Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: ![]() SQL Server
SQL Server
No SQL Server 2012 e 2014, a única maneira de inicializar uma réplica secundária em um grupo de disponibilidade do SQL Server Always On é usar o backup, a cópia e a restauração. O SQL Server 2016 apresenta um novo recurso para inicializar uma réplica secundária – a propagação automática. A propagação automática usa o transporte de fluxo de log para transmitir o backup usando a VDI para a réplica secundária de cada banco de dados do grupo de disponibilidade, usando os pontos de extremidade configurados. Esse novo recurso pode ser usado durante a criação inicial de um grupo de disponibilidade ou quando um banco de dados é adicionado a um. A propagação automática é encontrada em todas as edições do SQL Server que dão suporte a grupos de disponibilidade AlwaysOn e pode ser usada com grupos de disponibilidade tradicionais e grupos de disponibilidade distribuídos.
Segurança
As permissões de segurança variam de acordo com o tipo de réplica que está sendo inicializado:
- Para um grupo de disponibilidade tradicional, devem ser concedidas permissões ao grupo de disponibilidade na réplica secundária quando ele é ingressado no grupo de disponibilidade. No Transact-SQL, use o comando
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE. - Para um grupo de disponibilidade distribuído em que os bancos de dados da réplica que estão sendo criados estão na réplica primária do segundo grupo de disponibilidade, não é necessária nenhuma permissão extra porque essa réplica já é primária. No entanto, se houver apenas uma réplica no segundo grupo de disponibilidade, conceda a permissão
CREATE ANY DATABASEao nome do grupo de disponibilidade secundário ou a propagação automática poderá falhar. - Em uma réplica secundária no segundo grupo de disponibilidade de um grupo de disponibilidade distribuído, você deve usar o comando
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASE. Essa réplica secundária é propagada da réplica primária do segundo grupo de disponibilidade.
Impacto do log de transações e de desempenho sobre a réplica primária
A propagação automática pode ou não ser prática para inicializar uma réplica secundária, dependendo do tamanho do banco de dados, da velocidade da rede e da distância entre as réplicas primária e secundária. Por exemplo, considerando que:
- O tamanho do banco de dados é de 5 TB
- A velocidade da rede é de 1Gb/s
- A distância entre os dois sites é de 1.000 milhas
Se a largura de banda total estiver disponível, a rede de 1 GB/s poderá fornecer uma taxa de transferência prolongada de 125 MB/s. Neste exemplo, a propagação automática levará um pouco mais de 11 horas. Na prática, o processo de propagação automática é mais lento, pois os sinais da rede são degradados em distâncias mais longas e o link é compartilhado com outros recursos na rede. Durante a propagação, o log de transações no banco de dados da réplica primária continua crescendo e não pode ser truncado até que a propagação automática do banco de dados seja concluída. Em seguida, o log de transações pode ser truncado usando um backup de log de transações.
A propagação automática é um processo single-threaded que pode manipular até cinco bancos de dados. O threading simples afetará o desempenho, especialmente se o grupo de disponibilidade tiver mais de um banco de dados.
A compactação pode ser usada para a propagação automática, mas ela está desabilitada por padrão. A ativação da compactação reduz a largura de banda de rede e, possivelmente, acelera o processo, mas a desvantagem é a sobrecarga adicional do processador. Para usar a compactação durante a propagação automática, habilite o sinalizador de rastreamento 9567 – consulte Ajustar a compactação do grupo de disponibilidade.
Layout de disco
No SQL Server 2016 e nas versões anteriores, a pasta na qual o banco de dados é criado pela propagação automática já deve existir e ser a mesma que a do caminho da réplica primária.
No SQL Server 2017, a Microsoft recomenda usar os mesmos dados e o mesmo caminho do arquivo de log em todas as réplicas que participam de um grupo de disponibilidade, mas você poderá usar caminhos diferentes, se for necessário. Por exemplo, em um grupo de disponibilidade de plataforma cruzada, uma instância do SQL Server está no Windows e a outra instância do SQL Server está no Linux. As plataformas diferentes têm caminhos padrão diferentes. O SQL Server 2017 dá suporte para réplicas de grupo de disponibilidade em instâncias do SQL Server com caminhos padrão diferentes.
A tabela a seguir apresenta exemplos dos layouts de disco de dados compatíveis que podem dar suporte à propagação automática:
| Instância primária Caminho de dados padrão |
Instância secundária Caminho de dados padrão |
Instância primária Local do arquivo de origem |
Instância secundária Local do arquivo de destino |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Os cenários em que a localização do banco de dados da réplica primária e da secundária não forem os caminhos padrão da instância não serão afetados por esta alteração. Os requisitos para os caminhos de arquivo da réplica secundária serem compatíveis com os caminhos do arquivo da réplica primária permanecem os mesmos.
| Instância primária Caminho de dados padrão |
Instância secundária Caminho de dados padrão |
Instância primária Local do arquivo |
Instância secundária Local do arquivo |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
Se você mesclar os caminhos que estiverem dentro e fora do padrão nas réplicas primária e secundária, o SQL Server 2017 se comportará de forma diferente das versões anteriores. A tabela a seguir mostra o comportamento do SQL Server 2017.
| Instância primária Caminho de dados padrão |
Instância secundária Caminho de dados padrão |
Instância primária Local do arquivo |
SQL Server 2016 Instância secundária Local do arquivo |
SQL Server 2017 Instância secundária Local do arquivo |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
Para reverter para o comportamento do SQL Server 2016 e anteriores, habilite o sinalizador de rastreamento 9571. Para obter informações sobre como habilitar o sinalizador de rastreamento, consulte DBCC TRACEON (Transact-SQL).
Criar um grupo de disponibilidade com propagação automática
Crie um grupo de disponibilidade usando a propagação automática com o Transact-SQL ou o SSMS (SQL Server Management Studio, versão 17 ou posterior). Para usar o Assistente do Grupo de Disponibilidade no SSMS, siga estas instruções – quando chegar à Etapa 9, você verá a propagação automática como a primeira opção padrão.
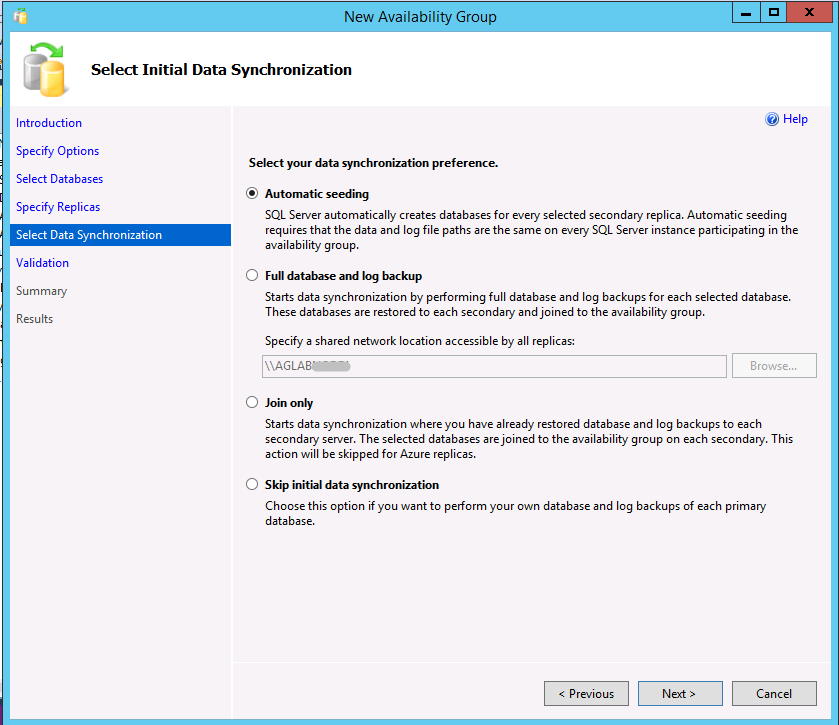
O exemplo a seguir cria um grupo de disponibilidade com a propagação automática usando o Transact-SQL. Consulte também o tópico Criar um grupo de disponibilidade (Transact-SQL). A propagação é habilitada em uma réplica secundária ao configurar a opção SEEDING_MODE como AUTOMATIC. O comportamento padrão é MANUAL, que é o comportamento pré-SQL Server 2016, que exige um backup do banco de dados na réplica primária, uma cópia do arquivo de backup na réplica secundária e uma restauração do backup com WITH NORECOVERY.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
A configuração SEEDING_MODE em uma réplica primária durante uma instrução CREATE AVAILABILITY GROUP não tem nenhum efeito porque a réplica primária já contém a cópia principal de leitura/gravação do banco de dados. SEEDING_MODE se aplica apenas quando outra réplica foi feita na primária e um banco de dados foi adicionado. O modo de propagação pode ser alterado posteriormente – consulte Alterar o modo de propagação de uma réplica.
Em uma instância que se torna uma réplica secundária, depois que a instância é ingressada, a seguinte mensagem de erro é adicionada ao Log do SQL Server:
A réplica de disponibilidade local do grupo de disponibilidade ‘AGName’ não recebeu permissão para criar bancos de dados, mas tem um
SEEDING_MODEdoAUTOMATIC. UseALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEpara permitir a criação de bancos de dados propagados pela réplica de disponibilidade primária.
Conceder permissão para criar banco de dados na réplica secundária do grupo de disponibilidade
Depois de ingressar, conceda permissão ao grupo de disponibilidade para criar bancos de dados na instância da réplica secundária do SQL Server. Para que a propagação automática funcione, o grupo de disponibilidade precisa ter permissão para criar um banco de dados.
Dica
Quando o grupo de disponibilidade cria um banco de dados em uma réplica secundária, ele define "sa" (mais especificamente, a conta com sid 0x01) como o proprietário do banco de dados.
Para alterar o proprietário do banco de dados depois que uma réplica secundária criar um banco de dados automaticamente, use ALTER AUTHORIZATION. Consulte ALTER AUTHORIZATION (Transact-SQL).
O exemplo a seguir concede esta permissão para o grupo de disponibilidade chamado AGName.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
Se for necessário, defina o proprietário do banco de dados na réplica secundária.
Verifique a propagação automática
Se ela for bem-sucedida, os bancos de dados serão criados automaticamente na réplica secundária com o estado:
- SYNCHRONIZED se a réplica secundária for configurada para ser síncrona e os dados estiverem sincronizados.
- SYNCHRONIZING se a réplica secundária for configurada com a movimentação de dados assíncrona ou quando configurada com síncrona, mas ainda não for sincronizada com a réplica primária.
Além das Exibições de Gerenciamento Dinâmico descritas abaixo, o início e a conclusão da propagação automática podem ser vistos no Log do SQL Server:

Combinar o backup e a restauração com a propagação automática
É possível combinar o backup, a cópia e a restauração tradicionais com a propagação automática. Nesse caso, primeiro restaure o banco de dados em uma réplica secundária, incluindo todos os logs de transações disponíveis. Em seguida, habilite a propagação automática ao criar o grupo de disponibilidade para atualizar o banco de dados da réplica secundária, como se um backup da parte final do log fosse restaurado [confira Backups da parte final do log (SQL Server)].
Adicionar um banco de dados a um grupo de disponibilidade com propagação automática
Adicione um banco de dados a um grupo de disponibilidade usando a propagação automática com o Transact-SQL ou o SSMS (SQL Server Management Studio, versão 17 ou posterior).
Se a réplica secundária usou a propagação automática quando foi adicionada ao grupo de disponibilidade, nenhuma tarefa adicional precisará ser realizada. Se a réplica secundária tiver utilizado backup, cópia e restauração, primeiro altere o modo de propagação (consulte a próxima seção) e, em seguida, ao adicionar o banco de dados, use a instrução GRANT – consulte Grupo de disponibilidade – adicionar um banco de dados.
Alterar o modo de propagação de uma réplica
O modo de propagação de uma réplica pode ser alterado depois que o grupo de disponibilidade é criado e, portanto, a propagação automática pode ser habilitada ou desabilitada. A habilitação da propagação automática após a criação permite que um banco de dados seja adicionado ao grupo de disponibilidade usando a propagação automática, caso ele tenha sido criado com o backup, a cópia e a restauração. Por exemplo:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
Para desabilitar a propagação automática, use o valor MANUAL.
Impedir a propagação automática após a criação de um grupo de disponibilidade
Se você não desejar desabilitar por completo a propagação automática de uma réplica secundária, mas desejar impedir temporariamente que a réplica secundária consiga criar bancos de dados automaticamente, negue a permissão CREATE do grupo de disponibilidade. Esse é o caso quando um novo banco de dados é adicionado ao grupo de disponibilidade, mas o grupo de disponibilidade não deve ter permissão para criar o banco de dados em uma réplica secundária.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Monitorar a propagação automática
Há quatro maneiras de monitorar e solucionar problemas da propagação automática:
- Log do SQL Server, conforme já descrito
- Exibições de gerenciamento dinâmico
- Tabelas de histórico de backup
- Eventos estendidos
Exibições de Gerenciamento Dinâmico
Há dois modos de exibição de gerenciamento dinâmico (DMVs) para monitorar a propagação: sys.dm_hadr_automatic_seeding e sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingcontém o status geral da propagação automática e retém o histórico de cada vez que ela for executada (com êxito ou não). A colunacurrent_stateterá um valor COMPLETED ou FAILED. Se o valor for FAILED, use o valor emfailure_state_descpara ajudar a diagnosticar o problema. Talvez você precise combinar isso com o conteúdo do Log do SQL Server para ver o que deu errado. Essa DMV é populada na réplica primária e em todas as réplicas secundárias.sys.dm_hadr_physical_seeding_statsmostra o status da operação de propagação automática durante a execução. Assim como acontece comsys.dm_hadr_automatic_seeding, ele retorna valores para as réplicas primária e secundária, mas o histórico não é armazenado. Os valores se referem apenas à execução atual e não são retidos. As colunas de interesse incluemstart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_ms,total_network_wait_time_mse, se a operação de propagação falhar, failure_message.
Tabelas de histórico de backup
A propagação automática também coloca as entradas nas tabelas msdb, que armazenam o histórico de backups e restaurações. Na réplica secundária que está recebendo a propagação automática, a coluna physical_device_name da tabela backupmediafamily tem um GUID para seu valor e a entrada correspondente em backupset tem o nome da réplica primária de server_name e machine_name.
Eventos estendidos
A propagação automática adiciona novos eventos estendidos para controlar a alteração de estado, as falhas e as estatísticas de desempenho durante a inicialização. Por exemplo, o script a seguir cria uma sessão de eventos estendidos que captura eventos relacionados à propagação automática.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
A tabela a seguir lista os eventos estendidos relacionados à propagação automática.
| Nome | Descrição |
|---|---|
| hadr_db_manager_seeding_request_msg | Mensagem de solicitação de propagação. |
| hadr_physical_seeding_backup_state_change | Alteração de estado lateral de backup da propagação física. |
| hadr_physical_seeding_restore_state_change | Alteração de estado lateral de restauração da propagação física. |
| hadr_physical_seeding_forwarder_state_change | Alteração de estado lateral do encaminhador da propagação física. |
| hadr_physical_seeding_forwarder_target_state_change | Alteração de estado lateral do destino do encaminhador da propagação física. |
| hadr_physical_seeding_submit_callback | Evento de retorno de chamada de envio da propagação física. |
| hadr_physical_seeding_failure | Evento de falha da propagação física. |
| hadr_physical_seeding_progress | Evento de progresso da propagação física. |
| hadr_physical_seeding_schedule_long_task_failure | Evento de falha da tarefa longa de agendamento da propagação física. |
| hadr_automatic_seeding_start | Ocorre quando uma operação de propagação automática é enviada. |
| hadr_automatic_seeding_state_transition | Ocorre quando uma operação de propagação automática altera o estado. |
| hadr_automatic_seeding_success | Ocorre quando uma operação de propagação automática é bem-sucedida. |
| hadr_automatic_seeding_failure | Ocorre quando uma operação de propagação automática falha. |
| hadr_automatic_seeding_timeout | Ocorre quando uma operação de propagação automática atinge o tempo limite. |
Confira também
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
Guia de solução de problemas e monitoramento dos grupos de disponibilidade Always On