Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Os Clusters de Big Data do Microsoft SQL Server 2019 foram desativados. O suporte para clusters de Big Data do SQL Server 2019 terminou em 28 de fevereiro de 2025. Para obter mais informações, consulte a postagem no blog de anúncios e as opções de Big Data na plataforma microsoft SQL Server.
Este tutorial demonstra como carregar e executar um notebook no Azure Data Studio em um cluster de Big Data do SQL Server 2019. Isso permite que os cientistas e os engenheiros de dados executem código Python, R ou Scala no cluster.
Tip
Se preferir, você poderá baixar e executar um script para os comandos neste tutorial. Para obter instruções, confira os Exemplos do Spark no GitHub.
Prerequisites
-
Ferramentas de Big Data
- kubectl
- Azure Data Studio
- Extensão do SQL Server 2019
- Carregar dados de exemplo em seu cluster de Big Data
Baixar o arquivo de notebook de exemplo
Use as instruções a seguir para carregar o arquivo de notebook de exemplo spark-sql.ipynb no Azure Data Studio.
Abra um prompt de comando do bash (Linux) ou o Windows PowerShell.
Navegue até um diretório no qual você deseja baixar o arquivo de notebook de exemplo.
Execute o seguinte comando de rotação para baixar o arquivo do notebook do GitHub:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Abrir o notebook
As etapas a seguir mostram como abrir o arquivo do notebook no Azure Data Studio:
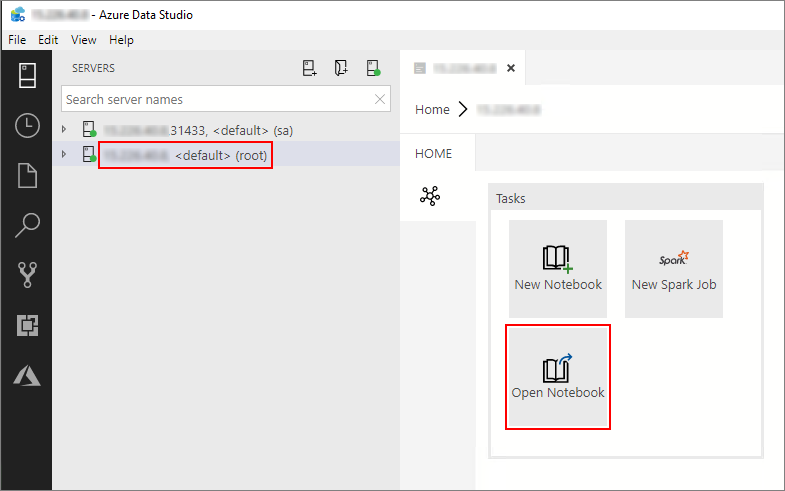
No Azure Data Studio, conecte-se à instância mestre do cluster de Big Data. Para obter mais informações, confira Conectar-se a um cluster de Big Data.
Clique duas vezes na conexão do gateway HDFS/Spark na janela Servidores. Em seguida, selecione Abrir Notebook.
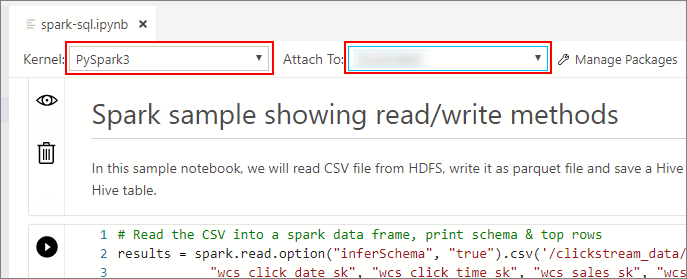
Aguarde até que o Kernel e o contexto de destino (Anexar a) sejam preenchidos. Defina o Kernel como PySpark3 e defina Anexar a como o endereço IP do seu ponto de extremidade do cluster de Big Data.
Important
No Azure Data Studio, todos os tipos de notebook Spark (Scala Spark, PySpark e SparkR) definem convencionalmente algumas variáveis importantes relacionadas à sessão do Spark após a execução da primeira célula. Essas variáveis são: spark, sc e sqlContext. Ao copiar a lógica de notebooks para envio em lote (por exemplo, em um arquivo Python para executar com azdata bdc spark batch create), defina as variáveis de acordo.
Executar as células do notebook
Você pode executar cada célula do notebook pressionando o botão Reproduzir à esquerda da célula. Os resultados são mostrados no notebook após a conclusão da execução da célula.

Execute cada uma das células no notebook de exemplo sucessivamente. Para obter mais informações sobre como usar notebooks com Clusters de Big Data do SQL Server, confira os seguintes recursos:
Next steps
Saiba mais sobre os notebooks: