Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
As agregações no Power BI podem melhorar o desempenho da consulta em relação a grandes modelos semânticos DirectQuery. Usando agregações, você armazena dados em cache no nível agregado na memória. Você pode configurar manualmente agregações no Power BI no modelo de dados, conforme descrito neste artigo. Para assinaturas Premium, você pode habilitar o recurso Agregações Automáticas nas Configurações do modelo para criá-las automaticamente.
Criando tabelas de agregação
Dependendo do tipo de fonte de dados, você pode criar uma tabela de agregações na fonte de dados como uma tabela ou exibição, consulta nativa. Para maior desempenho, crie uma tabela de agregações como uma tabela de importação criada no Power Query. Use a caixa de diálogo Gerenciar agregações no Power BI Desktop para definir agregações para colunas de agregação com propriedades de resumo, tabela de detalhes e coluna de detalhes.
Fontes de dados dimensional, como data warehouses e data marts, podem usar agregações baseadas em relação. Fontes de dados grandes baseadas em Hadoop geralmente baseiam agregações em colunas GroupBy. Este artigo descreve diferenças típicas de modelagem de dados do Power BI para cada tipo de fonte de dados.
Gerenciar agregações
No painel Dados de qualquer exibição do Power BI Desktop, clique com o botão direito do mouse na tabela de agregações e selecione Gerenciar agregações.
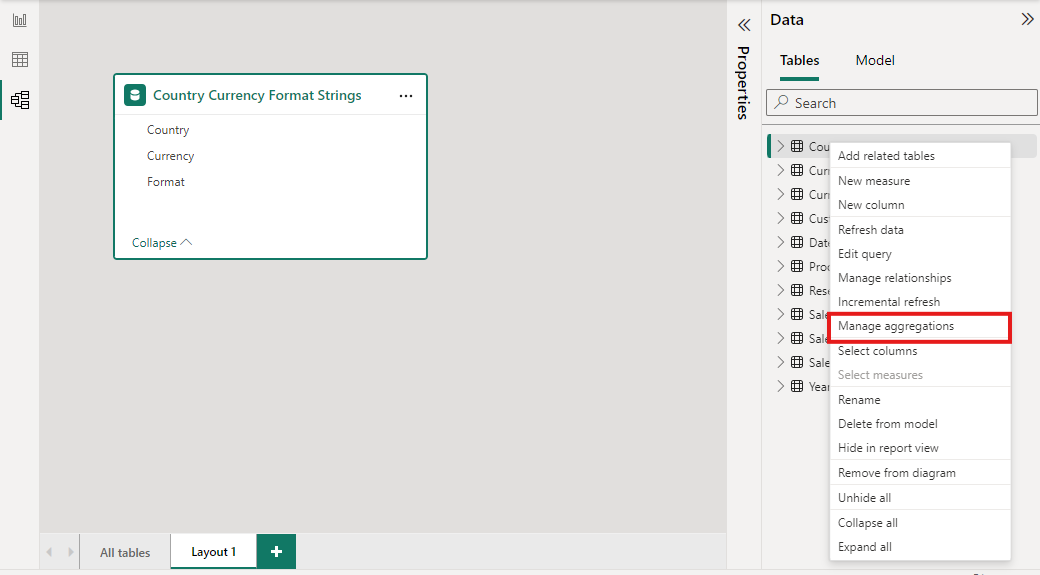
A caixa de diálogo Gerenciar agregações mostra uma linha para cada coluna na tabela, na qual você pode especificar o comportamento de agregação. No exemplo a seguir, as consultas à tabela de detalhes Vendas são redirecionadas internamente para a tabela de agregação Sales Agg .
Neste exemplo de agregação baseada em relação, as entradas GroupBy são opcionais. Com exceção de DISTINCTCOUNT, eles não afetam o comportamento de agregação e são principalmente para legibilidade. Sem as entradas de GroupBy, as agregações ainda são calculadas, baseadas nas relações. Esse comportamento é diferente do exemplo de Big Data posteriormente neste artigo, em que as entradas GroupBy são necessárias.
Validações
A caixa de diálogo Gerenciar agregações impõe validações:
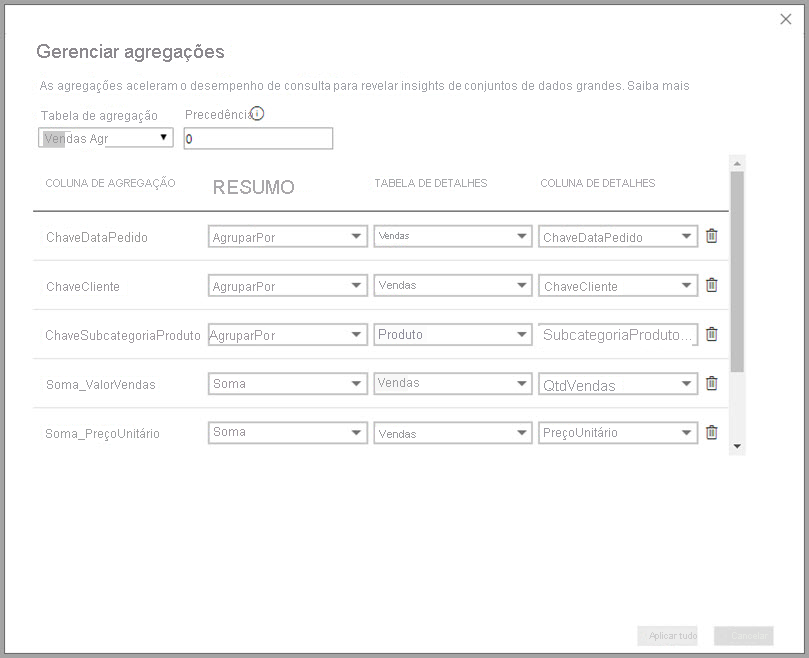
- A Coluna de Detalhes deve ter o mesmo tipo de dados que a Coluna de Agregação, exceto para funções de Resumização, como Contagem e Contagem de linhas de tabela. As linhas da tabela Count e Count só estão disponíveis para colunas de agregação de inteiros e não exigem um tipo de dados correspondente.
- Agregações encadeadas que abrangem três ou mais tabelas não são permitidas. Por exemplo, as agregações na Tabela A não podem se referir a uma Tabela B que tenha agregações referentes a uma Tabela C.
- Agregações duplicadas, em que duas entradas usam a mesma função de Resumo e se referem à mesma Tabela de Detalhes e Coluna de Detalhes, não são permitidas.
- A Tabela de Detalhes deve usar o modo de armazenamento DirectQuery, não Importar.
- Não é oferecido suporte para agrupamento por uma coluna de chave estrangeira utilizada por um relacionamento inativo, nem para depender da função USERELATIONSHIP para atingir agregações. Como alternativa, você pode usar a função TREATAS em vez de USERELATIONSHIP. Ao usar TREATAS, verifique se não há relações ativas entre as tabelas. As agregações ainda podem ser afetadas ao usar o TREATAS com essa configuração.
- As agregações baseadas em colunas GroupBy podem usar relações entre tabelas de agregação, mas não há suporte para a criação de relações entre tabelas de agregação no Power BI Desktop. Se necessário, você pode criar relações entre tabelas de agregação usando uma ferramenta de terceiros ou uma solução de script por meio de pontos de extremidade XMLA (XML for Analysis).
A maioria das validações é aplicada desabilitando valores de menu suspenso e mostrando texto explicativo no tooltip.
As tabelas de agregação estão ocultas
Os usuários com acesso somente leitura ao modelo não podem consultar tabelas de agregação. O acesso somente leitura evita preocupações de segurança quando usado com RLS (segurança em nível de linha). Consumidores e consultas referem-se à tabela de detalhes, não à tabela de agregação e não precisam saber sobre a tabela de agregação.
Por esse motivo, as tabelas de agregação ficam ocultas do modo de exibição relatório . Se a tabela ainda não estiver oculta, a caixa de diálogo Gerenciar agregações a definirá como oculta quando você selecionar Aplicar tudo.
Modos de armazenamento
O recurso de agregação funciona com modos de armazenamento no nível da tabela. As tabelas do Power BI podem usar os modos de armazenamento DirectQuery, Import ou Dual . O DirectQuery envia consultas diretamente para o back-end, enquanto a Importação armazena dados em cache na memória e envia consultas aos dados armazenados em cache. Todas as fontes de dados de importação e DirectQuery não multidimensionais do Power BI funcionam com agregações.
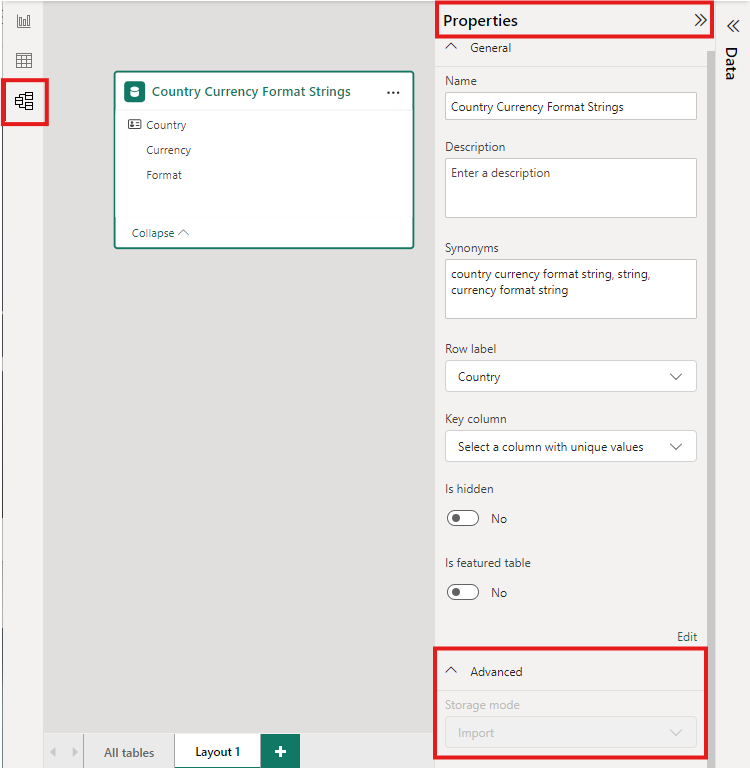
Para definir o modo de armazenamento de uma tabela agregada como Importar para acelerar as consultas, selecione a tabela agregada no modo de exibição modelo do Power BI Desktop. No painel Propriedades , expanda Avançado, solte a seleção no modo armazenamento e selecione Importar. Depois de definir o modo de armazenamento como Importar, você não poderá alterá-lo novamente.
Para obter mais informações sobre os modos de armazenamento de tabela, consulte Gerenciar o modo de armazenamento no Power BI Desktop.
RLS para agregações
Para funcionar corretamente para agregações, as expressões RLS devem filtrar a tabela de agregação e a tabela de detalhes.
No exemplo a seguir, a expressão RLS na tabela Geografia funciona para agregações, pois Geografia está no lado de filtragem das relações com a tabela Vendas e a tabela Agregação de Vendas. Consultas que usam a tabela de agregação e aquelas que não usam ambas têm RLS aplicado com êxito.
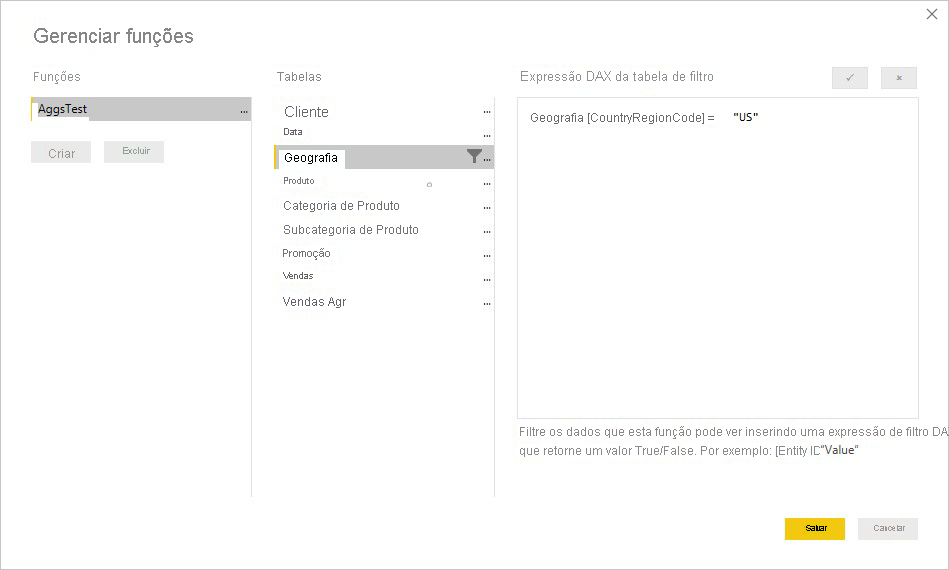
Uma expressão RLS na tabela Product filtra apenas a tabela de detalhes de Vendas, não a tabela agregada de Vendas. Como a tabela de agregação é outra representação dos dados na tabela de detalhes, não seria seguro responder a consultas da tabela de agregação se o filtro RLS não puder ser aplicado. Filtrar apenas a tabela de detalhes não é recomendável, pois as consultas de usuário dessa função não se beneficiam de ocorrências de agregação.
Uma expressão RLS que filtra apenas a tabela de agregação Sales Agg e não a tabela de detalhes Vendas não é permitida.
Para agregações baseadas em colunas GroupBy, uma expressão RLS aplicada à tabela de detalhes pode filtrar a tabela de agregação, pois todas as colunas GroupBy na tabela de agregação são cobertas pela tabela de detalhes. Por outro lado, um filtro RLS na tabela de agregação não pode filtrar a tabela de detalhes, portanto, ela não é permitida.
Agregação com base em relações
Os modelos dimensional normalmente usam agregações com base em relações. Modelos do Power BI de data warehouses e data marts se assemelham a esquemas de estrela e floco de neve, com relações entre tabelas de dimensões e tabelas de fatos.
No exemplo a seguir, o modelo obtém dados de uma única fonte de dados. As tabelas usam o modo de armazenamento DirectQuery. A tabela de fatos de Vendas contém bilhões de linhas. Ao definir o modo de armazenamento de Vendas para o modo Importação para cache, consumiria uma sobrecarga considerável de memória e recursos.
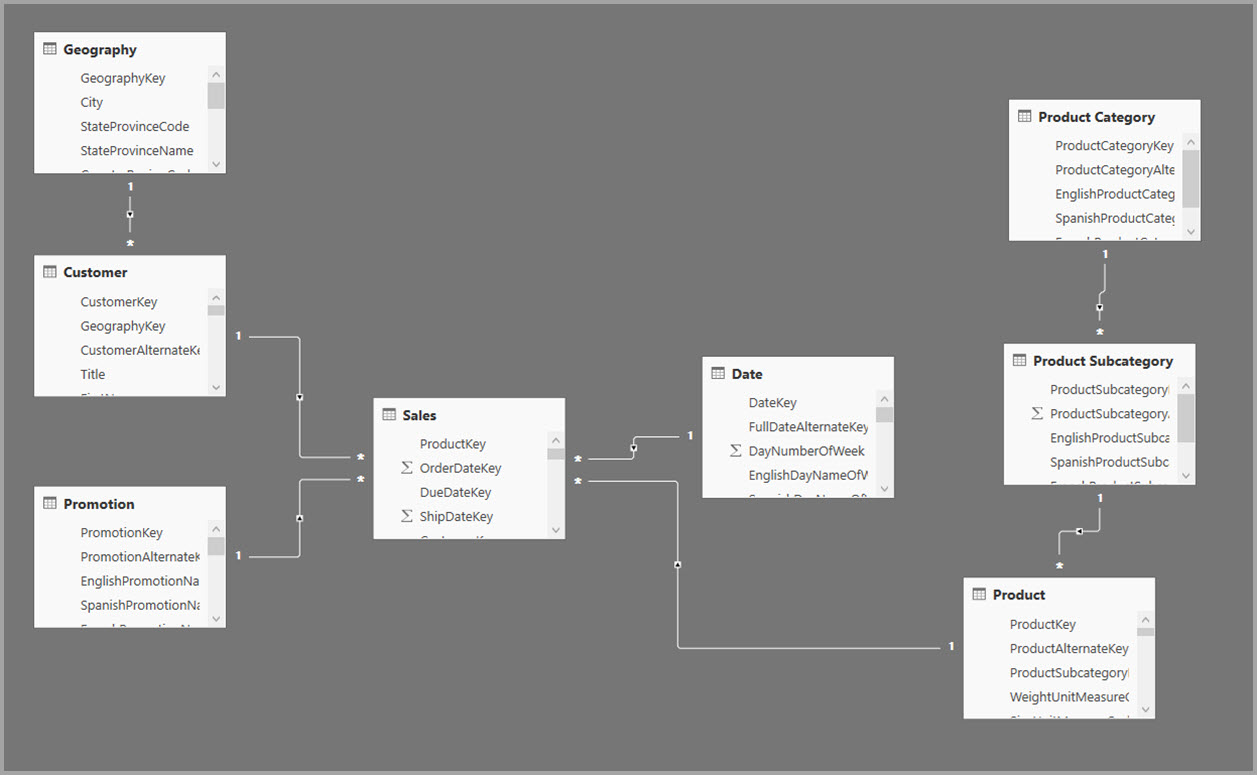
Em vez disso, crie a tabela de agregação Sales Agg . Na tabela Sales Agg , o número de linhas é igual à soma de SalesAmount agrupada por CustomerKey, DateKey e ProductSubcategoryKey. A tabela Sales Agg está em uma granularidade maior do que Sales, portanto, em vez de bilhões, ela pode conter milhões de linhas, que são mais fáceis de gerenciar.
Se as tabelas de dimensão a seguir forem usadas com mais frequência para consultas de alto valor de negócio, elas poderão filtrar Sales Agg usando relações um para muitos ou muitos para um.
- Geografia
- Cliente
- Data (calendário)
- Subcategoria do produto
- Categoria do produto
A imagem a seguir mostra esse modelo.
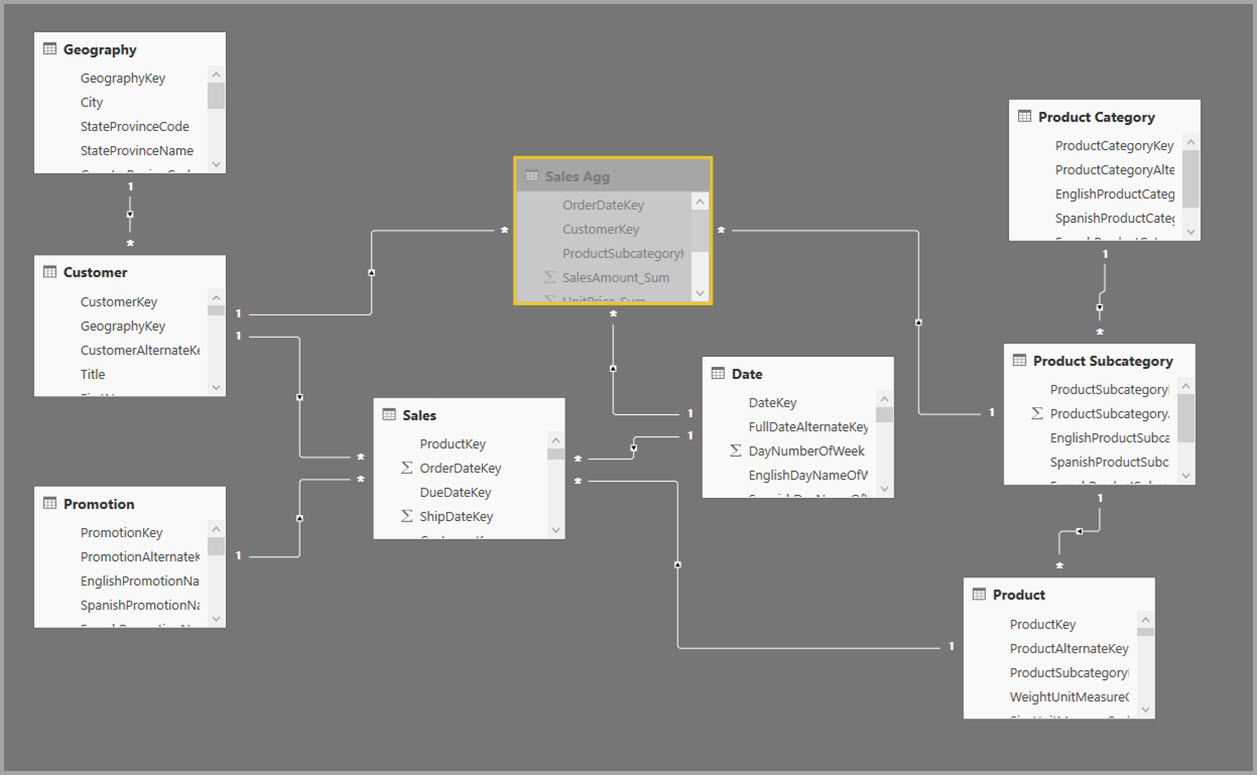
A tabela a seguir mostra as agregações da tabela Sales Agg .

Observação
A tabela Sales Agg , como qualquer tabela, tem a flexibilidade de ser carregada de várias maneiras. Você pode executar a agregação no banco de dados de origem usando processos ETL ou ELT ou usando a expressão M para a tabela. A tabela agregada pode usar o modo de armazenamento de importação, com ou sem a atualização incremental para modelos semânticos. Pode usar o DirectQuery e ser otimizado para consultas rápidas, utilizando índices columnstore. Essa flexibilidade permite arquiteturas equilibradas que podem espalhar a carga da consulta para evitar gargalos.
Alterar o modo de armazenamento da tabela Agregada Sales Agg para Importar abre uma caixa de diálogo informando que as tabelas de dimensão relacionadas podem ser definidas para o modo de armazenamento Dual.
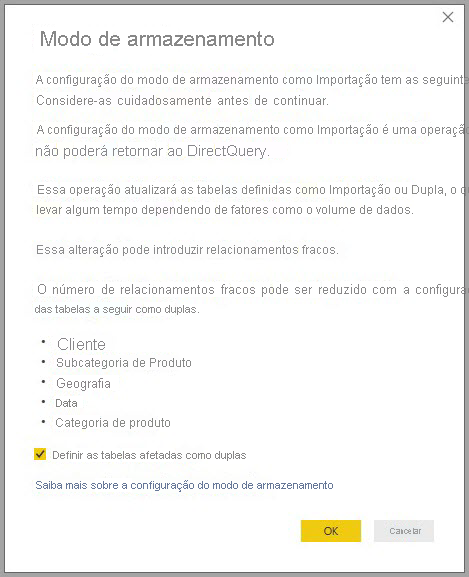
Definir as tabelas de dimensão relacionadas como Dual permite que elas atuem como Importação ou DirectQuery, dependendo da subconsulta. No exemplo:
- Consultas que agregam métricas da tabela Import-mode Sales Agg e agrupam por atributos das tabelas Dual relacionadas retornam resultados do cache na memória.
- Consultas que agregam métricas da tabela Vendas DirectQuery e agrupam por atributos das tabelas Duplas relacionadas retornam resultados no modo DirectQuery. A lógica de consulta, incluindo a operação GroupBy, é passada para o banco de dados de origem.
Para obter mais informações sobre o modo de armazenamento duplo, consulte Gerenciar o modo de armazenamento no Power BI Desktop.
Relações regulares versus limitadas
As ocorrências de agregação com base em relações exigem relações regulares.
As relações regulares incluem as seguintes combinações de modo de armazenamento, em que ambas as tabelas são de uma única origem:
| Tabela em muitos lados | Tabela no lado 1 |
|---|---|
| Duplo | Duplo |
| Importação | Importação ou Duplo |
| DirectQuery | DirectQuery ou Dual |
O único caso em que uma relação entre fontes distintas é regular é se ambas as tabelas estiverem definidas como Import. Relações muitos a muitos são sempre limitadas.
Para obter ocorrências de agregação entre fontes que não dependem de relações, consulte Agregações com base em colunas GroupBy.
Exemplos de consulta de agregação com base em relações
A consulta a seguir usa a agregação porque as colunas na tabela Data estão na granularidade que pode usar a agregação. A coluna SalesAmount usa a agregação Sum .

A consulta a seguir não usa a agregação. Apesar de solicitar a soma de SalesAmount, a consulta está executando uma operação GroupBy em uma coluna na tabela Produto, que não está numa granularidade que permita a agregação. Se você observar as relações no modelo, uma subcategoria de produto poderá ter várias linhas de Produto . A consulta não consegue determinar a qual produto agrupar. Nesse caso, a consulta é revertida para DirectQuery e envia uma consulta SQL à fonte de dados.

As agregações não são apenas para cálculos simples que executam uma soma simples. Cálculos complexos também podem se beneficiar. Conceitualmente, um cálculo complexo é dividido em subconsultas para cada SUM, MIN, MAX e COUNT. Cada subconsulta é avaliada para determinar se ela pode usar a agregação. Essa lógica não é verdadeira em todos os casos devido à otimização do plano de consulta, mas, em geral, deve ser aplicada. O exemplo a seguir usa a agregação:

A função COUNTROWS pode tirar proveito de agregações. A consulta a seguir usa a agregação porque há uma agregação de linhas de tabela Count definida para a tabela Vendas .

A função AVERAGE pode se beneficiar de agregações. A consulta a seguir usa a agregação porque AVERAGE é dobrada internamente para uma SOMA dividida por uma COUNT. Como a coluna UnitPrice tem agregações definidas para SOMA e COUNT, a agregação é usada.

Em alguns casos, a função DISTINCTCOUNT pode se beneficiar de agregações. A consulta a seguir usa a agregação porque há uma entrada GroupBy para CustomerKey, que mantém a distinção de CustomerKey na tabela de agregação. Essa técnica ainda pode atingir o limite de desempenho em que mais de 2 a 5 milhões de valores distintos podem afetar o desempenho da consulta. No entanto, pode ser útil em cenários em que há bilhões de linhas na tabela de detalhes, mas de 2 a 5 milhões de valores distintos na coluna. Nesse caso, o DISTINCTCOUNT pode executar mais rápido do que verificar a tabela com bilhões de linhas, mesmo que ela tenha sido armazenada em cache na memória.

As funções de Expressões de Análise de Dados (DAX) de inteligência de tempo são conscientes de agregações. A consulta a seguir utiliza agregação porque a função DATESYTD gera uma tabela de valores CalendarDay e a tabela de agregação está em uma granularidade que é coberta pelas colunas de agrupamento da tabela Data. Este é um exemplo de um filtro com valor de tabela para a função CALCULATE, que pode funcionar com agregações.

Agregação baseada em colunas GroupBy
Os modelos de Big Data baseados em Hadoop têm características diferentes dos modelos dimensionais. Para evitar junções entre tabelas grandes, os modelos de Big Data geralmente não usam relações, mas desnormalizam atributos de dimensão para tabelas de fatos. Você pode desbloquear esses modelos de Big Data para análise interativa usando agregações baseadas em colunas GroupBy.
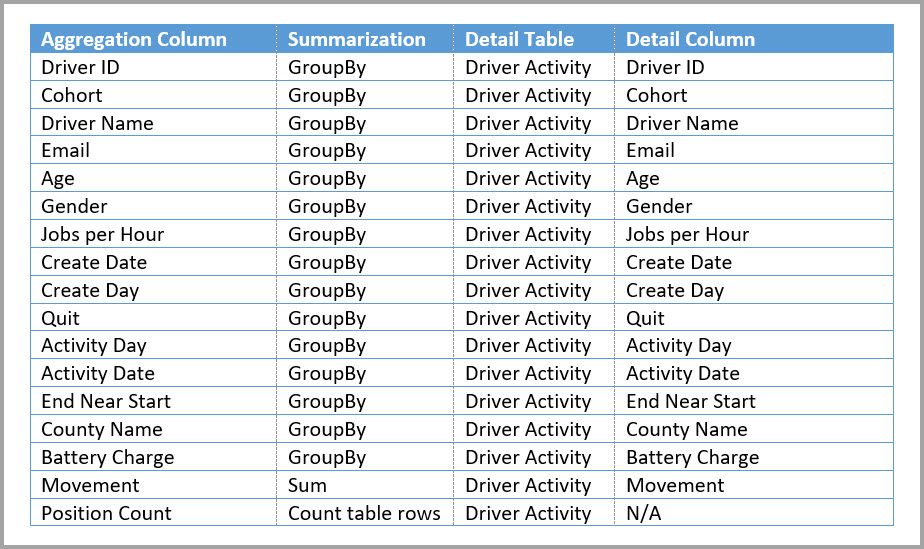
A tabela a seguir contém a coluna numérica Movimento para agregação. Todas as outras colunas são atributos para agrupar. A tabela contém dados de IoT e um grande número de linhas. O modo de armazenamento é DirectQuery. As consultas na fonte de dados que se agregam em todo o modelo são lentas devido ao grande volume.
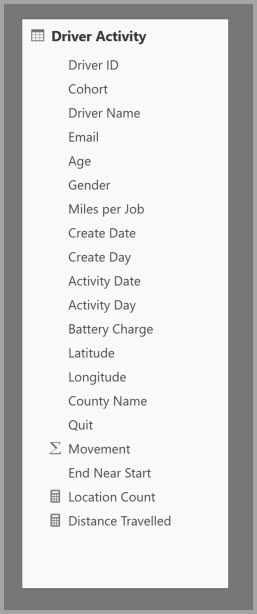
Para habilitar a análise interativa nesse modelo, adicione uma tabela de agregação que agrupa pela maioria dos atributos, mas exclui os atributos de alta cardinalidade, como longitude e latitude. Essa abordagem reduz drasticamente o número de linhas e é pequena o suficiente para caber confortavelmente em um cache na memória.
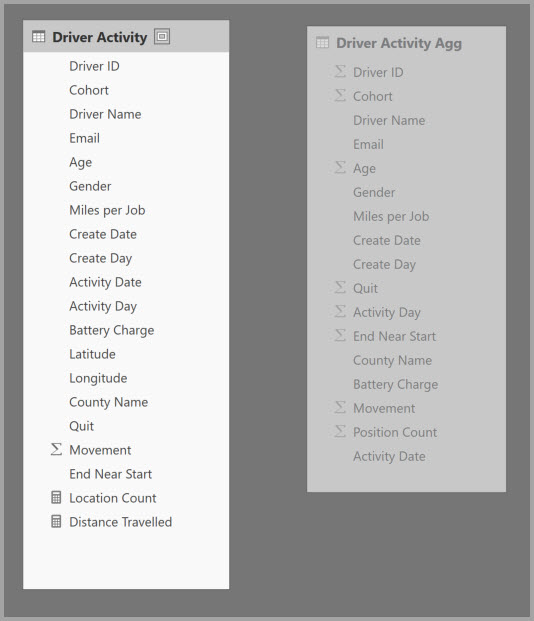
Defina os mapeamentos de agregação para a tabela Atividade do Driver Agg na caixa de diálogo Gerenciar agregações.
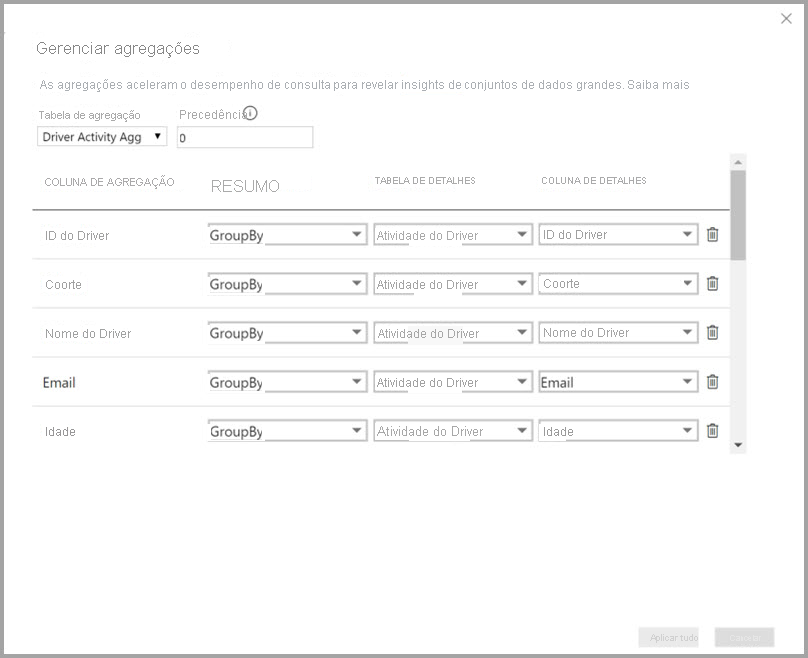
Em agregações baseadas em colunas GroupBy, as entradas GroupBy não são opcionais. Sem eles, as agregações não são atingidas. Esse comportamento é diferente do uso de agregações com base em relações, em que as entradas GroupBy são opcionais.
A tabela a seguir mostra as agregações para a tabela Agrupamento de Atividade do Motorista.
Defina o modo de armazenamento da tabela agregada Agg de Atividade do Driver como Importar.
Exemplo de consulta de agregação GroupBy
A consulta a seguir usa a agregação porque a coluna Data da Atividade é coberta pela tabela de agregação. A função COUNTROWS usa a agregação de linhas da tabela de Contagem.

Especialmente para modelos que contêm atributos de filtro em tabelas de fatos, é uma boa ideia usar agregações de Contar linhas da tabela. O Power BI pode enviar consultas para o modelo usando COUNTROWS nos casos em que ele não é solicitado explicitamente pelo usuário. Por exemplo, a caixa de diálogo de filtro mostra a contagem de linhas para cada valor.
Técnicas de agregação combinadas
Você pode combinar os relacionamentos e as técnicas de colunas do GroupBy para realizar agregações. Agregações baseadas em relações podem exigir que as tabelas de dimensão desnormalizadas sejam divididas em várias tabelas. Se esse requisito for caro ou impraticável para determinadas tabelas de dimensão, você poderá replicar os atributos necessários na tabela de agregação para essas tabelas de dimensão e usar relações para outras.
Por exemplo, o modelo a seguir replica Mês, Trimestre, Semestre e Ano na tabela Sales Agg . Não há nenhuma relação entre Sales Agg e a tabela Date, mas há relações com Cliente e Subcategoria de Produto. O modo de armazenamento do Sales Agg é Import.
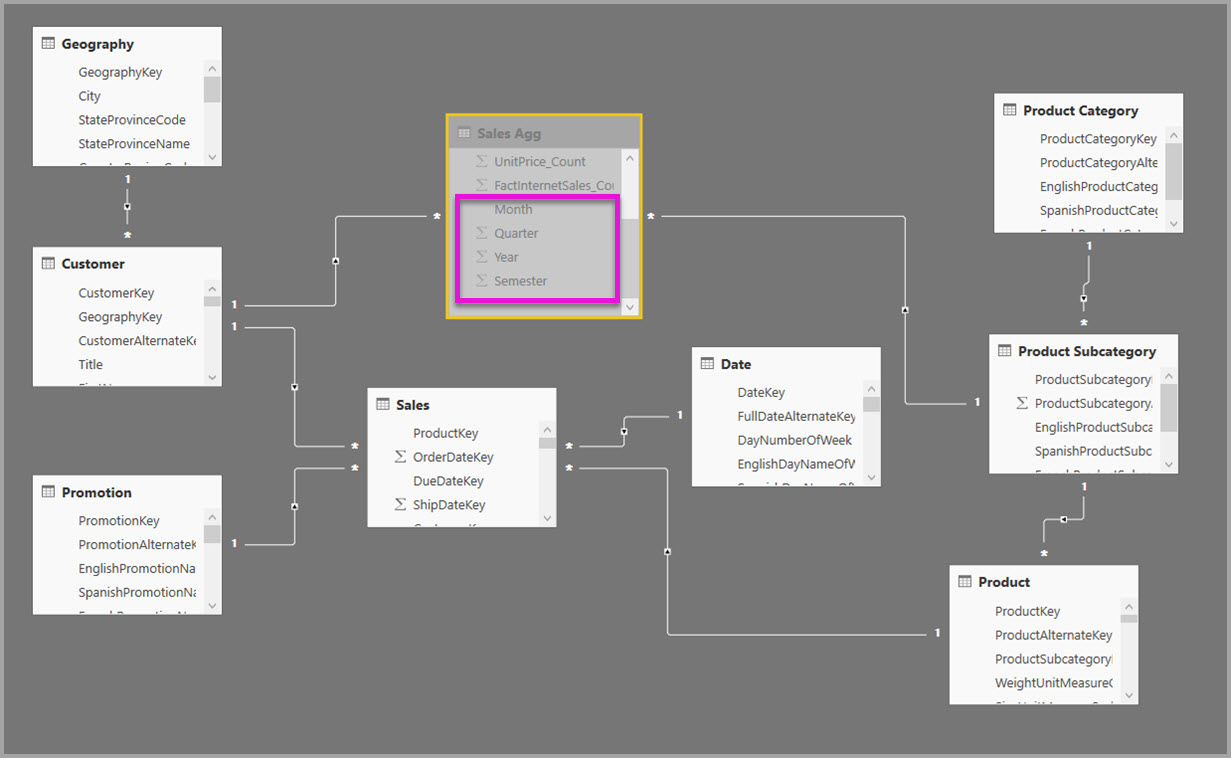
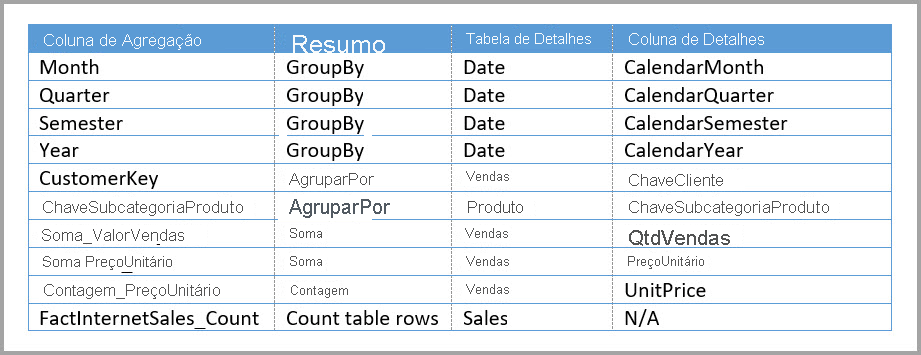
A tabela a seguir mostra as entradas definidas na caixa de diálogo de Gerenciamento de agregações para a tabela Sales Agg. As entradas GroupBy em que Data é a tabela de detalhes são obrigatórias, para usar agregações para consultas agrupadas pelos atributos Date . Como no exemplo anterior, as entradas GroupBy para CustomerKey e ProductSubcategoryKey não afetam o uso de agregação, exceto para DISTINCTCOUNT, devido à presença de relações.
Exemplos combinados de consulta de agregação
A consulta a seguir usa a agregação, pois a tabela de agregação abrange CalendarMonth e você pode acessar CategoryName por meio de relações um para muitos. A consulta usa a agregação SUM para SalesAmount.

A consulta a seguir não usa a agregação, pois a tabela de agregação não abrange CalendarDay.

A consulta de inteligência de tempo a seguir não usa a agregação, pois a função DATESYTD gera uma tabela de valores CalendarDay e a tabela de agregação não abrange CalendarDay.

Precedência de agregação
A precedência de agregação permite que uma única subconsulta considere várias tabelas de agregação.
O exemplo a seguir é um modelo composto que contém várias fontes:
- A tabela DirectQuery de Atividade de Motorista contém mais de um trilhão de linhas de dados de IoT provenientes de um sistema de grandes dados. Ele serve consultas de detalhamento para exibir leituras de IoT individuais em contextos de filtro controlados.
- A tabela Agregação de Atividade do Driver é uma tabela de agregação intermediária em modo DirectQuery. Ele contém mais de um bilhão de linhas no Azure Synapse Analytics (antigo SQL Data Warehouse) e é otimizado na origem usando índices columnstore.
- A Tabela de Importação Agg2 da Atividade de Driver possui uma alta granularidade, pois os atributos agrupados são poucos e de baixa cardinalidade. O número de linhas pode ser tão baixo quanto milhares, portanto, ele pode facilmente caber em um cache na memória. Esses atributos são usados por um painel executivo de alto perfil, portanto, as consultas que se referem a eles devem ser o mais rápidas possível.
Observação
As tabelas de agregação do DirectQuery que usam uma fonte de dados diferente da tabela de detalhes só têm suporte se a tabela de agregação for de uma fonte do SQL Server, do SQL do Azure ou do Azure Synapse Analytics (antigo SQL Data Warehouse).
O volume de memória desse modelo é relativamente pequeno, mas desbloqueia um modelo enorme. Ele representa uma arquitetura equilibrada porque espalha a carga de consulta entre componentes da arquitetura, utilizando-os com base em seus pontos fortes.
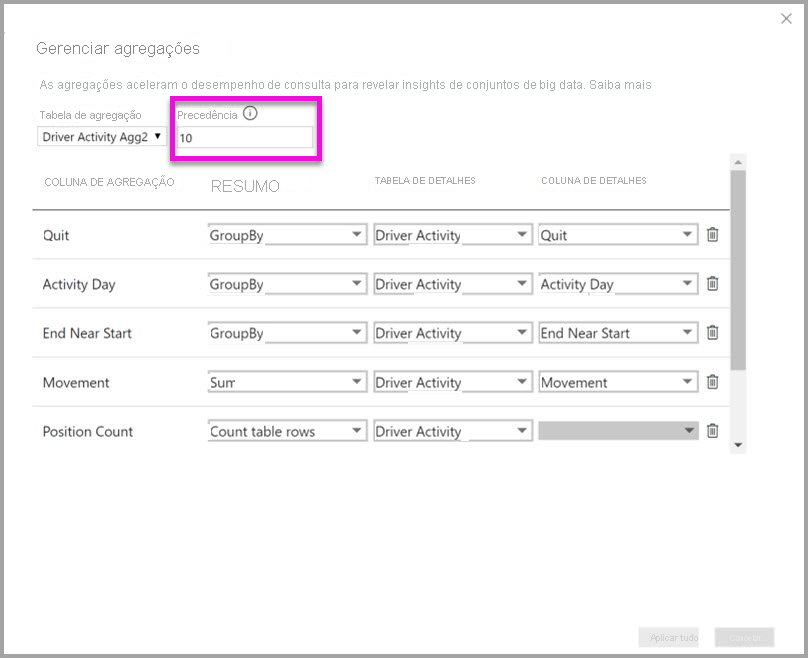
A caixa de diálogo Agregações Gerenciadas para o Agregador de Atividades do Motorista 2 define o campo Precedência como 10, que é superior à do Agregador de Atividades do Motorista. A configuração de precedência mais alta significa que as consultas que usam agregações consideram o Driver Activity Agg2 primeiro. Subconsultas que não estão na granularidade que o Driver Activity Agg2 pode responder podem considerar o Driver Activity Agg como alternativa. Consultas detalhadas que não podem ser respondidas por nenhuma das tabelas de agregação podem direcionar para a Atividade do Driver.
A tabela especificada na coluna Tabela de Detalhes é Atividade do Driver, não Agregação de Atividade do Driver, porque agregações encadeadas não são permitidas.
A tabela a seguir mostra as agregações para a tabela Atividade do Motorista Agg2.

Detectar se as consultas envolvem ou não agregações
O SQL Profiler pode detectar se as consultas vêm do mecanismo de armazenamento em cache na memória ou se o DirectQuery as envia por push para a fonte de dados. Você pode usar o mesmo processo para detectar se as agregações estão sendo usadas. Para obter mais informações, consulte Consultas que atingem ou perdem o cache.
O SQL Profiler também fornece o evento Query Processing\Aggregate Table Rewrite Query estendido.
O snippet JSON a seguir mostra um exemplo da saída do evento quando uma agregação é usada.
- matchingResult mostra que a subconsulta usa uma agregação.
- dataRequest mostra as colunas GroupBy e colunas agregadas que a subconsulta usa.
- O mapeamento mostra as colunas na tabela de agregação que são mapeadas.

Manter os caches sincronizados
As agregações que combinam os modos de armazenamento DirectQuery, Import e Dual podem retornar dados diferentes, a menos que o cache na memória permaneça em sincronia com os dados de origem. Por exemplo, a execução da consulta não tenta mascarar problemas de dados filtrando os resultados do DirectQuery para corresponder aos valores armazenados em cache. Talvez seja necessário lidar com esses problemas na origem. As otimizações de desempenho nunca devem comprometer sua capacidade de atender aos requisitos de negócios. Você precisa entender os fluxos de dados e o design adequadamente.
Considerações e limitações
As agregações não dão suporte a parâmetros de consulta M dinâmicos.
A partir de agosto de 2022, devido a alterações na funcionalidade, o Power BI ignora tabelas de agregação de modo de importação com fontes de dados habilitadas para SSO (logon único) devido a possíveis riscos à segurança. Para garantir o desempenho ideal da consulta com agregações, desabilite o SSO dessas fontes de dados.
Community
O Power BI tem uma comunidade vibrante em que MVPs, profissionais de BI e colegas compartilham experiência em grupos de discussão, vídeos, blogs e muito mais. Ao aprender sobre agregações, verifique estes recursos: