Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A simplicidade e a facilidade de uso que permitem aos usuários do Power BI coletar dados rapidamente e gerar relatórios interessantes e poderosos para tomar decisões de negócios inteligentes também permite que os usuários gerem facilmente consultas com baixo desempenho. Isso geralmente ocorre quando há duas tabelas relacionadas à maneira como uma chave estrangeira relaciona tabelas SQL ou listas do SharePoint. (Para o registro, esse problema não é específico do SQL ou do SharePoint e ocorre em muitos cenários de extração de dados de back-end, especialmente em que o esquema é fluido e personalizável.) Também não há nada de inerentemente errado em armazenar dados em tabelas separadas que compartilham uma chave comum. Na verdade, esse é um princípio fundamental do design e da normalização do banco de dados. Mas isso implica uma maneira melhor de expandir a relação.
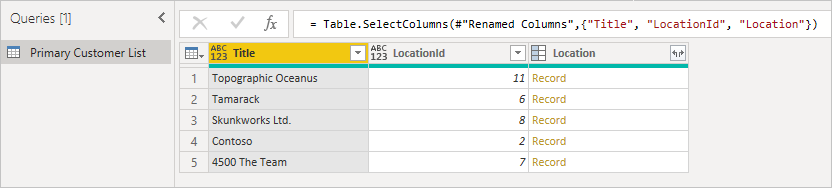
Considere o exemplo a seguir de uma lista de clientes do SharePoint.

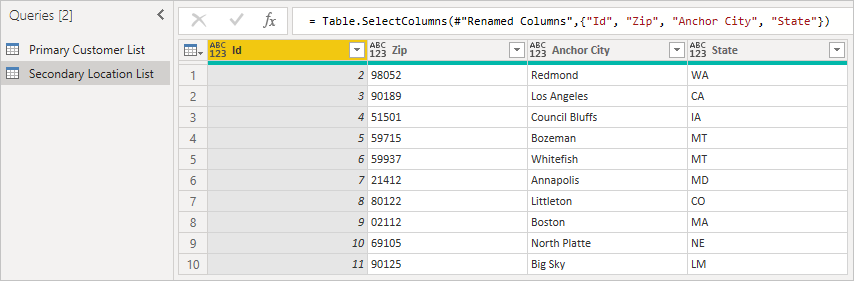
E a lista de locais a seguir à qual se refere.
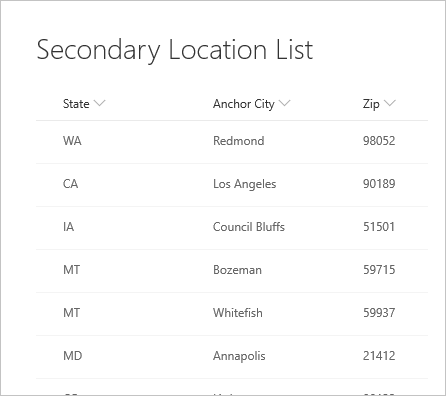
Ao se conectar pela primeira vez à lista, a localização aparece como um registro.
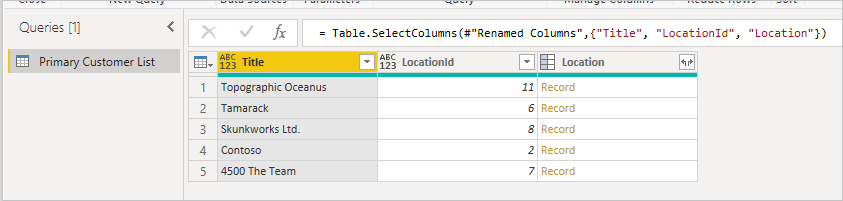
Esses dados de nível superior são coletados por meio de uma única chamada HTTP para a API do SharePoint (ignorando a chamada de metadados), que você pode ver em qualquer depurador da Web.

Ao expandir o registro, você verá os campos unidos da tabela secundária.
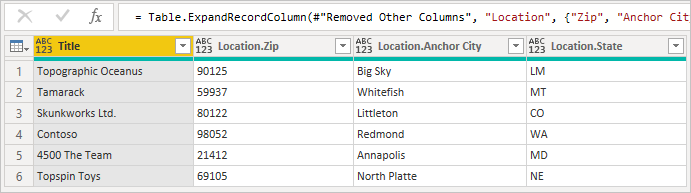
Ao expandir linhas relacionadas de uma tabela para outra, o comportamento padrão do Power BI é gerar uma chamada para Table.ExpandTableColumn. Você pode ver isso no campo de fórmula gerado. Infelizmente, esse método gera uma chamada individual para a segunda tabela para cada linha na primeira tabela.
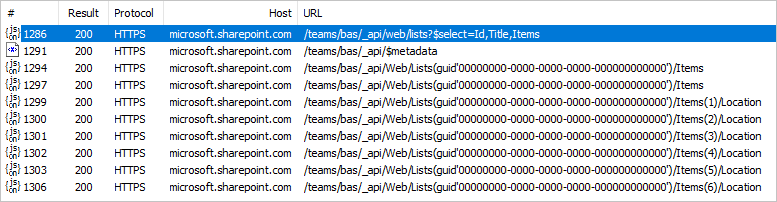
Isso aumenta o número de chamadas HTTP em uma para cada linha na lista primária. Isso pode não parecer muito no exemplo acima de cinco ou seis linhas, mas em sistemas de produção em que as listas do SharePoint atingem centenas de milhares de linhas, isso pode causar uma degradação significativa da experiência.
Quando as consultas atingem esse gargalo, a melhor mitigação é evitar o comportamento de chamada por linha usando uma junção de tabela clássica. Isso garante que haverá apenas uma chamada para recuperar a segunda tabela, e o restante da expansão pode ocorrer na memória usando a chave comum entre as duas tabelas. A diferença de desempenho pode ser enorme em alguns casos.
Primeiro, comece com a tabela original, observando a coluna que você deseja expandir e garantindo que você tenha a ID do item para que possa correspondê-la. Normalmente, a chave estrangeira é nomeada semelhante ao nome apresentado da coluna com ID acrescentada. Neste exemplo, é LocationId.
Em segundo lugar, carregue a tabela secundária, certificando-se de incluir a ID, que é a chave estrangeira. Clique com o botão direito do mouse no painel Consultas para criar uma nova consulta.
Por fim, junte as duas tabelas usando os respectivos nomes de coluna que correspondem. Normalmente, você pode encontrar esse campo expandindo primeiro a coluna e procurando as colunas correspondentes na visualização.

Neste exemplo, você pode ver que LocationId na lista primária corresponde à ID na lista secundária. A interface do usuário renomeia isso para Location.Id para tornar o nome da coluna exclusivo. Agora, vamos usar essas informações para mesclar as tabelas.
Clicando com o botão direito do mouse no painel de consulta e selecionando New Query>Combine>Merge Queries as New, você verá uma interface do usuário amigável para ajudá-lo a combinar essas duas consultas.
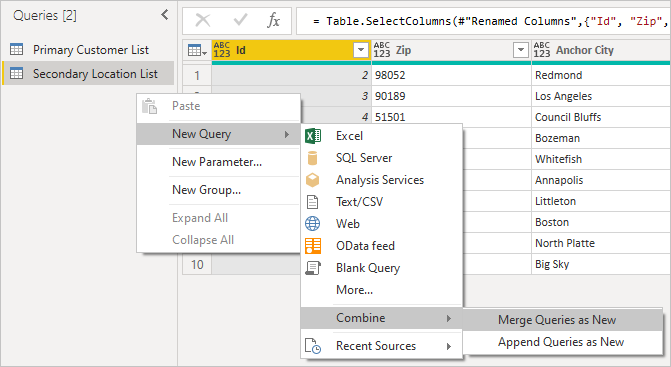
Selecione cada tabela na lista suspensa para ver uma pré-visualização da consulta.
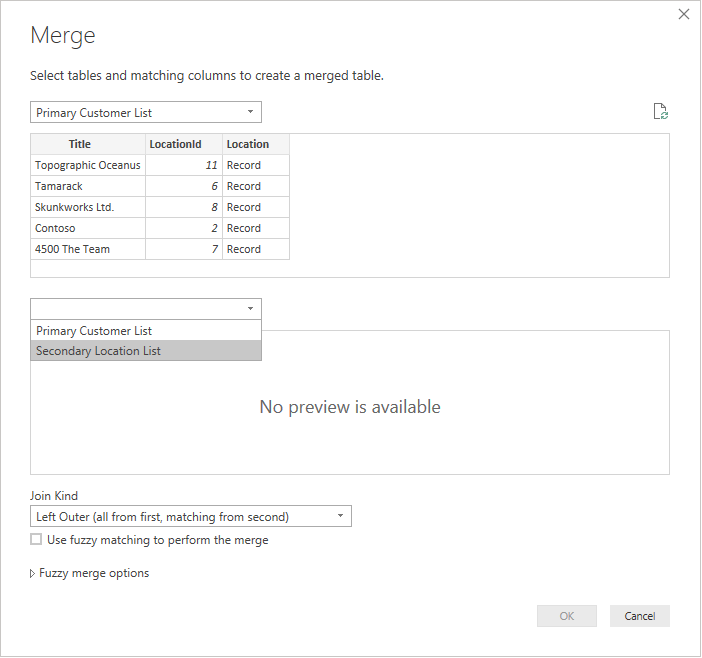
Depois de selecionar ambas as tabelas, selecione a coluna que une as tabelas logicamente (neste exemplo, é LocationId da tabela primária e ID da tabela secundária). A caixa de diálogo instruirá você sobre o número de linhas que correspondem usando essa chave estrangeira. Você provavelmente desejará usar o tipo de junção padrão (externo esquerdo) para esse tipo de dados.
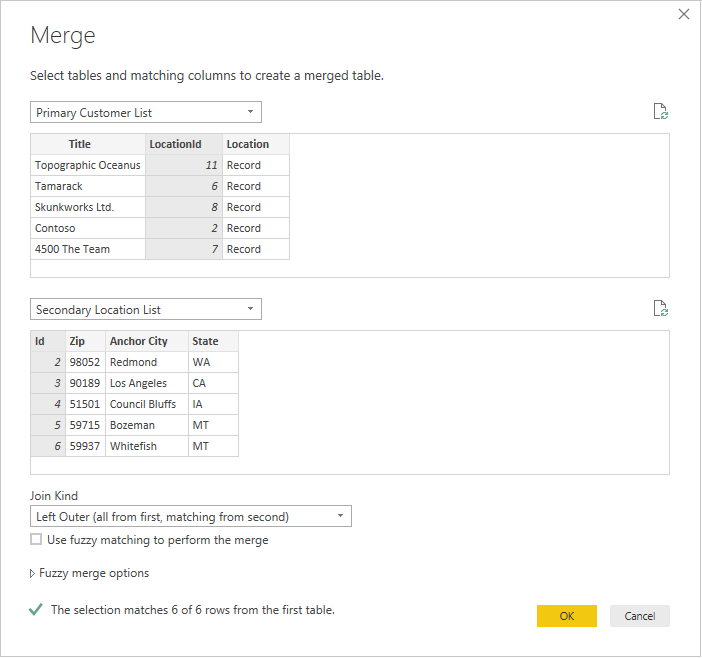
Selecione OK e você verá uma nova consulta, que é o resultado da junção. Expandir o registro agora não implica chamadas adicionais ao backend.

Atualizar esses dados resultará em apenas duas chamadas para o SharePoint— uma para a lista primária e outra para a lista secundária. A junção será executada na memória, reduzindo significativamente o número de chamadas para o SharePoint.
Essa abordagem pode ser usada para qualquer duas tabelas no PowerQuery que tenham uma chave estrangeira correspondente.
Observação
As listas de usuários e a taxonomia do SharePoint também são acessíveis como tabelas e podem ser unidas exatamente da maneira descrita acima, desde que o usuário tenha privilégios adequados para acessar essas listas.