Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server no Linux
SQL Server no Linux
Este artigo explica os conceitos relacionados às instâncias de cluster de failover (FCI) do SQL Server no Linux.
Para criar uma FCI do SQL Server no Linux, confira Configurar uma instância de cluster de failover - SQL Server em Linux (RHEL)
A camada de agrupamento
No RHEL (Red Hat Enterprise Linux), a camada de clustering baseia-se no complemento de HA do RHEL (Red Hat Enterprise Linux).
Observação
O acesso ao complemento de HA do Red Hat e à documentação exige uma assinatura.
No SUSE Linux Enterprise Server (SLES), a camada de clustering baseia-se na HAEExtensão de alta disponibilidade (HAE) do SUSE Linux Enterprise.
Para obter mais informações sobre configuração de cluster, opções do agente de recursos, gerenciamento, melhores práticas e recomendações, confira a Extensão de alta disponibilidade do SUSE Linux Enterprise 15.
O complemento de HA RHEL e o HAE do SUSE são criados no Pacemaker.
Como mostra o diagrama a seguir, o armazenamento é apresentado a dois servidores. Os componentes de clustering – Corosync e Pacemaker – coordenam a comunicação e o gerenciamento de recursos. Um dos servidores tem a conexão ativa com os recursos de armazenamento e o SQL Server. Quando o Pacemaker detecta uma falha, os componentes de clustering são responsáveis por mover os recursos para o outro nó.
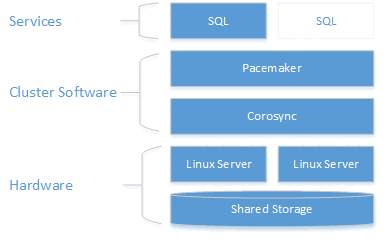
A integração do SQL Server com o Pacemaker no Linux não está tão acoplada quanto a do WSFC no Windows. O SQL Server não tem conhecimento sobre a presença do cluster. Toda a orquestração é externa, e o serviço é controlado como uma instância autônoma pelo Pacemaker. Além disso, o nome de rede virtual é específico do WSFC; não há equivalente a ele no Pacemaker. Espera-se que @@SERVERNAME e sys.servers retornem o nome de nó, enquanto as DMVs do cluster sys.dm_os_cluster_nodes e sys.dm_os_cluster_properties não retornem nenhum registro. Para usar uma cadeia de conexão que aponta para um nome de servidor ao invés do IP, eles precisam registrar no servidor DNS o IP usado para criar o recurso de IP virtual (conforme explicado nas seções a seguir) com o nome do servidor escolhido.
Número de instâncias e nós
Uma diferença importante com SQL Server em Linux é que só pode haver uma instalação de SQL Server por servidor Linux. Essa instalação é conhecida como uma instância. Diferentemente do Windows Server, que dá suporte a até 25 FCIs por WSFC (cluster de failover do Windows Server), uma FCI baseada em Linux terá apenas uma única instância. Essa instância única também é uma instância padrão. Não há nenhum conceito de uma instância nomeada no Linux.
Um cluster do Pacemaker só pode ter até 16 nós quando o Corosync está envolvido, de modo que um único FCI pode abranger até 16 servidores. Um FCI implementado com a Standard Edition do SQL Server dá suporte a até dois nós de um cluster, mesmo que o cluster do Pacemaker tenha o máximo de 16 nós.
Em uma FCI do SQL Server, a Instância do SQL Server está ativa em um nó ou no outro.
Nome e Endereço IP
Em um cluster do Pacemaker do Linux, cada FCI do SQL Server precisa de endereço IP e nome próprios. Se a configuração da FCI abranger várias sub-redes, será necessário um endereço IP por sub-rede. O nome exclusivo e os endereços IP são usados para acessar a FCI de modo que os aplicativos e os usuários finais não precisam ter conhecimento do servidor subjacente do cluster do Pacemaker.
O nome da FCI no DNS deve ser igual ao nome do recurso da FCI criado no cluster do Pacemaker. O nome e o endereço IP devem ser registrados no DNS.
Armazenamento compartilhado
Todas as FCIs, estejam no Linux ou no Windows Server, exigem alguma forma de armazenamento compartilhado. Esse armazenamento é apresentado a todos os servidores que podem hospedar a FCI, mas apenas um único servidor pode usar o armazenamento para a FCI em um determinado momento. As opções disponíveis para o armazenamento compartilhado no Linux são:
- iSCSI
- NFS (sistema de arquivos de rede)
- Bloco de Mensagens de Servidor (SMB)
No Windows Server, há opções ligeiramente diferentes. Uma opção que atualmente sem suporte nas FCIs baseadas em Linux é a capacidade de usar um disco local para o nó para o tempdb, que é o workspace temporário do SQL Server.
Em uma configuração que abrange vários locais, o que é armazenado em um data center deve ser sincronizado com o outro. No caso de um failover, a FCI pode ficar online e o armazenamento é visto como o mesmo. Conseguir isso exige um método externo para replicação de armazenamento, seja ele feito por meio do hardware de armazenamento subjacente ou por algum utilitário baseado em software.
Observação
Para o SQL Server, as implantações baseadas em Linux que usam discos apresentados diretamente a um servidor devem ser formatadas com XFS ou ext4. No momento, não há suporte para outros sistemas de arquivos. Todas as alterações serão refletidas aqui.
O processo para apresentar o armazenamento compartilhado é o mesmo para os diferentes métodos compatíveis:
- Configurar o armazenamento compartilhado
- Monte o armazenamento como uma pasta nos servidores que servirão como nós do cluster do Pacemaker para a FCI
- Se necessário, mova os bancos de dados do sistema do SQL Server para o armazenamento compartilhado
- Testar se o SQL Server funciona de cada servidor conectado ao armazenamento compartilhado
Uma grande diferença com o SQL Server em Linux é que, embora você possa configurar a localização do arquivo de log e dos dados do usuário padrão, os bancos de dados do sistema sempre devem existir em /var/opt/mssql/data. No Windows Server, é possível mover os bancos de dados do sistema, incluindo tempdb. Isso afeta o modo como o armazenamento compartilhado é configurado para uma FCI.
Os caminhos padrão para bancos de dados que não do sistema podem ser alterados usando o utilitário mssql-conf. Para obter informações sobre como alterar os padrões, Altere a localização do diretório de dados ou de log padrão. Você também pode armazenar dados e transações do SQL Server em outras localizações, contanto que tenham a segurança apropriada, mesmo que não seja uma localização padrão; a localização precisaria ser declarada.