Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Note
Use o Conector do Power Query Dataverse com fluxos de dados em vez do conector OData. Fluxos de dados são o método recomendado para migrar dados entre ambientes do Dataverse. Para obter mais informações, consulte O que são fluxos de dados?
A API Web do Dataverse funciona com qualquer tecnologia que dê suporte ao OData e ao OAuth. Você pode usar muitas opções para mover dados para dentro e para fora do Dataverse. O conector OData é um dos fluxos de dados. Ele foi projetado para dar suporte à migração e à sincronização de grandes conjuntos de dados no Dataverse.
Neste artigo, você aprenderá a migrar dados entre ambientes do Dataverse usando o conector OData de fluxos de dados.
Pré-requisitos
- Permissão de função de segurança do Administrador do Sistema ou do Personalizador de Sistema nos ambientes de origem e de destino.
- Licença do Power Apps, Power Automate ou Dataverse (por aplicativo ou por usuário).
- Dois ambientes do Dataverse com banco de dados.
Cenários
- Você precisa de uma migração única entre ambientes ou entre locatários (por exemplo, migração geográfica).
- Você precisa atualizar um aplicativo usado na produção. Você precisa de dados de teste em seu ambiente de desenvolvimento para criar facilmente as alterações.
Etapa 1: Planejar o fluxo de dados
Identifique os ambientes de origem e de destino.
- O ambiente de origem é do qual você migra os dados.
- O ambiente de destino é para o qual você migra os dados.
Verifique se o ambiente de destino já tem as tabelas definidas. O ideal é que ambos os ambientes tenham as mesmas tabelas definidas na mesma solução.
Importar relações requer vários fluxos de dados.
Tabelas com relações de um (pai/independente) para muitos (filhos/dependentes) precisam de fluxos de dados separados. Configure o fluxo de dados pai para ser executado antes de quaisquer tabelas filhas, já que os dados no pai precisam ser carregados primeiro para mapear corretamente as colunas nas tabelas filhas correspondentes. Além disso, você deve criar uma chave alternativa na tabela pai antes de definir uma coluna de pesquisa na tabela filho. Sem uma chave definida em uma tabela pai, você não pode preencher colunas de pesquisa em tabelas filho.
Etapa 2: Obter o endpoint OData para o ambiente de origem
O Dataverse fornece um ponto de extremidade do OData que não requer configuração extra para autenticação usando o conector de fluxos de dados. Você pode se conectar facilmente ao ambiente de origem.
Este artigo mostra como configurar um novo fluxo de dados usando o conector OData. Para obter informações sobre como se conectar a todas as fontes de dados compatíveis com fluxos de dados, consulte Criar e usar fluxos de dados.
Obtenha o ponto de extremidade OData para o ambiente-fonte:
Faça login no Power Apps.
Selecione o ambiente de origem necessário no canto superior direito.
Selecione o ícone Configurações (engrenagem) no canto superior direito e selecione Configurações Avançadas.
Na página Configurações , selecione a seta suspensa ao lado de Configurações e selecione Personalizações.
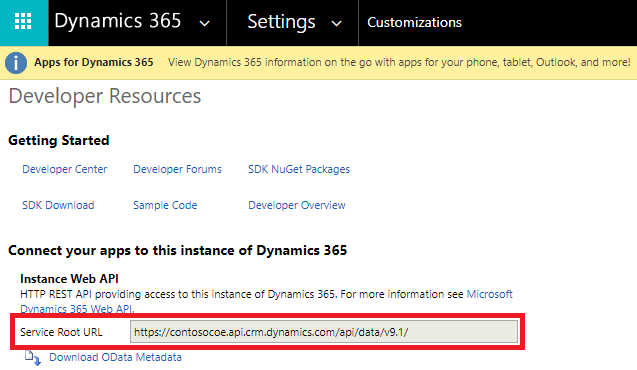
Na página Personalizações , selecione Recursos do Desenvolvedor.
Copie a URL raiz do serviço para o Bloco de Notas.
Etapa 3: Criar um novo fluxo de dados OData
No ambiente de destino , crie um novo fluxo de dados com o conector OData.
Faça login no Power Apps.
Selecione o ambiente de destino necessário no canto superior direito.
No painel de navegação esquerdo, expanda o menu Dados e selecione Fluxos de Dados.
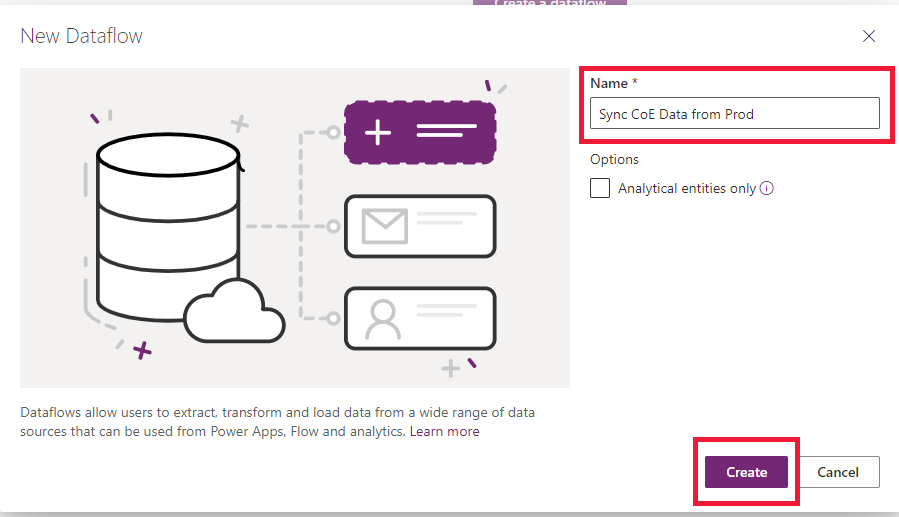
Selecione Novo fluxo de dados para criar um novo fluxo de dados. Forneça um nome significativo para o fluxo de dados. Selecione Criar.
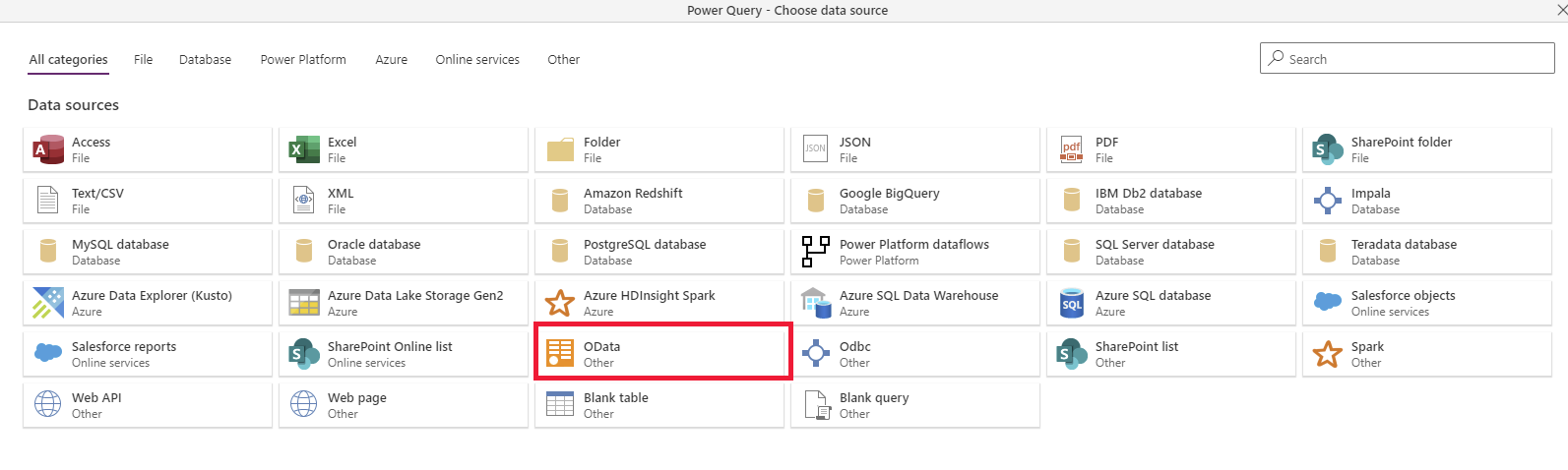
Selecione o conector OData .
Na caixa de diálogo Configurações de conexão , digite os valores da coluna:
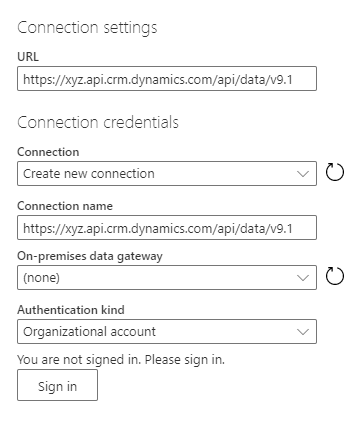
Coluna Description URL Forneça a URL raiz do serviço na coluna URL das configurações de conexão. Conexão Crie uma nova conexão. Esse valor será escolhido automaticamente se você não fez anteriormente uma conexão OData em fluxos de dados. Nome da conexão Opcionalmente, renomeie o nome da conexão, mas um valor é preenchido automaticamente. Gateway de dados local Nenhum. Um gateway de dados local não é necessário para conexões com esse serviço de nuvem. Tipo de autenticação Conta organizacional. Selecione Entrar para abrir a caixa de diálogo de entrada que autentica a conta associada à conexão. Importante
Desabilite os bloqueadores pop-up e cookie no navegador para configurar a autenticação da ID do Microsoft Entra. Esse requisito é semelhante ao fato de que você está usando o ponto de extremidade do OData do Dataverse ou qualquer outra fonte de dados de autenticação baseada em OAuth.
Selecione Avançar no canto inferior direito.
Etapa 4: Selecionar e transformar dados com o Power Query
Use o Power Query para selecionar as tabelas e transformar os dados conforme necessário.
Primeiro, selecione as tabelas que você deseja transferir. Você pode navegar por todas as tabelas no ambiente de origem e visualizar alguns dos dados em cada tabela.
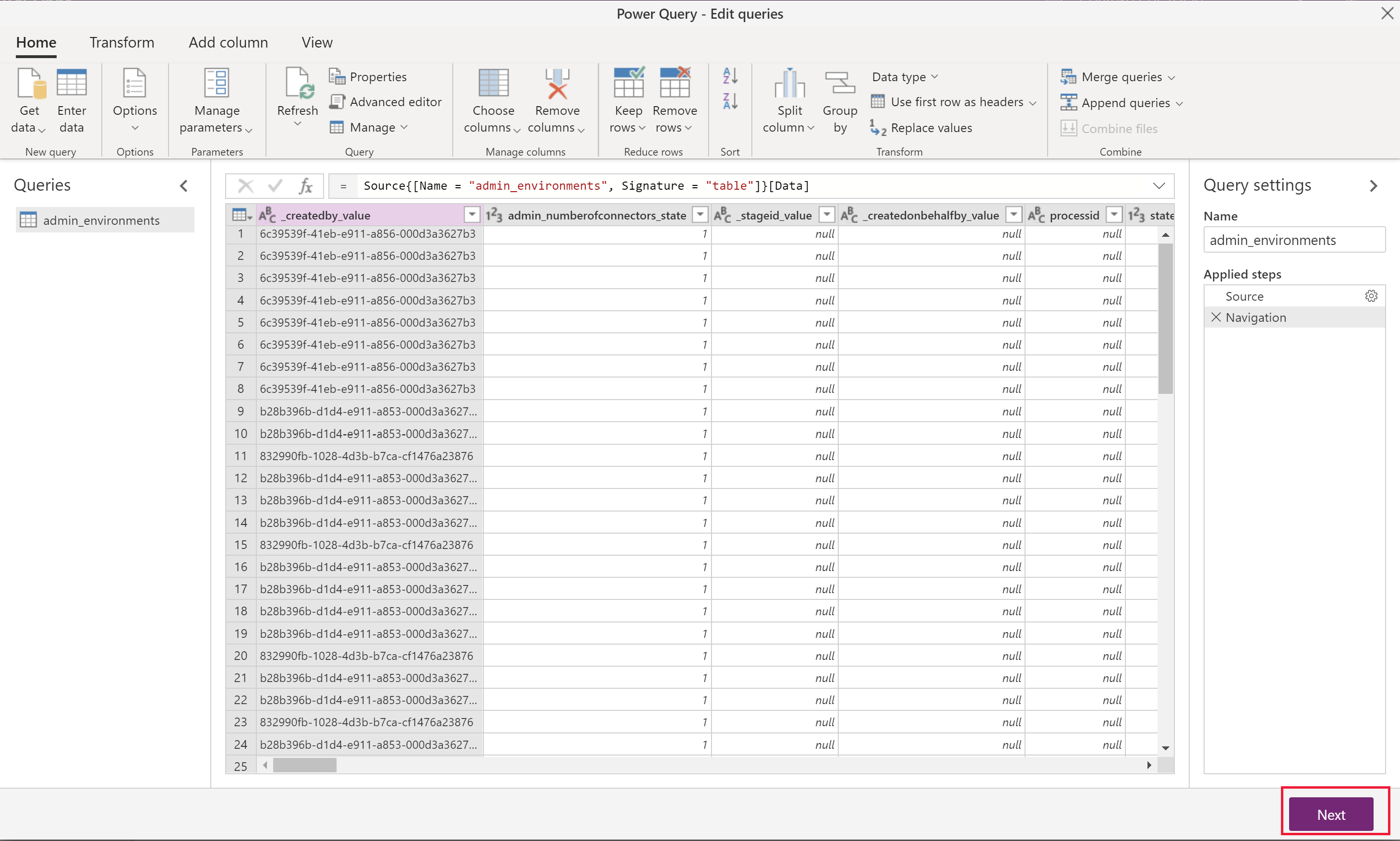
Selecione uma ou várias tabelas conforme necessário e selecione Transformar dados.
Note
Ao importar relacionamentos, lembre-se de importar o fluxo de dados da tabela pai antes dos filhos. Os dados do fluxo de dados dos filhos exigem os dados da tabela pai para o mapeamento correto, caso contrário, pode resultar em um erro.
Na janela Power Query – Editar consultas , você pode transformar a consulta antes da importação.
Se você estiver migrando apenas dados, não deverá haver a necessidade de modificar nada aqui.
Reduzir o número de colunas desnecessárias melhorará o desempenho do fluxo de dados para conjuntos de dados maiores.
Dica
Você pode voltar para escolher mais tabelas na faixa de opções Obter Dados para o mesmo conector OData.
Selecione Avançar no canto inferior direito.
Etapa 5: Definir configurações de ambiente de destino
Esta seção descreve como definir as configurações de ambiente de destino.
Etapa 5.1: Mapear tabelas
Para cada tabela escolhida, selecione o comportamento para importar essa tabela nessas configurações e selecione Avançar.
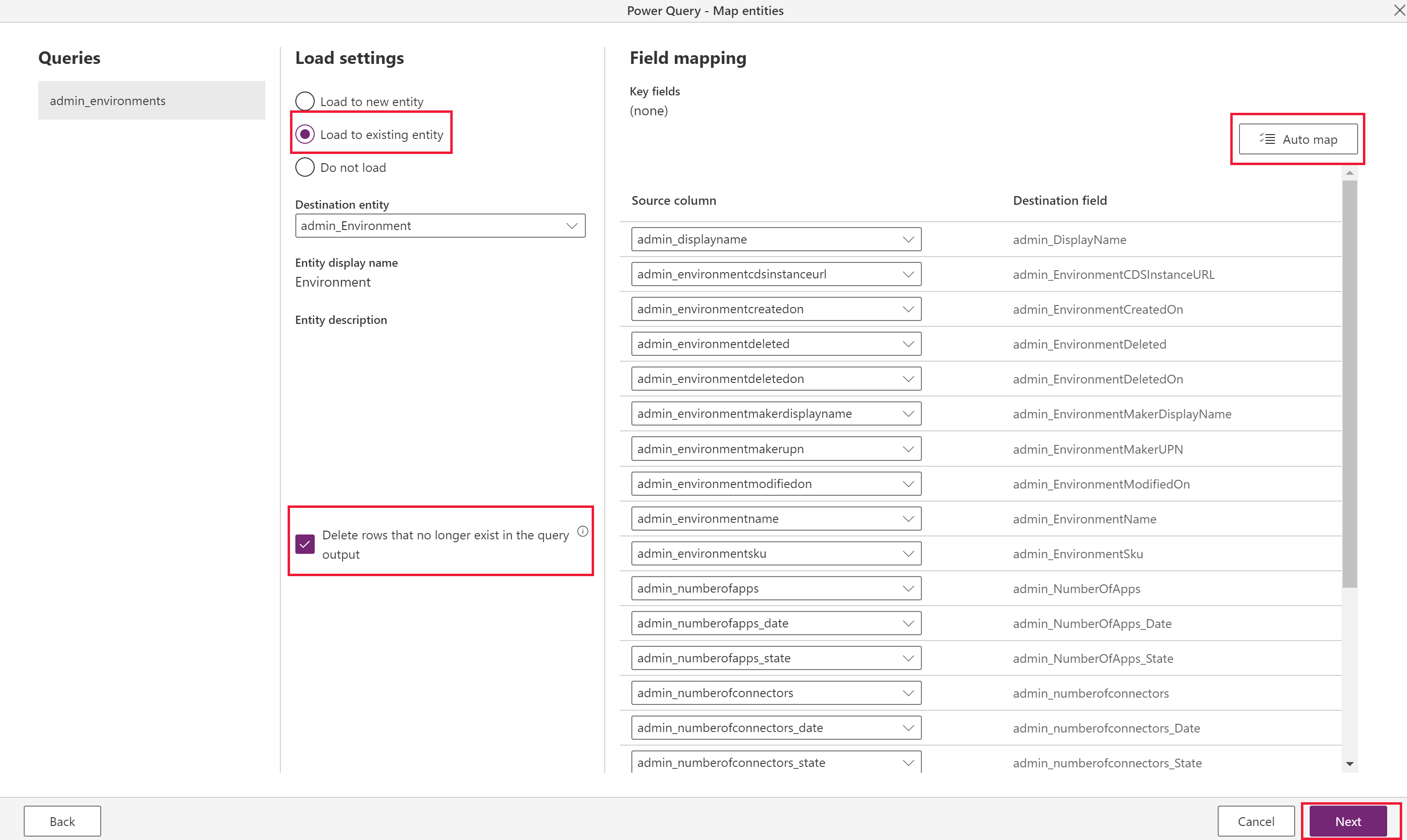
Carregar na tabela existente (recomendado)
O fluxo de dados sincroniza dados da tabela do ambiente de origem com o ambiente de destino e o mesmo esquema de tabela já está definido no ambiente de destino.
Idealmente, use a mesma solução em ambientes de destino e de origem para tornar a transferência de dados perfeita. Outra vantagem de ter uma tabela predefinida é mais controle sobre em qual solução a tabela está definida e o prefixo.
Escolha Excluir linhas que não existem mais na saída da consulta. Essa opção garante que os relacionamentos sejam mapeados corretamente porque mantém os valores das pesquisas. Para usar esse recurso, primeiro você deve definir uma definição de chaves alternativas para referenciar linhas na tabela de destino/existente para que o fluxo de dados possa determinar se os registros existentes devem ser atualizados ou criar novos.
Note
Use esta opção somente se você quiser que os dados na origem e no destino sejam os mesmos. Se outro processo no ambiente de destino adicionar dados à mesma tabela (ou se houver outros dados existentes na tabela), esse fluxo de dados os excluirá.
Se o esquema for idêntico em tabelas de origem e de destino, selecione Mapear automaticamente para mapear rapidamente as colunas.
Requer uma configuração de chave no ambiente de destino (já que as colunas de identificador exclusivo não estão disponíveis para modificação).
Importante
A opção Excluir linhas só está disponível quando uma chave é especificada. É possível ter uma tabela sem uma chave, mas uma chave é necessária quando você deseja atualizar ou excluir registros, pois é o identificador exclusivo que o sistema usa para executar essas tarefas. Você pode adicionar uma chave diretamente na tabela do Dataverse se a tabela não tiver uma chave e quiser usar a funcionalidade de exclusão ou atualização fornecida pelos fluxos de dados.
Mais informações: definir chaves alternativas usando o portal do Power Apps.
Carregar em uma nova tabela (não recomendado)
- Idealmente, você deve definir uma tabela no ambiente de destino usando a mesma importação de solução que foi utilizada no ambiente de origem. No entanto, há casos em que essa abordagem não é viável, portanto, essa opção existe se não houver nenhuma tabela existente para a qual carregar.
- Ele cria uma nova tabela personalizada na solução padrão do ambiente de destino.
Há uma opção para Não carregar, mas não inclua tabelas no fluxo de dados que não estão sendo carregadas. Você pode selecionar Voltar neste menu para retornar ao menu do Power Query e remover as tabelas que você não precisa.
Etapa 5.2: Atualizar configurações
Selecione Atualizar manualmente , pois essa migração é executada apenas uma vez e selecione Criar.
Etapa 6: Executar o fluxo de dados
Ao selecionar Criar, você inicia a carga inicial do fluxo de dados.
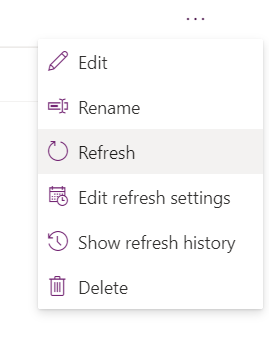
Você pode iniciar manualmente um fluxo de dados selecionando (...) na lista de fluxos de dados. Certifique-se de executar os fluxos de dados dependentes após a conclusão dos fluxos pai.
Dicas
- Experimente uma tabela primeiro para percorrer as etapas e, em seguida, compilar todos os fluxos de dados.
- Se você tiver tabelas com grandes quantidades de dados, considere configurar vários fluxos de dados separados para tabelas individuais.
- Relações um para muitos precisam de fluxos de dados separados para cada tabela. Execute o fluxo de dados da tabela pai (uma ou independente) antes da tabela filha.
- Se ocorrerem erros durante a atualização do fluxo de dados, exiba o histórico de atualizações no menu (...) na lista de fluxos de dados e baixe cada log de atualização.
Limitações
- Você não pode importar dados de relacionamento muitos para muitos.
- Você precisa configurar manualmente os fluxos de dados pai para serem executados antes dos fluxos de dados filho.
- Não é possível mapear para os campos Status e Motivo do Status. Para obter mais limitações de mapeamento de campo, consulte considerações de mapeamento de campo para fluxos > de dados padrão Limitações conhecidas.