Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: 2013 2016 2019
2013 2016 2019  sharePoint Online no Microsoft 365
sharePoint Online no Microsoft 365
Melhorar a relevância de pesquisa, personalizar modelos de classificação para calcular os resultados de classificação (classificação de relevância) precisamente usando recursos de classificação no SharePoint.
Pode ordenar os resultados da pesquisa no SharePoint de quatro formas, uma das quais por classificação. Quando você classifica os resultados da pesquisa, classificação pontuação, o SharePoint coloca os resultados mais relevantes na parte superior do conjunto de resultados de pesquisa.
Um resultado de pesquisa é relevante se receber uma classificação de classificação elevada, que é uma classificação numérica específica calculada pelo motor de busca com um modelo de classificação. Um modelo de classificação é uma lista de uma ou mais fases de classificação que contêm um conjunto de funcionalidades de classificação. O modelo de classificação define como o motor de busca calcula a classificação de relevância com vários fatores, que são representados no modelo de classificação como funcionalidades de classificação. Os fatores utilizados para calcular a classificação de relevância incluem, mas não se limitam a, o seguinte:
- A aparência dos termos de consulta no índice de texto completo, que inclui informações como título e corpo de um documento.
- Os metadados associados a um item específico, como o tipo de arquivo ou o comprimento da URL de um documento.
- O texto de âncora associado links de URL que apontam para um item específico.
- As informações sobre o usuário clica para cada item.
- A proximidade de termos de consulta no corpo ou o título de um documento.
Iniciar sua classificação modelar personalização com base em um modelo do modelo de classificação do SharePoint
Para facilitar sua personalização, comece usando o padrão de modelos de classificação no SharePoint como um modelo. Sendo assim, modifique o modelo de classificação de acordo com seu conjunto de dados.
Por padrão, o SharePoint fornece 14 modelos de classificação. Consulte O que é um modelo de classificação? (no TechNet) para obter informações detalhadas sobre estes modelos de classificação e a sua finalidade.
Importante
Se você instalar a atualização cumulativa do Microsoft Office SharePoint Online de agosto de 2013, recomendamos o uso do Modelo de Classificação de Pesquisa com Dois Estágios Lineares como o modelo básico para seu modelo de classificação personalizado. O modelo de classificação de pesquisa com dois estágios Linear é uma cópia do modelo de pesquisa padrão com um segundo estágio linear em vez de um segundo estágio rede neural.
Use os seguintes cmdlets do Windows PowerShell para personalizar modelos de classificação:
- Get-SPEnterpriseSearchRankingModel
- New-SPEnterpriseSearchRankingModel
- Remove-SPEnterpriseSearchRankingModel
- Set-SPEnterpriseSearchRankingModel
Para listar os modelos de classificação disponíveis
- Abra o Shell de Gerenciamento do SharePoint como administrador.
- Execute a seguinte sequência de Windows PowerShell cmdlets.
$ssa = Get-SPEnterpriseSearchServiceApplication -Identity "Search Service Application"
$owner = Get-SPenterpriseSearchOwner -Level ssa
Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner
Para recuperar um modelo de classificação padrão a ser usado como um modelo
- Abra o Shell de Gerenciamento do SharePoint como administrador.
- Execute a seguinte sequência de cmdlets do Windows PowerShell; filename.xml é o nome de um ficheiro no qual pretende guardar o modelo de classificação.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$defaultRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner | Where-Object { $_.IsDefault -eq $True }
$defaultRankingModel.RankingModelXML > filename.xml
Se você instalar a atualização cumulativa de SharePoint Server de agosto de 2013, você pode usar o procedimento a seguir para recuperar o modelo de classificação de pesquisa com dois estágios lineares para usar como um modelo para seu modelo de classificação personalizada.
Para recuperar o modelo de classificação de pesquisa com dois estágios lineares como um modelo
- Abra o Shell de Gerenciamento do SharePoint como administrador.
- Execute a seguinte sequência de cmdlets do Windows PowerShell; filename.xml é o nome de um ficheiro no qual pretende guardar o modelo de classificação.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$twoLinearStagesRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -Identity 5E9EE87D-4A68-420A-9D58-8913BEEAA6F2
$twoLinearStagesRankingModel.RankingModelXML > filename.xml
Para implantar um modelo de classificação personalizada
Da lista de modelos de classificação disponíveis, copie o GUID do modelo de classificação que você deseja usar como modelo. (Consulte Para listar todos os modelos de classificação disponíveis para a sequência de cmdlets do Windows PowerShell a utilizar.)
Execute a seguinte sequência de cmdlets do Windows PowerShell com o GUID copiado no passo 1 para <GUID>.
$ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $rm = Get-SPEnterpriseSearchRankingModel -Identity <GUID> -SearchApplication $ssa -Owner $owner $rm.RankingModelXML > myrm.xmlEdite o
myrm.xmlficheiro num editor XML. Você deve usar os novos valores GUID para os atributos de id no elemento RankModel2Stage e todos os elementos de RankingModel2NN. Para obter um novo valor GUID, por exemplo você pode usar o seguinte comando Windows PowerShell:[guid]::NewGuid()Crie um novo modelo de classificação com o cmdlet New-SPEnterpriseSearchRankingModel ao executar os seguintes comandos.
$myRankingModel = Get-Content .\\myrm.xml $myRankingModel = [String]$myRankingModel $ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $newrm = New-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -RankingModelXML $myRankingModel
Detalhes de classificação
Importante
[!IMPORTANTE] Fornecemos o detalhe de classificação e a página de ExplainRank acompanha a conveniência e apenas para ajudá-lo no ajuste de depuração e seus próprios modelos de classificação personalizada. Os conteúdos de detalhes de classificação e a página de acompanhamento ExplainRank não tem suporte e estão sujeitos a alterações sem aviso prévio em futuras atualizações e patches de software.
O detalhe de classificação é um documento XML que fornece informações detalhadas sobre classificação pontuação cálculo para um único item que corresponda a uma consulta de determinado usuário. Os detalhes de classificação é armazenada em uma propriedade gerenciada especial, chamada rankdetail.
Cada recurso classificação em um modelo de classificação tem um nó XML separado nos detalhes da classificação que descreve os detalhes de classificação no cálculo de pontuação. Os detalhes de classificação é fornecido apenas para consultas que tem resultados de pesquisa que não ultrapasse 100 itens.
Conceitualmente, o formato geral dos detalhes classificação se parece com o exemplo a seguir.
<rank_log version='15.0.0000.1000' id='[internal guid of ranking model used for calculation]' >
<query tree='[representation of user query used for ranking]'/>
<stage type='linear'>
[Details of rank calculation of the first ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the first stage of the ranking model]
</stage_model>
</stage>
<stage type='neural_net' >
[Details of rank calculation of the second ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the second stage of the ranking model]
</stage_model>
</stage>
</rank_log>
Para recuperar os detalhes de classificação, você precisa ser o administrador do aplicativo de serviço de pesquisa (SSA).
Para recuperar os detalhes de classificação
- Abra o Shell de Gerenciamento do SharePoint como administrador.
- Execute a seguinte sequência de cmdlets do Windows PowerShell e substitua <query_text> e <url> pelos valores reais.
$app = Get-SPEnterpriseSearchServiceApplication
$searchAppProxy = Get-spenterprisesearchserviceapplicationproxy | Where-Object { ($_.ServiceEndpointUri.PathAndQuery -like $app.Uri.PathAndQuery)}
$request = New-Object Microsoft.Office.Server.Search.Query.KeywordQuery($searchAppProxy)
$request.ResultTypes = [Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults
$request.QueryText = "<query_text> AND path:""<url>"""
$request.SelectProperties.Add("rankdetail")
$searchexecutor = new-Object Microsoft.Office.Server.Search.Query.SearchExecutor
$resultTables = $searchexecutor.ExecuteQuery($request)
$resultTables[([Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults)].Table
Noções básicas sobre o cálculo da ordem de classificação pela página do ExplainRank
O SharePoint fornece a página ExplainRank que está localizada na pasta layouts ( <searchCenter>/_layouts/15/). Esta página contém informações detalhadas sobre a pontuação de classificação para cada recurso de classificação com base em uma consulta de pesquisa determinado, uma ID do documento e um ID do modelo de classificação opcional. A informação é obtida e analisada do detalhe de classificação.
Pode aceder à página ExplainRank com o seguinte URL: http://< searchCenter>/_layouts/15/ExplainRank.aspx?q={x}&d={y}&rm={z}
Onde:
- x é a consulta de pesquisa.
- y é o ID do documento.
- z é o ID do modelo de classificação opcional. Se nenhum ID de modelo de classificação for fornecido, o modelo de classificação padrão será usado.
Assim como com os detalhes de classificação, para exibir a página ExplainRank, você precisa ser o administrador do aplicativo de serviço de pesquisa (SSA).
Ajustar seu modelo de classificação com os recursos de classificação
Os recursos de classificação funcionam como ajuste mostradores para um modelo de classificação. As seções a seguir descrevem os recursos de classificação disponíveis no modelo de classificação padrão do SharePoint e como eles contribuem para o cálculo de classificação de relevância.
BM25
O recurso de classificação BM25 ordenará itens com base na aparência dos termos de consulta no índice de texto completo. A entrada de dados BM25 pode ser qualquer uma das propriedades gerenciadas no índice de texto completo.
Observação
O recurso de classificação BM25 usado nesse contexto é a versão por campo, BM25F.
O recurso de classificação BM25 calcula a pontuação de classificação de relevância usando a seguinte fórmula.
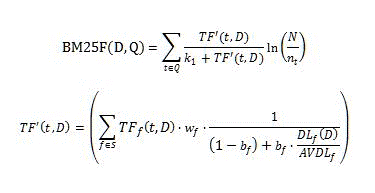
Onde:
- D é um documento, representado como uma lista de campos textuais, como o título ou o corpo.
- Q é a consulta do usuário, representada como uma lista de termos de consulta, t.
- S define a lista de campos que contribuem com a classificação de relevância; essa lista é definida pelo modelo de classificação.
- _w_f é um valor numérico que define a peso relativo do campo f ??? S; esse valor é definido pelo modelo de classificação.
- _b_f é um valor numérico que define a normalização de comprimento do documento para cada campo f ??? S.
- _TF_f (t, D) é o número de ocorrências de termos de consulta t no campo f do documento D.
- _DL_f (D) é o número total de palavras no campo f do documento D.
- N é a quantidade total de documentos no índice.
- _n_té um valor de documentos que têm o termo t em pelo menos uma das suas propriedades.
- _AVDL_fé a média _DL_f (D) para todos os documentos indexados.
- _k_1é um parâmetro escalar; Esse valor é definido pelo modelo de classificação.
Você deve mapear as propriedades gerenciadas usadas para o recurso de classificação BM25 ao índice de texto completo padrão na Escolha configurações pesquisáveis avançada da interface do usuário.
Em uma consulta do usuário, os termos de consulta que fazem parte dos seguintes operadores são excluídos dos cálculos de classificação de relevância: NOT(???) em FQL, NOT(???) em KQL e FILTER(???) em FQL.
Além disso, os termos de consulta que estão no âmbito, por exemplo, title:apple AND body:orange, são excluídos dos cálculos de classificação por relevância.
Exemplo de definição de característica de classificação BM25
<BM25Main name="ContentRank" k1="1">
<Layer1Weights>
<Weight>0.26236235707678</Weight>
</Layer1Weights>
<Properties>
<Property name="body" w="0.019391078235467" b="0.44402228898786156" propertyName="body" />
<Property name="Title" w="0.36096989709360422" b="0.38179554361297785" propertyName="Title" />
<Property name="Author" w="0.15808522836934547" b="0.13896219383271818" propertyName="Author" />
<Property name="Filename" w="0.15115036355698144" b="0.96245017871125826" propertyName="Filename" />
<Property name="QLogClickedText" w="0.3092664171701901" b="0.056446823262849853" propertyName="QLogClickedText" />
<Property name="AnchorText" w="0.021768362296187508" b="0.74173561196103566" propertyName="AnchorText" />
<Property name="SocialTag" w="0.10217215754116529" b="0.55968554315932328" propertyName="SocialTag" />
</Properties>
</BM25Main>
Exemplo de detalhe de classificação para o recurso de classificação BM25
<bm25 name='ContentRank'>
<schema pid_mapping='[1:content::7:%default] [2:content::1:%default] [3:content::5:%default] [56:content::2:%default] [100:content::3:link] [10:content::6:link] [264:content::14:link] ' pids_not_mapped=''/>
<query_term term='WORDS(content:integration, content:integrations, content:integrations)'>
<index name='content' N='10035' n='8'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.500486' weight='1'
tf='0 1 1 0 0 0 0 11 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='2.37967' score_acc='2.37967' term_weight='7.13439'/>
</query_term>
<query_term term='WORDS(content:effort, content:efforts, content:efforts)'>
<index name='content' N='10035' n='9'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'/>
<group id='link'/>
</index>
<rank score='0' score_acc='2.37967' term_weight='7.01661'/>
</query_term>
<query_term term='PHRASE(content:fastserver, content:plugin)'>
<index name='content' N='10035' n='3'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.0399696' weight='1'
tf='0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='0.311896' score_acc='2.69157' term_weight='8.11522'/>
</query_term>
<final score='2.69157' transformed='2.69157' normalized='2.69157' hidden_nodes_adds='0.706166 '/>
</bm25>
Grupos de peso
Em um modelo de classificação personalizada, você pode ter dois ou mais propriedades gerenciadas que são mapeadas para o mesmo grupo de peso no esquema de pesquisa. Nesses casos, o conteúdo dessas propriedades gerenciadas é combinado no índice de texto completo e não pode ser classificado separadamente no cálculo BM25. Este efeito é o mesmo que definir valores iguais para os parâmetros _w_f e _b_f dentro de cada grupo de propriedades geridas, mapeados para o mesmo grupo de peso no esquema de pesquisa. Para impedir isso, mapeie propriedades gerenciadas para um dos grupos diferentes de peso 16 disponíveis no esquema de pesquisa.
Grupos de peso também são conhecidos como contexto. Veja Influenciando a classificação dos resultados da pesquisa com o esquema de pesquisa (no TechNet) para obter mais informações sobre a relação entre uma propriedade gerida e o respetivo contexto.
Static
O recurso de classificação estático ordenará itens com base em numéricas propriedades gerenciadas que são armazenadas no índice de pesquisa. As propriedades geridas numéricas utilizadas para o cálculo de classificação por relevância nas funcionalidades de classificação estática têm de ser do tipo Número Inteiro e definidas como Refináveis ou Ordenáveis no esquema de pesquisa. Você não pode usar vários valores de propriedades gerenciadas em combinação com o recurso de classificação estática.
Antes do recurso de classificação estático possa ser agregado com outros recursos de classificação, cada recurso de classificação estático é preprocessado por meio de uma única transformação. A tabela 1 lista todas as funções de transformação com suporte.
Tabela 1. Funções de transformação suportadas para as funcionalidades de classificação estática e de proximidade
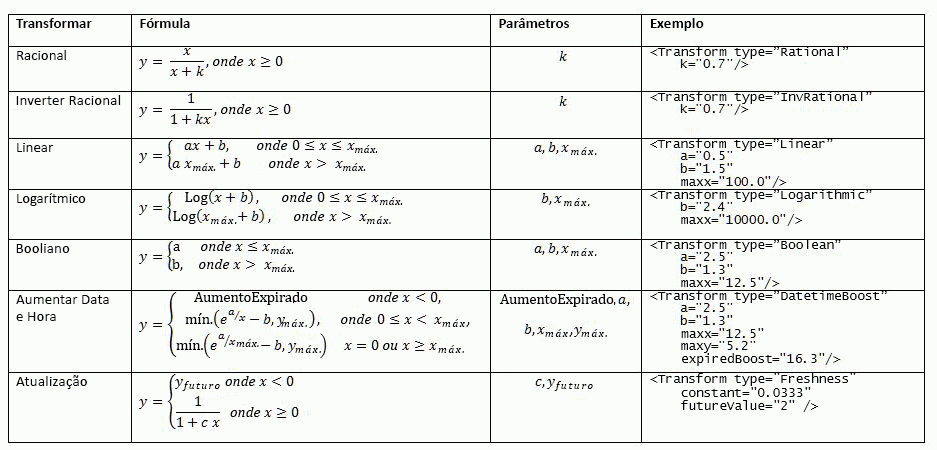
Exemplo de definição de recurso de classificação estática
<Static name="clickdistance" default="5" propertyName="clickdistance">
<Transform type="InvRational" k="0.27618729159042193" />
<Layer1Weights>
<Weight>0.616326852981262</Weight>
</Layer1Weights>
</Static>
Exemplo de detalhe de classificação para um recurso de classificação estática
<static_feature name='clickdistance' property_name='clickdistance'
used_default='1' raw_value='5' raw_value_transformed='5'
transformed='0.420003' normalized='0.420003'
hidden_nodes_adds='0.258859 '/>
Bucketed estático
O recurso de classificação estático bucketed ordenará documentos com base no seu tipo de arquivo e de idioma. A definição de um recurso de classificação estática bucketed dentro de um modelo de classificação depende se o recurso de classificação é parte de uma rede neural ou de um modelo linear. Os exemplos a seguir se aplicam apenas a modelos lineares. Para redes neurais, o número de <Add> atributos para cada registo tem de corresponder ao número de nós ocultos na rede neural.
As propriedades geridas utilizadas para o cálculo da classificação de relevância nas funcionalidades de classificação estática registada têm de ser do tipo Número Inteiro e definidas como Refináveis ou Ordenáveis no esquema de pesquisa. Você não pode usar vários valores de propriedades gerenciadas em combinação com o recurso de classificação estática bucketed.
Exemplo de definição de recurso de classificação estática em intervalos para o tipo de arquivo
Cada documento tem um tipo de ficheiro associado que o componente de processamento de conteúdos deteta e armazena no índice de pesquisa como um valor inteiro baseado em zero. Quando utiliza a funcionalidade de classificação estática registada para classificar documentos com base nos respetivos tipos de ficheiro, cada tipo de documento é associado a uma classificação de classificação de relevância específica. Por exemplo, na definição seguinte, o registo 2 corresponde a um documento .ppt; o nó <Add>0.680984743282165</Add> define pontos de classificação adicionais que são adicionados às classificações de relevância para todos os .ppt documentos.
<BucketedStatic name="InternalFileType" default="0" propertyName="InternalFileType">
<Bucket name="Html" value="0">
<HiddenNodesAdds>
<Add>0.464062832328107</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Doc" value="1">
<HiddenNodesAdds>
<Add>0.551558196047853</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Ppt" value="2">
<HiddenNodesAdds>
<Add>0.680984743282165</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xls" value="3">
<HiddenNodesAdds>
<Add>-0.143152682829863</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xml" value="4">
<HiddenNodesAdds>
<Add>-1.29219869408375</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Txt" value="5">
<HiddenNodesAdds>
<Add>-0.456669562992298</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ListItems" value="6">
<HiddenNodesAdds>
<Add>0.170944938307345</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Message" value="7">
<HiddenNodesAdds>
<Add>-0.0666769377412764</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Image" value="8">
<HiddenNodesAdds>
<Add>0.106988843357609</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
Exemplo de definição de recurso de classificação estática em intervalos para linguagem de documento
O componente de processamento do conteúdo detecta automaticamente o idioma para cada documento antes de ser adicionado ao índice de pesquisa. Quando você usa o recurso de classificação estático bucketed para documentos de classificação com base em sua língua, é possível definir como calcular a pontuação de classificação com base em se o idioma do documento que foi detectado automaticamente coincide com o idioma da consulta.
Em tempo de consulta, as informações sobre o idioma do usuário são gravadas ao mecanismo de pesquisa como uma propriedade de consulta.
Proximidade
O recurso de classificação de proximidade ordenará itens dependendo da distância entre os termos de consulta dentro do índice texto completo. A pontuação de classificação é Impulsionada se os dois termos de consulta aparecerem nas mesmas propriedades gerenciadas no índice texto completo. Cálculos de proximidade são caros em termos de atividade de disco e consumo de CPU; como resultado, o aumento de proximidade é realizado somente durante o segundo estágio do modelo de classificação padrão do SharePoint (se disponível).
Você pode avaliar o recurso de classificação de proximidade usando várias opções, controladas por atributos descritos na tabela 2.
Tabela 2. Atributos que controlam a avaliação das características de classificação de proximidade
| Atributos | Description |
|---|---|
isExact=0 |
Neste modo, o algoritmo de proximidade tenta localizar o período mínimo (distância) o subconjunto de termos de consulta em um documento. O algoritmo de proximidade considera fragmentos que contêm os termos de consulta no mesmos orders que eles aparecem na consulta de usuário. Se nenhum fragmento existe para todos os termos de consulta, o algoritmo de proximidade considera fragmentos que contêm tudo, exceto um dos termos da consulta. Este processo é iterado com o número de termos de consulta reduzidos de cada vez, até que o comprimento do fragmento exceda maxMinSpan. maxMinSpan é um atributo dentro do recurso de classificação de proximidade que especifica um limite definindo o comprimento máximo de um fragmento. Um fragmento ideal é aquele que contém todos os termos de consulta, mas é menor que maxMinSpan. |
isExact=1 |
Neste modo, o algoritmo de proximidade tenta localizar um trecho consecutivo de documento que contém todos os termos de consulta (ou a frase de consulta). |
isDiscounted |
Este atributo é aplicável a e isExact=1isExact=0. Quando isDiscounted está ativado, o valor de proximidade é multiplicado por esta fração: (número de ocorrências do melhor fragmento ou resultados exatos) dividido por (número de ocorrências do termo de consulta mais raro neste contexto). |
proximity="complete" |
Neste modo, o recurso de classificação de proximidade apenas aumenta a documentos onde o texto da consulta todo usuário ocorre dentro de uma propriedade gerenciada específica. |
proximity="perfect" |
Este modo é semelhante ao complete modo, mas é aplicado a campos curtos, como o título. O recurso de classificação de proximidade apenas aumenta a documentos onde o texto da consulta todo usuário corresponde a um exato title dentro de uma propriedade gerenciada específica. Se o title contém termos adicionais fora da consulta do usuário, o item não será considerado pelo algoritmo de proximidade. |
default |
Este atributo só se aplica a consultas de termos de único. Para itens que contêm o termo de consulta, o default valor é utilizado como resultado da classificação pela funcionalidade de classificação de proximidade. A perfect proximidade é uma exceção a esta regra. Para perfect proximidade, o valor padrão nunca é usado. Em vez disso, as consultas de termos de único são processadas da mesma maneira que outras consultas. |
Exemplo de definição de ordem de recurso de proximidade
O exemplo a seguir é um trecho do modelo de classificação padrão do SharePoint. Nesse modelo, o recurso de proximidade é apenas uma parte do cálculo de segundo estágio, que envolve uma rede neural. Por conseguinte, o exemplo contém vários elementos de peso, <LayerWeights>, que correspondem ao número de neurónios na camada oculta da rede neural.
<MinSpan name="Title_MinSpanExactDiscounted" default="0.43654446989518952" maxMinSpan="1" isExact="1" isDiscounted="1" propertyName="Title">
<Normalize SDev="0.20833333333333334" Mean="0.375" />
<Transform type="Linear" a="1" b="0" maxx="10000" />
<Layer1Weights>
<Weight>0.0399835450090479</Weight>
<Weight>-0.00693681478614802</Weight>
<Weight>0.0286196612755843</Weight>
<Weight>0.11775902923563</Weight>
<Weight>0.0885860088190342</Weight>
<Weight>0.102859503886488</Weight>
</Layer1Weights>
</MinSpan>
Você deve mapear propriedades gerenciadas usadas em recursos de classificação de proximidade para o índice de texto completo padrão no esquema de pesquisa.
Detalhe de exemplo de classificação para o recurso de classificação de proximidade
<proximity_feature name='Title_MinSpanExactDiscounted' pid='2'
proximity_type='exact_discounted'
used_default='0' raw_value='0' transformed='0'
normalized='-1.8'
hidden_nodes_adds='-0.0719704 0.0124863 -0.0515154 -0.211966 -0.159455 -0.185147 ' />
Dinâmica
O recurso de classificação dinâmico ordenará um item, dependendo se a propriedade de consulta corresponde a uma determinada propriedade gerenciada. Se houver uma correspondência, a pontuação de posição do item é multiplicada com um valor específico para distinguir esse item. O atributo de peso é usado para controlar o quanto esse recurso afeta a pontuação geral de classificação.
Observação
O recurso de classificação dinâmico não é personalizável; é apenas para uso interno. No entanto, se você instalar a atualização cumulativa do de SharePoint de agosto de 2013, o recurso de classificação AnchortextComplete é um recurso personalizável de classificação dinâmico que faz parte do modelo de classificação padrão.
Exemplo de definição de recurso de classificação dinâmico
<Dynamic name="AnchortextComplete" pid="501" default="0" property="AnchortextCompleteQueryProperty">
<Transform type="Rational" k="0.91495552365614574" />
<Layer1Weights>
<Weight>0.715419978898093</Weight>
</Layer1Weights>
</Dynamic>
Atualização
O modelo de classificação padrão do SharePoint não aumenta a classificação de resultados da pesquisa com base em sua atualização. Você poderá fazer isso adicionando um novo recurso de classificação estático que combina informações do gerenciamento de propriedades LastModifiedTime com a propriedade consulta DateTimeUtcNow, usando a função de transformar atualização. A função de transformação de atualização é a única transformação que você pode usar para esse recurso de classificação de atualização, pois converte a idade do item de uma representação interna em dias..
A transformação de atualização se baseia na seguinte fórmula:
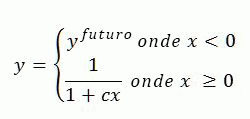
Onde:
- c e _y_Futurosão definidos no modelo de classificação.
- x é a idade de um item em dias.
- O valor de _y_future define o aumento de atualização para itens com LastModifiedTime superior à data e hora atuais.
Exemplo de definição de recurso de classificação de atualização
<Static name='freshboost' propertyName='LastModifiedTime' default='-1' convertPropertyToDatetime='1' rawValueTransform='compare' property='DateTimeUtcNow'>
<Transform type="Freshness" constant="0.0333" futureValue="2" />
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
Detalhe de classificação de exemplo para recurso de classificação de atualização usando um documento antigo (aproximadamente 580 dias)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115930137649186' raw_value='9.80661e+018' raw_value_transformed='-5.03135e+014' transformed='0.0490396' normalized='0.0490396' hidden_nodes_adds='0.0490396 '/>
Detalhes de classificação de exemplo para a funcionalidade de classificação de atualização com um novo documento (<1 dia)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115934928966979' raw_value='9.80712e+018' raw_value_transformed='-2.55529e+011' transformed='0.990248' normalized='0.990248'hidden_nodes_adds='0.990248 '/>
Agregação de recursos de classificação
Um modelo de classificação consiste em vários recursos de classificação que são considerados juntos para calcular uma pontuação de classificação.
Modelos de classificação de dois estágios
Um modelo de classificação pode ter dois estágios de classificação. No primeiro estágio, o modelo de classificação se aplica a recursos de classificação relativamente baratos para fazer a classificação bruta dos resultados. No segundo estágio, o modelo de classificação se aplica a recursos de classificação mais caros e adicionais aos itens com as pontuações de classificação mais altos.
O modelo de classificação padrão do SharePoint é um exemplo de modelo de classificação de dois estágios. Nesse modelo, o segundo estágio funciona com os primeiros 1000 itens com a pontuação de classificação maior que resulta do primeiro estágio.
Quando o processo de classificação no primeiro estágio estiver concluído, o mecanismo de pesquisa novamente classifica todos os itens, incluindo os itens que foram excluídos do segundo estágio. Isso geralmente resulta em itens do que o segundo estágio tendo um inferior classificação pontuação, quando comparada aos itens no primeiro estágio.
No entanto, para garantir que o mecanismo de pesquisa novamente classifica os itens com precisão, itens de segundo estágio devem ter uma pontuação maior de classificação que itens a partir do primeiro estágio. Para resolver esse dilema, são aumentou o as pontuações de classificação de segundo estágio. O mecanismo de pesquisa executa esse cálculo automaticamente, com base em uma combinação dos recursos de classificação.
Observação
Se você instalar a atualização cumulativa do SharePoint de agosto 2013, o modelo de classificação padrão usa um primeiro estágio linear e um segundo estágio neural de rede. O modelo de classificação de pesquisa com dois estágios Linear é uma cópia do modelo de pesquisa padrão com dois estágios lineares. É recomendável usar esse modelo como modelo básico de seu modelo de classificação personalizada, porque é mais fácil de ajustar um modelo de um modelo com uma rede neural linear.
Modelo linear
O modelo de capa para define uma combinação de linear de pontuações de posição de recursos de classificação.
A pontuação de posição fornecida pelo modelos lineares é calculada usando a seguinte fórmula:
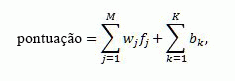
Onde:
- score é a pontuação de posição de saída produzida pelo modelo linear.
- M é o número de recursos de classificação excluindo bucketed recursos de classificação estáticos.
- K é o número de recursos de classificação estáticos com intervalos.
- _f_Sé o valor da _j_threcurso depois da transformação.
- _w_Sé o peso de contribuição de _j_threcurso para a combinação de linear.
Rede neural
Rede neural define uma combinação dos resultados de classificação dos recursos de classificação. Atualmente, o SharePoint fornece suporte para neurais redes que são limitadas a camada oculta com até oito neurônios.
A pontuação de classificação produzida pela rede neural é calculada usando a seguinte fórmula:
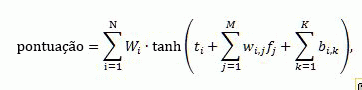
Onde:
- score é a pontuação de posição de saída produzida pela rede neural.
- N é o número de neurônios na camada de oculto da rede neural.
- M é o número de recursos de classificação, excluindo bucketed recursos de classificação estáticos.
- K é o número de recursos de classificação estáticos bucketed.
- _W_ié o peso de contribuição de _i_thneurônio oculto.
- _t_ié o limite de _i_thneurônio oculto.
- _W_i,Sé o peso de contribuição de _j_threcurso de _i_thneurônio oculto.
- _b_i,Cé a adição do _k_threcurso estático bucketed _i_thneurônio oculto.
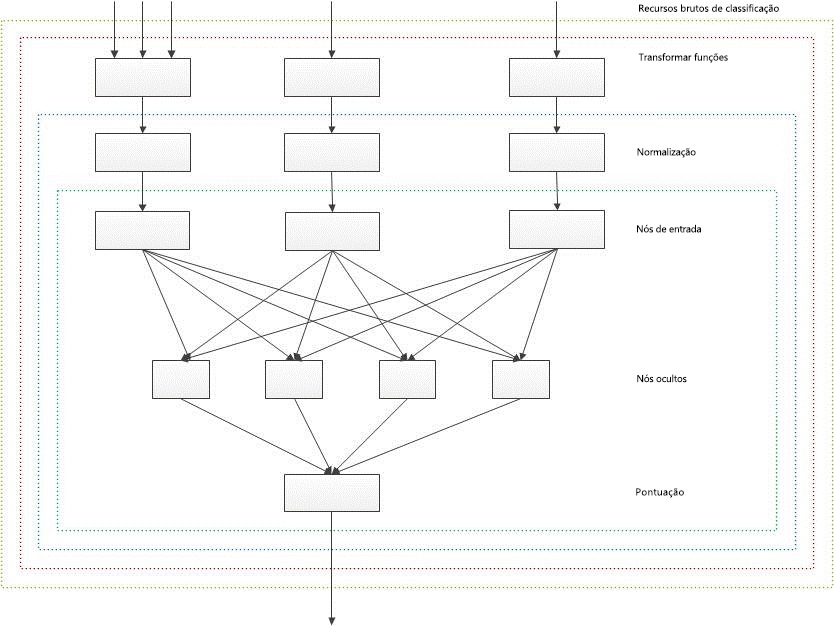
O esquema geral da classificação de computação de pontuação com uma rede neural de duas camadas é representada no diagrama a seguir. Este diagrama não considera o recurso classificação estático bucketed que contribui para redes neurais adicionando valores personalizados diretamente para nós ocultos, sem qualquer transformação ou a normalização.
Figura 1. Esquema geral de computação de pontuação de classificação com uma rede neural de duas camadas
Pré-cálculo em BM25 e recursos de classificação estáticos
Em um modelo de classificação, BM25 e recursos de classificação estáticos podem beneficiar precalculations para melhorar a latência da consulta para os termos de consulta que ocorrem frequentemente em itens. Essa melhoria de latência de consulta é obtida com o custo de indexação adicionais, em termos de espaço em disco usado pelo índice de pesquisa e consumo de CPU.
Você deve usar pré-cálculo apenas no primeiro estágio de um modelo de classificação. Consequentemente, se pré-cálculo estiver habilitado, os detalhes de classificação do primeiro estágio não será concluída.
Para habilitar o pré-cálculo, defina o atributo precalcEnabled como 1 na definição do estágio de classificação. Você só pode usar o pré-cálculo uma vez em um modelo de classificação.
Propriedades da consulta
Propriedades da consulta é um mecanismo de classificação que preenche informações adicionais úteis para classificação pontuação cálculo. Por exemplo, as propriedades da consulta podem ser a hora e data quando a consulta foi executada, que pode ser usada pelo recurso de classificação de atualização. A tabela 3 relaciona as propriedades de consulta disponíveis para a classificação. Você não pode configurar propriedades da consulta.
Tabela 3. Propriedades de consulta para classificação
| Propriedade Query | Description |
|---|---|
| AnchortextCompleteQueryProperty |
Aumenta conclua a âncora de texto. |
| DateTimeUtcNow |
Data e hora atuais. Esta propriedade de consulta pode ser usada pelo recurso de classificação de atualização. |
| DetectedLanguageRanking |
ID da linguagem de consulta. Esta propriedade de consulta é usada pelo recurso de classificação de DetectedLanguageRanking. |
| PersonalizationData |
Classificações de dados personalizados. |
| RecommendedforQueryProperty |
Classifica as recomendações. |
Exemplo 1: Modelo de classificação básica com um estágio linear contendo um único recurso de classificação estático
Este modelo de classificação pressupõe que o cliente tiver criado uma propriedade gerenciada nomeada CustomRating. O recurso de classificação estático requer CustomRating para ser do tipo de dados Integer e ser configurado como Sortable ou Refinable no esquema de pesquisa. Para cada documento no conjunto de resultados, a pontuação de posição produzida por esse modelo de classificação é igual ao valor de CustomRating para o documento. O efeito desse modelo é semelhante à classificação de todos os resultados da pesquisa, em ordem decrescente, com o CustomRating a propriedade gerenciada.
<?xml version="1.0"?>
<RankingModel2Stage name="RankModel1"
description="Rank model -- example 1"
id="D3FAF680-D213-4916-A95A-0409031643F8"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="619F2ECD-24F7-41CD-824C-234FC2EFDDCA" precalcEnabled="0" >
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<Static name="CustomRating" propertyName="CustomRating" default="0.0">
<Transform type="Linear" a="1" b="0" maxx="1000"/>
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Exemplo 2: Modelo de classificação mais complexa com um estágio linear e quatro recursos de classificação
Este modelo de classificação com um estágio linear contém estes quatro recursos de classificação:
BM25Esta funcionalidade de classificação baseia-se nas propriedades geridas Título e corpo; owatributo para título é definido para que os resultados dos termos de consulta em Título sejam duas vezes (2x) mais importantes do que os resultados dos termos de consulta no corpo.UrlDepthEsse recurso classificação baseia-se na propriedade UrlDepth gerenciados, que está disponível por padrão em instalações do SharePoint. UrlDepth contém o número de barras invertidas (\) no URL de um documento. A transformação inversa racional (InvRational) garante que documentos com URLs mais curtos recebem pontuações de posição maiores.TitleProximityEsse recurso classificação aumenta documentos se alguns dos termos de consulta ocorrem próximas umas das outras a title desses documentos.InternalFileTypeEsse recurso classificação aumenta a documentos do tipo HTML, DOC, XLS ou PPT. Os nomes das partições de memória de na definição do modelo de classificação são fornecidos para facilitar a leitura apenas.Observação
A
InternalFileTypepropriedade gerida, disponível por predefinição, utiliza o valor zero (0) para codificar documentos HTML, valor1para DOC, valor2para XLS e assim sucessivamente. Consulte a definição do modelo de classificação do SharePoint padrão para obter uma lista de todos os tipos de arquivo usado para a propriedade FileType gerenciados.
<?xml version="1.0"?>
<RankingModel2Stage name=" RankModel2"
description="Rank model -- example 2"
id="DE48A3A1-67CE-44A2-9712-E8A5128787CF"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="A0A030D1-805D-437E-A001-CC151ED7473A" precalcEnabled="0">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<BM25Main name="BM25" k1="1">
<Layer1Weights>
<Weight>1</Weight>
</Layer1Weights>
<Properties>
<Property name="Title" propertyName="Title" w="2" b="0.5" />
<Property name="body" propertyName="body" w="1" b="0.5" />
</Properties>
</BM25Main>
<Static name="UrlDepth" propertyName="UrlDepth" default="1">
<Transform type="InvRational" k="1.5"/>
<Layer1Weights>
<Weight>0.5</Weight>
</Layer1Weights>
</Static>
<MinSpan name="TitleProximity" propertyName="Title" default="0" maxMinSpan="1" isExact="0" isDiscounted="0">
<Normalize SDev="1" Mean="0"/>
<Transform type="Linear" a="1" b="-0.5" maxx="2"/>
<Layer1Weights>
<Weight>1.2</Weight>
</Layer1Weights>
</MinSpan>
<BucketedStatic name="InternalFileType" propertyName="InternalFileType" default="0">
<Bucket name="http" value="0">
<HiddenNodesAdds>
<Add>1.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="doc" value="1">
<HiddenNodesAdds>
<Add>2.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ppt" value="2">
<HiddenNodesAdds>
<Add>0.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="xls" value="3">
<HiddenNodesAdds>
<Add>-3.5</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Confira também
- Pesquisa no SharePoint
- Referência de sintaxe da Linguagem de Consulta de Palavra-chave (KQL)
- Referência de sintaxe de Linguagem de consulta RÁPIDA (FQL)
- Visão geral do resultado de pesquisa de classificação no SharePoint Server
- Criar um modelo de classificação personalizada usando o aplicativo de Ajuste do Modelo de Classificação