse plano reescrito é passado para o executor distribuído.
Planejamento de caminho rápido atrasado (Citus 13.2)
No Citus 13.2, o planejador atrasa a criação do plano de espaço reservado de caminho rápido até identificar o fragmento. Se o posicionamento do fragmento for local para o nó que manipula a consulta do cliente (modo MX), o Citus poderá evitar deparsar, analisar e planejar etapas para a consulta de fragmentos e reutilizar um plano armazenado em cache. Essa abordagem melhora a taxa de transferência.
Elegibilidade:
- A consulta é ou
UPDATEestáSELECTem uma tabela distribuída (esquema ou fragmento de coluna) ou tabela local gerenciada pelo Citus. - Nenhuma função volátil.
- O fragmento pode ser determinado no momento do plano e é local para o nó (modo MX).
- Atualmente, não há suporte para tabelas de referência.
Comportamento:
- Se o fragmento for local e seguro, o executor substituirá o OID da tabela distribuída pelo OID de fragmento, chamadas
standard_plannere armazenará em cache o plano na tarefa. - Caso contrário, o executor retornará ao plano de espaço reservado de caminho rápido.
GUC:
-
citus.enable_local_fast_path_query_optimization(padrãoon).
Executor de consulta distribuída
O executor distribuído do Citus executa planos de consulta distribuída e lida com falhas. O executor é adequado para obter respostas rápidas para consultas que envolvem filtros, agregações e junções colocadas. Também é bom para executar consultas de locatário único com cobertura completa do SQL. O executor abre uma conexão por fragmento para os trabalhadores conforme necessário e envia todas as consultas de fragmento para eles. Em seguida, ele busca os resultados de cada consulta de fragmento, mescla-os e retorna os resultados finais ao usuário.
Subconsulta e execução de push-pull de CTE
Se necessário, o Citus pode coletar resultados de subconsultas e CTEs (expressões de tabela comuns) no nó coordenador e, em seguida, empurrá-los de volta entre os trabalhadores para uso por uma consulta externa. Essa arquitetura permite que o Citus dê suporte a uma maior variedade de constructos SQL.
Por exemplo, ter subconsultas em uma cláusula WHERE nem sempre pode executar embutido ao mesmo tempo que a consulta principal, mas deve ser feito separadamente. Suponha que um aplicativo de análise da Web mantenha uma page_views tabela particionada por page_id. Para consultar o número de hosts de visitantes nas 20 páginas mais visitadas, use uma subconsulta para localizar a lista de páginas e, em seguida, uma consulta externa para contar os hosts.
SELECT page_id, count(distinct host_ip)
FROM page_views
WHERE page_id IN (
SELECT page_id
FROM page_views
GROUP BY page_id
ORDER BY count(*) DESC
LIMIT 20
)
GROUP BY page_id;
O executor executa um fragmento dessa consulta em cada fragmento por page_id, conta s distintos host_ipe combina os resultados no coordenador. No entanto, a LIMIT subconsulta significa que a subconsulta não pode ser executada como parte do fragmento. Ao planejar recursivamente a consulta, o Citus pode executar a subconsulta separadamente, enviar os resultados para todos os trabalhos, executar a consulta de fragmento principal e efetuar pull dos resultados para o coordenador. O design push-pull dá suporte a subconsultas como a do exemplo anterior.
Você pode ver essa execução por push-pull em ação examinando a saída EXPLAIN dessa consulta.
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)
O processo está bastante envolvido, então vamos dividi-lo e examinar cada peça.
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id
A raiz da árvore é o que o nó coordenador faz com os resultados dos trabalhos. Nesse caso, ele está agrupando-os e GroupAggregate exige que eles sejam classificados primeiro.
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
A verificação personalizada tem duas subárvores grandes, começando com um subplano distribuído.
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
Os nós de trabalho executam esse subplano para cada um dos 32 fragmentos (o Citus está escolhendo um representante para exibição). Você pode reconhecer todas as partes da IN (...) subconsulta: a classificação, o agrupamento e a limitação. Quando todos os trabalhadores concluem essa consulta, eles enviam sua saída de volta para o coordenador, o que a coloca como resultados intermediários.
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
O Citus inicia outro trabalho de executor nesta segunda subárvore. Ele vai contar hosts distintos em page_views. Ele usa um JOIN para se conectar com os resultados intermediários. Os resultados intermediários ajudam a restringi-lo às 20 principais páginas.
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)
O trabalho recupera internamente os resultados intermediários usando uma read_intermediate_result função, que carrega dados de um arquivo no qual o nó coordenador copiou.
Este exemplo mostrou como o Citus executou a consulta em várias etapas com um subplano distribuído e como você pode usar EXPLAIN para saber mais sobre a execução da consulta distribuída.
Planejador e executor do PostgreSQL
Depois que o executor distribuído envia os fragmentos de consulta para os trabalhadores, os trabalhadores processam os fragmentos, como consultas PostgreSQL regulares. O planejador do PostgreSQL em cada trabalho escolhe o plano mais ideal para executar a consulta localmente na tabela de fragmentos correspondente. O executor do PostgreSQL executa a consulta e retorna os resultados da consulta para o executor distribuído. Para obter mais informações sobre o planejador e executor do PostgreSQL, consulte o manual do PostgreSQL. Por fim, o executor distribuído passa os resultados para o coordenador para agregação final.