Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo destina-se a modeladores de dados de importação que trabalham com o Power BI Desktop. É um tópico de design de modelo importante que é essencial para fornecer modelos intuitivos, precisos e ideais.
Para uma discussão mais aprofundada sobre o design ideal do modelo, incluindo funções e relações de tabela, consulte Entender o esquema de estrela e sua importância para o Power BI.
Finalidade da relação
Uma relação de modelo propaga filtros aplicados na coluna de uma tabela de modelo a uma tabela de modelo diferente. Os filtros serão propagados desde que haja um caminho de relação a seguir, o que pode envolver a propagação em várias tabelas.
Os caminhos de relação são determinísticos, o que significa que os filtros são sempre propagados da mesma maneira e sem variação aleatória. No entanto, as relações podem ser desabilitadas ou ter o contexto de filtro modificado por cálculos de modelo que usam funções DAX específicas. Para obter mais informações, consulte o tópico Funções DAX Relevantes neste artigo.
Importante
As relações de modelo não impõem a integridade dos dados. Para mais informações, consulte o tópico avaliação de relacionamento mais adiante neste artigo, que explica como as relações de modelo se comportam quando há problemas de integridade nos seus dados.
Veja como as relações propagam filtros com um exemplo animado.
Neste exemplo, o modelo consiste em quatro tabelas: Categoria, Product, Yeare Sales. A tabela Categoria está relacionada à tabela Produto, e a tabela Produto está relacionada à tabela Vendas. A tabela Ano também está relacionada à tabela Vendas. Todas as relações são de um-para-muitos (cujos detalhes são descritos posteriormente neste artigo).
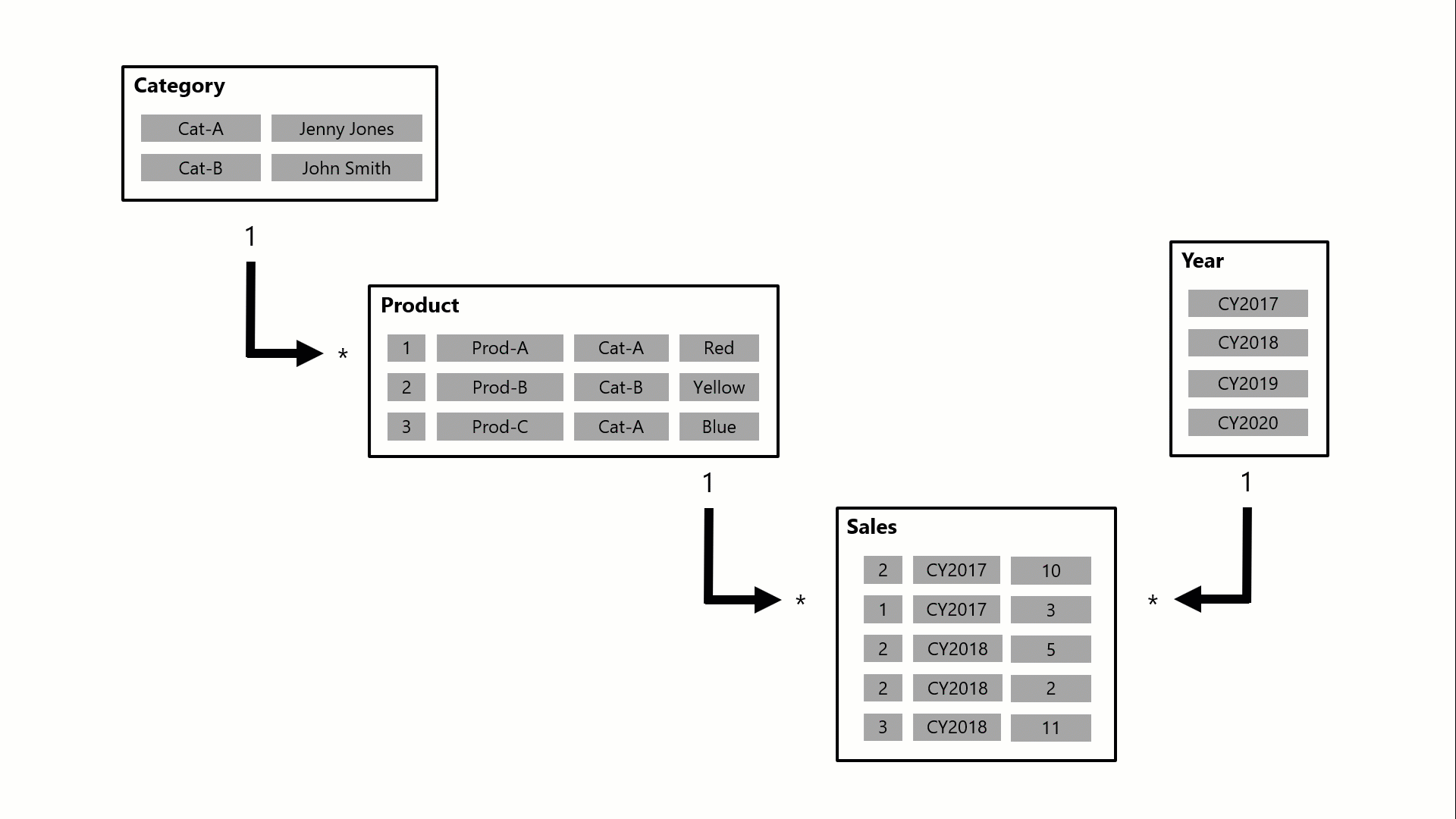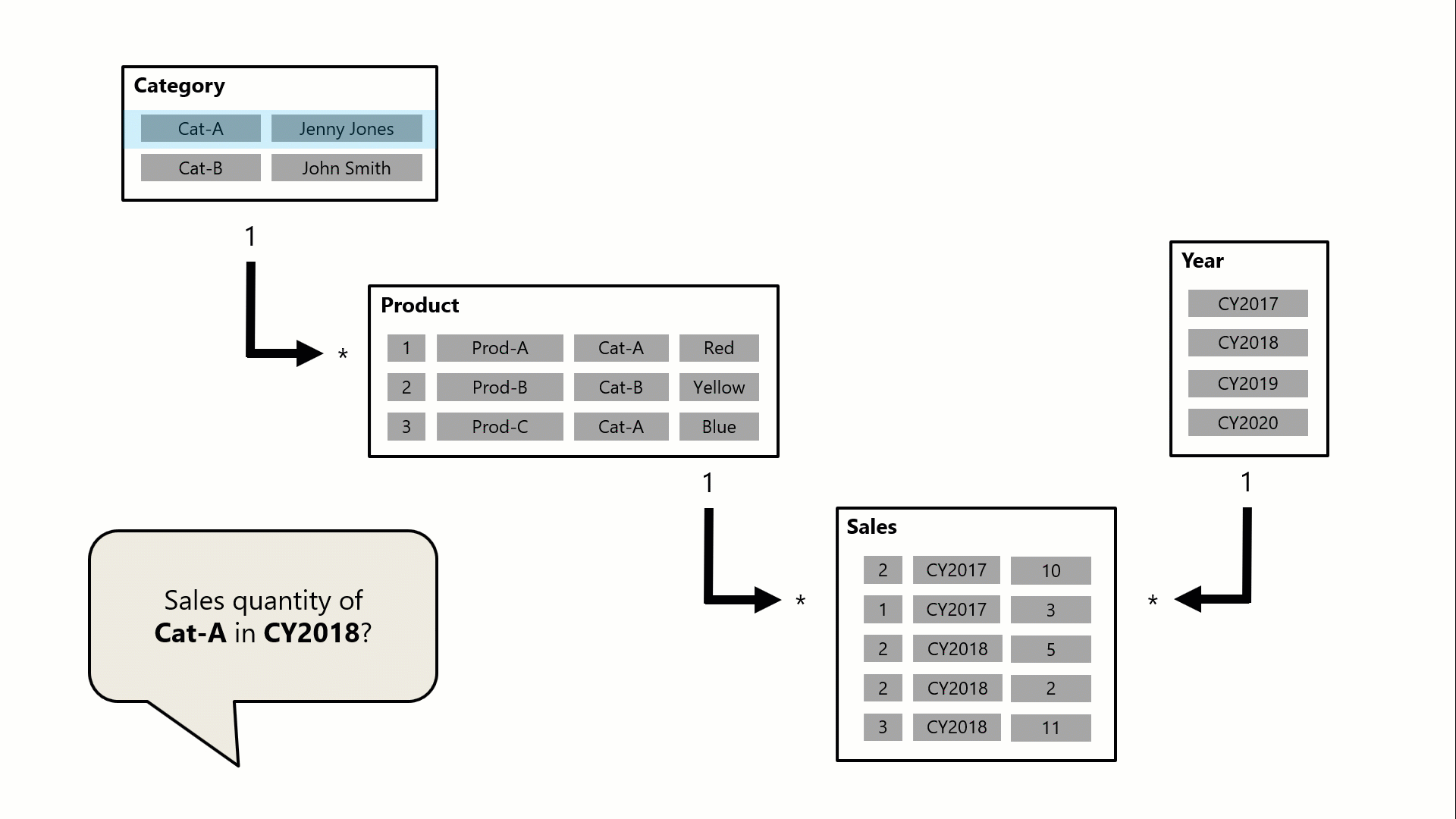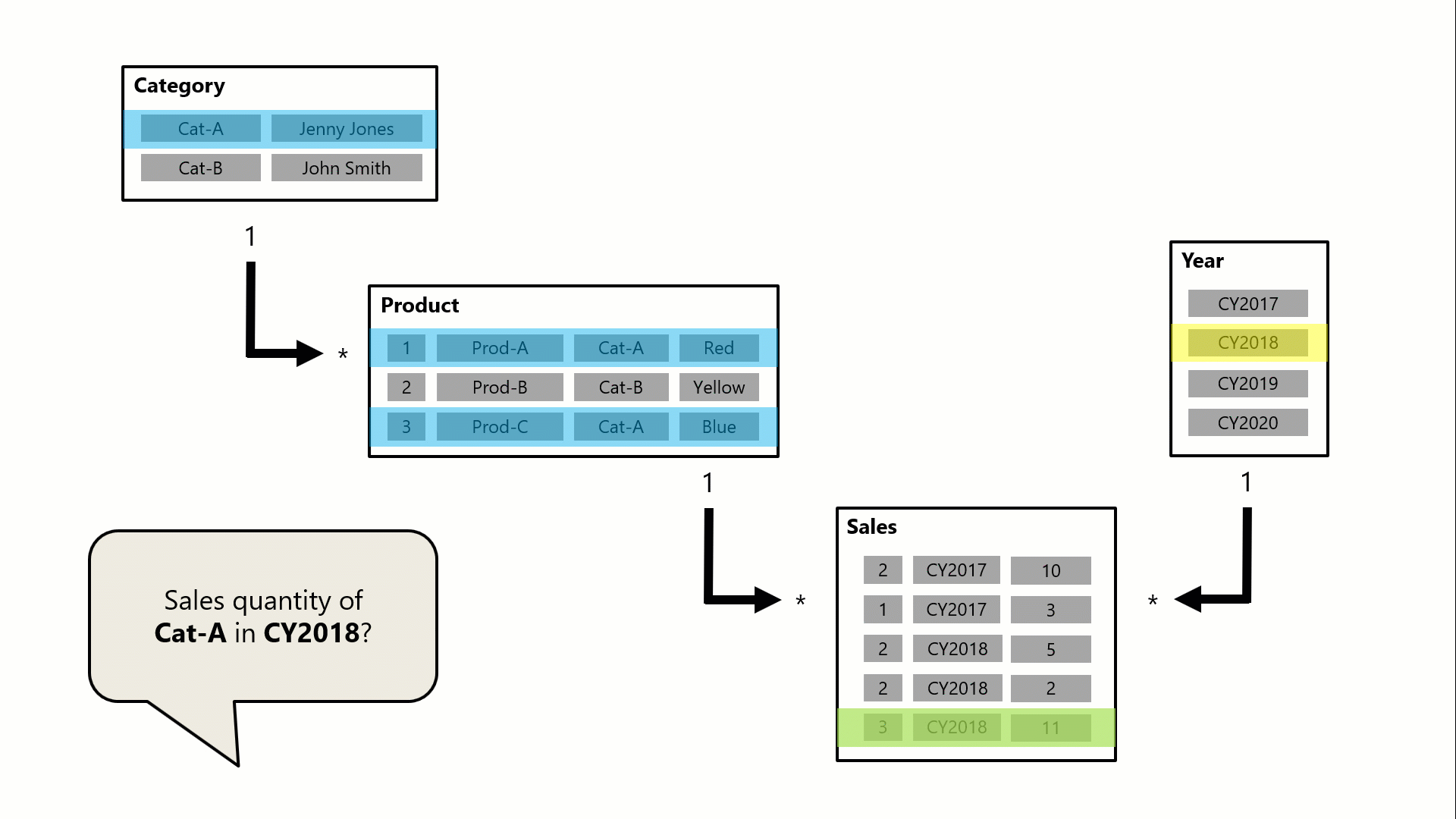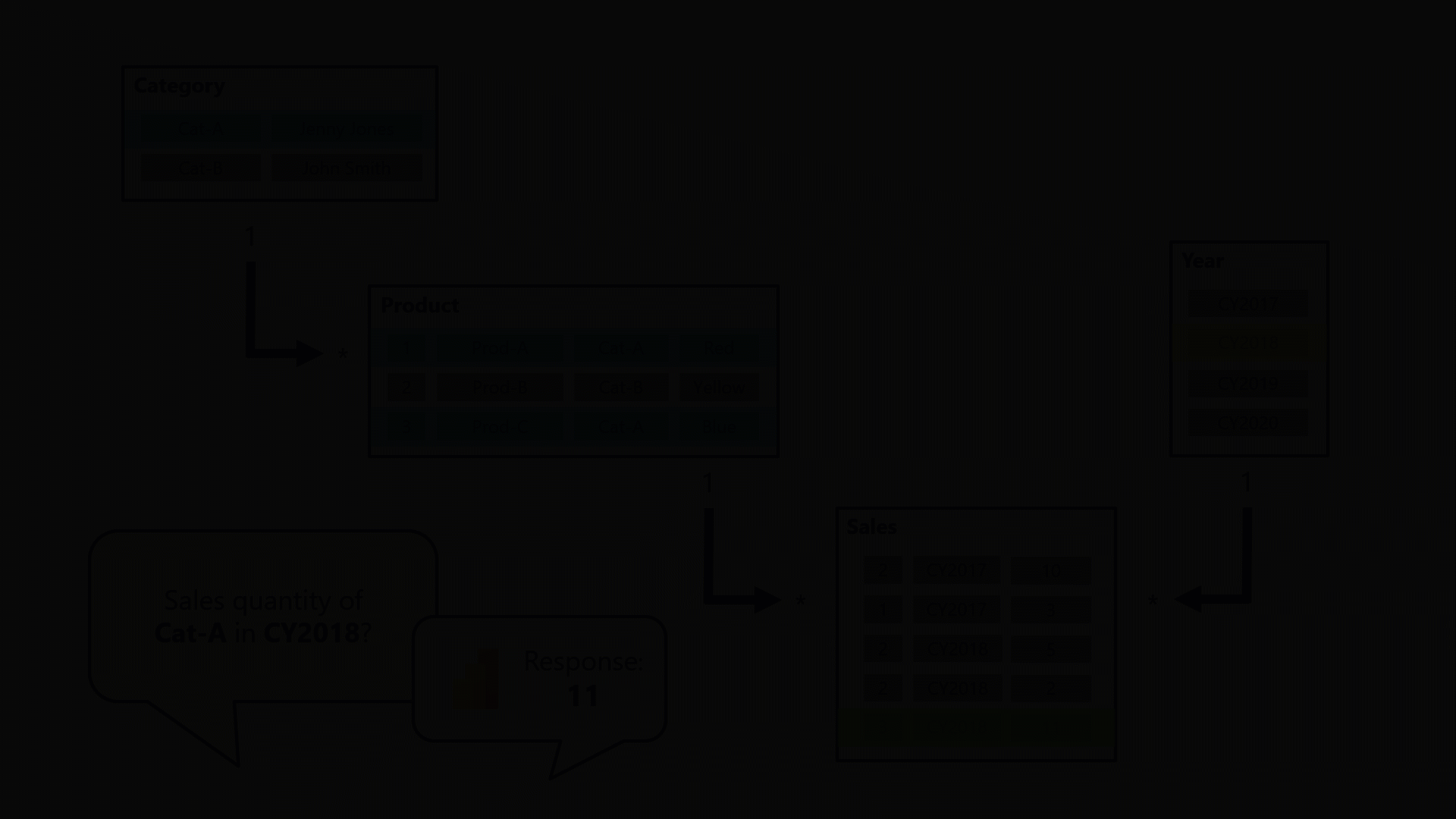
Uma consulta (possivelmente gerada por um visual de cartão do Power BI) solicita a quantidade total de vendas para pedidos de vendas feitos para uma única categoria, Cat-A e por um único ano, CY2018. É por isso que você pode ver filtros aplicados nas tabelas Categoria e Ano. O filtro na tabela Categoria é propagado para a tabela Produto para isolar dois produtos atribuídos à categoria Cat-A. Em seguida, os filtros da tabela Product são propagados para a tabela Sales para isolar apenas duas linhas de vendas para esses produtos. Essas duas linhas de vendas representam as vendas de produtos atribuídos à categoria Cat-A. A quantidade combinada é de 14 unidades. Ao mesmo tempo, o filtro da tabela Ano propaga para filtrar ainda mais a tabela Vendas, resultando em apenas uma linha de vendas para produtos atribuídos à categoria Cat-A e que foi pedido no ano CY2018. O valor da quantidade retornado pela consulta é de 11 unidades. Observe que quando vários filtros são aplicados a uma tabela (como a tabela Sales neste exemplo), é sempre uma operação AND, exigindo que todas as condições sejam verdadeiras.
Aplicar princípios de projeto de esquema de estrela
Recomendamos que você aplique os princípios de design do esquema em estrela para produzir um modelo composto por tabelas de dimensão e fatos. É comum configurar o Power BI para impor regras que filtram tabelas de dimensão, permitindo que as relações de modelo propagam esses filtros com eficiência para tabelas de fatos.
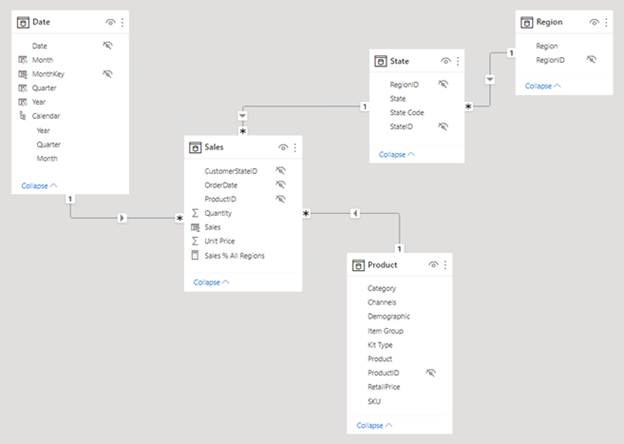
A imagem a seguir é o diagrama de modelo do modelo de dados de análise de vendas da Adventure Works. Ele mostra um design de esquema em estrela composto por uma única tabela de fatos chamada Vendas. As outras quatro tabelas são tabelas de dimensão que dão suporte à análise de medidas de vendas por data, estado, região e produto. Observe as relações de modelo que conectam todas as tabelas. Essas relações propagam filtros (direta ou indiretamente) para a tabela Vendas.
Tabelas desconectadas
É incomum que uma tabela de modelo não esteja relacionada a outra tabela de modelo. Essa tabela em um design de modelo válido é descrita como uma tabela desconectada. Uma tabela desconectada não se destina a propagar filtros para outras tabelas de modelo. Em vez disso, a abordagem aceita "entrada do usuário" (talvez com um visual de segmentação), permitindo que os cálculos do modelo utilizem o valor de entrada de uma maneira significativa. Por exemplo, considere uma tabela desconectada carregada com um intervalo de valores de taxa de câmbio. Desde que um filtro seja aplicado para um valor único de taxa, uma expressão de medida pode usar esse valor para converter os valores de vendas.
O parâmetro de hipóteses do Power BI Desktop é um recurso que cria uma tabela desconectada. Para obter mais informações, confira Criar e usar um parâmetro What If para visualizar variáveis no Power BI Desktop.
Propriedades da relação
Um relacionamento de modelo relaciona uma coluna em uma tabela a uma coluna em uma tabela diferente. (Há um caso especializado em que esse requisito não é verdadeiro e se aplica apenas a relações de várias colunas em modelos DirectQuery. Para obter mais informações, consulte o artigo de função COMBINEVALUES DAX.)
Observação
Não é possível relacionar uma coluna a uma coluna diferente na mesma tabela. Às vezes, esse conceito é confundido com a capacidade de definir uma restrição de chave estrangeira de um banco de dados relacional que faz referência à própria tabela. Você pode usar esse conceito de banco de dados relacional para armazenar relações pai-filho (por exemplo, cada registro de funcionário está relacionado a um funcionário ao qual ele "se reporta"). No entanto, você não pode usar relações de modelo para gerar uma hierarquia de modelo com base nesse tipo de relação. Para criar uma hierarquia pai-filho, confira As funções Pai e Filho.
Tipos de dados de colunas
O tipo de dado para as colunas "de" e "para" da relação deve ser o mesmo. O trabalho com relações definidas em colunas DateTime pode não ter o comportamento esperado. O mecanismo que armazena dados do Power BI usa apenas tipos de dados DateTime; os tipos de dados Data, Hora e Data/Hora/Fuzo horário são constructos de formatação do Power BI implementados na parte superior. Todos os objetos dependentes de modelo ainda aparecerão como datetime no mecanismo (como relações, grupos e assim por diante). Assim, se um usuário selecionar Data da guia Modelagem para essas colunas, elas ainda não são registradas como sendo a mesma data, porque a parte horária dos dados ainda está sendo considerada pelo mecanismo. Leia mais sobre como os tipos de data/hora são tratados. Para corrigir o comportamento, os tipos de dados da coluna devem ser atualizados no Editor do Power Query a fim de remover a parte Hora dos dados importados, para que quando o mecanismo estiver manipulando os dados, os valores apareçam iguais.
Cardinalidade
Cada relação de modelo é definida por um tipo de cardinalidade. Há quatro opções de cardinalidade, que representam as características dos dados das colunas relacionadas de origem e destino. O lado "um" significa que a coluna contém valores exclusivos; o lado "muitos" significa que a coluna pode conter valores duplicados.
Observação
Se uma operação de atualização de dados tentar carregar valores duplicados em uma coluna do lado "um", toda a atualização de dados falhará.
As quatro opções, bem como suas notações abreviadas, são descritas na seguinte lista com marcadores:
- Um para muitos (1:*)
- Muitos para um (:1)
- Um para um (1:1)
- Muitos para muitos (*:*)
Quando você cria uma relação no Power BI Desktop, o designer detecta e define automaticamente o tipo de cardinalidade. O Power BI Desktop consulta o modelo para saber quais colunas contêm valores exclusivos. Para modelos de importação, ele usa estatísticas de armazenamento internas; para modelos DirectQuery, ele envia consultas de criação de perfil para a fonte de dados. Às vezes, no entanto, o Power BI Desktop pode errar. Podem ocorrer erros quando tabelas ainda precisam ser carregadas com os dados ou porque as colunas que você espera que contenham valores duplicados atualmente contêm valores exclusivos. Em ambos os casos, você pode atualizar o tipo de cardinalidade contanto que qualquer uma das colunas no lado "um" contenha valores exclusivos (ou a tabela ainda deve ser carregada com linhas de dados).
Cardinalidade de um para muitos (e muitos para um)
As opções de cardinalidade de um para muitos e de muitos para um são essencialmente iguais e também são os tipos de cardinalidade mais comuns.
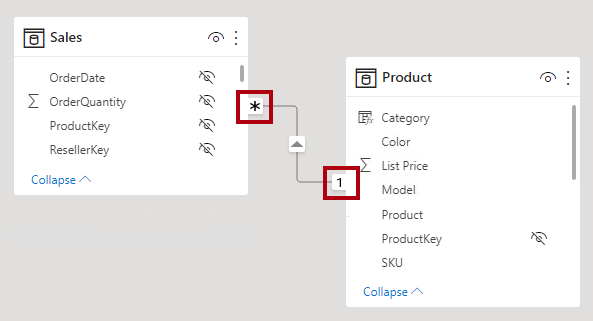
Ao configurar uma relação de um para muitos ou de muitos para um, você escolherá aquela que corresponde à ordem em que as colunas estão relacionadas. Considere como você configuraria o relacionamento da tabela Produto com a tabela Vendas usando a coluna ProductID encontrada em cada tabela. O tipo de cardinalidade seria um para muitos, pois a coluna ProductID na tabela Produto contém valores exclusivos. Se você tivesse relacionado as tabelas na direção inversa, Vendas para Produto, a cardinalidade seria muitos para um.
Cardinalidade de um para um
Uma relação de um para um significa que ambas as colunas contêm valores exclusivos. Esse tipo de cardinalidade não é comum e provavelmente representa um design de modelo de qualidade inferior devido ao armazenamento de dados redundantes.
Para obter mais informações sobre o uso desse tipo de cardinalidade, confira Diretrizes de relação um para um.
Cardinalidade de muitos para muitos
Uma relação de muitos para muitos significa que ambas as colunas podem conter valores duplicados. Esse tipo de cardinalidade é usado raramente. Normalmente, é útil ao criar requisitos de modelo complexos. Você pode usá-la para relacionar fatos de muitos para muitos ou para relacionar fatos de maior granulação. Por exemplo, quando as metas de vendas são armazenadas no nível da categoria do produto e a tabela de dimensões do produto é armazenada no nível do produto.
Para obter diretrizes sobre como usar esse tipo de cardinalidade, confira Diretrizes para relações muitos-para-muitos.
Observação
O tipo de cardinalidade “de muitos para muitos” não tem suporte para modelos desenvolvidos para o Servidor de Relatórios do Power BI de janeiro de 2024 e posteriores.
Dica
Na exibição de modelo do Power BI Desktop, você pode interpretar o tipo de cardinalidade de uma relação examinando os indicadores (1 ou *) em qualquer um dos lados da linha de relacionamento. Para determinar quais colunas estão relacionadas, você precisará selecionar ou passar o cursor sobre a linha de relação para realçar as colunas.
Direção do filtro cruzado
Cada relação de modelo é definida com uma direção de filtro cruzado. Sua configuração determina as direções em que os filtros serão propagados. As opções de filtro cruzado possíveis dependem do tipo de cardinalidade.
| Tipo de cardinalidade | Opções de filtro cruzado |
|---|---|
| Um para muitos (ou muitos para um) | Solteiro Ambos |
| Um para um | Ambos |
| Muitos para muitos | Única (Tabela1 a Tabela2) Única (Tabela2 a Tabela1) Ambos |
A direção de filtro cruzado único significa "direção única" e Ambas significa "ambas as direções". Uma relação que filtra em ambas as direções é geralmente descrita como bidirecional.
Para relaçãos de um para muitos, a direção do filtro cruzado é sempre do lado "um" e, opcionalmente, do lado "muitos" (bidirecional). Para relações de um para um, a direção do filtro cruzado vem sempre de ambas as tabelas. Por fim, para as relações de muitos para muitos, a direção do filtro cruzado pode ser de uma das tabelas ou de ambas as tabelas. Perceba que, quando o tipo de cardinalidade inclui um lado "um", os filtros sempre se propagam a partir desse lado.
Quando a direção do filtro cruzado é definida como Ambos, uma outra propriedade fica disponível. Ela pode aplicar a filtragem bidirecional quando o Power BI impõe regras de RLS (segurança em nível de linha). Para obter mais informações sobre a RLS, confira RLS (segurança em nível de linha) com o Power BI Desktop.
Você pode modificar a direção do filtro cruzado da relação, incluindo a desativação da propagação do filtro, usando um cálculo de modelo. Ele é obtido usando a função CROSSFILTER DAX.
Tenha em mente que as relações bidirecionais podem afetar negativamente o desempenho. Além disso, a tentativa de configurar um relacionamento bidirecional pode resultar em caminhos de propagação de filtro ambíguos. Nesse caso, o Power BI Desktop pode falhar ao confirmar a alteração do relacionamento e alertará você com uma mensagem de erro. Às vezes, no entanto, o Power BI Desktop pode permitir que você defina caminhos de relacionamento ambíguos entre tabelas. A resolução da ambiguidade do caminho de relação é descrita posteriormente neste artigo.
É recomendável usar a filtragem bidirecional somente conforme necessário. Para saber mais, confira Diretrizes de relações bidirecionais.
Dica
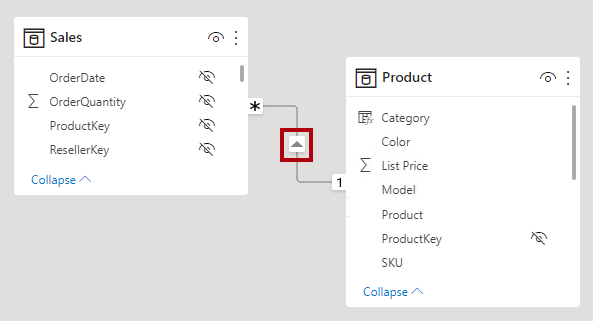
No modo de exibição de modelo do Power BI Desktop, você pode interpretar a direção de filtro cruzado de uma relação observando as pontas de seta ao longo da linha de relação. Uma única ponta de seta representa um filtro unidirecional na direção da seta; uma ponta de seta dupla representa um relacionamento bidirecional.
Tornar essa relação ativa
Só pode haver um caminho de propagação de filtro ativo entre duas tabelas de modelo. No entanto, é possível introduzir caminhos de relação adicionais, embora você precise definir essas relações como inativas. Os relacionamento inativos só podem se tornar ativos durante a avaliação de um cálculo de modelo. Isso é feito usando a função DAX USERELATIONSHIP.
Em geral, recomendamos definir relações ativas sempre que possível. Eles ampliam o escopo e o potencial de como os autores de relatório podem usar seu modelo. Usar apenas relações ativas significa que as tabelas de dimensões com função múltipla devem ser duplicadas em seu modelo.
Em circunstâncias específicas, no entanto, você pode definir uma ou mais relações inativas para uma tabela de dimensão com função múltipla. Esse design é ideal quando:
- Não há nenhum requisito para que os visuais de relatório sejam filtrados simultaneamente por funções diferentes.
- A função DAX
USERELATIONSHIPé usada para ativar uma relação específica para cálculos de modelo relevantes.
Para saber mais, confira Diretrizes de relações ativas vs inativas.
Dica
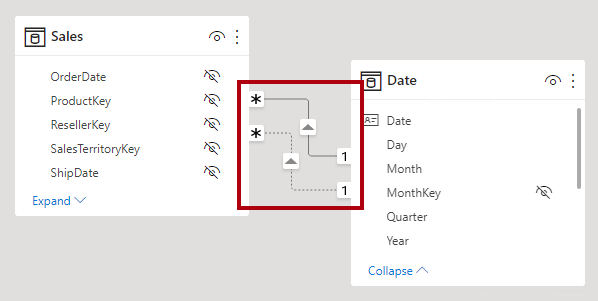
No modo de exibição de modelo do Power BI Desktop, você pode interpretar o status ativo vs. inativo do relacionamento. Um relacionamento ativo é representado por uma linha sólida; um relacionamento inativo é representado como uma linha tracejada.
Pressupor integridade referencial
A propriedade Pressuponha integridade referencial está disponível apenas para relações de um para muitos e de um para um entre duas tabelas do modo de armazenamento DirectQuery pertencentes ao mesmo grupo de origem. Você só pode habilitar essa propriedade quando a coluna do lado "muitos" não contém NULLs.
Quando habilitadas, as consultas nativas enviadas à fonte de dados unirão as duas tabelas usando um INNER JOIN em vez de um OUTER JOIN. Em geral, habilitar essa propriedade melhora o desempenho da consulta, embora dependa dos detalhes da fonte de dados.
Sempre habilite essa propriedade quando houver uma restrição de chave estrangeira de banco de dados entre as duas tabelas. Mesmo quando não existir uma restrição de chave estrangeira, considere habilitar a propriedade, desde que tenha certeza de que há integridade de dados.
Importante
Caso a integridade dos dados seja comprometida, a junção interna eliminará linhas sem correspondência entre as tabelas. Por exemplo, considere uma tabela Vendas de modelo com um valor de coluna ProductID que não existia na tabela Produto relacionada. Filtrar a propagação da tabela Produto para a tabela Vendas eliminará as linhas de vendas de produtos desconhecidos. Isso resultaria em um subestado dos resultados das vendas.
Para obter mais informações, confira Pressupor configurações de integridade referencial no Power BI Desktop.
Funções DAX relevantes
Há várias funções DAX relevantes para relacionamentos de modelo. Cada função é descrita brevemente na seguinte lista com marcadores:
- RELATED: recupera o valor do lado "um" de uma relação. Ela é útil quando envolve cálculos de tabelas diferentes que são avaliadas no contexto da linha.
- RELATEDTABLE: recupera uma tabela de linhas do lado "muitos" de uma relação.
- USERELATIONSHIP: permite que um cálculo use uma relação inativa. (Tecnicamente, essa função modifica o peso de uma relação de modelo inativa específica que ajuda a influenciar seu uso.) Ela é útil quando seu modelo inclui uma tabela Dimensão com função múltipla e você escolhe criar relações inativas com base nessa tabela. Você também pode usar essa função para resolver a ambiguidade em caminhos de filtro.
- CROSSFILTER: modifica a direção do filtro cruzado da relação (para um ou ambos) ou desabilita a propagação de filtro (nenhuma). É útil quando você precisa alterar ou ignorar relações de modelo durante a avaliação de um cálculo específico.
- COMBINEVALUES: une duas ou mais cadeias de texto em uma única cadeia de texto. A finalidade dessa função é dar suporte a relações de várias colunas em modelos DirectQuery quando as tabelas pertencem ao mesmo grupo de origem.
- TREATAS: aplica o resultado de uma expressão de tabela como filtros a colunas de uma tabela não relacionada. É útil em cenários avançados quando você deseja criar uma relação virtual durante a avaliação de um cálculo específico.
- Funções pai e filho: uma família de funções relacionadas que podem ser usadas para gerar colunas calculadas para a naturalização de uma hierarquia pai-filho. Em seguida, você pode usar essas colunas para criar uma hierarquia de nível fixo.
Avaliação de relação
As relações de modelo, de uma perspectiva de avaliação, são classificadas como regular ou limitada. Não é uma propriedade de relacionamento configurável. Na verdade, é inferido do tipo de cardinalidade e da fonte de dados das duas tabelas relacionadas. É importante entender o tipo de avaliação porque pode haver implicações ou consequências de desempenho caso a integridade dos dados seja comprometida. Essas implicações e consequências de integridade são descritas neste tópico.
Primeiro, alguma teoria de modelagem é necessária para entender totalmente as avaliações de relacionamento.
Um modelo de importação ou o DirectQuery tem todos os seus dados originados do cache Vertipaq ou do banco de dados de origem. Em ambas as instâncias, o Power BI é capaz de determinar que existe um lado de "um" de uma relação.
Um modelo composto, no entanto, pode incluir tabelas usando diferentes modos de armazenamento (importação, DirectQuery ou dual) ou várias fontes DirectQuery. Cada fonte, incluindo o cache Vertipaq de dados importados, é considerada um grupo de origem. As relações de modelo podem ser classificadas como internas a um grupo de origem ou inter/entre grupos de origem. Uma relação interna do grupo de origem relaciona duas tabelas em um grupo de origem, ao passo que uma relação inter/entre grupos de origem relaciona tabelas de diferentes grupos de origem. Observe que as relações em modelos de Importação ou DirectQuery são sempre dentro do grupo de origem.
Aqui, temos um exemplo de um modelo composto.
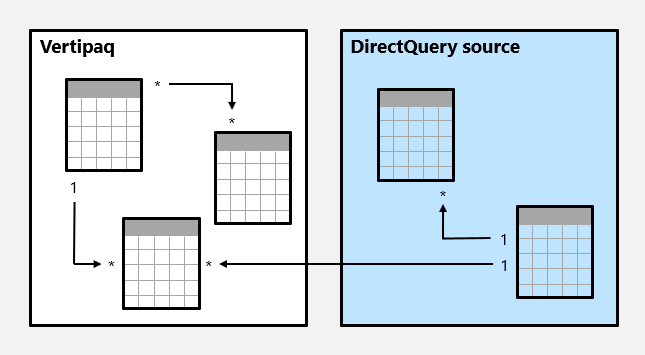
Neste exemplo, o modelo composto consiste em dois grupos de origem: um grupo de origem Vertipaq e um grupo de origem DirectQuery. O grupo de origem Vertipaq contém três tabelas e o grupo de origem DirectQuery contém duas tabelas. Existe uma relação entre grupos de origem para relacionar uma tabela no grupo de origem Vertipaq a uma tabela no grupo de origem DirectQuery.
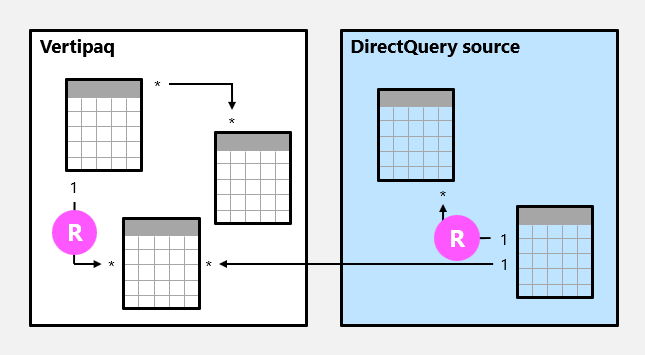
Relações regulares
Uma relação de modelo é regular quando o mecanismo de consulta pode determinar o lado "um" da relação. Ela tem uma confirmação de que a coluna do lado "um" contém valores exclusivos. Todas as relações um-para-muitos internas ao grupo de origem são regulares.
No exemplo a seguir, há duas relações regulares, ambas marcadas como R. As relações incluem a relação de um-para-muitos contida no grupo de origem Vertipaq e a relação de um-para-muitos contida no grupo de origem DirectQuery.
Para modelos de importação, em que todos os dados são armazenados no cache Vertipaq, o Power BI cria uma estrutura de dados para cada relação regular no momento da atualização de dados. As estruturas de dados consistem em mapeamentos indexados de todos os valores de coluna para coluna e sua finalidade é acelerar a junção de tabelas no momento da consulta.
No momento da consulta, as relações regulares permitem que a expansão da tabela ocorra. A expansão da tabela resulta na criação de uma tabela virtual, incluindo as colunas nativas da tabela base e, em seguida, se expandindo para tabelas relacionadas. Para tabelas de importação, a expansão da tabela é feita no mecanismo de consulta; para tabelas DirectQuery, isso é feito na consulta nativa que é enviada para o banco de dados de origem (desde que a propriedade Assume integridade referencial não esteja habilitada). O mecanismo de consulta age na tabela expandida, aplicando filtros e agrupando pelos valores nas colunas da tabela expandida.
Observação
As relações inativas também são expandidas, mesmo quando o relação não é usada por um cálculo. Relações bidirecionais não têm impacto na expansão da tabela.
Para relações de um para muitos, a expansão de tabela ocorre do lado "muitos" para o lado "um" usando a semântica LEFT OUTER JOIN. Quando um valor correspondente do lado de "muitos" para o lado de "um" não existir, uma linha virtual em branco será adicionada à tabela do lado de "um". Esse comportamento se aplica apenas a relações regulares, não a relações limitadas.
A expansão da tabela também ocorre para relações de um para um internas ao grupo de origem, mas usando a semântica FULL OUTER JOIN. Esse tipo de junção garante que linhas virtuais em branco sejam adicionadas em ambos os lados, quando necessário.
Linhas virtuais em branco são, efetivamente, membros desconhecidos. Membros desconhecidos representam violações de integridade referencial em que o valor do lado de "muitos" não tem um valor do lado de "um" correspondente. O ideal é que esses espaços em branco não existam. Eles podem ser eliminados por meio da limpeza o do repado dos dados de origem.
Veja como a expansão da tabela funciona com um exemplo animado.

Neste exemplo, o modelo consiste em três tabelas: Categoria, Produto e Vendas. A tabela Categoria está relacionada à tabela Produto com uma relação um-para-muitos, e a tabela Produto está relacionada à tabela Vendas com uma relação um-para-muitos. A tabela Categoria contém duas linhas; a tabela Produto contém três linhas; e a tabela Vendas contêm cinco linhas. Há valores correspondentes em ambos os lados de todas as relações, o que significa que não há violações de integridade referencial. Uma tabela expandida de tempo de consulta é revelada. A tabela consiste nas colunas de todas as três tabelas. É efetivamente uma perspectiva desnormalizada dos dados contidos nas três tabelas. Uma nova linha é adicionada à tabela Vendas e tem um valor de identificador de produção (9) que não tem valor correspondente na tabela Produto. É uma violação de integridade referencial. Na tabela expandida, a nova linha tem valores (em branco) para as colunas das tabelas Categoria e Produto.
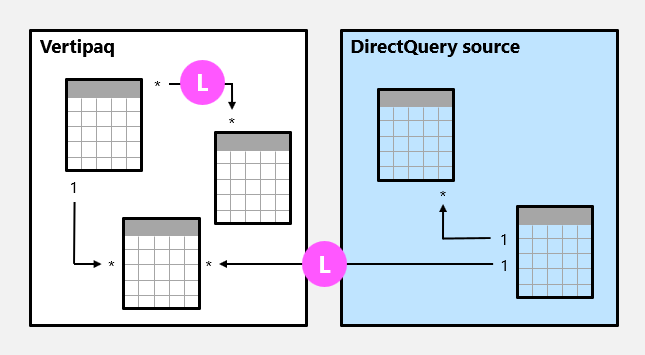
Relações limitadas
Uma relação de modelo é limitada quando não há um lado "um" garantido. Uma relação limitada pode acontecer por dois motivos:
- A relação usa um tipo de cardinalidade de muitos para muitos (mesmo que uma ou ambas as colunas contenham valores exclusivos)
- A relação é entre grupos de origem cruzados (o que só pode ser o caso para modelos compostos).
No exemplo a seguir, há duas relações limitadas, ambas marcadas como L. As duas relações incluem a relação muitos-para-muitos contida no grupo de origem Vertipaq e a relação de um para muitos entre grupos de origem.
Para modelos de importação, estruturas de dados nunca são criadas para relações limitadas. Nesse caso, o Power BI resolve junções de tabela no momento da consulta.
A expansão de tabela nunca ocorre para relações limitadas. As junções de tabela são obtidas usando a semântica INNER JOIN, e por esse motivo, linhas virtuais em branco não são adicionadas para compensar as violações de integridade referencial.
Há outras restrições relacionadas a relações limitadas:
- A função DAX
RELATEDnão pode ser usada para recuperar os valores da coluna do lado "one". - Impor RLS tem restrições de topologia
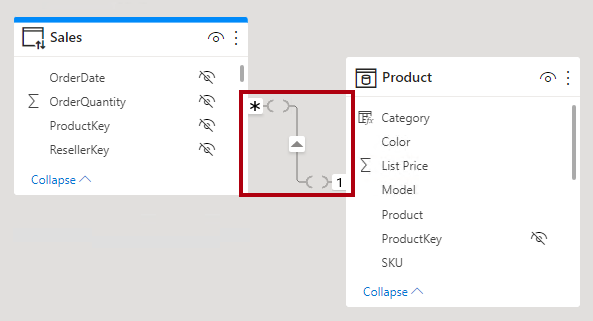
Dica
No modo de exibição de modelo do Power BI Desktop, você pode interpretar uma relação como sendo limitada. Uma relação limitada é representada com marcas semelhantes a parênteses ( ) após os indicadores de cardinalidade.
Resolver a ambiguidade do caminho de relação
As relações bidirecionais podem introduzir vários e, portanto, ambíguos caminhos de propagação de filtro entre tabelas de modelo. Ao avaliar a ambiguidade, o Power BI escolhe o caminho de propagação do filtro de acordo com a prioridade e o peso .
Prioridade
As camadas de prioridade definem uma sequência de regras que o Power BI usa para resolver a ambiguidade do caminho de relação. A primeira correspondência de regra determina o caminho que o Power BI seguirá. Cada regra abaixo descreve como os filtros fluem de uma tabela de origem para uma tabela de destino.
- Um caminho que consiste em relação um para muitos.
- Um caminho que consiste em relacionamentos um para muitos e muitos para muitos.
- Um caminho que consiste em relações muitos para um.
- Um caminho que consiste em relações de um-para-muitos da tabela de origem para uma tabela intermediária, seguido por relações de muitos-para-um da tabela intermediária para a tabela de destino.
- Um caminho que consiste em relações um para muitos ou muitos para muitos da tabela de origem para uma tabela intermediária, seguido por relações muitos para um ou muitos para muitos da tabela intermediária para a tabela de destino.
- Qualquer outro caminho.
Quando uma relação é incluída em todos os caminhos disponíveis, ela deixa de ser considerada por todos os caminhos.
Peso
Cada relação em um caminho tem um peso. Por padrão, cada peso da relação é igual, a menos que a função USERELATIONSHIP seja usada. O peso do caminho é o máximo de todos os pesos de relação ao longo do caminho. O Power BI usa os pesos de caminho para resolver a ambiguidade entre vários caminhos na mesma camada de prioridade. Ele não escolherá um caminho com uma prioridade menor, mas escolherá o caminho com o peso mais alto. O número de relações no caminho não afeta o peso.
Você pode influenciar o peso de uma relação usando a função USERELATIONSHIP. O peso é determinado pelo nível de aninhamento da chamada para essa função, em que a chamada mais interna recebe o peso mais alto.
Considere o exemplo a seguir. A medida Product Sales atribui um peso maior à relação entre Sales[ProductID] e Product[ProductID], seguido pela relação entre Inventory[ProductID] e Product[ProductID].
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Observação
Se o Power BI detectar vários caminhos que têm a mesma prioridade e o mesmo peso, ele retornará um erro de caminho ambíguo. Nesse caso, você deve resolver a ambiguidade influenciando os pesos da relação usando a função USERELATIONSHIP ou removendo ou modificando relações de modelo.
Preferência de desempenho
A lista a seguir classifica o desempenho de propagação do filtro, do desempenho mais rápido ao mais lento:
- Relações um-para-muitos internas ao grupo de origem
- Relações de modelo muitos para muitos obtidas com uma tabela intermediária e que envolvem pelo menos uma relação bidirecional
- Relações de cardinalidade de muitos para muitos
- Relações entre grupos de origem
Conteúdo relacionado
Para obter mais informações sobre este artigo, confira os seguintes recursos:
- Entenda o esquema estrela e a importância para o Power BI
- Orientação de relacionamento um-a-um
- Diretrizes da relação muitos para muitos
- Diretrizes de relações ativas vs inativas
- Diretrizes de relação bidirecional
- diretrizes de solução de problemas de relação
- Vídeo: O que Fazer e o que Não Fazer nas Relações do Power BI
- Perguntas? Tente perguntar na Comunidade do Power BI
- Sugestões? Contribua com ideias para melhorar o Power BI