Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
O Azure Data Lake Analytics se aposentou em 29 de fevereiro de 2024. Saiba mais com este comunicado.
Para análise de dados, sua organização pode usar o Azure Synapse Analytics ou o Microsoft Fabric.
O que é distorção de dados?
Resumidamente, a distorção de dados é um valor super-representado. Imagine que você atribuiu 50 examinadores fiscais para auditar as declarações fiscais, um examinador para cada estado dos EUA. O examinador de Wyoming, como a população lá é pequena, tem pouco a fazer. Na Califórnia, no entanto, o examinador é mantido ocupado por causa da grande população do estado.

Em nosso cenário, os dados são distribuídos de forma desigual em todos os examinadores fiscais, o que significa que alguns examinadores devem trabalhar mais do que outros. Em seu próprio trabalho, você frequentemente experimenta situações como o exemplo de examinador de impostos aqui. Em termos mais técnicos, um vértice obtém muito mais dados do que seus pares, uma situação que faz com que o vértice funcione mais do que os outros e que eventualmente atrasa um trabalho inteiro. O que é pior, o trabalho pode falhar, porque os vértices podem ter, por exemplo, uma limitação de runtime de 5 horas e uma limitação de memória de 6 GB.
Resolvendo problemas de distorção de dados
As Ferramentas do Azure Data Lake para Visual Studio e Visual Studio Code podem ajudar a detectar se o trabalho tem um problema de distorção de dados.
- Instalar as Ferramentas do Azure Data Lake para Visual Studio
- Instalar as Ferramentas do Azure Data Lake para Visual Studio Code
Se houver um problema, você poderá resolvê-lo experimentando as soluções nesta seção.
Solução 1: Melhorar o particionamento de tabela
Opção 1: Filtrar o valor da chave distorcida com antecedência
Se isso não afetar sua lógica de negócios, você poderá filtrar os valores de frequência mais alta com antecedência. Por exemplo, se houver muitos 000-000-000 na coluna GUID, talvez você não queira agregar esse valor. Antes de agregar, você pode escrever "WHERE GUID != "000-000-000"" para filtrar o valor de alta frequência.
Opção 2: Escolher uma chave de distribuição ou partição diferente
No exemplo anterior, se você quiser verificar apenas a carga de trabalho de auditoria fiscal em todo o país/região, poderá melhorar a distribuição de dados selecionando o número da ID como sua chave. Escolher uma chave de distribuição ou partição diferente às vezes pode distribuir os dados de forma mais uniforme, mas você precisa garantir que essa escolha não afete sua lógica de negócios. Por exemplo, para calcular a soma do imposto para cada estado, convém designar State como a chave de partição. Se você continuar enfrentando esse problema, tente usar a Opção 3.
Opção 3: Adicionar mais chaves de partição ou distribuição
Em vez de usar apenas State como uma chave de partição, você pode usar mais de uma chave para particionamento. Por exemplo, considere adicionar de CEP como outra chave de partição para reduzir os tamanhos de partição de dados e distribuir os dados de forma mais uniforme.
Opção 4: Usar a distribuição round-robin
Se você não encontrar uma chave apropriada para partição e distribuição, pode tentar usar a distribuição cíclica. A distribuição Round-robin trata todas as linhas de forma igual e coloca-as aleatoriamente em compartimentos correspondentes. Os dados são distribuídos uniformemente, mas perdem informações de localidade, uma desvantagem que também pode reduzir o desempenho do trabalho para algumas operações. Além disso, se você estiver fazendo agregação para a chave distorcida de qualquer maneira, o problema de distorção de dados persistirá. Para saber mais sobre a distribuição round-robin, consulte a seção Distribuições de Tabelas U-SQL em CREATE TABLE (U-SQL): Criando uma Tabela com Esquema.
Solução 2: Melhorar o plano de consulta
Opção 1: usar a instrução CREATE STATISTICS
O U-SQL fornece a instrução CREATE STATISTICS em tabelas. Essa instrução fornece mais informações ao otimizador de consulta sobre as características de dados (por exemplo, distribuição de valor) que são armazenadas em uma tabela. Para a maioria das consultas, o otimizador de consulta já gera as estatísticas necessárias para um plano de consulta de alta qualidade. Ocasionalmente, talvez seja necessário melhorar o desempenho da consulta criando mais estatísticas com CREATE STATISTICS ou modificando o design da consulta. Para obter mais informações, consulte a página CREATE STATISTICS (U-SQL).
Exemplo de código:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Observação
As informações de estatísticas não são atualizadas automaticamente. Se você atualizar os dados em uma tabela sem recriar as estatísticas, o desempenho da consulta poderá diminuir.
Opção 2: Usar SKEWFACTOR
Se você quiser somar o imposto para cada estado, deverá usar o estado GROUP BY, uma abordagem que não evita o problema de distorção de dados. No entanto, você pode fornecer uma dica de dados em sua consulta para identificar a distorção de dados nas chaves para que o otimizador possa preparar um plano de execução para você.
Normalmente, você pode definir o parâmetro como 0,5 e 1, com 0,5 significando não muita distorção e uma significando distorção pesada. Como a indicação afeta a otimização do plano de execução para a declaração atual e todas as declarações subsequentes, certifique-se de adicionar a indicação antes da possível agregação de chave enviesada.
SKEWFACTOR (columns) = x
Fornece uma dica de que as colunas fornecidas têm um fator de distorção x de 0 (sem distorção) a 1 (distorção pesada).
Exemplo de código:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Opção 3: Usar ROWCOUNT
Além de SKEWFACTOR, para casos específicos de junção de chave distorcida, se você souber que o outro conjunto de linhas unidas é pequeno, você pode informar o otimizador adicionando uma dica ROWCOUNT na instrução U-SQL antes de JOIN. Dessa forma, o otimizador pode escolher uma estratégia de junção de difusão para ajudar a melhorar o desempenho. Lembre-se de que ROWCOUNT não resolve o problema de distorção de dados, mas pode oferecer ajuda extra.
OPTION(ROWCOUNT = n)
Identifique um pequeno conjunto de linhas antes do JOIN, fornecendo um número estimado de linhas inteiras.
Exemplo de código:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Solução 3: Melhorar o redutor e o combinador definidos pelo usuário
Às vezes, você pode escrever um operador definido pelo usuário para lidar com uma lógica de processo complicada, e um redutor e um combinador bem escritos podem atenuar um problema de distorção de dados em alguns casos.
Opção 1: Usar um redutor recursivo, se possível
Por padrão, um redutor definido pelo usuário é executado no modo não recursivo, o que significa que o trabalho de redução para uma chave é distribuído em um único vértice. Mas se os dados forem distorcidos, os conjuntos de dados enormes poderão ser processados em um único vértice e executados por um longo tempo.
Para melhorar o desempenho, você pode adicionar um atributo em seu código para definir o redutor a ser executado no modo recursivo. Em seguida, os conjuntos de dados enormes podem ser distribuídos para vários vértices e executados em paralelo, o que acelera seu trabalho.
Para alterar um redutor não recursivo para recursivo, você precisa verificar se o algoritmo é associativo. Por exemplo, a soma é associativa e a mediana não. Você também precisa garantir que a entrada e a saída do redutor mantenham o mesmo esquema.
Atributo do redutor recursivo:
[SqlUserDefinedReducer(IsRecursive = true)]
Exemplo de código:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Opção 2: Usar o modo combinador de nível de linha, se possível
Semelhante à dica ROWCOUNT para casos específicos de junção com chave enviesada, o modo combinador tenta distribuir grandes conjuntos de valores de chaves enviesadas para vários vértices, para que o trabalho possa ser executado simultaneamente. O modo combinador não pode resolver problemas de distorção de dados, mas pode oferecer ajuda extra para grandes conjuntos de valores de teclas distorcidas.
Por padrão, o modo combinador é Completo, o que significa que os conjuntos de linhas da esquerda e da direita não podem ser separados. Configurar o modo como Esquerda/Direita/Interno permite uma junção a nível de linha. O sistema separa os conjuntos de linhas correspondentes e os distribui em vários vértices executados em paralelo. No entanto, antes de configurar o modo combinador, tenha cuidado para garantir que os conjuntos de linhas correspondentes possam ser separados.
O exemplo a seguir mostra um conjunto de fileiras à esquerda separado. Cada linha de saída depende de uma única linha de entrada da esquerda e, potencialmente, depende de todas as linhas da direita com o mesmo valor de chave. Se você definir o modo combinador como esquerda, o sistema separará o enorme conjunto de linhas à esquerda em conjuntos menores e os atribuirá a vários vértices.
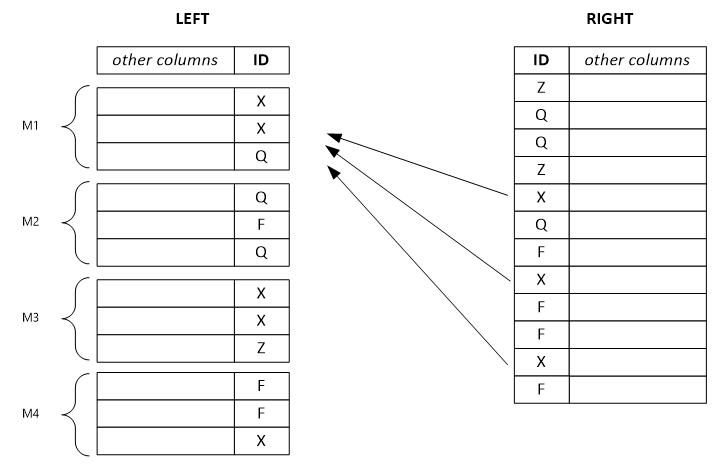
Observação
Se você definir o modo combinador errado, a combinação será menos eficiente e os resultados poderão estar errados.
Atributos do modo combinador:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): Cada linha de saída potencialmente depende de todas as linhas de entrada da esquerda e da direita com o mesmo valor de chave.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): cada linha de saída depende de uma única linha de entrada da esquerda (e potencialmente todas as linhas da direita com o mesmo valor de chave).
qlUserDefinedCombiner(Mode=CombinerMode.Right): cada linha de saída depende de uma única linha de entrada da direita (e potencialmente todas as linhas da esquerda com o mesmo valor de chave).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): cada linha de saída depende de uma única linha de entrada da esquerda e da direita com o mesmo valor.
Exemplo de código:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}