Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo fornece alguns cenários de exemplo para cada um dos três resultados possíveis para dobramento de consulta. Ele também inclui algumas sugestões sobre como aproveitar ao máximo o mecanismo de dobragem de consulta e o efeito que ele pode ter em suas consultas.
O cenário
Imagine um cenário em que, usando o banco de dados Wide World Importers no SQL do Azure Synapse Analytics, você tem a tarefa de criar uma consulta no Power Query que se conecta à tabela fact_Sale e recupera as últimas 10 vendas apenas com os seguintes campos:
- Chave de Venda
- Chave de Cliente
- Chave de Data da Fatura
- Description
- Quantidade
Observação
Para fins de demonstração, este artigo usa o banco de dados descrito no tutorial sobre como carregar o banco de dados Wide World Importers no Azure Synapse Analytics. A principal diferença neste artigo é que a fact_Sale tabela contém apenas dados para o ano 2000, com um total de 3.644.356 linhas.
Embora os resultados possam não corresponder exatamente aos resultados obtidos seguindo o tutorial da documentação do Azure Synapse Analytics, o objetivo deste artigo é mostrar os principais conceitos e o impacto que a dobra de consultas pode ter em suas consultas.

Este artigo mostra três maneiras de obter o mesmo resultado com diferentes níveis de otimização de consulta.
- Sem otimização de consulta
- Dobramento parcial de consulta
- Dobramento de consulta completo
Nenhum exemplo de dobragem de consulta
Importante
Consultas que dependem exclusivamente de fontes de dados não estruturadas ou que não têm um mecanismo de computação, como arquivos CSV ou Excel, não têm recursos de dobragem de consulta. Isso significa que o Power Query avalia todas as transformações de dados necessárias usando o mecanismo do Power Query.
Depois de se conectar ao seu banco de dados e navegar até a fact_Sale tabela, selecione a transformação Manter linhas inferiores encontrada dentro do grupo Reduzir linhas da guia Página Inicial.
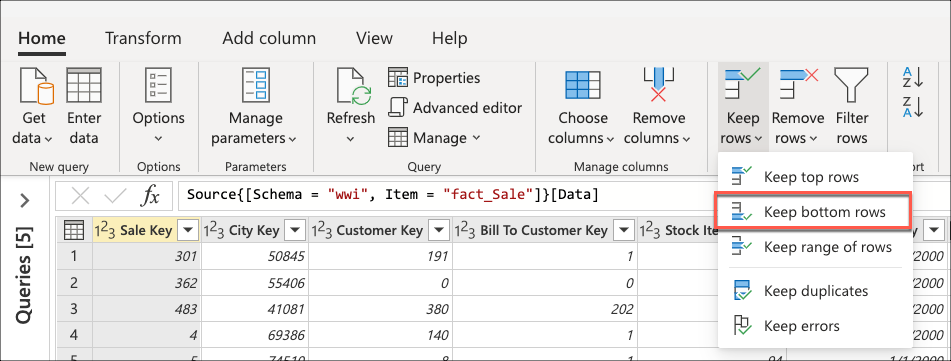
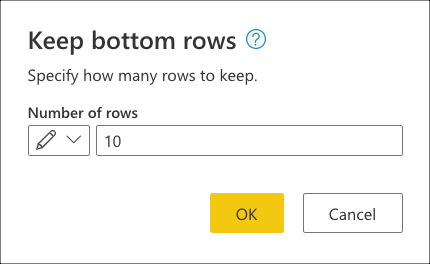
Depois de selecionar essa transformação, uma nova caixa de diálogo será exibida. Nesta nova caixa de diálogo, você pode inserir o número de linhas que deseja manter. Para esse caso, insira o valor 10 e selecione OK.
Dica
Para esse caso, a execução dessa operação gera o resultado das últimas 10 vendas. Na maioria dos cenários, recomendamos que você forneça uma lógica mais explícita que defina quais linhas são consideradas por último aplicando uma operação de classificação na tabela.
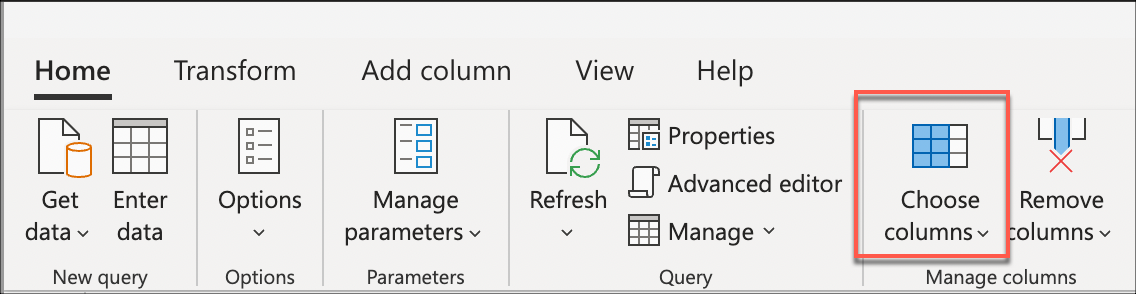
Em seguida, selecione a transformação Escolher colunas encontradas dentro do grupo Gerenciar colunas da guia Página Inicial . Em seguida, você pode selecionar as colunas que deseja manter de sua tabela e remover o restante.
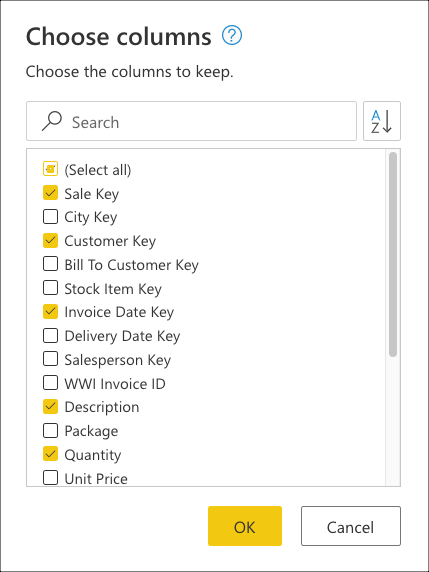
Por fim, dentro da caixa de diálogo Escolher colunas, selecione as Sale Keycolunas, , Customer Keye Invoice Date KeyDescriptionQuantity, em seguida, selecione OK.
O exemplo de código a seguir é o script M completo para a consulta que você criou:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(
#"Kept bottom rows",
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
)
in
#"Choose columns""
Sem otimização de consulta: compreensão da avaliação da consulta
Em etapas aplicadas no editor do Power Query, observe que os indicadores de dobramento de consulta para Manter linhas inferiores e Escolher colunas são marcados como etapas avaliadas fora da fonte de dados ou, em outras palavras, pelo mecanismo do Power Query.
Você pode clicar com o botão direito do mouse na última etapa da consulta, aquela chamada Escolher colunas, e selecionar a opção que diz Exibir plano de consulta. O objetivo do plano de consulta é fornecer uma visão detalhada de como a consulta é executada. Para saber mais sobre esse recurso, vá para o plano de consulta.

Cada uma das caixas na imagem anterior é chamada de nó. Um nó representa a quebra da operação para atender a essa consulta. Nodos que representam fontes de dados, como o SQL Server no exemplo anterior e o nó Value.NativeQuery, representam qual parte da consulta é delegada para a fonte de dados. O restante dos nós, nesse caso Table.LastN e Table.SelectColumns realçado no retângulo na imagem anterior, são avaliados pelo mecanismo do Power Query. Esses dois nós representam as duas transformações que você adicionou, Mantidas as linhas inferiores e Escolher colunas. O restante dos nós representa operações que ocorrem no nível da fonte de dados.
Para ver a solicitação exata enviada à fonte de dados, selecione Exibir detalhes no Value.NativeQuery nó.

Essa solicitação de fonte de dados está no idioma nativo da fonte de dados. Para esse caso, esse idioma é SQL e essa instrução representa uma solicitação para todas as linhas e campos da fact_Sale tabela.
Consultar essa solicitação de fonte de dados pode ajudá-lo a entender melhor a história que o plano de consulta tenta transmitir:
-
Sql.Database: Este nó representa o acesso à fonte de dados. Conecta-se ao banco de dados e envia solicitações de metadados para entender seus recursos. -
Value.NativeQuery: representa a solicitação que foi gerada pelo Power Query para atender à consulta. O Power Query envia as solicitações de dados em uma instrução SQL nativa para a fonte de dados. Nesse caso, isso representa todos os registros e campos (colunas) dafact_Saletabela. Para esse cenário, esse caso é indesejável, pois a tabela contém milhões de linhas e o interesse é apenas nos últimos 10. -
Table.LastN: depois que ofact_SalePower Query recebe todos os registros da tabela, ele usa o mecanismo do Power Query para filtrar a tabela e manter apenas as últimas 10 linhas. -
Table.SelectColumns: o Power Query usa a saída do nóTable.LastNe aplica uma nova transformação chamadaTable.SelectColumns, que seleciona as colunas específicas que você deseja manter de uma tabela.
Para sua avaliação, essa consulta teve que baixar todas as linhas e campos da fact_Sale tabela. Essa consulta levou uma média de 6 minutos e 1 segundo para ser processada em uma instância padrão de fluxos de dados do Power BI (que contabiliza a avaliação e o carregamento de dados em fluxos de dados).
Exemplo de dobragem de consulta parcial
Depois de se conectar ao banco de dados e navegar até a fact_Sale tabela, você começa selecionando as colunas que deseja manter de sua tabela. Selecione a transformação Escolher colunas encontrada dentro do grupo Gerenciar colunas na guia Página Inicial . Essa transformação ajuda você a selecionar explicitamente as colunas que deseja manter de sua tabela e remover o restante.
Dentro da caixa de diálogo Escolher colunas, selecione as colunas Sale Key, Customer Key, Invoice Date Key, Description e Quantity, depois selecione OK.
Agora você cria uma lógica que classifica a tabela para ter as últimas vendas na parte inferior da tabela. Selecione a Sale Key coluna, que é a chave primária e a sequência incremental ou o índice da tabela. Classifique a tabela usando somente esse campo em ordem crescente do menu de contexto da coluna.
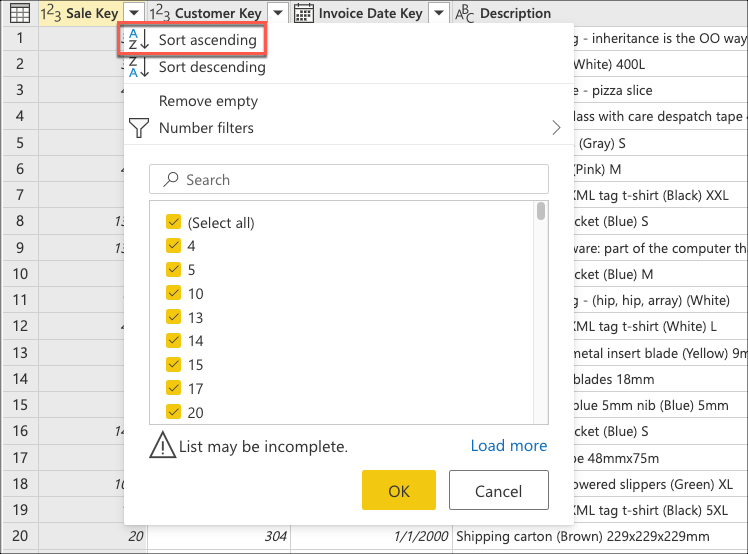
Em seguida, selecione o menu contextual da tabela e escolha a transformação Manter linhas inferiores .
Em Manter linhas inferiores, insira o valor 10 e selecione OK.
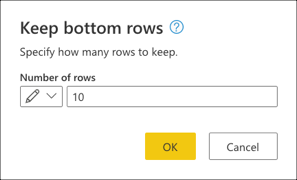
O exemplo de código a seguir é o script M completo para a consulta que você criou:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Exemplo de dobra de consulta parcial: Noções básicas sobre a avaliação da consulta
Verificando o painel de etapas aplicadas, observe que os indicadores de expansão de consulta estão mostrando que a última transformação que você adicionou, Kept bottom rows, está marcada como uma etapa avaliada fora da fonte de dados ou, em outras palavras, pelo mecanismo do Power Query.
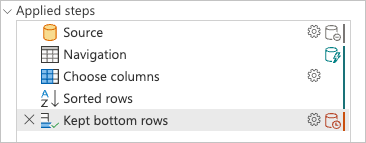
Você pode clicar com o botão direito do mouse na última etapa da consulta, aquela nomeada Kept bottom rowse selecionar a opção de plano de consulta para entender melhor como sua consulta pode ser avaliada.

Cada uma das caixas na imagem anterior é chamada de nó. Um nó representa todos os processos que precisam acontecer (da esquerda para a direita) para que sua consulta seja avaliada. Alguns desses nós podem ser avaliados na origem de dados, enquanto outros, como o nó para Table.LastN, representado pela etapa Linhas inferiores mantidas, são avaliados usando o mecanismo do Power Query.
Para ver a solicitação exata enviada à fonte de dados, selecione Exibir detalhes no Value.NativeQuery nó.

Essa solicitação está no idioma nativo da fonte de dados. Para esse caso, esse idioma é SQL e essa instrução representa uma solicitação para todas as linhas, com apenas os campos solicitados da fact_Sale tabela ordenada pelo Sale Key campo.
Consultar essa solicitação de fonte de dados pode ajudá-lo a entender melhor a história que o plano de consulta completo tenta transmitir. A ordem dos nós é um processo sequencial que começa solicitando os dados da fonte de dados:
-
Sql.Database: conecta-se ao banco de dados e envia solicitações de metadados para entender seus recursos. -
Value.NativeQuery: representa a solicitação gerada pelo Power Query para atender à consulta. O Power Query envia as solicitações de dados em uma instrução SQL nativa para a fonte de dados. Para esse caso, isso representa todos os registros, com apenas os campos solicitados dafact_Saletabela no banco de dados classificados em ordem crescente peloSales Keycampo. -
Table.LastN: depois que ofact_SalePower Query recebe todos os registros da tabela, ele usa o mecanismo do Power Query para filtrar a tabela e manter apenas as últimas 10 linhas.
Para sua avaliação, essa consulta teve que baixar todas as linhas e apenas os campos necessários da fact_Sale tabela. Levou uma média de 3 minutos e 4 segundos para ser processada em uma instância padrão de fluxos de dados do Power BI (que contabiliza a avaliação e o carregamento de dados em fluxos de dados).
Exemplo de dobragem de consulta completa
Depois de se conectar ao banco de dados e navegar até a fact_Sale tabela, comece selecionando as colunas que deseja manter de sua tabela. Selecione a transformação Escolher colunas encontrada dentro do grupo Gerenciar colunas na guia Página Inicial . Essa transformação ajuda você a selecionar explicitamente as colunas que deseja manter de sua tabela e remover o restante.
Em Escolher colunas, selecione as colunas Sale Key, Customer Key, Invoice Date Key, Description e Quantity, em seguida, selecione OK.
Agora você cria uma lógica que classifica a tabela para ter as últimas vendas na parte superior da tabela. Selecione a Sale Key coluna, que é a chave primária e a sequência incremental ou o índice da tabela. Classifique a tabela apenas usando esse campo em ordem decrescente do menu de contexto da coluna.
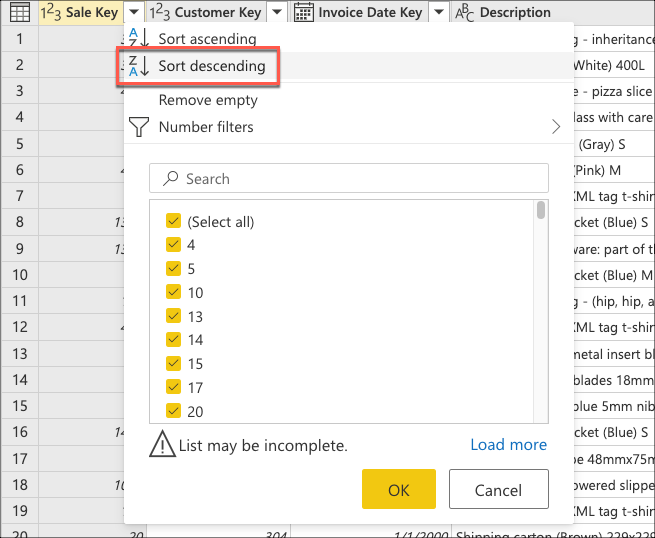
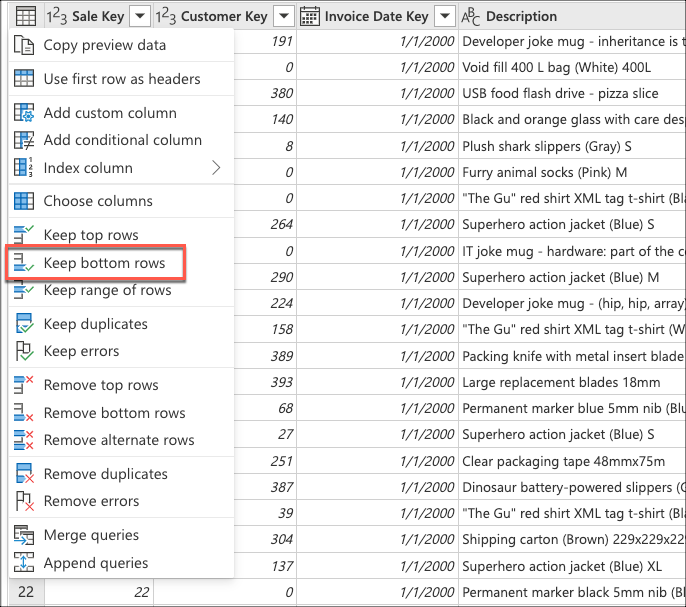
Em seguida, selecione o menu contextual da tabela e escolha a transformação Manter linhas superiores .
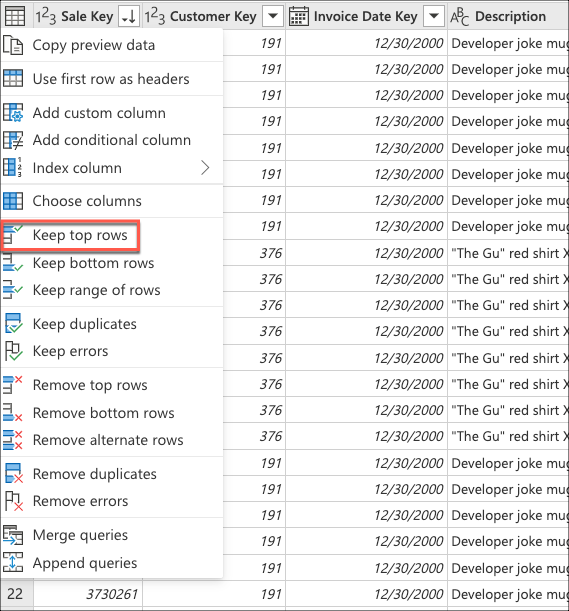
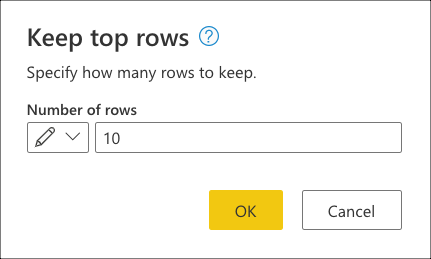
Em Manter linhas superiores, insira o valor 10 e selecione OK.
O exemplo de código a seguir é o script M completo para a consulta que você criou:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Exemplo de dobragem de consulta completa: Noções básicas sobre a avaliação da consulta
Ao verificar o painel de etapas aplicadas, observe que os indicadores de dobragem de consulta estão mostrando que as transformações que você adicionou, Escolher colunas, Linhas classificadas e Linhas mantidas nas primeiras linhas estão marcadas como etapas que são avaliadas na fonte de dados.

Você pode clicar com o botão direito do mouse na última etapa da consulta, aquela chamada Manter linhas superiores e selecionar a opção que lê o plano de consulta.

Essa solicitação está no idioma nativo da fonte de dados. Para esse caso, esse idioma é SQL e essa instrução representa uma solicitação para todas as linhas e campos da fact_Sale tabela.
Consultar essa consulta de fonte de dados pode ajudá-lo a entender melhor a história que o plano de consulta completo tenta transmitir:
-
Sql.Database: conecta-se ao banco de dados e envia solicitações de metadados para entender seus recursos. -
Value.NativeQuery: representa a solicitação gerada pelo Power Query para atender à consulta. O Power Query envia as solicitações de dados em uma instrução SQL nativa para a fonte de dados. Para esse caso, isso representa uma solicitação somente para os 10 principais registros dafact_Saletabela, com apenas os campos necessários depois de serem classificados em ordem decrescente usando oSale Keycampo.
Observação
Embora não haja nenhuma cláusula que possa ser usada para SELECIONAR as linhas inferiores de uma tabela na linguagem T-SQL, há uma cláusula TOP que recupera as linhas superiores de uma tabela.
Para sua avaliação, essa consulta baixa apenas 10 linhas, com apenas os campos que você solicitou da fact_Sale tabela. Essa consulta levou uma média de 31 segundos para ser processada em uma instância padrão de fluxos de dados do Power BI (que contabiliza a avaliação e o carregamento de dados em fluxos de dados).
Comparação de desempenho
Para entender melhor o efeito que a dobra de consulta tem nessas consultas, você pode atualizar suas consultas, registrar o tempo necessário para atualizar totalmente cada consulta e compará-las. Para simplificar, este artigo fornece os tempos médios de atualização capturados usando o mecanismo de atualização de fluxos de dados do Power BI enquanto se conecta a um ambiente dedicado do Azure Synapse Analytics com DW2000c como o nível de serviço.
A hora de atualização de cada consulta foi a seguinte:
| Example | Etiqueta | Tempo em segundos |
|---|---|---|
| Sem otimização de consulta | None | 361 |
| Dobramento parcial de consulta | Parcial | 184 |
| Dobramento de consulta completo | Completo | 31 |
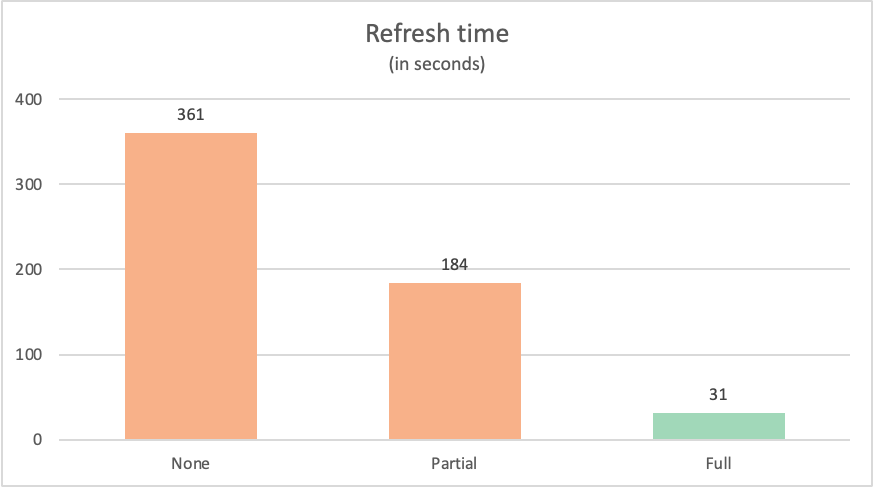
Geralmente, é o caso de uma consulta que é completamente enviada para a fonte de dados ter melhor desempenho do que consultas semelhantes que não são completamente processadas pela fonte de dados. Pode haver muitas razões pelas quais este é o caso. Esses motivos vão desde a complexidade das transformações executadas pela consulta até as otimizações de consulta implementadas na fonte de dados, como índices e computação dedicada e recursos de rede. Ainda assim, há dois processos-chave específicos que a dobragem de consultas tenta usar que minimizam o efeito que ambos os processos têm no Power Query.
- Dados em trânsito
- Transformações executadas pelo mecanismo do Power Query
As seções a seguir explicam o efeito que esses dois processos têm nas consultas mencionadas anteriormente.
Dados em trânsito
Quando uma consulta é executada, ela tenta buscar os dados da fonte de dados como uma de suas primeiras etapas. Os dados que são obtidos da fonte de dados são definidos pelo mecanismo de dobragem de consultas. Esse mecanismo identifica as etapas da consulta que podem ser descarregadas para a fonte de dados.
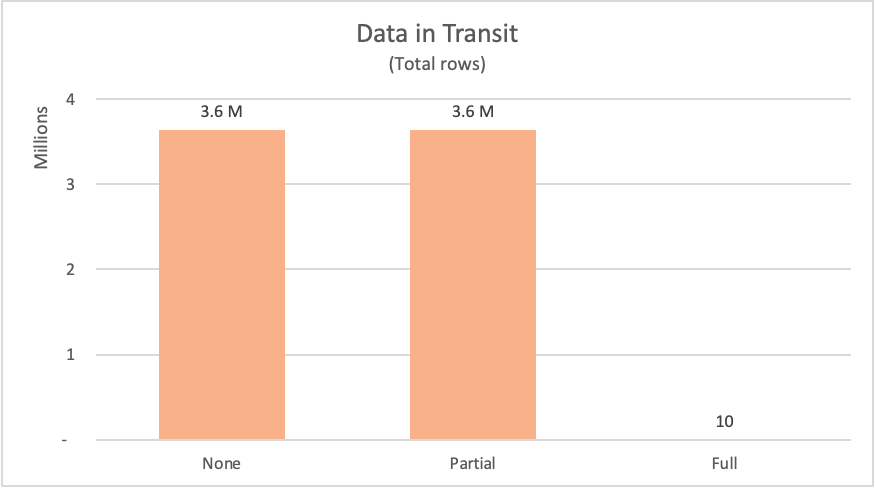
A tabela a seguir lista o número de linhas solicitadas da fact_Sale tabela do banco de dados. A tabela também inclui uma breve descrição da instrução SQL enviada para solicitar esses dados da fonte de dados.
| Example | Etiqueta | Linhas solicitadas | Description |
|---|---|---|---|
| Sem otimização de consulta | None | 3644356 | Solicitação para todos os campos e todos os registros da fact_Sale tabela |
| Dobramento parcial de consulta | Parcial | 3644356 | Solicitar todos os registros, mas apenas os campos necessários da tabela fact_Sale após a ordenação pelo campo Sale Key |
| Dobramento de consulta completo | Completo | 10 | Solicitar apenas os campos necessários e os 10 primeiros registros da fact_Sale tabela após serem classificados em ordem decrescente pelo Sale Key campo |
Quando você solicita dados de uma fonte de dados, a fonte de dados precisa calcular os resultados da solicitação e, em seguida, enviar os dados para o solicitante. Embora os recursos de computação já tenham sido mencionados, os recursos de rede de mover os dados da fonte de dados para o Power Query e, em seguida, fazer com que o Power Query possa receber efetivamente os dados e prepará-los para as transformações que ocorrem localmente podem levar algum tempo dependendo do tamanho dos dados.
Para os exemplos exibidos, o Power Query teve que solicitar mais de 3,6 milhões de linhas da fonte de dados para os exemplos sem dobramento de consulta e com dobramento de consulta parcial. No exemplo de dobramento de consulta completo, foram solicitadas apenas 10 linhas. Para os campos solicitados, o exemplo de dobragem sem consulta solicitou todos os campos disponíveis da tabela. Tanto a dobra de consulta parcial quanto os exemplos completos de dobragem de consulta enviaram apenas uma solicitação para exatamente os campos necessários.
Cuidado
Recomendamos que você implemente soluções de atualização incremental que utilizam o dobramento de consultas para consultas ou tabelas com grandes quantidades de dados. Diferentes integrações de produtos do Power Query implementam tempos limite para encerrar consultas de execução prolongada. Algumas fontes de dados também implementam tempos limite em sessões de execução longa, tentando executar consultas caras em seus servidores. Mais informações: Usando a atualização incremental com fluxos de dados e atualização incremental para modelos semânticos
Transformações executadas pelo mecanismo do Power Query
Este artigo mostrou como você pode usar o plano de consulta para entender melhor como sua consulta pode ser avaliada. Dentro do plano de consulta, você pode ver os nós exatos das operações de transformação executadas pelo mecanismo do Power Query.
A tabela a seguir mostra os nós dos planos de consulta das consultas anteriores que teriam sido avaliadas pelo mecanismo do Power Query.
| Example | Etiqueta | Nós de transformação no mecanismo Power Query |
|---|---|---|
| Sem otimização de consulta | None |
Table.LastN, Table.SelectColumns |
| Dobramento parcial de consulta | Parcial | Table.LastN |
| Dobramento de consulta completo | Completo | — |
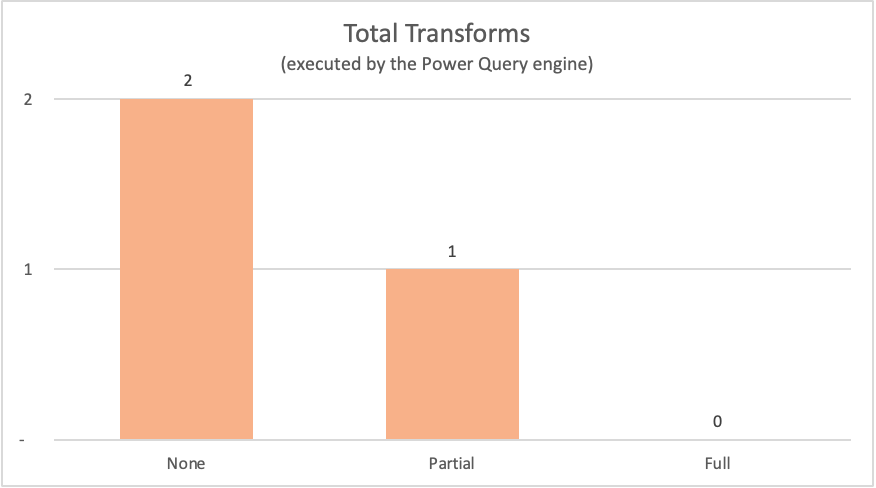
Para os exemplos mostrados neste artigo, o exemplo de dobragem de consulta completo não exige que nenhuma transformação ocorra dentro do mecanismo do Power Query, pois a tabela de saída necessária vem diretamente da fonte de dados. Por outro lado, as outras duas consultas exigiram que alguma computação acontecesse no mecanismo do Power Query. Devido à quantidade de dados que precisam ser processados por essas duas consultas, o processo para esses exemplos leva mais tempo do que o exemplo de dobragem de consulta completa.
As transformações podem ser agrupadas nas seguintes categorias:
| Tipo de operador | Description |
|---|---|
| Remoto | Operadores que são nós de dados. A avaliação desses operadores ocorre fora do Power Query. |
| Streaming | Os operadores são operadores de passagem. Por exemplo, Table.SelectRows com um filtro simples geralmente pode filtrar os resultados conforme eles passam pelo operador e não precisam coletar todas as linhas antes de mover os dados.
Table.SelectColumns e Table.ReorderColumns são outros exemplos desse tipo de operadores. |
| Verificação completa | Operadores que precisam coletar todas as linhas antes que os dados possam passar para o próximo operador na cadeia. Por exemplo, para classificar dados, o Power Query precisa coletar todos os dados. Outros exemplos de operadores de verificação completa são Table.Group, Table.NestedJoine Table.Pivot. |
Dica
Embora nem todas as transformações sejam iguais do ponto de vista de desempenho, na maioria dos casos, ter menos transformações geralmente é melhor.
Considerações e sugestões
- Siga as práticas recomendadas ao criar uma nova consulta, conforme indicado nas práticas recomendadas no Power Query.
- Use os indicadores de dobragem de consulta para verificar quais etapas estão impedindo que sua consulta dobre. Reordene-os, se necessário, para aumentar o dobramento.
- Use o plano de consulta para determinar quais transformações estão acontecendo no mecanismo do Power Query para uma etapa específica. Considere modificar sua consulta existente reorganizando suas etapas. Em seguida, verifique o plano de consulta da última etapa da consulta novamente e veja se o plano de consulta está melhor do que o anterior. Por exemplo, o novo plano de consulta tem menos nós do que o anterior, e a maioria dos nós são nós de "Streaming" e não de "verificação completa". Para fontes de dados que dão suporte à otimização, todos os nós no plano de consulta, com exceção de
Value.NativeQuerye os nós de acesso à fonte de dados, representam transformações que não foram otimizadas. - Quando disponível, você pode usar a opção Exibir Consulta Nativa (ou Exibir consulta de fonte de dados) para garantir que sua consulta possa ser dobrada novamente para a fonte de dados. Se essa opção estiver desabilitada para sua etapa e você estiver usando uma origem que normalmente a habilita, você criou uma etapa que interrompe a dobra de consulta. Se você estiver usando uma fonte que não dá suporte a essa opção, poderá contar com os indicadores de dobragem de consulta e o plano de consulta.
- Use as ferramentas de diagnóstico de consulta para entender melhor as solicitações enviadas à fonte de dados quando as funcionalidades de dobramento de consulta estiverem disponíveis para o conector.
- Quando você combina dados provenientes do uso de vários conectores, o Power Query tenta enviar o máximo de trabalho possível para ambas as fontes de dados, em conformidade com os níveis de privacidade definidos para cada fonte de dados.
- Leia o artigo sobre os níveis de privacidade para proteger suas consultas contra um erro do Firewall de Privacidade de Dados.
- Utilize outras ferramentas para verificar o processamento de consultas conforme a perspectiva da requisição recebida pela fonte de dados. Com base no exemplo neste artigo, você pode usar o Microsoft SQL Server Profiler para verificar as solicitações enviadas pelo Power Query e recebidas pelo Microsoft SQL Server.
- Se você adicionar uma nova etapa a uma consulta totalmente dobrada e a nova etapa também for dobrada, o Power Query poderá enviar uma nova solicitação à fonte de dados em vez de usar uma versão armazenada em cache do resultado anterior. Na prática, esse processo pode resultar em operações aparentemente simples em uma pequena quantidade de dados demorando mais para serem atualizados na versão prévia do que o esperado. Essa atualização mais longa ocorre porque o Power Query está consultando novamente a fonte de dados em vez de trabalhar a partir de uma cópia local dos dados.