Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo apresenta a nova API de Fala e mostra como implementá-la em um aplicativo Xamarin.iOS para dar suporte ao reconhecimento contínuo de fala e transcrever fala (de fluxos de áudio ao vivo ou gravados) em texto.
Novidade no iOS 10, a Apple lançou a API de reconhecimento de fala que permite que um aplicativo iOS ofereça suporte ao reconhecimento contínuo de fala e transcreva fala (de fluxos de áudio ao vivo ou gravados) em texto.
De acordo com a Apple, a API de reconhecimento de fala tem os seguintes recursos e benefícios:
- Altamente preciso
- Estado da Arte
- Fácil de usar
- Rápido
- Suporta vários idiomas
- Respeita a privacidade do usuário
Como funciona o reconhecimento de fala
O Reconhecimento de Fala é implementado em um aplicativo iOS adquirindo áudio ao vivo ou pré-gravado (em qualquer um dos idiomas falados compatíveis com a API) e passando-o para um Reconhecimento de Fala que retorna uma transcrição de texto sem formatação das palavras faladas.

Ditado do teclado
Quando a maioria dos usuários pensa em Reconhecimento de Fala em um dispositivo iOS, eles pensam no assistente de voz Siri integrado, que foi lançado junto com o Ditado do Teclado no iOS 5 com o iPhone 4S.
O Ditado do Teclado é suportado por qualquer elemento de interface que dê suporte ao TextKit (como UITextField ou UITextArea) e é ativado pelo usuário clicando no Botão de Ditado (diretamente à esquerda da barra de espaço) no teclado virtual do iOS.
A Apple divulgou as seguintes estatísticas de ditado de teclado (coletadas desde 2011):
- O Keyboard Dictation tem sido amplamente utilizado desde que foi lançado no iOS 5.
- Aproximadamente 65.000 aplicativos o usam por dia.
- Cerca de um terço de todo o ditado do iOS é feito em um aplicativo de terceiros.
O Ditado do Teclado é extremamente fácil de usar, pois não requer nenhum esforço por parte do desenvolvedor, além de usar um elemento de interface do TextKit no design da interface do usuário do aplicativo. O Ditado do Teclado também tem a vantagem de não exigir nenhuma solicitação de privilégio especial do aplicativo antes que ele possa ser usado.
Os aplicativos que usam as novas APIs de reconhecimento de fala exigirão permissões especiais a serem concedidas pelo usuário, pois o reconhecimento de fala requer a transmissão e o armazenamento temporário de dados nos servidores da Apple. Consulte nossa documentação de aprimoramentos de segurança e privacidade para obter detalhes.
Embora o Ditado do Teclado seja fácil de implementar, ele vem com várias limitações e desvantagens:
- Requer o uso de um campo de entrada de texto e a exibição de um teclado.
- Ele funciona apenas com entrada de áudio ao vivo e o aplicativo não tem controle sobre o processo de gravação de áudio.
- Ele não fornece controle sobre a linguagem usada para interpretar a fala do usuário.
- Não há como o aplicativo saber se o botão Ditado está disponível para o usuário.
- O aplicativo não pode personalizar o processo de gravação de áudio.
- Ele fornece um conjunto muito superficial de resultados que carece de informações como tempo e confiança.
API de reconhecimento de fala
Novidade no iOS 10, a Apple lançou a API de reconhecimento de fala, que fornece uma maneira mais poderosa para um aplicativo iOS implementar o reconhecimento de fala. Esta API é a mesma que a Apple usa para alimentar a Siri e o Keyboard Dictation e é capaz de fornecer transcrição rápida com precisão de última geração.
Os resultados fornecidos pela API de Reconhecimento de Fala são personalizados de forma transparente para os usuários individuais, sem que o aplicativo precise coletar ou acessar dados privados do usuário.
A API de Reconhecimento de Fala fornece resultados de volta ao aplicativo de chamada quase em tempo real enquanto o usuário está falando e fornece mais informações sobre os resultados da tradução do que apenas texto. Estão incluídos:
- Múltiplas interpretações do que o usuário disse.
- Níveis de confiança para as traduções individuais.
- Informações de tempo.
Conforme declarado acima, o áudio para tradução pode ser fornecido por uma transmissão ao vivo ou de uma fonte pré-gravada e em qualquer um dos mais de 50 idiomas e dialetos suportados pelo iOS 10.
A API de reconhecimento de fala pode ser usada em qualquer dispositivo iOS com iOS 10 e, na maioria dos casos, requer uma conexão ativa com a Internet, pois a maior parte das traduções ocorre nos servidores da Apple. Dito isso, alguns dispositivos iOS mais recentes oferecem suporte à tradução sempre ativa no dispositivo de idiomas específicos.
A Apple incluiu uma API de disponibilidade para determinar se um determinado idioma está disponível para tradução no momento atual. O aplicativo deve usar essa API em vez de testar a conectividade com a Internet diretamente.
Conforme observado acima na seção Ditado do teclado, o reconhecimento de fala requer a transmissão e o armazenamento temporário de dados nos servidores da Apple pela Internet e, como tal, o aplicativo deve solicitar a permissão do usuário para realizar o reconhecimento incluindo a NSSpeechRecognitionUsageDescription chave em seu Info.plist arquivo e chamando o SFSpeechRecognizer.RequestAuthorization método.
Com base na fonte do áudio que está sendo usado para o Reconhecimento de Fala, outras alterações no arquivo do Info.plist aplicativo podem ser necessárias. Consulte nossa documentação de aprimoramentos de segurança e privacidade para obter detalhes.
Adotando o reconhecimento de fala em um aplicativo
Há quatro etapas principais que o desenvolvedor deve seguir para adotar o reconhecimento de fala em um aplicativo iOS:
- Forneça uma descrição de uso no arquivo do
Info.plistaplicativo usando aNSSpeechRecognitionUsageDescriptionchave. Por exemplo, um aplicativo de câmera pode incluir a seguinte descrição: "Isso permite que você tire uma foto apenas dizendo a palavra 'queijo'". - Solicite autorização chamando o
SFSpeechRecognizer.RequestAuthorizationmétodo para apresentar uma explicação (fornecida naNSSpeechRecognitionUsageDescriptionchave acima) do motivo pelo qual o aplicativo deseja acesso de reconhecimento de fala ao usuário em uma caixa de diálogo e permitir que ele aceite ou recuse. - Crie uma solicitação de reconhecimento de fala:
- Para áudio pré-gravado em disco, use a
SFSpeechURLRecognitionRequestclasse. - Para áudio ao vivo (ou áudio da memória), use a
SFSPeechAudioBufferRecognitionRequestclasse.
- Para áudio pré-gravado em disco, use a
- Passe a Solicitação de Reconhecimento de Fala para um Reconhecimento de Fala (
SFSpeechRecognizer) para iniciar o reconhecimento. Opcionalmente, o aplicativo pode manter o retornoSFSpeechRecognitionTaskpara monitorar e rastrear os resultados do reconhecimento.
Essas etapas serão abordadas em detalhes abaixo.
Fornecendo uma descrição de uso
Para fornecer a chave necessária NSSpeechRecognitionUsageDescription no arquivo, faça o Info.plist seguinte:
Clique duas vezes no
Info.plistarquivo para abri-lo para edição.Alterne para a guia Código-fonte:
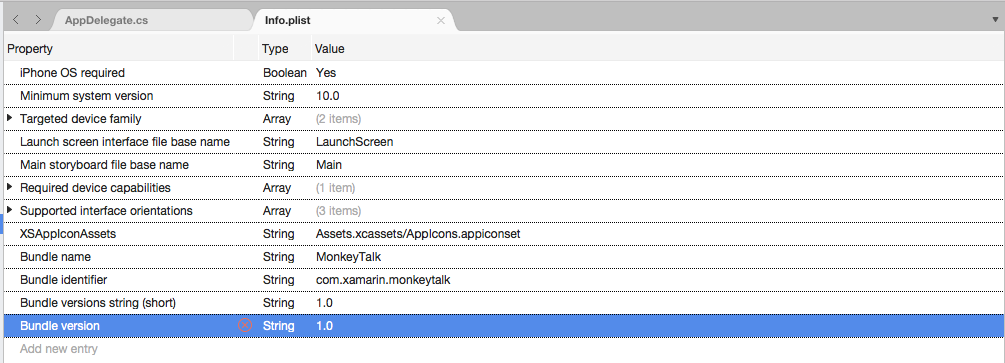
Clique em Adicionar Nova Entrada, insira
NSSpeechRecognitionUsageDescriptionpara a Propriedade,Stringpara o Tipo e uma Descrição de Uso como o Valor. Por exemplo: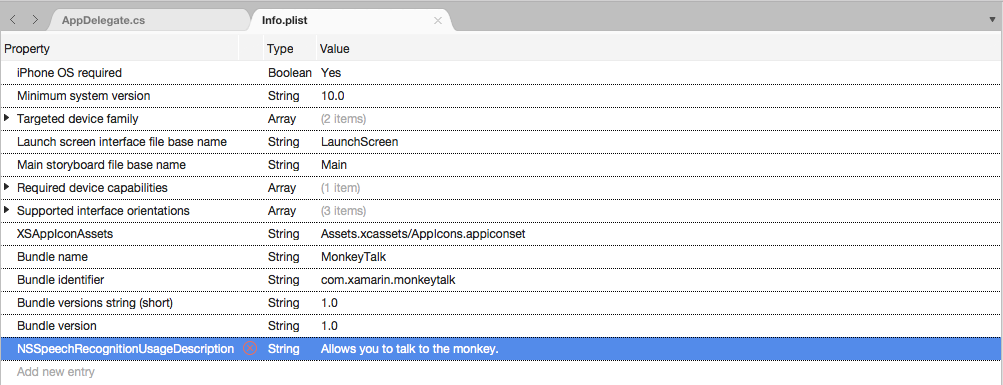
Se o aplicativo estiver lidando com a transcrição de áudio ao vivo, ele também exigirá uma descrição de uso do microfone. Clique em Adicionar Nova Entrada, insira
NSMicrophoneUsageDescriptionpara a Propriedade,Stringpara o Tipo e uma Descrição de Uso como o Valor. Por exemplo: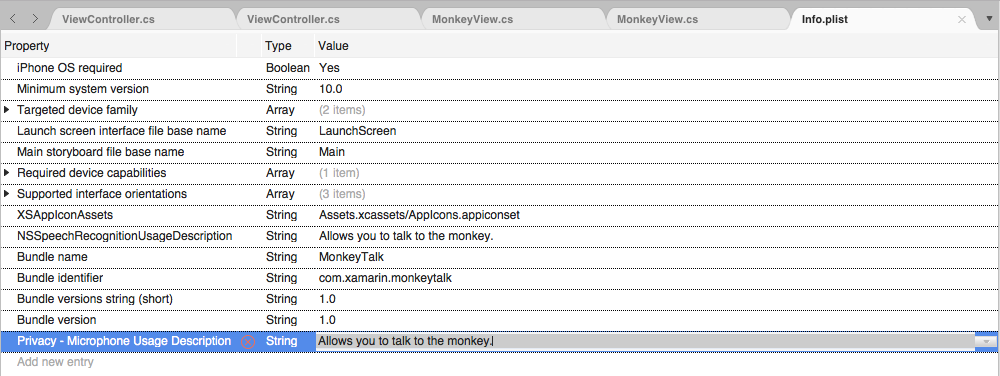
Salve as alterações no arquivo.





Importante
Se não fornecer uma das teclas acima Info.plist (NSSpeechRecognitionUsageDescription ou NSMicrophoneUsageDescription), pode resultar na falha do aplicativo sem aviso ao tentar acessar o Reconhecimento de Fala ou o microfone para áudio ao vivo.
Solicitando autorização
Para solicitar a autorização de usuário necessária que permite que o aplicativo acesse o reconhecimento de fala, edite a classe principal do Controlador de Exibição e adicione o seguinte código:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
O RequestAuthorization método da SFSpeechRecognizer classe solicitará permissão do usuário para acessar o reconhecimento de fala usando o motivo que o desenvolvedor forneceu na NSSpeechRecognitionUsageDescription chave do Info.plist arquivo.
Um SFSpeechRecognizerAuthorizationStatus resultado é retornado para a RequestAuthorization rotina de retorno de chamada do método que pode ser usada para executar uma ação com base na permissão do usuário.
Importante
A Apple sugere aguardar até que o usuário inicie uma ação no aplicativo que exija reconhecimento de fala antes de solicitar essa permissão.
Reconhecendo a fala pré-gravada
Se o aplicativo quiser reconhecer a fala de um arquivo WAV ou MP3 pré-gravado, ele poderá usar o seguinte código:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
Examinando esse código em detalhes, primeiro, ele tenta criar um Reconhecedor de Fala (SFSpeechRecognizer). Se o idioma padrão não tiver suporte para reconhecimento de fala, null será retornado e as funções serão encerradas.
Se o Reconhecimento de Fala estiver disponível para o idioma padrão, o aplicativo verificará se ele está disponível no momento para reconhecimento usando a Available propriedade. Por exemplo, o reconhecimento pode não estar disponível se o dispositivo não tiver uma conexão ativa com a Internet.
A SFSpeechUrlRecognitionRequest é criado a NSUrl partir do local do arquivo pré-gravado no dispositivo iOS e é entregue ao Reconhecedor de Fala para processar com uma rotina de retorno de chamada.
Quando o retorno de chamada é chamado, se não NSError null for, houve um erro que deve ser tratado. Como o reconhecimento de fala é feito de forma incremental, a rotina de retorno de chamada pode ser chamada mais de uma vez, de modo que a SFSpeechRecognitionResult.Final propriedade é testada para ver se a tradução está concluída e se a melhor versão da tradução é gravada (BestTranscription).
Reconhecendo a fala ao vivo
Se o aplicativo deseja reconhecer a fala ao vivo, o processo é muito semelhante ao reconhecimento da fala pré-gravada. Por exemplo:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
Olhando para este código em detalhes, ele cria várias variáveis privadas para lidar com o processo de reconhecimento:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Ele usa o AV Foundation para gravar áudio que será passado para um SFSpeechAudioBufferRecognitionRequest para lidar com a solicitação de reconhecimento:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
O aplicativo tenta iniciar a gravação e todos os erros são tratados se a gravação não puder ser iniciada:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
A tarefa de reconhecimento é iniciada e um identificador é mantido para a Tarefa de Reconhecimento (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
O retorno de chamada é usado de maneira semelhante ao usado acima na fala pré-gravada.
Se a gravação for interrompida pelo usuário, tanto o Mecanismo de Áudio quanto a Solicitação de Reconhecimento de Fala serão informados:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Se o usuário cancelar o reconhecimento, o Mecanismo de Áudio e a Tarefa de Reconhecimento serão informados:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
É importante chamar RecognitionTask.Cancel se o usuário cancelar a tradução para liberar memória e o processador do dispositivo.
Importante
Deixar de fornecer as NSSpeechRecognitionUsageDescription teclas ou NSMicrophoneUsageDescription Info.plist pode resultar na falha do aplicativo sem aviso ao tentar acessar o Reconhecimento de Fala ou o microfone para áudio ao vivo (var node = AudioEngine.InputNode;). Consulte a seção Fornecendo uma descrição de uso acima para obter mais informações.
Limites de reconhecimento de fala
A Apple impõe as seguintes limitações ao trabalhar com o Reconhecimento de Fala em um aplicativo iOS:
- O Reconhecimento de Fala é gratuito para todos os aplicativos, mas seu uso não é ilimitado:
- Dispositivos iOS individuais têm um número limitado de reconhecimentos que podem ser realizados por dia.
- Os aplicativos serão limitados globalmente com base na solicitação por dia.
- O aplicativo deve estar preparado para lidar com falhas de conexão de rede e limite de taxa de uso do Reconhecimento de Fala.
- O reconhecimento de fala pode ter um alto custo tanto no consumo de bateria quanto no alto tráfego de rede no dispositivo iOS do usuário, por isso, a Apple impõe um limite estrito de duração de áudio de aproximadamente um minuto de fala no máximo.
Se um aplicativo está atingindo rotineiramente seus limites de limitação de taxa, a Apple pede que o desenvolvedor entre em contato com eles.
Considerações sobre privacidade e usabilidade
A Apple tem a seguinte sugestão para ser transparente e respeitar a privacidade do usuário ao incluir o Reconhecimento de Fala em um aplicativo iOS:
- Ao gravar a fala do usuário, certifique-se de indicar claramente que a gravação está ocorrendo na interface do usuário do aplicativo. Por exemplo, o aplicativo pode reproduzir um som de "gravação" e exibir um indicador de gravação.
- Não use o Reconhecimento de Fala para informações confidenciais do usuário, como senhas, dados de saúde ou informações financeiras.
- Mostre os resultados do reconhecimento antes de agir sobre eles. Isso não apenas fornece comentários sobre o que o aplicativo está fazendo, mas permite que o usuário lide com erros de reconhecimento à medida que são cometidos.
Resumo
Este artigo apresentou a nova API de Fala e mostrou como implementá-la em um aplicativo Xamarin.iOS para dar suporte ao reconhecimento contínuo de fala e transcrever fala (de fluxos de áudio ao vivo ou gravados) em texto.