Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Rastreamento distribuído é um método usado para criar perfis e monitorar aplicativos, especialmente aplicativos criados usando uma arquitetura de microsserviços. Ele permite rastrear um evento no sistema de um serviço para outro e recuperar diagnósticos de ponta a ponta sobre desempenho e latência. A recomendação de Contexto de Rastreamento do W3C define como as informações de contexto são enviadas e modificadas entre os serviços em cenários de rastreamento distribuído. Este artigo fornece aplicações práticas e casos de uso para rastreamento distribuído e explica como implementá-lo em vários serviços no Power Platform.
Identificadores de rastreamento
No Contexto de Rastreamento do W3C padrão, a cada rastreamento é atribuído um globalmente exclusivo de 16 bytes trace-id. A cada atividade no rastreamento é atribuído um exclusivo de 8 bytes span-id.
trace-id representa a transação geral e span-id representa operações individuais dentro dessa transação. Cada atividade registra a trace-id, a sua span-id e a span-id de seu pai, estabelecendo relações entre pais e filhos entre as atividades.
No W3C padrão, traceparent é um cabeçalho usado para rastrear solicitações à medida que elas se movem por diferentes serviços ou sistemas. Ele contém uma única trace-id, uma parent-id que representa o chamador imediato e trace-flags para decisões de amostragem.
Cenário de exemplo
Vamos considerar um exemplo em que um navegador inicia uma transação, vários microsserviços interagem e uma chamada é feita para a API Web do Dataverse:
| Source |
trace-id e span-id |
|---|---|
| Browser |
trace-parent: 00-11111111111111111111111111111111-2222222222222222-01 |
| Kubernetes |
trace-parent: 00-11111111111111111111111111111111-3333333333333333-01 |
| Dataverse |
trace-parent: 00-11111111111111111111111111111111-4444444444444444-01 |
O Navegador inicia a transação: o navegador envia uma solicitação a um servidor Web. A solicitação é atribuída a
trace-ide aspan-id, span-id-1.Interação de microsserviços: o servidor Web processa a solicitação e faz uma chamada para um microsserviço. A chamada recebe uma nova
span-id(span-id-2) e mantém a mesmatrace-id. O microsserviço chama outro microsserviço, criando outraspan-id(span-id-3) e assim por diante. Em cada caso,trace-idpermanece a mesmo, mas uma novaspan-idé gerada para cada operação.Chamada para API Web do Dataverse: um dos microsserviços faz uma chamada para a API Web do Dataverse. Novamente, a chamada recebe uma nova
span-id(span-id-4) e mantém a mesmatrace-id.
Trace-ID e relações pai-filho
trace-id associa todas as transações a uma relação pai-filho. Cada span-id um representa uma operação exclusiva dentro do rastreamento, e o principal span-id a vincula à operação principal. Essa estrutura hierárquica permite rastrear toda a transação, desde a solicitação inicial até a resposta final, mesmo quando ela atravessa vários serviços e sistemas.
Mapeamento trace-id e Operation Id
O Application Insights mapeia o campo W3C trace-id para Operation Id, permitindo que você consulte facilmente um conjunto de ações relacionadas que ocorrem como parte do rastreamento de ponta a ponta.

Aplicações práticas e benefícios
O padrão W3C Trace Context para rastreamento distribuído oferece várias aplicações práticas e benefícios:
Visibilidade de ponta a ponta: o contexto de rastreamento fornece visibilidade de ponta a ponta de uma transação, ajudando você a entender como as solicitações se propagam pelo sistema.
Monitoramento de desempenho: permite monitorar o desempenho de serviços individuais e identificar gargalos.
Diagnóstico de erros: ele ajuda a diagnosticar erros rastreando o caminho de uma solicitação e identificando onde as falhas ocorrem.
Acompanhamento de dependência: permite rastrear dependências entre serviços e entender como eles interagem.
Ao implementar o rastreamento distribuído com o padrão W3C Trace Context, você pode obter insights valiosos sobre o comportamento do seu aplicativo, melhorar seu desempenho e aprimorar a experiência geral do usuário.
Casos de uso potenciais
A tabela a seguir descreve possíveis casos de uso para rastreamento distribuído no Power Platform. Cada caso de uso ilustra como o rastreamento distribuído pode ser aplicado a diferentes cenários, permitindo que você monitore e diagnostique problemas de desempenho em vários serviços.
| Exemplo | Description | Notes |
|---|---|---|
| Agente autônomo | Um evento de dados dispara um agente autônomo. A possível transação de longa duração mantém o rastreamento pai. A transação pode cruzar vários processos e serviços, incluindo a possível entrega a um agente de atendimento ao cliente. | O Power Automate pode solicitar rastreamento distribuído do plug-in do Dataverse. Cada etapa do processo adiciona telemetria do Application Insights. Você pode consultar a transação de ponta a ponta no Application Insights ou usando consultas KQL. |
| Transação do usuário final na Web, móvel ou do agente | Um usuário inicia uma transação para atualizar os dados do cliente. As entradas de rastreamento são adicionadas ao Application Insights a partir da solicitação e das mensagens de rastreamento do Dataverse. | O serviço Kubernetes inicia uma transação distribuída. Ele chama a API Web do Dataverse para atualizar os detalhes do cliente. |
| Agente de suporte ao cliente | Um cliente entra em contato com a central de atendimento. Um operador de call center usa Copilot no Dynamics 365 Customer Service e um aplicativo baseado em modelo para atualizar os detalhes do cliente. Cada componente na atualização grava no Application Insights. | A transação começa com o operador do call center. O aplicativo baseado em modelo solicita uma transação distribuída do Dataverse. |
Integração da API Web do Dataverse
Vamos explorar como a API Web do Dataverse pode ser integrada ao Contexto de Rastreamento do W3C para rastreamento distribuído.
O serviço de chamada inicia um rastreamento com uma trace-id e span-id exclusiva. O valor trace-parent pode ser passado para a API Web no corpo de uma solicitação HTTP POST ou como parte de uma cadeia de caracteres de consulta HTTP, por exemplo:
-
Opção 1: Corpo do POST:
postData(environmentUrl + "api/data/v9.0/" + customApiName, token, ...) -
Opção 2: Cadeia de caracteres da consulta da marca:
postData(environmentUrl + "api/data/v9.0/" + customApiName + "?tag=01-0af...")
Usando qualquer um dos métodos, você pode configurar um plug-in do Dataverse para incorporar o rastreamento do Application Insights, gerando novas mensagens de rastreamento da span-id.
Integração do Dataverse
Agora vamos explorar como implementar esse padrão usando os recursos geralmente disponíveis do Dataverse.
Para aplicar o rastreamento distribuído a chamadas para a API Web do Dataverse:
- Usar mensagens do Dataverse para estender o pipeline de mensagens.
- Crie uma API personalizada com plug-ins do Dataverse que usam o SDK do Application Insights para adicionar as relações pai-filho necessárias.
Invocar a partir de outros serviços do Power Platform
Digamos que você queira permitir que outros serviços do Power Platform, como Copilot Studio, Power Apps ou fluxos de nuvem do Power Automate, sejam incluídos na solução geral de rastreamento distribuído. Considere invocar uma função de um aplicativo, fluxo, código ou outra função para chamar as APIs personalizadas do Dataverse, conforme discutido nesta seção.
Mensagens do Dataverse para entidades ou APIs personalizadas
Você pode definir mensagens personalizadas do Dataverse que permitem interagir com entidades ou APIs personalizadas no ambiente do Dataverse. As mensagens do Dataverse permitem que você simplifique seus processos de gerenciamento de dados e garanta uma integração perfeita com suas necessidades de observabilidade. Saiba mais em Criar suas próprias mensagens.
Adicionar etapas a um plug-in
Depois de criar um tipo de mensagem do Dataverse ou usar um tipo de entidade predefinido em um ambiente, use um plug-in para configurar a execução em diferentes estágios do pipeline de processamento de dados e permitir o rastreamento distribuído. Saiba mais em Usar plug-ins para estender os processos empresariais
Os estágios do pipeline podem incluir etapas de pré-validação, pré-operação e pós-operação. Ao adicionar etapas a um plug-in, você controla o fluxo de dados e garante que as ações sejam executadas no momento certo.
Pré-validação: ocorre antes da operação principal ser executada. Ele valida os dados e garante que eles atendam aos critérios exigidos.
Pré-operação: ocorre após a etapa de pré-validação, mas antes da operação principal ser executada. Ele executa quaisquer preparações ou modificações necessárias nos dados.
Pós-operação: ocorre após a operação principal ser executada. Ele executa qualquer limpeza necessária ou outras ações com base nos resultados da operação principal.
Você pode configurar os plug-ins para executar essas etapas de forma síncrona ou assíncrona, dependendo dos requisitos do seu aplicativo.
Valores de configuração não seguros e seguros
Você pode usar os campos Configuração Não Segura e Configuração Segura na ferramenta Registro de Plug-in para controlar aspectos do comportamento do plug-in.
Configuração Não Segura: as configurações não seguras ficam visíveis para todos os usuários e podem incluir configurações como nível de log, habilitar/desabilitar rastreamento e outras informações não confidenciais.
Configuração Segura: as configurações seguras só são visíveis para usuários com as permissões apropriadas e podem incluir informações confidenciais, como cadeias de conexão, chaves de API e outros dados confidenciais.
Para cenários de rastreamento distribuído, use o campo Configuração Não Segura para gerenciar se o rastreamento está ativado e definir o nível de log. Use o campo Configuração Segura para armazenar informações da cadeia de conexão exigidas pelo plug-in.

Saiba mais em Registrar um plug-in.
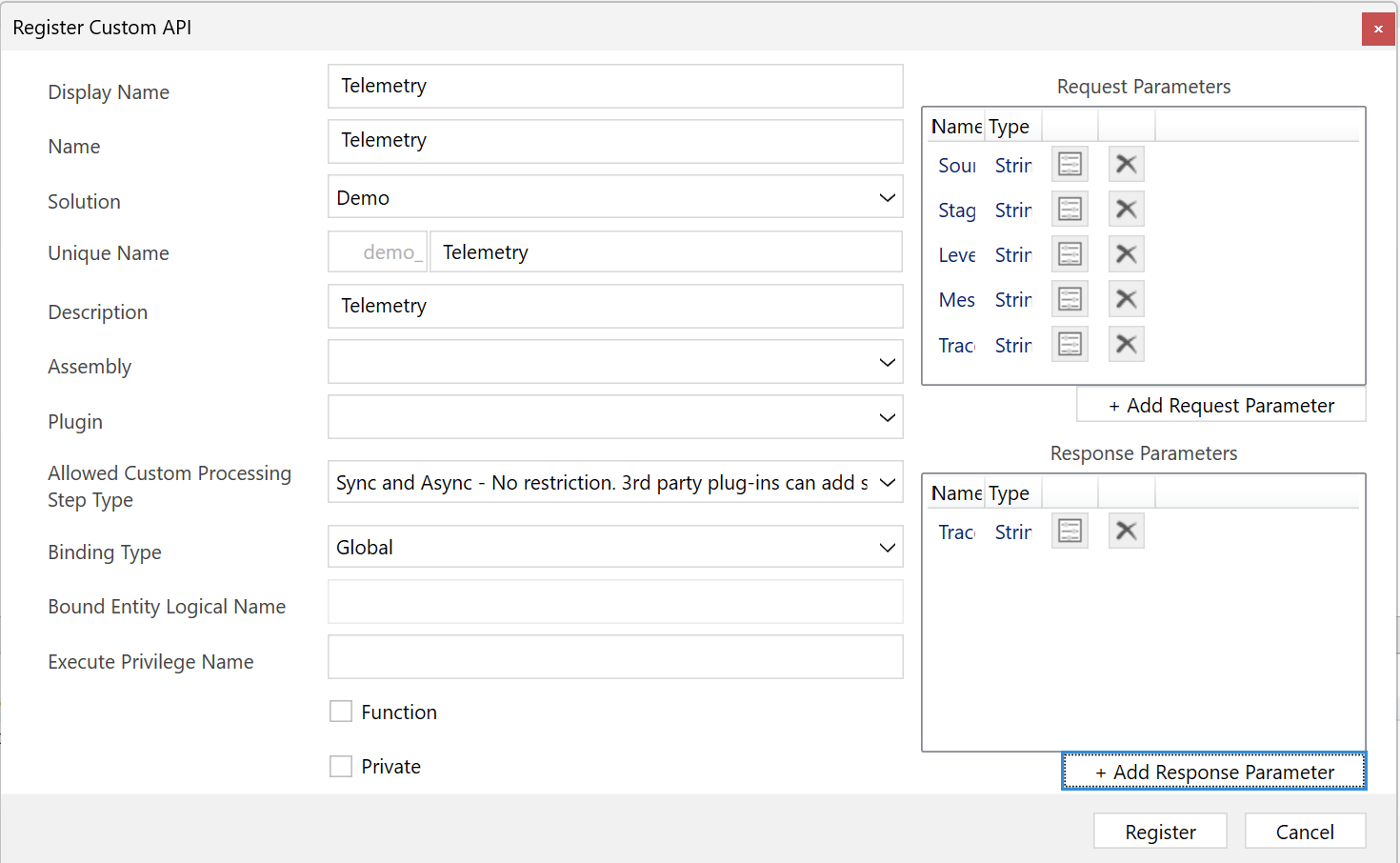
API personalizada com parâmetros de solicitação e resposta
O Dataverse permite que você crie e use APIs personalizadas com parâmetros específicos de solicitação e resposta para atender às necessidades do seu aplicativo.
InputParameters: Definir os dados de entrada exigidos pela API personalizada. Eles podem incluir vários tipos de dados, como cadeias de caracteres, inteiros e objetos complexos.OutputParameters: Definir os dados de saída retornados pela API personalizada. Eles podem incluir vários tipos de dados e estruturas, permitindo que você forneça respostas detalhadas e significativas aos consumidores de API.
Dica
Para rastreamento distribuído, você pode marcar o valor da cadeia de caracteres de consulta para passar uma Variável Compartilhada da API.
Etapas de processamento personalizadas (síncronas e assíncronas)
Ao usar etapas de processamento personalizadas, você pode definir se as etapas devem ser executadas de forma síncrona ou assíncrona. Essa flexibilidade permite que você otimize o desempenho e a capacidade de resposta de seu aplicativo.
- Processamento síncrono: as etapas são executadas sequencialmente. A próxima etapa não é iniciada até que a etapa atual seja concluída. Essa abordagem garante que cada etapa seja concluída antes de passar para a próxima.
- Processamento assíncrono: as etapas são executadas independentemente. A próxima etapa pode ser iniciada antes que a etapa atual seja concluída. Essa abordagem permite o processamento paralelo e pode melhorar o desempenho geral do seu aplicativo.
Ao definir etapas de processamento personalizadas, você pode adicionar monitoramento e outras funcionalidades a entidades existentes ou mensagens de API personalizadas, garantindo que seu aplicativo opere de forma eficiente e eficaz.
Plug-ins C# do Dataverse
Criar e implantar plug-ins C# do Dataverse que usam o SDK do Application Insights para criar o relacionamento pai-filho correto entre serviços. Saiba mais e, Gravar um plug-in.
Comparação entre o plug-in personalizado e o ILogger pronto para uso
O Dataverse fornece um ILogger pronto para uso que pode ser configurado no nível do ambiente. O ILogger integrado foi projetado para oferecer um mecanismo de registro padronizado em diferentes ambientes, garantindo consistência e facilidade de uso. No entanto, ele pode não fornecer o mesmo nível de granularidade e personalização que o ILogger de plug-in personalizado.
O plug-in personalizado ILogger no Dataverse oferece níveis mais detalhados de informações, como Rastreamento, Depuração e Informações. Ele permite que os desenvolvedores capturem dados mais específicos e relevantes durante a execução de plug-ins. O ILogger usa valores da solicitação de mensagem ou do parâmetro de tag de Variável Compartilhada para especificar o pai de rastreamento de chamada para melhor controle e correlação de logs.
Saiba mais em Gravar telemetria no recurso do Application Insights usando ILogger.
Principais conceitos do C# para analisar a atividade e especificar a ID pai
Quando você usa o ILogger de plug-in personalizado, é essencial entender os principais conceitos do C# para analisar a atividade e especificar a ID pai. Veja um exemplo de como criar uma nova atividade para uma mensagem de rastreamento:
// Create a new activity for the trace message
var activity = new Activity("CustomActivity");
activity.SetParentId(traceParent);
activity.Start();
// Create a trace telemetry record
var traceTelemetry = new TraceTelemetry(message, ConvertLogLevel(level))
{
Message = message,
Context = { Operation = { ParentId = dependencyTelemetry.Id, Id = activity.Id } }
};
// Track the trace telemetry
telemetryClient.TrackTrace(traceTelemetry);
Dica
O Projeto de exemplo OpenTelemetry do Dataverse contém um exemplo de integração de plug-in do Dataverse com OpenTelemetry. OpenTelemetry é uma coleção de padrões, APIs, SDKs e ferramentas do W3C que você pode usar para instrumentar, gerar, coletar e exportar dados de telemetria.
Colaboradores
Microsoft mantém este artigo. Os colaboradores a seguir escreveram este artigo.
Principais autores:
- Grant Archibald, Gerente Sênior de Programas