Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server no Linux
SQL Server no Linux
Esse tutorial explica como configurar grupos de disponibilidade do SQL Server com o HPE Serviceguard para Linux em execução em VMs (máquinas virtuais) locais ou em VMs baseadas no Azure.
Para obter uma visão geral dos clusters do HPE Serviceguard, consulte Os Clusters do HPE Serviceguard.
Observação
A Microsoft dá suporte à movimentação de dados, ao grupo de disponibilidade e aos componentes do SQL Server. Entre em contato com a HPE para obter suporte relacionado à documentação sobre gerenciamento de cluster e de quorum do HPE Serviceguard.
Este tutorial é composto pelas seguintes etapas:
- Instale o SQL Server em todas as três VMs que você planeja incluir no grupo de disponibilidade.
- Instale o HPE Serviceguard nas VMs.
- Crie o cluster HPE Serviceguard.
- Crie o balanceador de carga no portal do Azure.
- Crie o grupo de disponibilidade e adicione um banco de dados de exemplo ao grupo de disponibilidade.
- Implante a carga de trabalho do SQL Server no grupo de disponibilidade por meio do gerenciador de cluster do Serviceguard.
- Execute um failover automático e reintegre o nó ao cluster.
Pré-requisitos
No Azure, crie três VMs (Máquinas Virtuais) baseadas em Linux. Para criar máquinas virtuais baseadas em Linux no Azure, confira Início Rápido: criar máquinas virtuais do Linux no portal do Azure. Ao implantar as VMs, use distribuições do Linux com suporte do HPE Serviceguard. Você também pode implantar as VMs localmente em um ambiente local, se preferir.
Para obter um exemplo de uma distribuição compatível, confira HPE Serviceguard para Linux. Entre em contato com a HPE para obter informações sobre suporte para ambientes de nuvem pública.
As instruções no tutorial são validadas junto ao HPE Serviceguard para Linux. Uma edição de avaliação está disponível para download com a HPE.
Arquivos de banco de dados do SQL Server na LVM (montagem de volume lógico) para todas as três máquinas virtuais. Consulte o guia de início rápido do HPE (Serviceguard Linux).
Verifique se você tem o runtime do Java do OpenJDK instalado nas VMs. O SDK de Java da IBM não é compatível.
Instalar o SQL Server
Em todas as três VMs, siga uma das etapas na seção a seguir com base na distribuição do Linux escolhida para este tutorial. As etapas instalam o SQL Server e as ferramentas.
Red Hat Enterprise Linux (RHEL)
SUSE Linux Enterprise Server (SLES)
Observação
A partir do SQL Server 2025 (17.x), não há suporte para SLES (SUSE Linux Enterprise Server).
Ao concluir esta etapa, você tem o serviço e as ferramentas do SQL Server instalados em todas as três VMs que participarão do grupo de disponibilidade.
Instalar o HPE Serviceguard nas VMs
Nesta etapa, instale o HPE Serviceguard para Linux em todas as três VMs. A tabela a seguir descreve a função que cada servidor desempenha no cluster.
| Número de VMs | Função HPE Serviceguard | Função da réplica de grupo de disponibilidade do Microsoft SQL Server |
|---|---|---|
| 1 | Nós de cluster do HPE Serviceguard | Réplica primária |
| 1 ou mais | Nó de cluster do HPE Serviceguard | Réplica secundária |
| 1 | Servidor de quorum do HPE Serviceguard | Réplica somente de configuração |
Observação
Consulte este vídeo da HPE, que descreve como instalar e configurar um cluster HPE Serviceguard via interface do usuário.
Para instalar o Serviceguard, use o método cminstaller. Instruções específicas estão disponíveis nos seguintes links:
- Instale o Serviceguard para Linux em dois nós. Consulte a seção Install_serviceguard_using_cminstaller.
- Instale o servidor de quorum do Serviceguard no terceiro nó. Consulte a seção Install_QS_from_the_ISO.
Depois de concluir a instalação do cluster HPE Serviceguard, você poderá habilitar o portal de gerenciamento de cluster na porta TCP 5522 no nó de réplica principal. As etapas a seguir adicionam uma regra ao firewall para permitir 5522. O comando a seguir é para um RHEL (Red Hat Enterprise Linux). É necessário executar comandos semelhantes para outras distribuições:
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
Criar um cluster do HPE Serviceguard
Siga estas instruções para configurar e criar o cluster do HPE Serviceguard. Nesta etapa, você também configura o servidor de quorum.
- Configure o servidor de quorum do Serviceguard no terceiro nó. Consulte a seção Configure_QS.
- Configure e crie o cluster do Serviceguard nos outros dois nós. Consulte a seção Configure_and_create_Cluster.
Observação
Você pode ignorar a instalação manual do cluster e do quorum do HPE Serviceguard, adicionando a extensão HPE Serviceguard para Linux (SGLX) do marketplace de VMs do Azure ao criar sua VM.
Criar o grupo de disponibilidade e adicionar um banco de dados de exemplo
Nesta etapa, você criará um grupo de disponibilidade com duas ou mais réplicas síncronas e uma réplica somente de configuração, que fornece proteção de dados e também pode fornecer alta disponibilidade. O seguinte diagrama representa essa arquitetura:
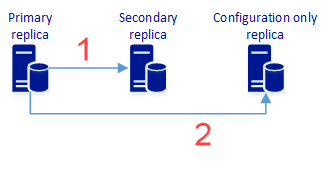
Replicação síncrona de dados do usuário para a réplica secundária. Ela também inclui metadados de configuração do grupo de disponibilidade.
Replicação síncrona de metadados de configuração do grupo de disponibilidade. Ela não inclui dados do usuário.
Para obter mais informações, confira Alta disponibilidade e proteção de dados para configurações de grupo de disponibilidade.
Para criar o grupo de disponibilidade, siga estas etapas:
- Habilite grupos de disponibilidade e reinicie o MSSQL Server em todas as VMs, incluindo a réplica somente de configuração.
-
Habilitar uma sessão de evento
AlwaysOn_health(opcional) - Criar um certificado na VM primária
- Criar o certificado em servidores secundários
- Criar os pontos de extremidade de espelhamento de banco de dados nas réplicas
- Criar grupo de disponibilidade
- Ingressar as réplicas secundárias
- Adicionar um banco de dados ao grupo de disponibilidade
Habilitar grupos de disponibilidade e reiniciar o mssql-server
Habilite grupos de disponibilidade em todos os nós que hospedam uma instância do SQL Server. Em seguida, reinicie o mssql-server. Execute seguinte script em todos os três nós:
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
Habilitar uma sessão de evento AlwaysOn_health (opcional)
Opcionalmente, habilite os eventos estendidos dos grupos de disponibilidade Always On para ajudar no diagnóstico da causa raiz quando você resolver problemas de um grupo de disponibilidade. Execute o seguinte comando em cada instância do SQL Server:
ALTER EVENT SESSION AlwaysOn_health ON SERVER
WITH (STARTUP_STATE = ON);
GO
Criar um certificado na VM primária
O script Transact-SQL a seguir cria uma chave mestra e um certificado. Em seguida, ele faz backup do certificado e protege o arquivo com uma chave privada. Atualize o script com senhas fortes. Conecte-se à instância primária do SQL Server e execute o seguinte script Transact-SQL:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<private-key-password>'
);
Nesse momento, a réplica primária do SQL Server tem um certificado em /var/opt/mssql/data/dbm_certificate.cer e uma chave privada em var/opt/mssql/data/dbm_certificate.pvk. Copie esses dois arquivos para o mesmo local em todos os servidores que hospedam réplicas de disponibilidade. Para acessar esses arquivos, use o mssql usuário ou conceda permissão ao mssql usuário.
Por exemplo, no servidor de origem, o comando a seguir copia os arquivos para o computador de destino. Substitua os valores de node2 pelo nome do host que executa a instância secundária do SQL Server. Copie também o certificado na réplica de configuração somente e execute os comandos a seguir nesse nó.
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
Agora, nas VMs secundárias que executam a instância secundária e a réplica somente de configuração do SQL Server, execute os seguintes comandos para que o mssql usuário possa ter o certificado copiado:
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Criar o certificado em servidores secundários
O script Transact-SQL a seguir cria uma chave mestra e um certificado com base no backup que você criou na réplica primária do SQL Server. Atualize o script com senhas fortes. A senha de descriptografia é a mesma senha que você usou para criar o .pvk arquivo em uma etapa anterior. Para criar o certificado, execute o script a seguir em todos os servidores secundários, exceto na réplica somente de configuração:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<private-key-password>'
);
No exemplo anterior, substitua <private-key-password> pela mesma senha usada ao criar o certificado na réplica primária.
Criar os pontos de extremidade de espelhamento de banco de dados nas réplicas
Nas réplicas primárias e secundárias, execute os seguintes comandos para criar os endpoints de espelhamento de banco de dados.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Observação
5022 é a porta padrão usada para o ponto de extremidade de espelhamento de banco de dados, mas você pode alterá-la para qualquer porta disponível.
Na réplica de apenas configuração, crie o ponto de extremidade de espelhamento de banco de dados usando o comando a seguir. Defina o valor para Role como WITNESS, que é a função necessária para a réplica de configuração apenas.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Criar grupo de disponibilidade
Na instância da réplica primária, execute os comandos a seguir. Esses comandos criam um grupo de disponibilidade chamado ag1, que tem um EXTERNAL cluster_type e concede permissão para de criação de banco de dados ao grupo de disponibilidade.
Antes de executar os scripts a seguir, substitua os espaços reservados <node1>, <node2> e <node3> (réplica apenas de configuração) pelos nomes das VMs que você criou nas etapas anteriores.
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
Unir as réplicas secundárias
Execute os comandos a seguir em todas as réplicas secundárias. Esses comandos ingressam as réplicas secundárias no grupo de disponibilidade ag1 com a réplica primária e permitem acesso de criação de banco de dados ao grupo de disponibilidade ag1.
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Adicionar um banco de dados ao grupo de disponibilidade
Conecte-se à réplica primária e execute os seguintes comandos T-SQL para:
Crie um banco de dados de exemplo chamado
db1, que você adicionará ao grupo de disponibilidade.CREATE DATABASE [db1]; GODefinir o modelo de recuperação do banco de dados para completo. Todos os bancos de dados em um grupo de disponibilidade exigem o modelo de recuperação completo.
ALTER DATABASE [db1] SET RECOVERY FULL;Faça backup do banco de dados. Um banco de dados requer pelo menos um backup completo para que você possa adicioná-lo a um grupo de disponibilidade.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Defina o banco de dados para o modelo de recuperação total.
ALTER DATABASE [db1] SET RECOVERY FULL;Faça backup do banco de dados no disco.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Adicione o banco de dados
db1ao grupo de disponibilidade.ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
Depois de concluir as etapas anteriores, você verá um ag1 grupo de disponibilidade. As três VMs são adicionadas como réplicas com uma réplica primária, uma réplica secundária e uma réplica somente de configuração.
ag1 contém um banco de dados.
Implantar a carga de trabalho do grupo de disponibilidade do SQL Server (Gerenciador de Cluster HPE)
No HPE Serviceguard, implante a carga de trabalho do SQL Server no grupo de disponibilidade por meio da interface do usuário do gerenciador de cluster do Serviceguard.
Implante a carga de trabalho do grupo de disponibilidade e habilite a HA (alta disponibilidade), DR (recuperação de desastre) via cluster do Serviceguard usando a interface gráfica do usuário do gerenciador do Serviceguard. Consulte a seção Proteger grupos de disponibilidade Always On do Microsoft SQL Server em Linux.
Criar o balanceador de carga no portal do Azure
Para implantações no Azure Cloud, o HPE Serviceguard para Linux requer um balanceador de carga para habilitar conexões de cliente com a réplica primária, para substituir endereços IP tradicionais.
No portal do Azure, abra o grupo de recursos que contém as máquinas virtuais ou nós de cluster do Serviceguard.
No grupo de recursos, selecione Adicionar.
Pesquise "balanceador de carga" e, em seguida, nos resultados da pesquisa, selecione o Balanceador de Carga publicado pela Microsoft.
No painel Balanceador de carga, selecione Criar.
Configure o balanceador de carga da seguinte maneira:
Configuração Valor Nome O nome do balanceador de carga. Por exemplo, SQLAvailabilityGroupLB.Tipo Interno SKU Básica ou Standard Rede Virtual Rede virtual usada para as réplicas de VM Sub-rede Sub-rede na qual as instâncias do SQL Server estão hospedadas Atribuição de Endereço IP Estático Endereço IP privado Criar um IP privado na sub-rede Assinatura Escolher a assinatura em questão Grupo de recursos Escolher o grupo de recursos em questão Localidade Selecionar o mesmo local que nós SQL
Configurar o pool de back-end
O pool de back-end são os endereços das duas instâncias nas quais o cluster Serviceguard está configurado.
- No grupo de recursos, selecione o balanceador de carga criado.
- Vá para Configurações>Pools de Backend e selecione Adicionar para criar um pool de endereços de backend.
- Em Adicionar pool de back-end, em Nome, digite um nome para o pool de back-end.
- Em Associado a, selecione Máquina virtual.
- Selecione a máquina virtual no ambiente e associe o endereço IP apropriado a cada seleção.
- Selecione Adicionar.
Criar uma investigação
A investigação define como o Azure verifica qual do nó de cluster Serviceguard é a réplica primária. O Azure investiga o serviço com base no endereço IP em uma porta que você define quando cria o teste.
No painel Configurações do balanceador de carga, selecione Investigações de integridade.
No painel Investigações de integridade, selecione Adicionar.
Use os valores a seguir para configurar a investigação:
Configuração Valor Nome Nome que representa a investigação. Por exemplo, SQLAGPrimaryReplicaProbe.Protocolo TCP Porta Você pode usar qualquer porta disponível. Por exemplo, 59999. Intervalo 5 Limite não íntegro 2 Selecione OK.
Entre em todas as suas máquinas virtuais e abra a porta de investigação usando os seguintes comandos:
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
O Azure cria a investigação e a usa para testar o nó Serviceguard no qual a instância de réplica primária do grupo de disponibilidade está em execução. Lembre-se da porta configurada (59999), que é necessária para implantar o AG no cluster do Serviceguard.
Definir as regras de balanceamento de carga
As regras de balanceamento de carga configuram como o balanceador de carga roteia o tráfego para o nó Serviceguard, que é a réplica primária no cluster. Para esse balanceador de carga, habilite o retorno do servidor direto, pois apenas um dos nós de cluster Serviceguard pode ser uma réplica primária por vez.
Nas configurações do balanceador de carga, selecione Regras de balanceamento de carga.
Em Regras de balanceamento de carga, selecione Adicionar.
Defina a regra de balanceamento de carga usando as seguintes configurações:
Configuração Valor Nome Nome que representa as regras de balanceamento de carga. Por exemplo, SQLAGPrimaryReplicaListener.Protocolo TCP Porta 1433 Porta de back-end 1433. Esse valor é ignorado porque essa regra usa IP flutuante. Investigação Use o nome da investigação que você criou para este balanceador de carga. Persistência de sessão Nenhum Tempo limite ocioso (minutos) 4 IP flutuante Habilitado Selecione OK.
O Azure configura a regra de balanceamento de carga. Agora, o balanceador de carga está configurado para rotear o tráfego para o nó Serviceguard, que é a instância de réplica primária no cluster.
Anote o endereço IP de front-end do balanceador de carga LbReadWriteIP, que você precisa implantar o AG no cluster Serviceguard.
Neste ponto, o grupo de recursos tem um balanceador de carga que se conecta em todos os nós Serviceguard. O balanceador de carga também contém um endereço IP para os clientes se conectarem à instância de réplica primária no cluster, para que qualquer computador que seja uma réplica primária possa responder a solicitações para o grupo de disponibilidade.
Realizar um failover automático e ingressar o nó de volta no cluster
Para o teste de failover automático, coloque a réplica primária offline (desligue o equipamento). Esta ação simula a indisponibilidade repentina do nó primário. O comportamento esperado é:
O gerenciador de cluster promove uma das réplicas secundárias no grupo de disponibilidade para primária.
A réplica primária com falha se junta automaticamente ao cluster depois de ser reiniciada. O gerenciador de cluster a promove a uma réplica secundária.
Para o HPE Serviceguard, consulte Testar a configuração para prontidão de failover.